Today I Learned
오늘 공부한 내용은 최적화!
Optimization
머신러닝에서는 손실함수의 최소화를 목표로 파라미터(매개변수)를 조정해 최적의 해를 찾는 과정을 최적화라고 한다.
-
목표함수 : 최적화의 대상이 되는 함수로 머신러닝에서는 손실함수가 목표함수다. 최소화(최대화)하려는 대상이다.
-
매개변수 : 파라미터. 목표 함수를 최적화하기 위해 조정되는 변수들이다. 딥러닝에서는 모델의 가중치(weight)와 편향(bias)이 매개변수에 속한다.
-
최적화 알고리즘
최적화 알고리즘은 목표 함수를 최소화하거나 최대화하기 위해 매개변수를 조정하는 방법을 정의한다. 일반적으로 경사하강법을 포함한 다양한 알고리즘이 사용된다.
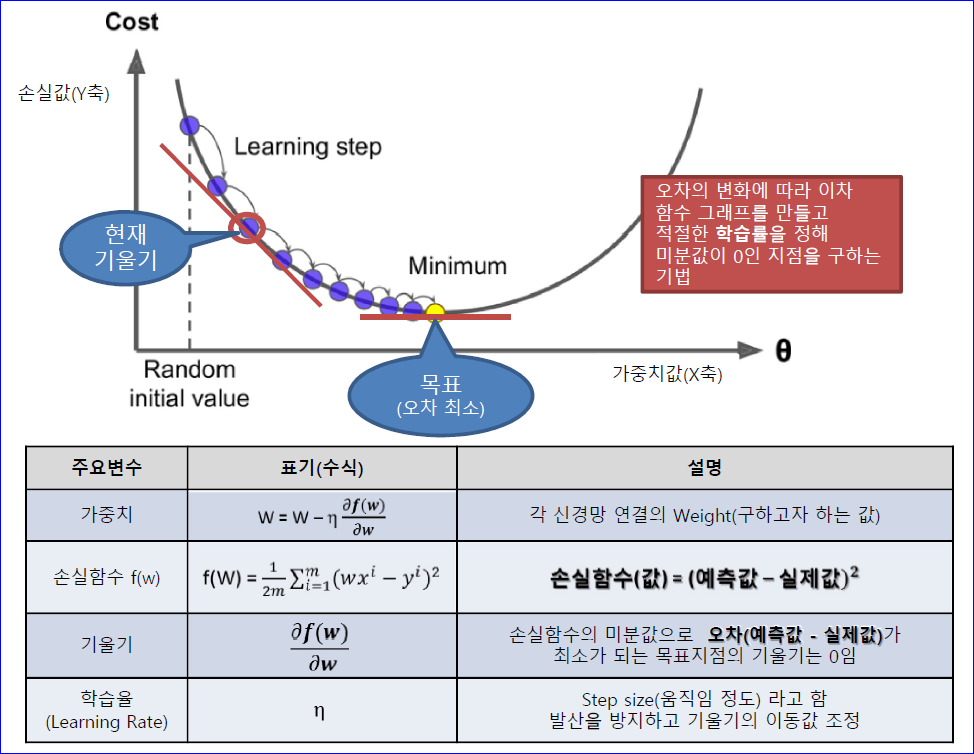
경사하강법(Gradient Descent)
최적화 알고리즘의 일종으로, 손실 함수의 값을 최소화하기 위해 사용된다.
기울기(gradient)를 사용해 손실함수의 값을 최소화하는 방향으로 매개변수를 업데이트 한다.
-
기울기를 계산해 기울기의 반대방향으로 파라미터를 이동시켜 손실함수의 값을 최소화한다.
-
기울기 : 현재 위치에서 손실함수의 변화율. 기울기 반대방향으로 이동하면 손실함수의 값이 최소화된다.
-
학습률 : Learning Rate. 모델의 파라미터를 업데이트할 때 한번에 이동하는 크기를 결정하는 하이퍼 파라미터. 매개변수를 얼마나 빠르게 최적값으로 수렴시킬 지를 조절한다. 학습률이 너무 크면 최소값을 놓칠 수 있고, 너무 작으면 학습 연산이 늘어나 시간이 길어질 수 있으므로 적절한 크기로 설정해야한다.
-
일차 미분한 값만 사용하고, 반복적으로 최적화해서 local minimum을 찾는게 목적인 방법이다.
Optimization의 용어
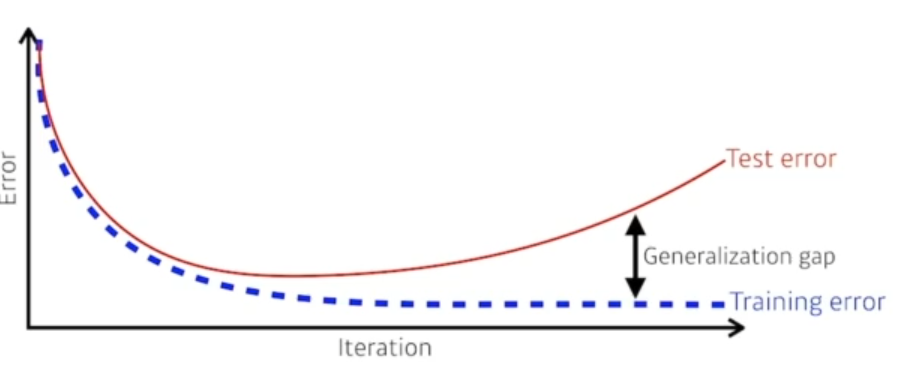
- Generalization(일반화)
머신 러닝 모델이 훈련 데이터 외의 새로운 데이터에 대해 얼마나 잘 예측하는지를 나타내는 능력
일반화가 잘 된 모델은 테스트 데이터와 실제 데이터 모두 성능이 좋다.
-
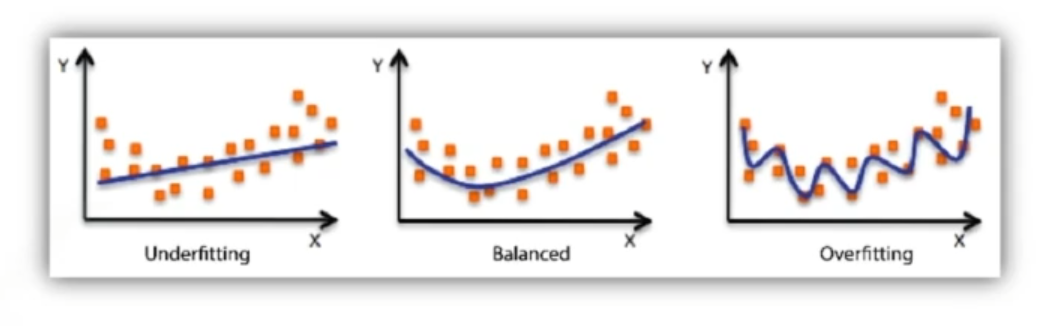
Under-fitting
모델이 훈련 데이터의 패턴을 충분히 학습하지 못하는 상황.
모델이 너무 단순해서 데이터의 복잡한 관계를 포착하지 못할 때 발생한다.
훈련 데이터도 제대로 안 맞는 상황 -
Over-fitting
모델이 훈련 데이터에 너무 맞춰져서, 훈련 데이터의 잡음이나 세부 사항까지 학습하는 상황.
모델이 훈련 데이터에서는 높은 성능을 보이지만, 새로운 데이터에 대해서는 일반화 성능이 떨어진다. 즉, 학습 데이터에만 잘 맞는 상황
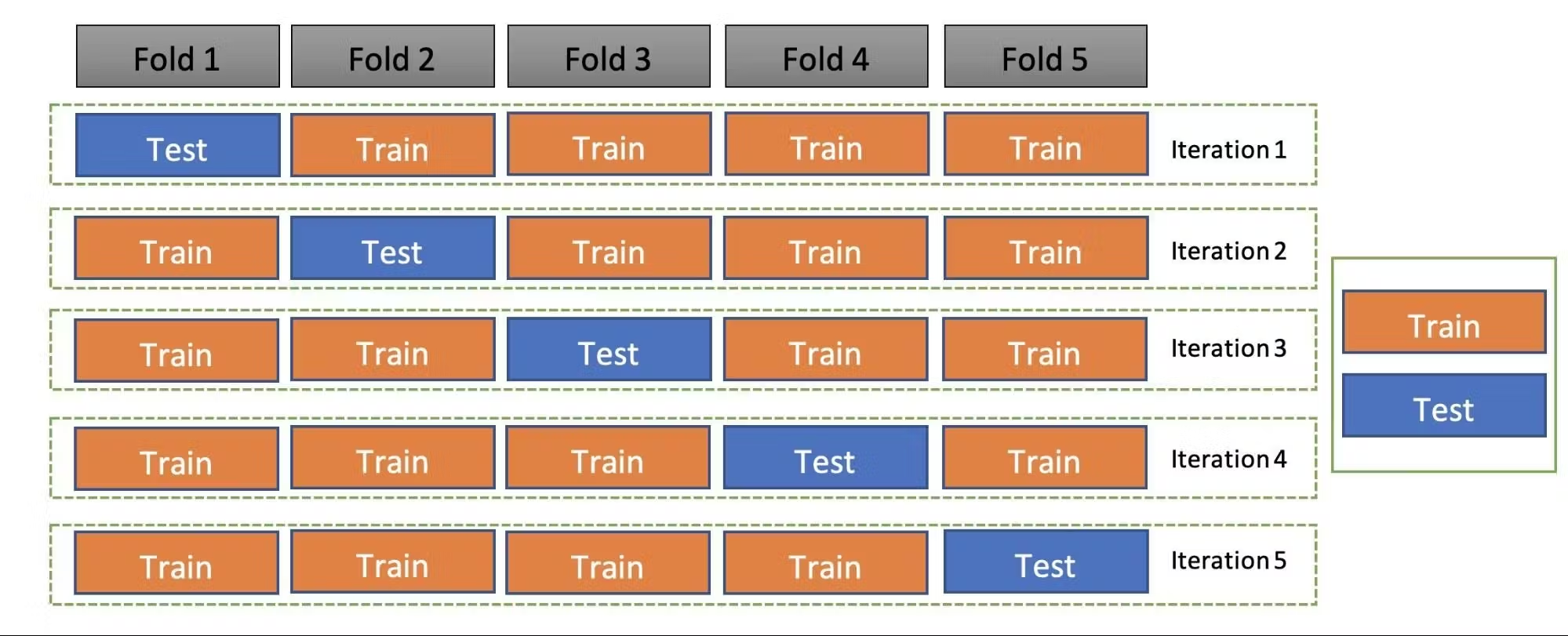
- Cross Validation(교차검증)
데이터를 여러 개의 폴드로 나누어, 각 폴드에 대해 번갈아가며 훈련과 테스트를 수행하는 방법
일반적으로 k개로 나누는 k-폴드 방식을 사용한다.
모델의 일반화 성능을 더 신뢰성 있게 평가할 수 있다.
-
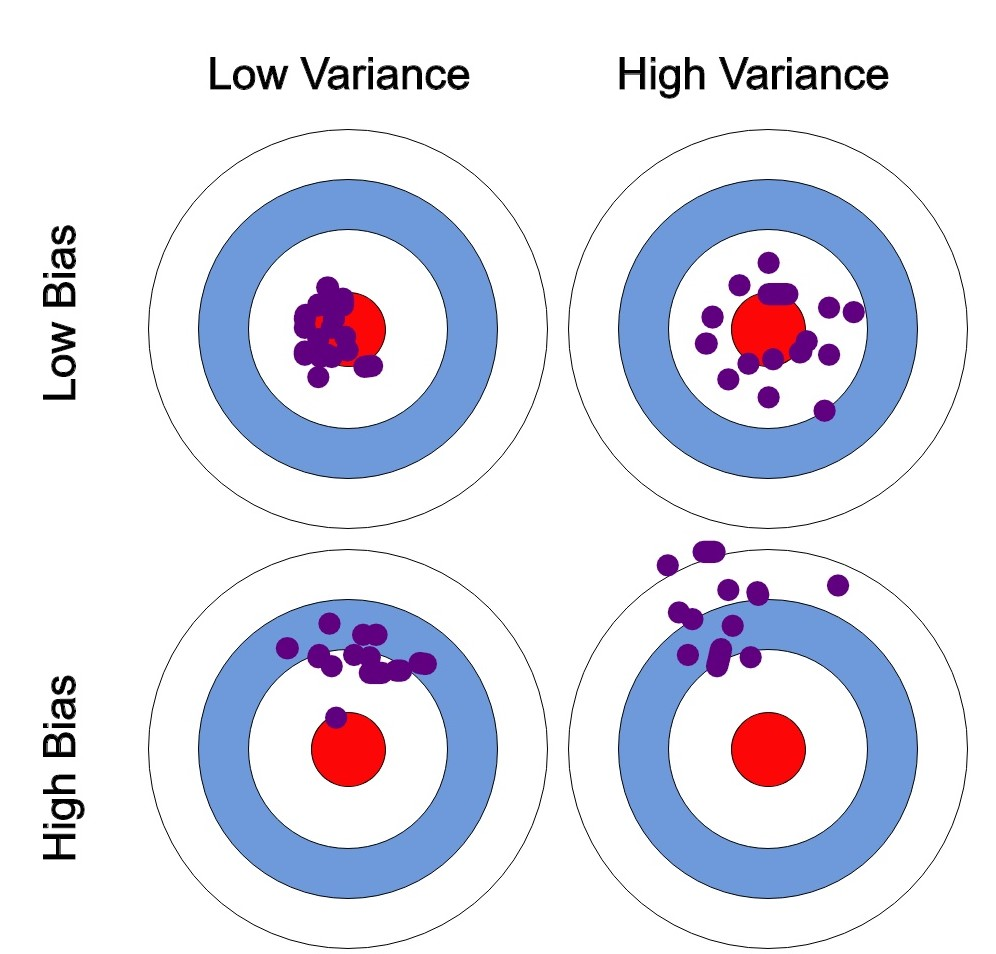
Bias-Variance Tradeoff
Bias는 모델이 데이터의 실제 패턴을 잘못 추정하는 경향으로 주로 under-fitting의 원인이다.
mean(기대값)과 많이 벗어난 정도를 말한다.
Variance는 모델이 훈련 데이터의 잡음까지 학습하여 예측이 훈련 데이터에 과도하게 맞춰지는 경향으로 주로 over-fitting의 원인이다.
학습 데이터에 noise가 끼게 되면 bias^2, variance는 서로 하나가 줄면 하나가 늘어나는 trade-off 관계가 된다. -
Bootstrapping
데이터를 샘플링하여 여러 개의 훈련 데이터를 생성하는 방법
원본 데이터에서 중복을 허용하여 샘플링된다. -
Bagging(Bootstrap Aggregating)
여러 모델을병렬적(독립적)으로훈련시켜 예측 결과를 평균내거나 투표하여 최종 예측을 만드는 방법
각 모델은 원본 데이터에서 Bootstrapping을 통해 생성된 데이터로 훈련된다. -
Boosting
여러 약한 모델을순차적(sequential)으로 훈련시켜 예측 모델을 만드는 방법
여러개의 weak-learner로 한개의 strong-learner를 만든다.
각 모델은 이전 모델이 잘못 예측한 데이터 포인트에 가중치를 부여하여 훈련된다.
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
