Today I Learned
오늘은 온보딩 2일차 pandas에 대해 공부했다!
Pandas
구조화된 데이터 처리를 지원하는 Python 라이브러리
-
Numpy와 통합해서 강력한 스프레드 시트 처리 기능을 제공한다.
-
인덱싱, 연산용, 전처리 함수 등을 제공하고, 데이터 처리 및 통계 분석을 위해 사용한다.
-
용어
Data Table, sample : 전체 데이터
attribute, field, feature, column : 열
instance, tuple, row : 행
data : 데이터 하나의 값
DataFrame : 데이터 테이블 전체를 포함하는 Object
Series : DataFrame중 하나의 column에 해당하는 데이터의 모음 Object -
import pandas as pd로 라이브러리 호출
데이터 로딩
-
pd.read_csv() : csv 타입 데이터 로드. 기존 데이터를 가져와서 데이터 프레임을 생성한다.
-
.columns = [컬럼명 리스트] : 컬럼명 지정
-
.head() : 첫 다섯줄 출력
import pandas as pd
data_url ='https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data' #Data URL
df_data = pd.read_csv(data_url,sep='\s+', header = None) #csv 타입 데이터 로드, separate는 빈공간으로 지정하고, Column은 없음
df_data.columns = ['CRIM','ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO' ,'B', 'LSTAT', 'MEDY'] # Column Header 이름 지정
df_data.head() # 첫 다섯줄 출력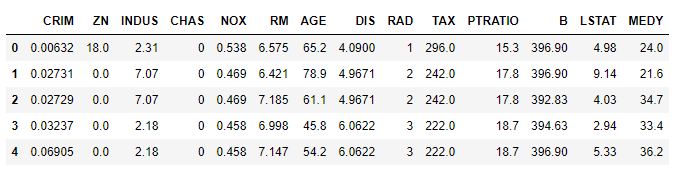
Series
Column Vector를 표현하는 Object
-
numpy의 ndarray의 서브클래스, 데이터는 어떤 타입이든 가능하다. Duplicate도 가능.
-
index값을 01234~가 아니라 abcde처럼 다르게 지정할 수 있다.
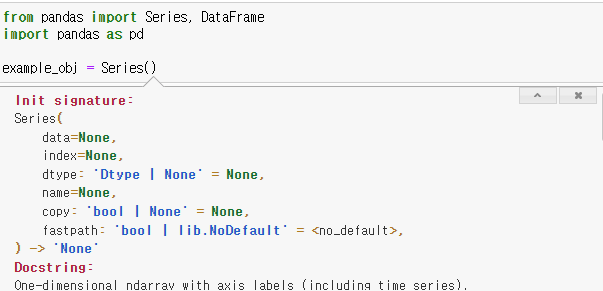
- 리스트 데이터를 Series로 변환시키는 예시
index 미입력시 01234~로 index 자동 생성
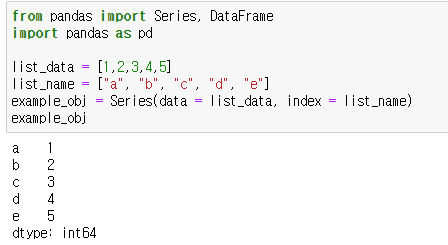
-
dict타입으로 index와 data를 같이 입력할 수 있다.
dtype으로 데이터 타입을 지정하고 name으로 series의 이름을 설정할 수 있다.
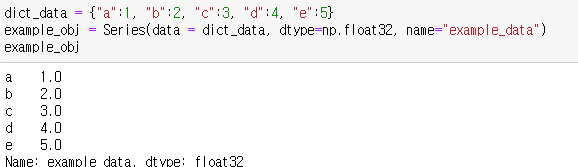
-
index를 이용해 바로 indexing으로 접근과 할당이 가능하다.
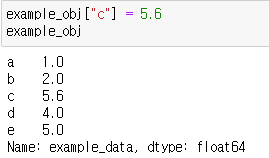
-
.values : 값 리스트만
.index : 인덱스 리스트만
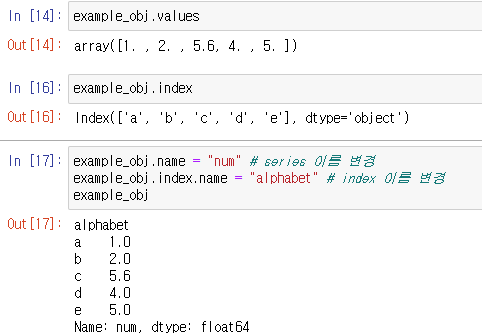
dataframe
데이터 테이블 전체를 포함하는 Object
Series를 모아서 만든 DataTable로 2차원이다.
-
Numpy의 array와 비슷하다.
-
column마다 다른 데이터 타입을 담을 수 있다.
-
하나의 데이터에 접근하려면 index와 column명 둘 다 알아야 접근할 수 있다.
-
DataFrame 생성
data를 dict형태로 넣되 value가 리스트.
(보통은 csv파일을 불러오기 때문에 이렇게 생성하는 경우는 거의 x)
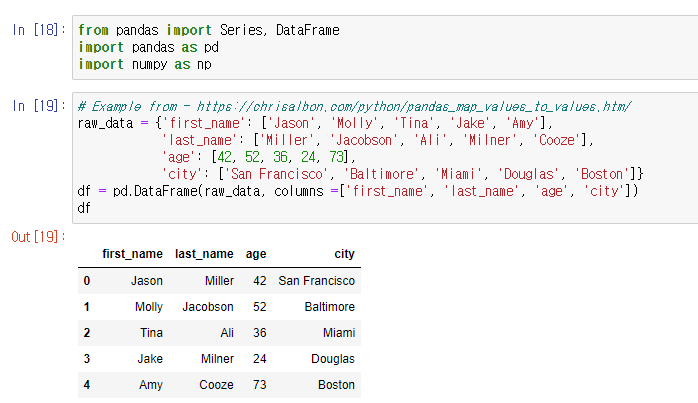
-
원하는 컬럼만 잘라서 만들 수 있다.
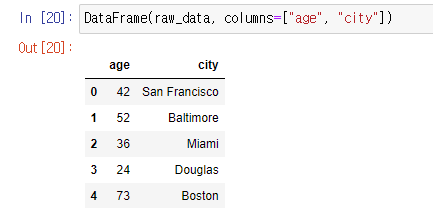
-
컬럼을 .컬럼명 이나 [컬럼명]으로 불러오면 series 타입으로 추출이 가능하다.
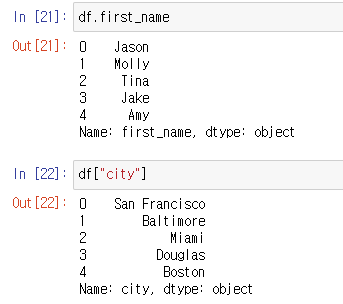
-
loc : 로케이션. 인덱스의 이름을 넣으면 해당 인덱스의 데이터를 속성별로 알려준다.
iloc : 인덱스가 0123~과 같은 일반적인 인덱스가 아니고 문자나 다른 형태일때 숫자를 입력하면 해당 숫자의 순서(0123~)에 맞는 값의 데이터를 알려준다.
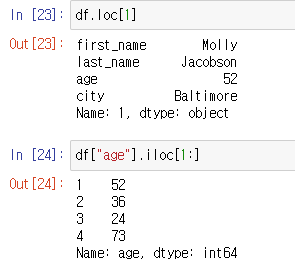
-
비교
부등호를 이용해 비교를 하면 boolean으로 값을 알려준다.
해당 결과를 컬럼에 바로 추가시킬 수도 있다.
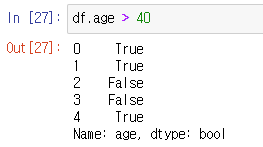
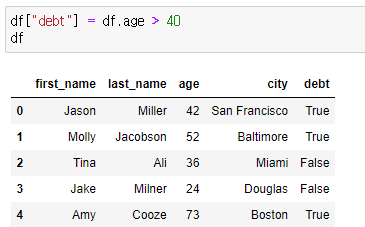
-
T : 행과 열을 바꿔서 보여준다.
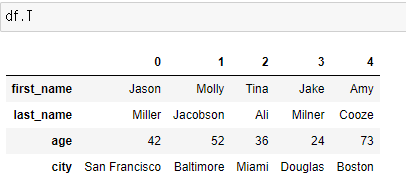
-
.to_csv() : csv로 변환시켜준다.

-
drop(컬럼명, axis=) : 컬럼을 없엔 결과물을 임시로 보여줌
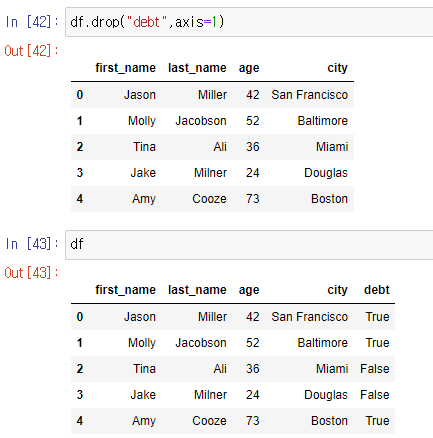
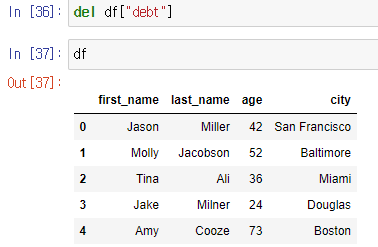
- del : 컬럼을 메모리에서 완전삭제