Today I Learned
오늘 배운 내용은 Sequential 데이터를 처리하는 다른 모델인 Transformer!
-
Sequential 데이터의 문제점
끝이 잘리거나, 생략되거나, 순서가 섞이거나, 밀리는 데이터들을 처리해야 한다. -
이런 문제를 해결하기 위해서
Attention is All You Need(2017)논문에서 Transformer구조가 등장했다.
Transformer
Sequential 데이터를 다루는 방법론으로 RNN, LSTM과는 다른 구조로 처리한다.
-
RNN과 다르게 재귀적인 구조가 없다.
-
주로 NLP(자연어 처리)분야에서 활용되지만 다른 영역에서도 활용된다.
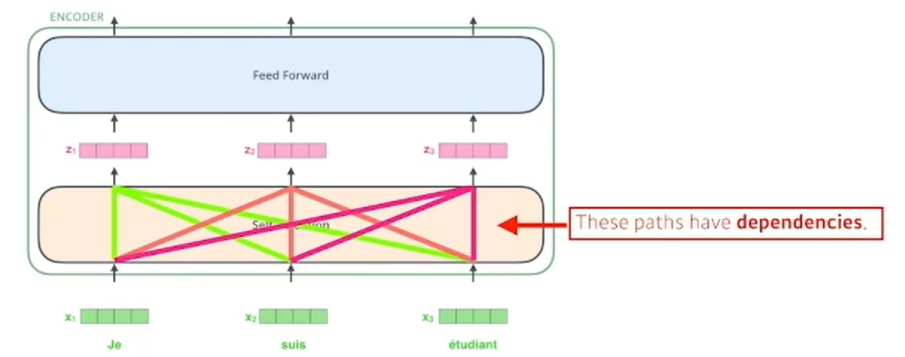
-
N개의 x벡터가 주어지면 Self-Attention에서 N개의 벡터가 모두 다 한번에 고려된다. 서로 dependency를 가진다.
-
Transformer 구조 구현 시, Huggingface 라이브러리를 많이 사용한다.
Transformer의 구성 요소
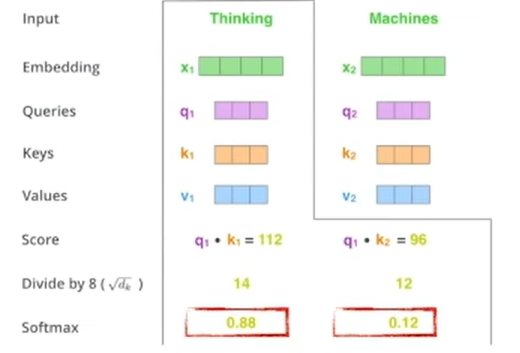
Self-Attention
-
입력 시퀀스의 각 단어가 다른 모든 단어와의 상호 작용을 계산하는 메커니즘
-
한 문장은 단어끼리 서로간의 관계가 중요하다.
-
여기서 Q, K, V의 세가지 행렬(벡터)를 사용하는데, 각 단어에 대한 Query, Key, Value를 나타낸다. QKV는 단어간의 상호작용을 계산(score)하는데 사용되며 이를 통해서 단어간의 관계를 이해하고 문맥을 파악할 수 있다.
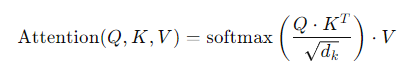
- 쿼리 행렬과 키 행렬 간의 내적을 계산한 후 점곱 결과를 키 벡터의 차원 수의 제곱근으로 나누어 스케일링하고, 이 값을 softmax 함수를 통해 정규화한다. 이렇게 얻은 가중치를 값 행렬V와 곱하여 각 단어의 출력을 계산한다. 이러한 과정을 모든 단어에 대해 반복하여 모든 단어의 출력을 얻는다.
Transformer Block
-
트랜스포머 블록은 여러 개의 Self-Attention 레이어와 피드포워드 신경망(feedforward neural network)으로 구성된다.
-
각 레이어는 잔차 연결과 layer normalization가 적용되어 있다.
Position Embedding
-
Transformer는 입력 시퀀스의 단어들의 상대적 위치 정보를 학습하기 위해 포지션 임베딩을 사용한다.
-
이를 통해 모델은 단어의 위치를 인식하고 시퀀스의 순서 정보를 고려할 수 있다.
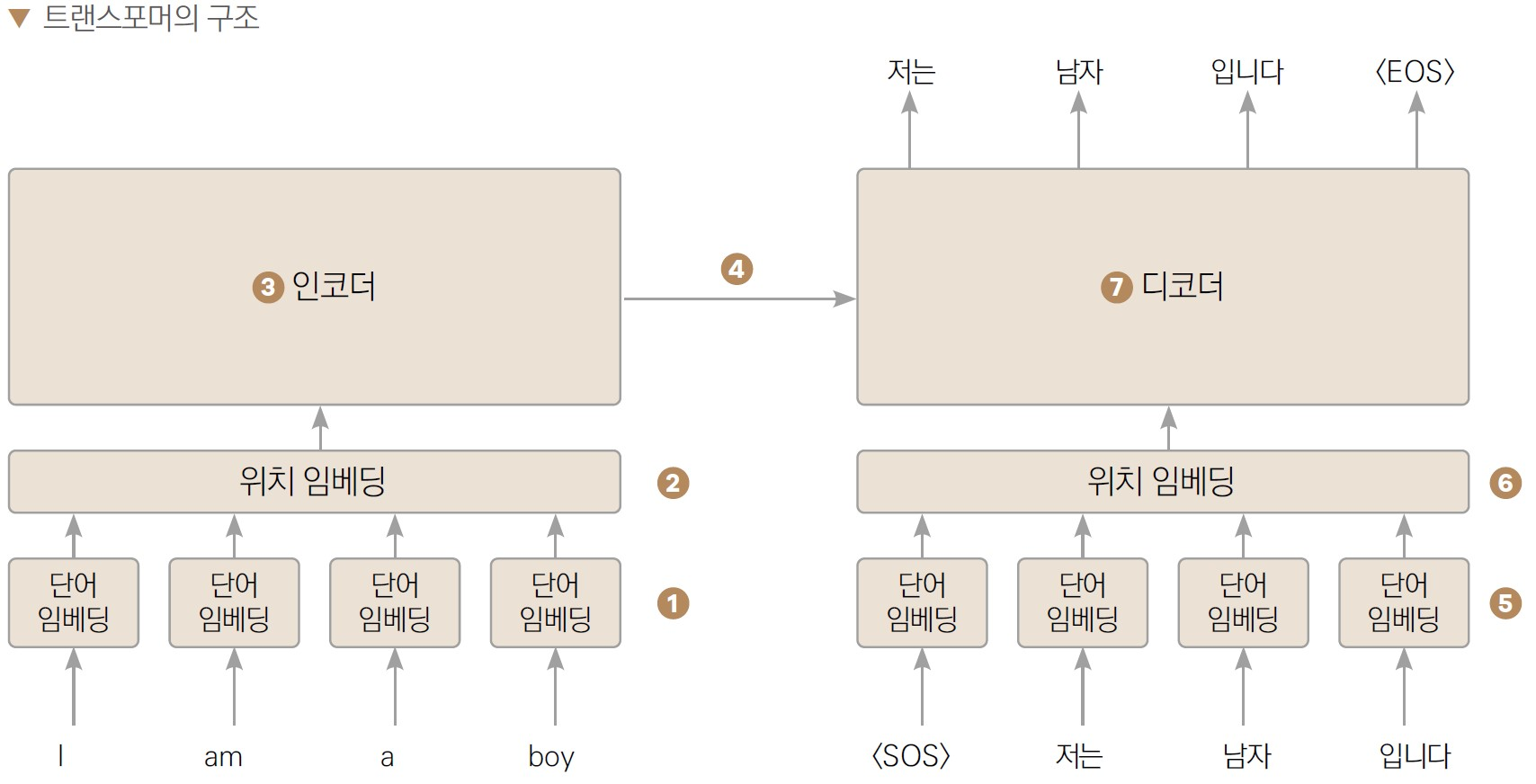
Encoder-Decoder 구조
-
Encoder
입력 시퀀스의 각 단어는 임베딩되고 포지션 임베딩이 추가된 후, 여러 개의 트랜스포머 블록을 거쳐 인코딩된다. 이 과정에서 자기 어텐션 메커니즘을 통해 각 단어는 다른 모든 단어와의 상호 작용을 계산한다. -
Decoder
디코더는 인코더의 출력을 입력으로 받아 디코딩한다. 디코더는 인코더와 동일한 구조를 가지지만, 추가적으로 다음 단어를 예측하기 위한 출력 레이어가 있다. -
Output Generation
디코더의 출력 레이어를 통해 다음 단어의 확률 분포가 생성되고, 이를 통해 다음 단어를 선택하여 시퀀스를 생성하는데, 이 과정은 토큰 단위로 반복된다.
Transformer 구조의 활용
-
Vision Transformer
Transformer 구조를 NLP가 아니라 이미지 인식 작업에 적용한 것
Transformer 인코더와 포지셔널 인코딩 사용 -
DALL-E
Transformer 구조의 디코더를 사용. Transformer는 자기 어텐션 메커니즘을 통해 입력 데이터의 상호 관계를 학습하는데, 이를 통해 텍스트와 이미지 간의 연관성을 모델링한다.
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
