Today I Learned
오늘은 AI 강의 앙상블 러닝에대해 학습했다.
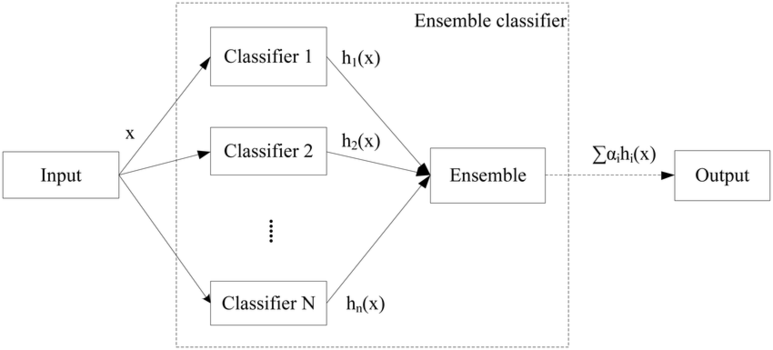
Ensemble Learning 앙상블 러닝
여러 개의 다양한 학습 알고리즘을 결합하여 하나의 강력한 모델을 만드는 머신 러닝 기법
-
하나의 단일 알고리즘보다 적당한 알고리즘 여러개를 조합해서 단일 알고리즘보다 성능 향상을 기대하는 기법이다.
-
특정한 하나의 알고리즘은 모든 문제에서 항상 우월하긴 힘들다. (각 알고리즘별로 강점과 약점이 존재한다)
-
여러개의 결정 트리를 결합해 하나의 결정트리보다 더 좋은 성능을 내는 기법이다.
-
핵심은 여러개의 약 분류기(Weak Classifier)를 결합해 강 분류기(Strong Classifier)를 만드는 과정
-
여러 단일 모델들의 평균치를 내거나 투표를 해서 다수결에 의한 결정을 하는 등 여러 모델들의 집단 지성을 활용해 더 나은 결과를 도출해 내는 것에 주 목적이 있다.
-
장점
성능을 분산시키기 때문에 overfitting을 감소하는 효과가 있고, 개별 모델 성능이 잘 안나올때 이용하면 전체적인 성능이 향상될 수 있다. -
단점
모델의 복잡성이 증가하고 계산비용이 더 많이 필요할 수 있고, 모델의 해석이 어려울 수 있다.
기법
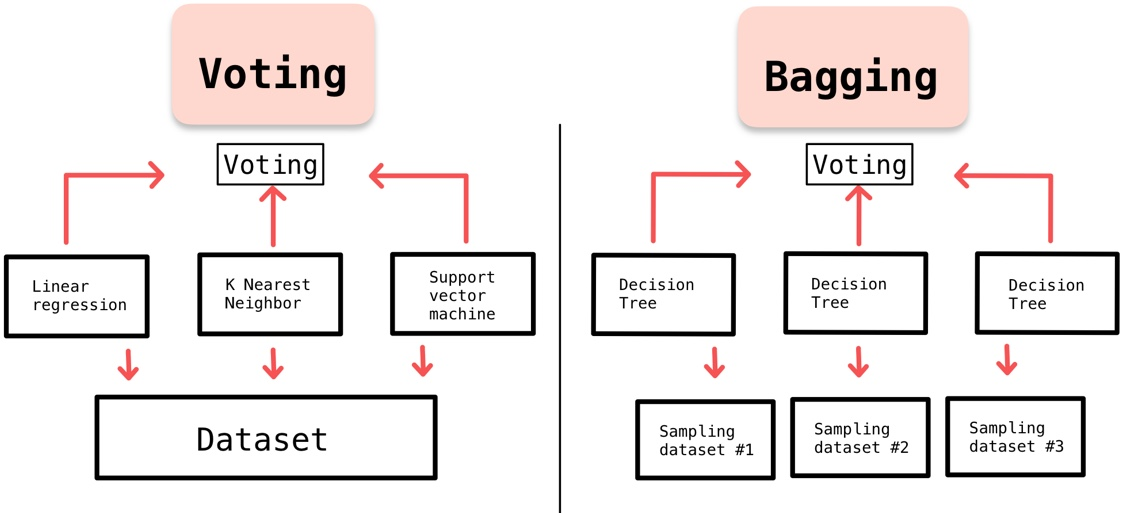
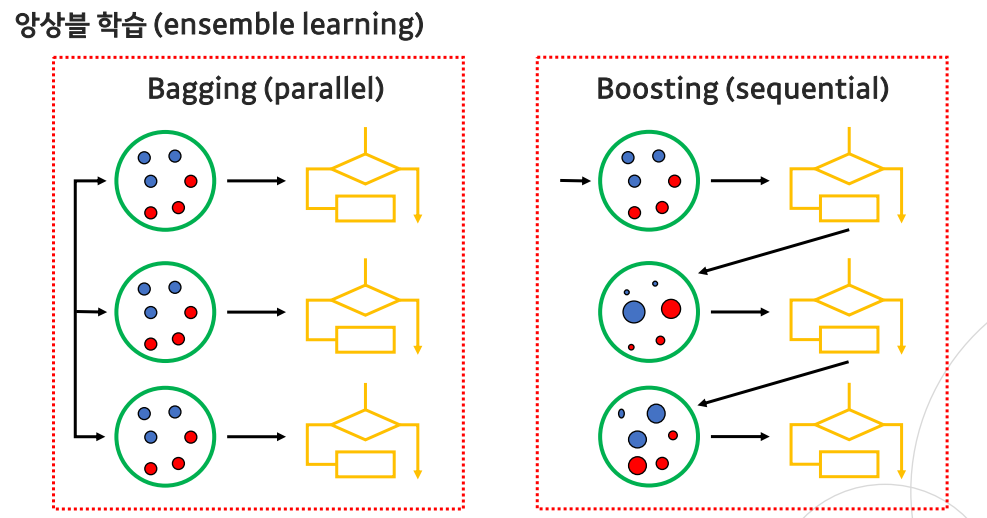
1. Bagging
-
Bootstrap Aggregation의 약자
-
훈련 셋에서
중복을 허용해 샘플링하는 방식이다. -
모델의 분산을 줄이고 overfitting을 방지하는 데 효과적이다.
-
각 모델이 독립적으로 학습되는 알고리즘으로 데이터의 무작위 부분집합을 생성하여 각 부분집합에 모델을 학습시킨다. 각 모델은 같은 알고리즘을 사용하지만 다른 부분집합을 기반으로 학습된다.
-
대표적으로 랜덤 포레스트 알고리즘이 있다.
2. Pasting(페이스팅)
-
bagging의 한 유형으로 학습데이터의
중복을 허용하지 않고샘플링해서 여러개의 기본 모델을 독립적으로 학습시키는 방법이다. (보통은 배깅을 사용하고 페이스팅은 많이 사용하는 방식은 아니다) -
배깅과 마찬가지로 각 모델은 동일한 기계 학습 알고리즘을 사용하여 학습되지만, 중복을 허용하지 않기 때문에 각 모델이 서로 다른 데이터를 기반으로 학습되어 다양성이 증가된다. 결과적으로 모델의 일반화 능력이 향상된다.
-
중복이 비허용되기 때문에 데이터셋이 상당히 큰 경우에 유용하고 부분집합을 사용하기 때문에 병렬로 여러 모델을 학습시키는 것이 효율적이다.
3. Voting(보팅)
-
다수의 기본 모델의 예측을 결합하여 최종 예측을 만드는 방법이다. (주로 분류 문제에 사용)
-
bagging과 같은 투표 방식이라는 점에서 유사하지만, voting은 다른 알고리즘 model 사용하고, bagging은 같은 알고리즘 내에서 다른 sample 조합을 사용하는 차이점이 있다.
-
즉, 서로 다른 알고리즘이 도출한 결과물에 대해 최종 투표하는 방식이다.
-
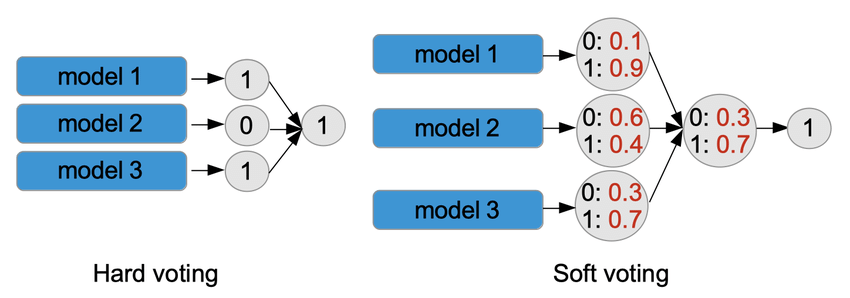
hard voting
결과물에 대한 최종 값을 투표로 결정. 다수결과 비슷하다. 각 기본 모델의 예측 클래스들을 집계하여 가장 많은 투표를 얻은 클래스를 최종 예측으로 선택한다. 각 모델의 예측에 동일한 가중치를 부여한다. -
soft voting
최종 결과물이 나올 확률값을 다 더해서 최종 결과물에 대한 각각의 확률을 구한 뒤 최종값을 도출. 각 기본 모델의 예측 확률들을 평균하여 가장 높은 평균 예측 확률을 가진 클래스를 최종 예측으로 선택한다. 일반적으로 각 모델의 신뢰도를 고려하여 가중 평균을 계산한다.
4. Boosting
-
앙상블 학습의 한 유형으로, 여러 개의 기본 모델을 연속적으로 학습하여 강력한 모델을 생성하는 기법이다. 각 모델은 이전 모델이 만든 오차를 보완하도록 학습되어 최종 예측을 개선한다.
-
보통 bagging에 비해 성능이 잘 나오지만 sequantial한 방식 때문에 bagging에 비해 속도가 느리고 overfitting 확률이 높다.
5. Stacking
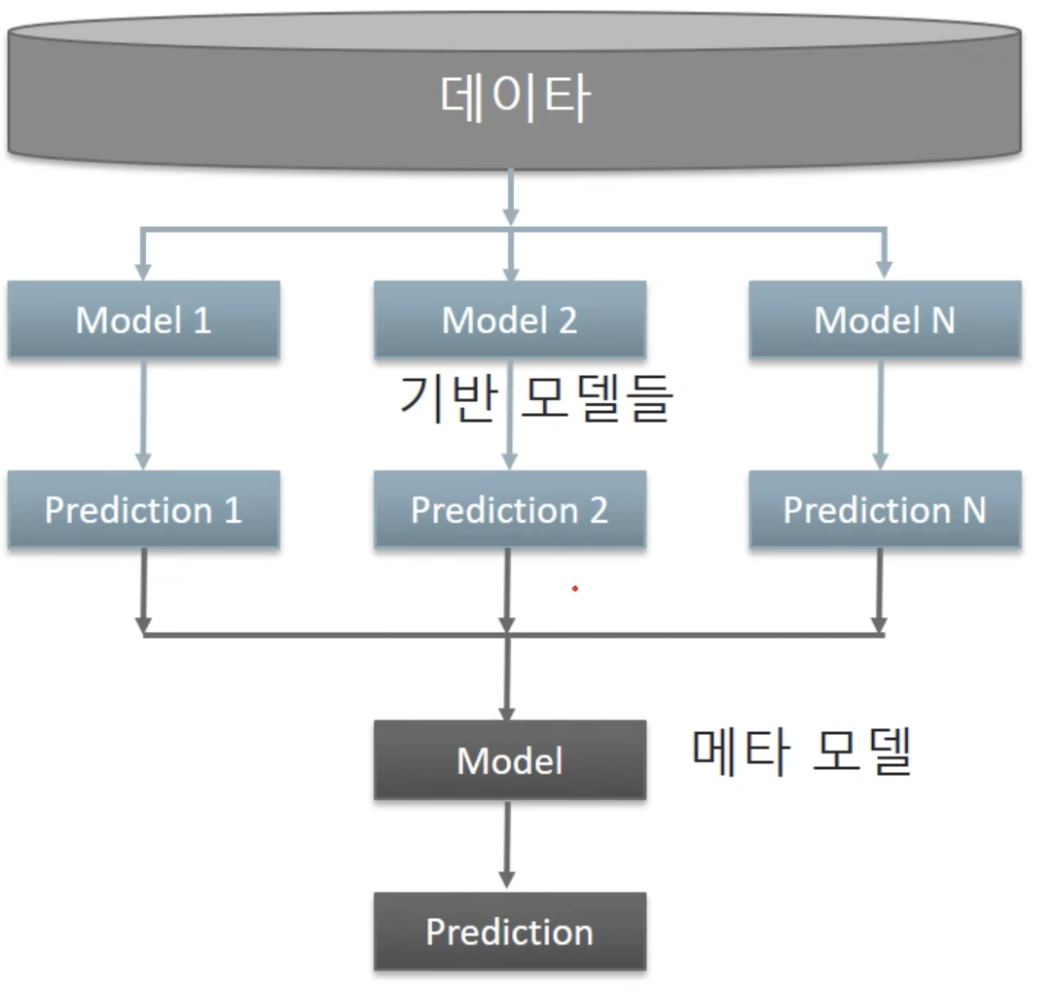
-
여러 모델들을 활용해 각각의 예측 결과를 도출한 뒤 그 예측 결과를 결합해서 메타학습을 거쳐 최종 예측 결과를 만드는 기법. 중간의 여러 모델들이 base learner고, 이를 기반으로 최종 예측 결과를 만드는 모델이 Meta 모델이다.
-
단일 모델보다 월등히 성능이 향상된다. 하지만 overfitting의 위험이 있다. 그래서 cross validation을 기반으로 stacking을 진행해서 overfitting을 피한다.
-
시간과 비용이 많이 소모되기 때문에 모델의 성능을 쥐어짜기 위한 방법으로 쓰이고, 현실적으로 production 레벨에선 잘 쓰진 않는다.
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
