Today I Learned
오늘은 AI 수업 트리모델을 수강했다.
Tree Model
데이터의 특성을 기반으로 계층적인 의사결정 규칙을 만들어 내는 모델
Decision Tree
-
가장 기초적인 트리 모델
-
컬럼(feature) 값들을 기준으로 그룹을 만들어 목적에 맞는 의사결정을 만드는 방법
-
하나의 질문으로 yes or no로 decision을 내려서 분류(스무고개처럼)
-
모든 데이터들을 사용해 트리를 생성한다.
Bagging & Boosting
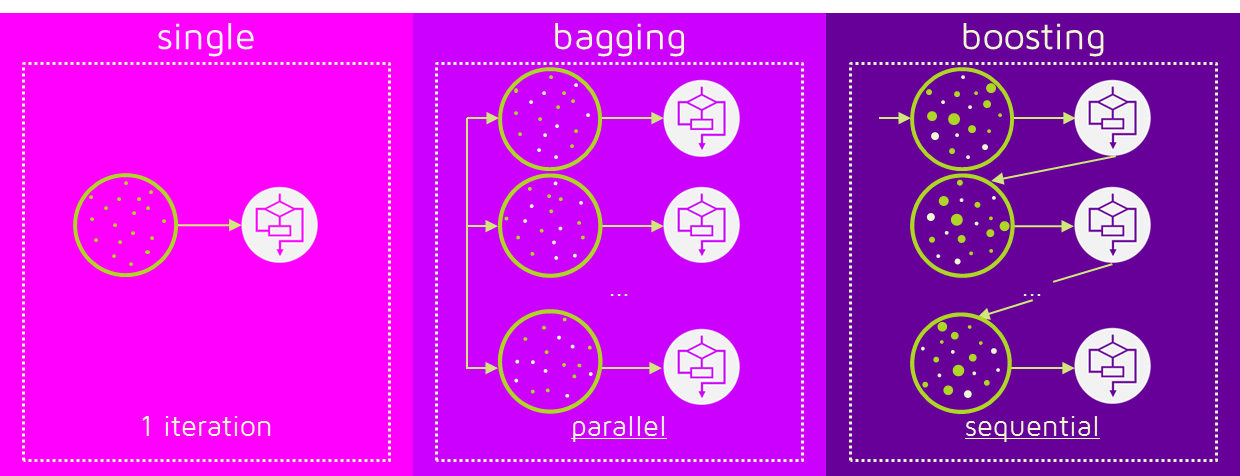
Bagging
-
Bootstrap(데이터를 여러번 샘플링) + Aggregation(종합)의 약자로, 부트스트랩 샘플링과 앙상블 기법을 결합한 방법. 샘플을 여러 번 뽑아 각 모델을 학습시켜 결과를 집계(Aggregating) 하는 방법
-
데이터 셋을 랜덤하게 샘플링해서 모델을 만들어 나가는 것이 특징
-
샘플링한 데이터 셋 하나 당 하나의 Decision Tree가 생성된다.
-
생성한 Decision Tree의 Decision들을 취합해 하나의 Decision을 만든다.
-
병렬모델(각 모델이 서로 연관이 없음), 다양한 Tree를 생성
Boosting
-
부스팅은 여러 개의 약한 학습기(weak learner)를 순차적으로 학습하여 강력한 최종 모델을 만드는 방식
-
초기에 랜덤한 데이터 셋으로 하나의 Decision Tree를 만들고 잘 맞추지 못한 데이터에 weight를 부여해 다음 샘플링에 반영해 잘 맞출 수 있도록 한다.
-
매 반복마다 잘못 예측한 데이터에 가중치를 높여 다음 학습기가 보완하도록 유도한다.
-
순차적 모델(이전 tree의 error기반), 정밀한 Tree 생성
모델 소개
-
LightGBM, XGBoost, CatBoost가 유명한 boosting 모델이다.
-
XGBoost, CatBoost는 트리 생성시 균형적으로 생성(트리 양쪽 좌우가 균형있게 생성)되고, LightGBM는 한쪽의 가지가 지속적 성장 후 다른쪽 가지가 성장된다.
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
