Today I Learned
오늘은 머신러닝 이어서 수강!
Validation Strategy
데이터 셋
1. Train Set (훈련 데이터)
모델을 학습시키는 데 사용되는 데이터. 모델은 Train Set을 이용해 가중치를 조정하고 패턴을 학습한다. 일반적으로 전체 데이터 셋 중 대다수가 여기에 속한다. 모델을 학습하는데는 유일하게 Train Set만 쓰인다.
- noise 데이터를 train set에 포함할지 안할지 고민해봐야 한다.
2. Validation Set (검증 데이터)
훈련 데이터셋을 이용하여 모델을 학습한 후에 모델의 하이퍼파라미터(Hyperparameters)를 조정하고 모델의 성능을 평가하는 데에 사용된다. 학습이 이미 완료된 모델을 검증하는 데이터셋이다.
-
최종 test set을 모델에 적용하기 전에 모델이 overfit한지 underfit한지 알아보기 위해 validation set을 사용한다.
-
test set과 최대한 유사하게 샘플을 만드는 것이 좋다. 하지만 일반적으로는 test set 정보는 알 수 없다(unseen). 따라서 전체 데이터 셋과 유사하게 만드는 것이 좋다.
3. Test Set (테스트 데이터)
모델의 성능을 평가하는 데 사용된다. 모델이 훈련 데이터에 과적합(overfitting)되었는지 확인하고, 새로운 데이터에 대한 일반화 능력을 평가한다. 모델을 최종적으로 평가하기 위해 사용되며 모델의 성능 측정에 사용된다. 학습과 검증이 완료된 모델의 최종 성능을 평가하기 위한 데이터셋이다.
-
테스트 데이터는 최대한 전체 데이터 셋을 대표하는 데이터여야 한다. 따라서 함부로 바꿀 수 없다.
-
그래서 테스트는 두고 validation set을 변경하는 것이 비교적 합리적인 선택이다. 이렇게 validation set을 컨트롤 하는 전략을 Validation Strategy라 한다.
Hold-out Validation
전체 데이터 셋을 test와 validation set으로 나눈다.
일반적으로 8:2정도로 나눈다.
-
random
간단하지만 데이터셋이 충분히 크지 않다면 전체 데이터를 대표하지는 못할 수 있다. -
stratified split
전체 데이터의 카테고리별 비율을 따져서 비율을 유지한채로 train과 validation set을 나눈다.
Cross Validation(교차검증)

전체 데이터셋을 k개의 부분집합(폴드, fold)으로 나눈 후, k-1개의 폴드를 훈련 데이터로, 나머지 1개의 폴드를 평가 데이터로 사용한다. 이 과정을 k번 반복하여 각 폴드가 한번씩 평가 데이터로 사용되는 방법이다.
- k-fold CV
데이터를 랜덤한 k개의 폴드로 나누는 방법. 보통 k=5나 k=10을 많이 사용한다.
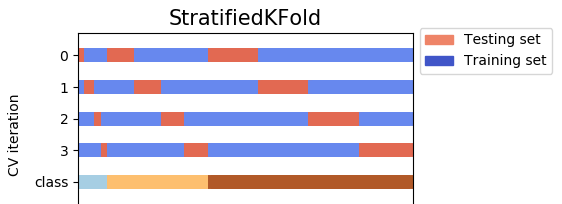
- Stratified k-fold CV
데이터의 클래스 분포를 반영하여 각 폴드 내 클래스 비율을 유지해서 폴드를 나누는 방법.
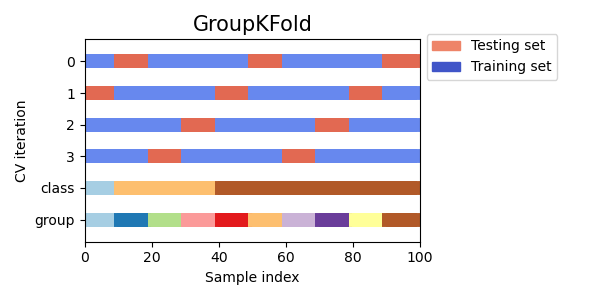
3. Group k-fold CV
같은 그룹이 동일한 폴드에 들어가지 않게 split하는 방법. 그룹이 폴드 개수보다 많아야 가능하다.
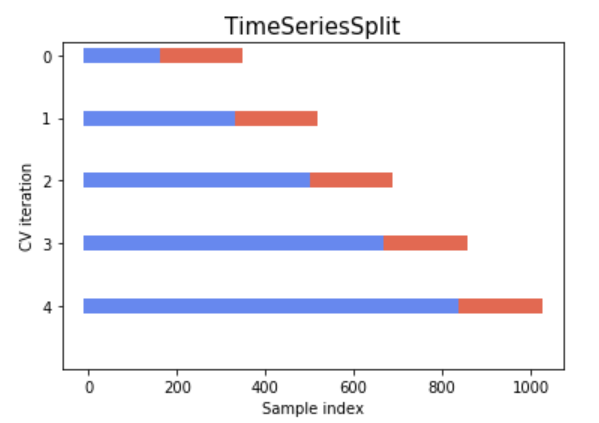
- time series split
시계열 데이터는 데이터의 순차 시간을 고려해 validation set을 선정해야 한다. 미래 데이터로 과거 데이터를 예측하는 일이 없도록 하기 위함이다.
Reproducibility(재현성)
-
재현성 : 같은 데이터와 코드를 사용했을 때 동일한 결과를 얻을 수 있는 것을 의미합니다.
-
머신러닝의 랜덤성과 샘플링이 매번 바뀌는 이유 때문에 모델 성능이 매번 다르게 나온다. 하지만 반복 실행했을때 똑같은 조건 하에서 샘플링이 되어야 모델 성능을 정확히 측정할 수 있기때문에 재현성이 중요하다.
-
이를 위해서 시드를 고정(
Fix seed)해야 한다. -
머신러닝 라이브러리와 알고리즘에는 난수 발생기가 사용되는데, 이때 시드(seed) 값에 따라 결과가 달라질 수 있다. 시드 값은 난수 발생 순서를 결정하는 초기값이다. numpy에선 아래와 같이 고정할 수 있다.
import numpy as np
import random
SEED = 42
np.random.seed(SEED)
random.seed(SEED)- 실험시에는 재현성을 위해 seed를 고정하고 최종 모델 배포시에는 시드 고정을 풀면 된다.
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
