Today I Learned
오늘은 앙상블 러닝에 이어서 트리 알고리즘과 tabnet에 대해 공부!
Tree Algorithms
Decision Tree : impurity(불순도, 복잡성)
-
결정 트리에서 사용하는 개념으로 데이터의 혼잡도나 불확실성을 측정하는 지표
-
해당 노드안에 다른 것이 섞여있는 정도가 높을수록 높고, 덜 섞여있을 수록 낮다.
(낮을수록 잘 구분되어있으므로 좋은 지표다) -
결정 트리는 데이터를 분할할 때 불순도를 최소화 하는 방향으로 분할을 수행한다.
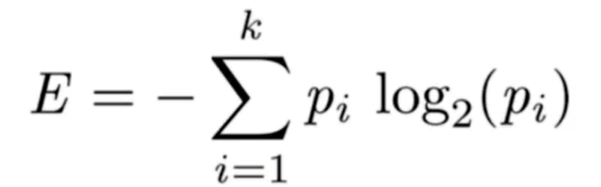
- Entropy(엔트로피)
불순도를 측정하는 지표. 정보량의 기대값.
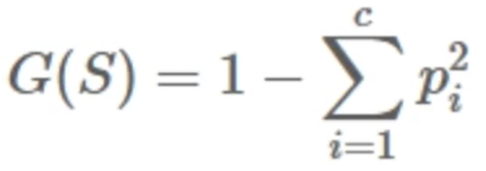
- Gini Index
불순도 측정 지표. 데이터의 통계적 분산 정도를 정량화해서 표현한 값
XGboost
-
Gradient Boosting을 기반으로 Regulatization Term을 추가한 앙상블 학습 알고리즘
-
다양한 Loss function을 지원해서 task에 따른 유연한 튜닝이 가능하다.
-
성능은 좋지만 학습시간이 느리다는 단점이있다.
LightGBM
-
XGBoost의 느린 학습시간과 많은 하이퍼 파라미터를 단순화해서 간단하게 사용할 수 있게 했다.
-
leaf-wise tree growth 방식이라 loss 변화가 가장 큰 노드에서 분할해서 성장하는 수직 성장 방식이다. (XGboost는 트리 깊이를 줄이고 균형있게 만들기 위해 root노드와 가까운 노드부터 순회하는 수평 성장 방식)
-
대용량 데이터에 유리하고, 데이터가 적으면 overfitting 위험성이 있다.
-
GOSS : Gradient-based One-Side Sampling
기울기가 큰 데이터는 취하고 기울기가 작은 데이터는 작은 비율만 선택하는 방식
Catboost
-
범주형 데이터가 많은 곳에서 높은 성능을 발휘
-
순서형 원칙(Ordered Principle)을 제시
-
Random Permutation : 데이터를 셔플링해서 뽑아낸다.
-
범주형 feature 처리 방법
Ordered Target Encoding
Categorical Feature Combinations
One-Hot Encoding -
Optimized Parameter Tuning
하이퍼 파라미터 디폴트 최적화가 잘 되어있어서 파라미터 튜닝을 XGboost, LightGBM에 비해 덜 신경써도 된다.
TabNet
Tabular Data(정형 데이터, 테이블형식의 구조화된 데이터)를 위한 딥러닝 모델
-
전처리 과정이 필요하지 않다.
-
정형 데이터에 대해서는 기존의 신경망 모델이나 Decision Tree based gradient boosint 모델에 비해 우수하다.
-
Feature selection, interpretability가 가능한 신경망 모델,
설명 가능한 모델 -
feature 갑을 예측하는 Unsupervised pre-training 단계를 적용해 상당한 성능 향상을 보여준다.
-
순차적인 어텐션(Sequential Attention)을 사용해서 각 의사결정 단계에서 추론할 특징(feature)을 선택해 학습 능력이 가장 두드러진 특징을 사용한다. 기존 머신러닝에서는 특징 선택과 모델 학습 과정이 나누어져있지만 TabNet은 한번에 가능하다.
참고 사이트 : subinium
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
