Today I Learned
오늘은 pandas 이어서!
Pandas
- 엑셀 파일을 다룰 때는 xlrd 모듈을 설치해야 한다.
!conda install --7 xlrd
Selection & Drop
-
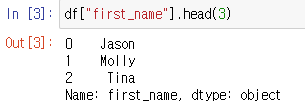
컬럼 1개만 선택 시 : .head(index) = Return the first
nrows.
head()만 사용시 기본적으로 첫 5개를 보여준다.
-
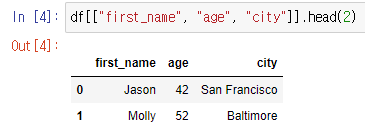
컬럼 여러개 선택 시 : 리스트를 입력.
-
series를 따로 변수에 저장해 indexing해서 볼 수 있고, 부등호를 이용해서 필터링할 수 있다.

-
.drop(n) : index n의 행을 제외해서 보여준다.
여러 행을 제외하려면 리스트로 입력한다.
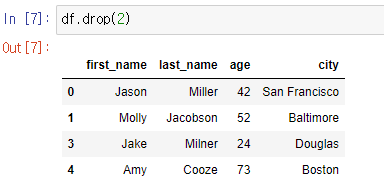
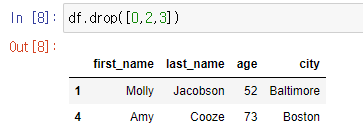
-
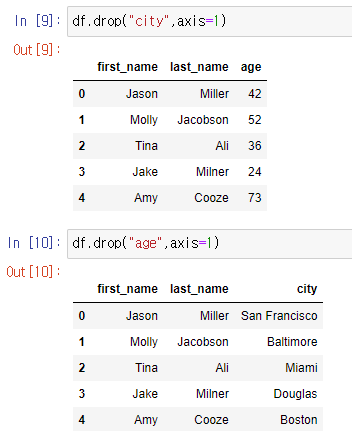
열을 제외할때는 axis=1을 추가한다.
DataFrame Operation
-
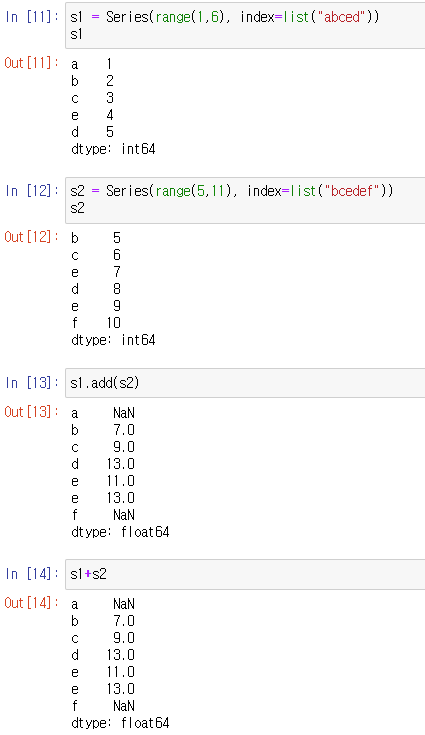
series operation
index를 기준으로 연산을 수행한다.
겹치는 index가 없으면 NaN값을 반환한다.
-
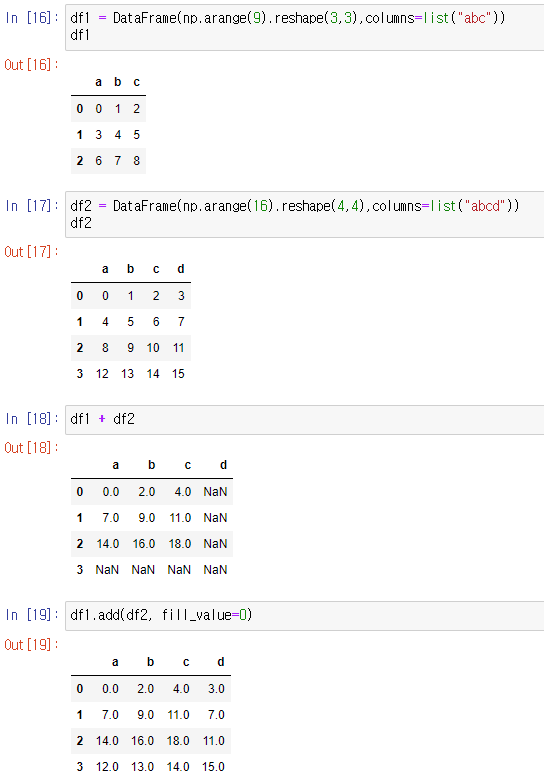
dataframe operation
df에선 column과 index를 모두 고려해 연산을 수행한다.
+같은 연산자를 사용하면 겹치는 index만 계산하고 안겹치면 NaN을 반환한다.
하지만 .add()에 파라미터로 fill_value=기본값 을 설정하면 기본값을 넣어 계산해 준다.
사칙연산 add, sub, div, mul 다 사용가능하다.
-
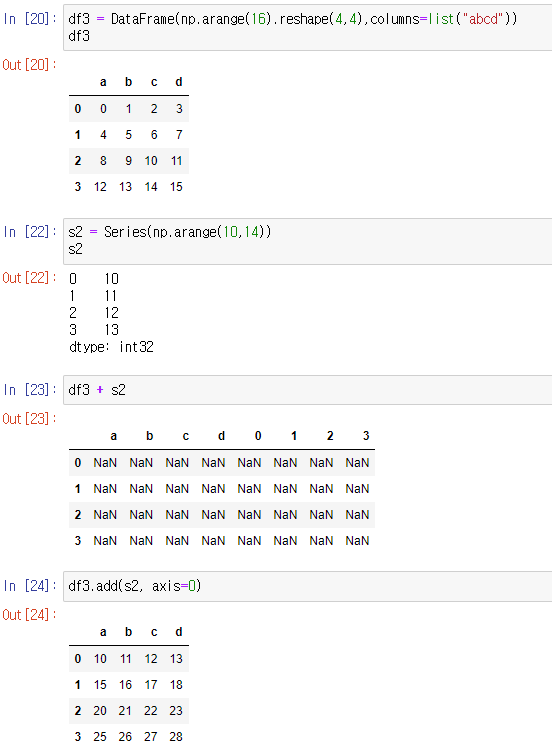
dataframe + series
데이터프레임에 시리즈를 더할때는 연산자를 사용하지 않고
add, sub, div, mul에 파라미터로 axis=0처럼 기준값을 설정해주면 된다.

Full-Stack Dev / MLOps