Today I Learned
오늘은 인공신경망과 역전파, 데이터 관리에 대해 공부했다.
강의 복습
- Linear Classifier의 단점
- 데이터가 선형적으로 구분 가능할 때만 잘 작동한다.
- 특성 간의 복잡한 상호작용을 모델링하지 못한다.
- 각 클래스당 하나의 템플릿만 학습할 수 있다.(말이면 말 앞모습만/ 뒷모습은 모른다)
- featurization
원본 데이터는 유지하면서 몇 가지 특징을 추출해 다른 좌표계(embedding space)로 연결해서 task를 수행하는 과정. 이 과정을 거친 데이터를 feature라 한다.
Neural Network
A neural network is a method in artificial intelligence that teaches computers to process data in a way that is inspired by the human brain.
 이미지 출처 : medium - Rukshan Pramoditha
이미지 출처 : medium - Rukshan Pramoditha
- Linear layer를 여러층 쌓아봐야 여전히 그 모델은 Linear하다.
따라서 각각의 layer가 끝나면 activation function을 적용해야 non-linear하게 만들 수 있다.
weights와 activation function을 번갈아 가면서 적용!
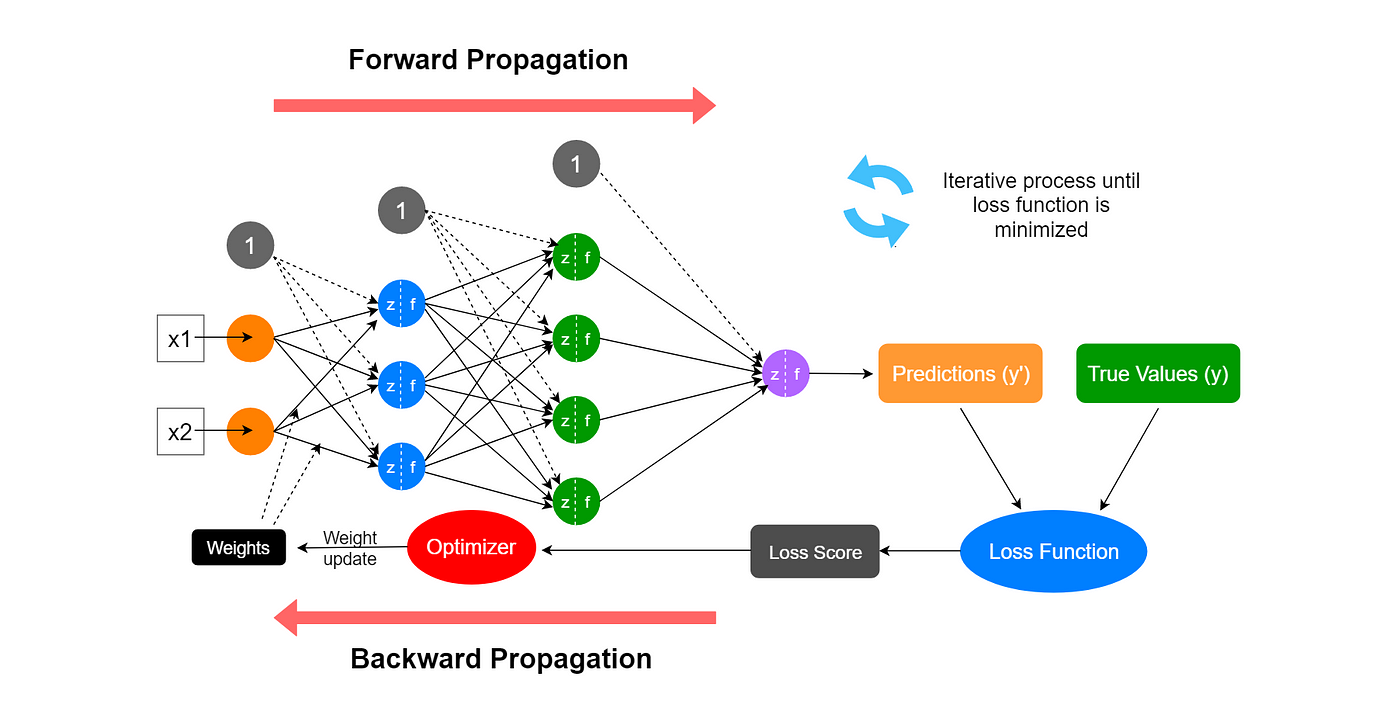
Backpropagation
주어진 입력에 대해 신경망이 출력한 결과와 실제 값(정답) 사이의 오차를 계산하고, 이 오차를 최소화하기 위해 가중치를 업데이트하는 방법
단계
- 순방향 전파(Forward Propagation)
입력 데이터가 신경망의 각 층을 통과하면서 계산되어 출력값을 생성.
각 층의 weight와 activation function이 적용된다. - 오차 계산
MSE나 CE같은 손실함수(loss funciton)를 이용해 예측값과 실제값의 차이(loss)를 계산.
- 역전파(Backpropagation)
신경망 각 층의 역방향으로 가면서 각 weight에 대한 오차의 기울기(gradient)를 계산한다.
체인 룰을 사용해 각 가중치가 손실함수에 미치는 영향을 계산한다. - 가중치 업데이트
계산된 기울기 값을 이용해 가중치를 업데이트 한다.
W(new) = W(old)−η⋅∇L(W) : η-학습률, ∇L-손실함수의 기울기
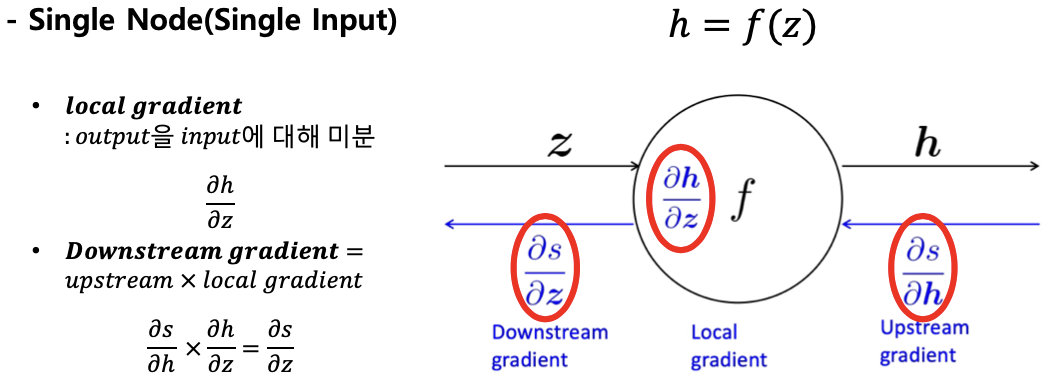
- chain rule
downstream gradient = upstream gradient x local gradient
 이미지 출처 : hera0131
이미지 출처 : hera0131
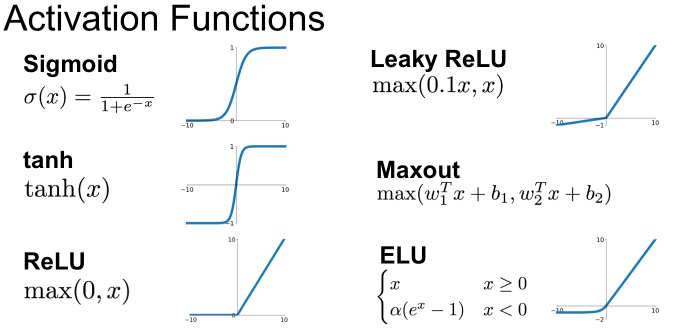
Activation Functions
 이미지 출처 : syj9700
이미지 출처 : syj9700
-
sigmoid
0~1 범위의 출력. 입력이 크거나 작으면 출력이 0이나 1에 가까워져 gradient가 0에 수렴하는 문제(Vanishing Gradient)로 인해 훈련이 잘 안되고, exp()연산의 비용이 큰 단점이 있다.
그리고 0이 아닌 0.5가 중심이라 입력이 양수면 upstream gradient 부호가 변하지 않으므로, gradient가 특정한 방향으로만 업데이트 되는 비효율적인 문제가 있다. -
tanh
-1~1 범위의 출력. sigmoid 특성과 비슷하되, 중심이 0에 가까워서 sigmoid보다 훈련 시 효율적이다. 하지만 Vanishing Gradient 문제는 여전히 있다. -
ReLU
max(0,x) Vanishing Gradient문제가 없고, 미분시 양수는 1, 음수는 0이라 연산이 효율적이다. 하지만 0 지점에서 미분이 불가능하고, 중심이 0이 아니고, 음수 입력에 대해 항상 0을 반환하여 "죽은 ReLU" 문제(dead ReLU)이 있다. -
Leaky ReLU
max(0.01x, x) ReLU에서 입력이 음수일때도 0이 아닌 약간의 기울기를 줘서 단점(dead ReLU)을 해결했다. 하지만 기울기가 적절하지 않으면 문제가 여전히 발생할 수 있다. -
ELU
이것 역시 ReLU의 단점을 해결한 것으로 음수지역에 robustness를 더했다. 하지만 exp() 연산의 비용이 큰 단점이 있다. -
실제 학습에서는 분류의 마지막 layer에서나 sigmoid, tanh같은걸 쓸 수도 있지, 학습단계에선 ReLU 류만 사용한다.
Weight Initialization
신경망의 weight을 학습 초기단계에 설정하는 방법
-
가중치가 너무 작거나 크면 역전파 과정에서 gradient가 사라지거나(vanishing) 폭발(exploding)해 학습이 제대로 되지 않는다. 그렇다고 모든 가중치를 동일하게 초기화하면 모든 뉴런이 동일하게 학습을 수행해 학습이 제대로 진행되지 않는다.
따라서 무작위로 가중치를 설정해야 한다. -
Small Gaussian Random
평균이 0, 분산이 아주 작은 가우시안 분포에서 무작위로 가중치를 초기화하는 방법
간단하게 쓸 수 있고, 얕은 신경망에선 효과적이다.
하지만 네트워크가 깊거나 입력 데이터의 분포가 복잡하면 성능이 좋지 않다.
깊어질수록 gradient가 0에 가까워져 학습이 잘 되지 않는다. -
Large Gaussian Random
초기 가중치가 상대적으로 큰 값을 가지게 하여, 네트워크가 학습을 시작할 때 각 층의 활성화 값이 크게 변동할 수 있도록한다.
하지만 큰 초기 가중치는 네트워크의 학습을 불안정하게 할 수 있다.
깊어질수록 gradient가 극단에 가까워져 exploding할 수 있다. -
Xavier Initialization
W = np.random.randn(dim_in, dim_out) / np.sqrt(dim_in)
가중치를 정규분포나 균등분포를 이용해 초기화한다.
랜덤값을 input 개수의 제곱근을 상수로 나눠버린다.
분포의 분산은 이전 층의 노드 개수나 다음 층의 노드 개수를 사용해 계산한다. -
실무에서는 pytorch의 initialization 방식을 사용하면 된다.
Learning Rate Scheduling
학습 과정에서 Learning Rate를 동적으로 조절하는 방법
-
학습률은 모델의 가중치를 업데이트할 때(optimization 과정) 사용되는 매개변수로 학습과정의 안정성과 수렴 속도에 영향을 끼친다.
-
너무 크면 loss가 오히려 커져서 optimal한 값에 수렴하지 못하거나 불안정할 수 있고, 너무 작으면 loss는 적어도 수렴 속도가 너무 느려진다.
-
learing rate decay : 처음에는 학습률을 크게 잡고, 점점 작게 낮추는 방법
-
실무에선 학습률 여러개를 설정해서 learning curve를 보고 insight를 잡아서 설정하면 된다. 그리고 첨엔 0에 가까운 값에서 시작해서 학습률을 올리다(warmup) saturate되면 학습률을 확 줄여서 계속 줄이는 방법도 있다.
데이터 관리
Data Preprocessing
원본 데이터가 학습에 적합하지 않을 때 모델의 성능과 학습 효율성을 높이기 위해 데이터를 전처리 하는 과정.
- zero-centering / normalization
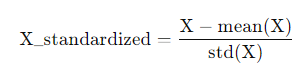
Gradient Descent의 효율성과 안정성을 위해 이 과정을 거친다.
데이터의 평균을 0으로 만들기 위해 데이터에서 평균값을 뺀다.(zero-centering)
그리고 정규화를 위해 std(표준편차)로 데이터를 나눈다.
이렇게하면 weight의 작은 변화에 덜 민감해진다.
import numpy as np
x_train -= np.mean(x_train, axis=0)
x_train /= np.std(x_train, axis=0)- PCA
고차원 데이터를 저차원으로 압축하는 방법. 주요 특성은 보존하면서 차원을 줄인다.
분산이 제일 긴 축을 중심으로 rotate하고 분산으로 나눠서 정규화 시킨다.
Data Augmentation
데이터셋의 양이 적을 때 기존 데이터를 이용해 인위적으로 데이터를 늘리는 기법
-
훈련 데이터의 다양성을 높이면서 일반화 능력을 향상시켜 과적합을 방지한다.
-
데이터만 변형시키고 classifier는 불변해야한다.
-
이미지 데이터는 회전, 크롭, 스케일링(확대or축소), 플립(수평만), 왜곡(보정), 노이즈 추가 등이 있다.
-
텍스트 데이터는 동의어 교체, 문장 순서 변경, 번역후 역번역, gpt로 문장 생성 등이 있다.
-
시계열데이터는 시간이동, 스무딩, 노이즈 추가 등이 있다.
-
pytorch의 torchvision.transforms 모듈이나 Keras의 ImageDataGenerator 클래스 같은 라이브러리를 사용해 Data Augmentation를 할 수 있다.
-
Translation Invariance
입력 데이터의 위치변화(픽셀 이동 등)가 있어도 출력이 일관적인 특성.
과제
- 과제 1에서 데이터에 발생한 오류에 대해 토의했다.
데이터상에 11열짜리 데이터가 21열까지 있어 어떤 코드로 가져오느냐에 따라 결과가 달라졌다.
이 내용은 내일 오류 수정이 되면 다시 토의해볼 예정
# 열을 11열까지만 불러와서 해결하는 코드
dataset = pd.read_csv("2018_2019_2020.csv", usecols=range(11))
# 형식이 일치하지 않는 잘못된 행을 건너뛰는 코드
dataset = pd.read_csv("2018_2019_2020.csv", on_bad_lines='skip')피어세션
- google colab에서 T4 GPU나 TPU를 사용해서 램을 늘려 연산 시간을 줄일 수 있다.
- 위 코드보다 아래코드가 결과는 같은데 더 빠르다?
for i in range(len(X_test)):
plt.plot([X_test[i], X_test[i]], [y_test[i], predictions[i]], color='gray', linestyle='--', linewidth=0.5)
plt.vlines(X_test, y_test, predictions, color='gray', linestyle='--', linewidth=0.5)회고
- 내용이 점점 어려워지고 있다. 진도 나가는 속도는 빠른데 아직 흡수하긴 모자란 느낌.
좀 더 집중하고 복습해서 익혀야겠다.
