Today I Learned
오늘 배운 내용은 기존 딥러닝 방법론들을 연도별로 impact 있었던 논문 위주로 배웠다.
딥러닝 방법론
AlexNet(2012)
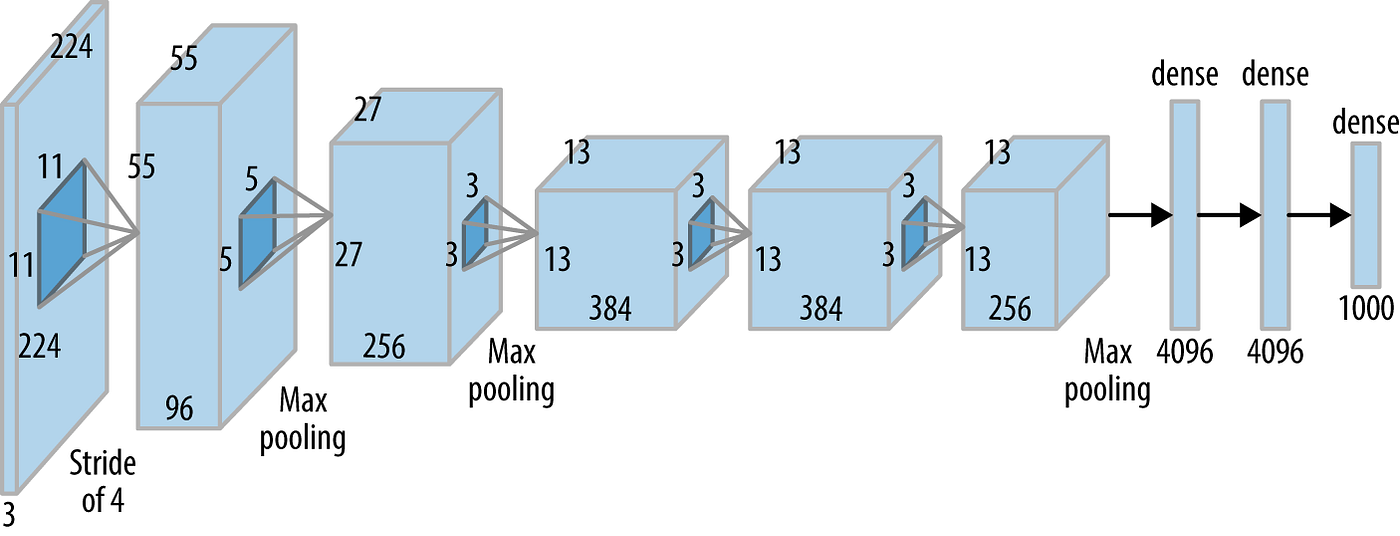
2012년에 이미지넷 대회에 우승하면서 널리 알려진 신경망 모델. 이 이후로 딥러닝으로 패러다임 전환이 이루어졌다.
-
이미지 분류를 위한 합성곱 신경망(CNN, Convolutional Neural Network)이다.
-
8개의 layers로 구성되어 처음에는 전체 이미지를 보고 점점 더 자세히 분석해 작은 특징들을 찾아낸 뒤, 마지막으로 모든 특징을 종합해 이 이미지가 무엇인지 분류하는 절차를 따른다.
-
ReLU 활성화 함수, dropout, 데이터 증강 등의 기술을 사용했다.
DQN(2013)
Deep Q-Network. 딥마인드에서 아타리 게임을 강화학습을 이용해 풀어내게 된 딥러닝 모델.
-
강화 학습(Reinforcement Learning)의 한 종류로 딥러닝을 활용하여 복잡한 환경에서 최적의 행동을 학습하는 알고리즘이다.
-
강화 학습에서 Agent는 환경과 상호작용하며 최적의 행동을 학습한다.
Agent는 상태를 관찰하고, 행동을 선택하여 보상을 얻는다.
Agent의 목표는 장기적으로 최대 보상을 얻는 정책을 학습하는 것이다.
Encoder-Decoder(2014)
자연어 처리(NLP)와 시퀀스 변환 작업에서 널리 사용되는 아키텍처
-
Encoder-Decoder 모델은 두 개의 주요 구성 요소 인코더(Encoder)와 디코더(Decoder)로 구성된다.
-
이 모델은 입력 시퀀스를 고정된 길이의 벡터로 인코딩하고, 이를 기반으로 출력 시퀀스를 생성한다.
Adam Optimizer(2014)
딥러닝 모델의 학습을 효율적으로 도와주는 최적화 알고리즘
-
확률적 경사 하강법(SGD)과 그 변형들의 장점을 결합하여, 빠르고 효과적인 학습을 가능하게 한다. 대규모 데이터와 복잡한 모델에서 현재까지도 좋은 성능을 발휘해 자주 쓰인다.
-
확률적 경사 하강법의 변형으로, 학습 과정에서 각 파라미터의 학습률을 적응적으로 조정하는데, 이를 위해 일차 모멘트(Gradient의 이동 평균)와 이차 모멘트(Gradient 제곱의 이동 평균)를 사용한다.
GAN(2015)
Generative Adversarial Network.
생성자와 판별자가 서로 경쟁하는 게임 이론적 접근 방식이다.
-
생성자(Generator)와 판별자(Discriminator)의 2개의 신경망으로 구성되어 있으며, 이 둘이 서로 경쟁하면서 학습하는 구조다.
-
특히 이미지 생성, 비디오 생성, 데이터 증강 등 다양한 생성 작업에서 뛰어난 성능을 발휘한다.
ResNet(2015)
Residual Networks.
ResNet 이전에는 Network(layer)를 너무 깊게 쌓으면 test 성능이 안좋게 나와 얕게 쌓았다. 하지만 ResNet에서 Network를 깊게 쌓아도 test 성능이 좋게 나오게 만들었고, 레이어가 더 깊어지는 패러다임 전환이 일어났다.
- 잔차 연결(Residual Connection)을 도입하여, 신경망의 각 층이 입력을 직접 전달받을 수 있게 한다. 이를 통해 정보 손실을 줄이고, 깊은 네트워크에서도 효과적인 학습을 가능하게 한다.
Transformer(2017)
구글에서 발표한 논문 명 Attention Is All You Need.
언어 처리(NLP) 분야에서 혁신을 가져온 모델이다.
- 가장 큰 특징은 순환 신경망(RNN)이나 합성곱 신경망(CNN)을 사용하지 않고도 시퀀스를 처리할 수 있다는 점이다. 이를 통해 병렬 처리가 가능해져 학습 속도가 대폭 향상되었다.
BERT(2018)
Bidirectional Encoder Representations from Transformers.
Google이 발표한 Transformer 아키텍처를 기반의 자연어 처리(NLP) 모델
- 트랜스포머 모델을 사용하며, 양방향(bidirectional) 언어 모델링을 수행한다. 기존의 언어 모델과 달리 BERT는 문맥을 고려하기 위해 좌측과 우측 모두의 문맥을 고려하여 단어를 예측한다.
- 대규모 텍스트 코퍼스(ex. 위키)를 사용하여 사전 훈련을 진행한다. 그 후 사전 훈련된 가중치를 초기화하고, 특정 NLP 작업에 맞게 추가적인 훈련(fine-tuning)을 수행한다.
GPT(2019)
Open AI의 GPT
수억 개 이상의 파라미터를 가지며, 대규모 텍스트 코퍼스에서 사전 훈련된 후, 다양한 자연어 처리(NLP) 작업에 미세 조정된다.
Self Supervised Learning(2020)
SimCLR 논문. 주어진 학습데이터 외에 라벨(label, ex. 고양이, 강아지)을 모르는 unsupervised Data를 활용한다는 아이디어
-
모델이 입력 데이터로부터 스스로 학습할 수 있도록 설계되었다.
-
풍부한 양의 데이터를 수집하고 라벨을 지정하는 데 필요한 노력과 비용을 줄일 수 있다.
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
