Today I Learned
오늘 배운 내용은 transformer 구조!
강의 복습
RNN
Recurrent Neural Network. 순서가 중요한 시퀀스 데이터를 처리하는 순환 구조의 신경망
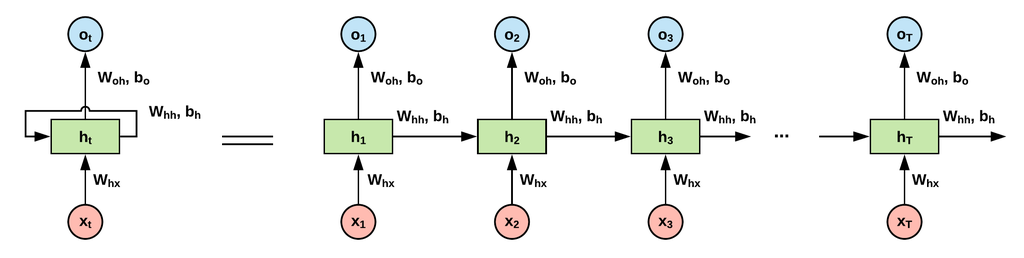 이미지 출처 : @yuns_u
이미지 출처 : @yuns_u
-
순환구조
이전 단계의 출력이 다음 단계의 입력으로 사용된다.
RNN은 입력 데이터와 출력을 처리하는 동시에 상태를 기억한다.
모든 단계에서 W(weight)가 동일하며, h_t는 이전의 모든 단계의 정보를 기억한다. -
순환구조라서 병렬화가 힘들고 계산에 비용이 많이 든다.
-
기본 RNN은 역전파 과정에서 gradient 문제와 Short-term dependencies 문제가 있다.
-
many-to-many에서 1:1 관계를 가정하기 때문에 언어의 경우 서순이 다르거나 문장 길이(단어 수)가 다르면 RNN을 적용할 수 없다.
-
자세한 내용은 이전에 써뒀던 TIL #421참고
-
모든 단계에서 W가 같기 때문에 t가 커지면 역전파 과정에서 W>1이면 gradient가 exploding하고, W<1이면 gradient가 vanishing 하는 문제가 발생한다.
-> 따라서 deep하게 layer depth를 쌓을 수가 없다!
LSTM
RNN의 gradient와 Short-term dependencies 문제를 해결하기 위해 나온 방법
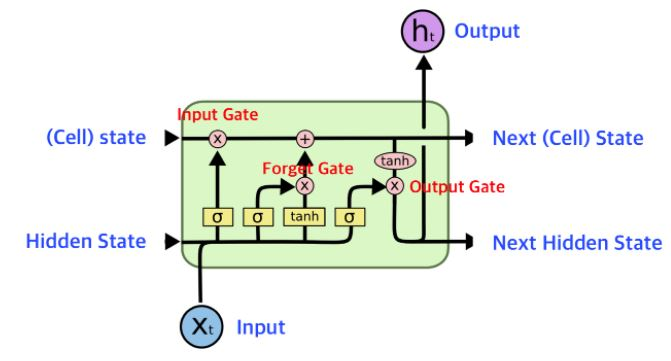
이미지 출처 : wikidocs
-
역전파 과정에서 FC(Fully-connected, W를 지나는 곳)를 거치지 않기 위해 Cell state를 추가함. Cell state는 long-term 장기 기억을 처리하는 역할을 한다.
-
Forget Gate : 기억 셀에서 기존의 정보를 얼마나 삭제할지를 결정
Input Gate : 현재 입력과 이전의 상태를 기반으로, 현재 정보를 얼마나 기억할지를 결정
Output Gate : 기억 셀의 상태를 기반으로 최종 출력(h_t)을 결정 -
기본 RNN보다 long-range 데이터를 잘 처리할 수 있고, 어느정도 gradient 문제를 해결했다. 하지만 완전히 해결은 x.
GRU
-
LSTM에서 cell state를 배제한 모델.
-
PyTorch에선 위의 모델들을 nn.LSTM처럼 nn 모델로 쉽게 사용할 수 있다.
요즘엔 기본 RNN은 거의 안쓰고 RNN을 썼다 하더라도 LSTM이나 GRU 모델로 쓴다.
seq2seq
Sequence-to-Sequence. 시퀀스 데이터를 입력으로 받아 다른 시퀀스를 출력으로 생성하는 모델. RNN을 기반으로 인코더와 디코더를 가진 모델이다.
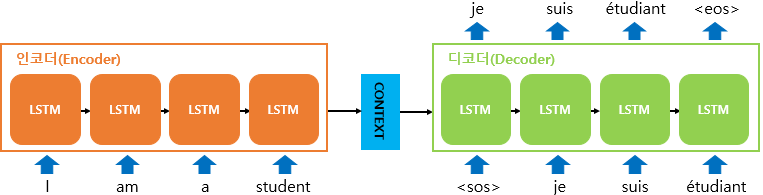 이미지 출처 : wikidocs
이미지 출처 : wikidocs
-
인코더와 디코더 모두 RNN, LSTM, GRU 같은 순환 신경망으로 구성된다.
-
인코더
입력 시퀀스의 각 요소가 인코더에 주어지고, 이를 받아서 hidden state를 각 단계에서 계속 업데이트 한다.
시퀀스의 마지막 요소가 처리되면, 인코더는 전체 시퀀스의 의미를 압축(many-to-one)한 벡터(hidden state)를 최종적으로 생성한다.
-
디코더
인코더의 출력 벡터를 입력으로 받아 한 단계씩 출력 시퀀스를 생성(one-to-many)한다.
이 과정에서 이전 출력을 입력으로 사용한다.(auto-regressive)
출력은 일반적으로 softmax 함수로 확률 분포로 변환된다. -
teacher forcing
훈련과정에서는 디코더의 학습을 안정화 하기 위해 디코더의 예측값을 다음 디코더의 입력값으로 넣지 않고, 실제 값(정답)을 디코더의 다음 값으로 넣는다.
참고 사이트 : wikidocs
Attention
RNN의 고질적 문제인 vanishing gradient가 남아있고, LSTM,GRU는 긴 시퀀스 처리에 문제가 있고, seq2seq은 하나의 고정된 크기의 벡터에 정보를 압축하면서 정보 손실이 발생하는 문제가 있다. 즉, 입력이 길어질 수록 출력 품질이 떨어진다.
이를 해결하기 위해 나온 것이 Attention Mechanism
-
디코더에서 출력을 예측하는 매 시점마다 연관있는 입력에 더 집중(attention)해서 참고해 예측을 하는 방식.
-
기본적으로 seq2seq과 구조는 비슷하지만, 디코더에서 인코더에 있는 모든 hidden state 참고할 수 있고, 같은 비중이 아니라 연관성 높은 h를 더 집중해서 본다.
Attention 함수
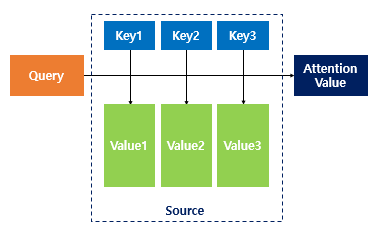 이미지 출처 : wikidocs
이미지 출처 : wikidocs
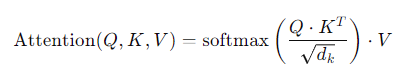
Attention(Q,K,V) = Attention 값
Q = Query : t 시점의 디코더의 hidden states.
현재 관심이 있는 요소. 정보를 얻고자 하는 대상. ex) 현재 번역하고있는 단어
K = Keys : 모든 시점의 인코더의 hidden states
쿼리가 어떤 값을 참조할지 결정하는 index. 각 단어에 대해 생성. 쿼리와 키의 유사도를 계산
V = Values : 모든 시점의 인코더의 hidden states
실제로 가져올 정보. 원본 값의 벡터. 쿼리와 관련된 키에 따라 선택.
Attention value : 인코더 hidden states의 가중치 평균. 즉 V의 가중합 결과
-
Q와 K는 dim이 같아야하고, V는 Attention value와 dim이 같아야 한다.
-
쿼리 행렬과 키 행렬 간의 유사도를 측정한 후(내적으로 계산) 키 벡터의 차원 수의 제곱근으로 나누어 스케일링하고, 이 값을 softmax 함수를 적용해 가중치를 계산한다. 이렇게 얻은 가중치를 값 행렬V와 곱하여 가중합을 계산(Attention value)한다. 이러한 과정을 모든 단어에 대해 end 토큰이 출력될 때까지 반복하여 최종 출력을 얻는다.
-
RNN의 장기 의존성 문제를 해결했고, 시퀀스를 순서대로 처리할 필요가 없어 동시에 병렬처리할 수 있고, 다양한 입력길이와 구조에 적응할 수 있다. 그리고 가중치를 attention map으로 나타내서 모델이 어떤 요소에 주목하는 지 시각화할 수 있다.
-
하지만 복잡하고, 계산 비용이 크고(최대 O(n^2)), 메모리 사용량이 많은 단점이 있다.
Transformers
NLP와 시퀀스 데이터 처리에 사용되는 딥러닝 모델
RNN을 사용하지 않고 어텐션만으로 인코더-디코더 구조를 설계한다.
2017년 "Attention is All You Need" 논문에서 처음 소개되었다.
-
기본적으로 단어만 1대1 매칭으로 보지 않고, input은 주위의 요소와 서로 유기적으로 연결되어있다고 가정한다.
-
자세한 내용은 기존에 정리한 TIL #422참고
-
input 단어를 임베딩 해서 input token={x1,x2,...,xn}이 주어지면 각 xi값은 linear transfromation에 의해 Wq, Wk, Wv(learned parameter)를 곱해서 Qi, Ki, Vi로 매핑된다.
-
그 다름 Qi와 Ki를 내적(dot product)해서 유사도를 구하고, 이 값을 Vi와 곱하고 그 값들을 다 더하면 가중합이 나온다. 이 값을 Wo와 곱해(linear transfromation) Zi를 출력한다.
Zi를 구할때는 모든 Vi들이 Wo와 곱해져서 가중합으로 반영된다. -
transformer 모델은 transformer block을 여러번 적용해서 정확도를 높일 수 있다.
Token Aggregation
-
기본 transformer 모델은 출력 값도 입력 값처럼 시퀀스 데이터다.
그래서 이 모델을 분류나 회귀문제에 사용하려면 Token Aggregation을 사용한다. -
transformer block 연산 후 나온 zi 값을 평균내서 z로 만든다.
그리고 이 z값을 input으로 받는 classifier나 regressor를 넣어주면 분류, 회귀문제에 사용할 수 있다. -
시퀀스가 길지 않을때는 평균이 효과적이다.
-
다른 방법으로는 CLS라는 아무 값이 없는 더미 토큰을 transformer의 입력값으로 넣어서 이 값의 출력값을 평균 대신 모든 문장을 대표하는 역할로 사용한다.
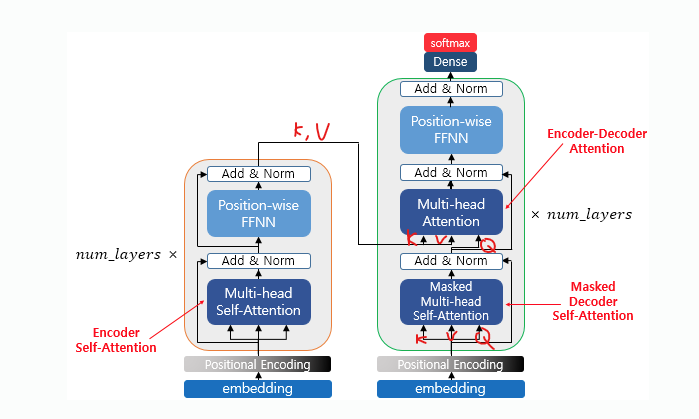
이미지 출처 : wikidocs
Encoder
positional encoding
Transformer는 RNN과 달리 토큰 시퀀스의 순서에 대한 정보를 내제적으로 갖고 있지 않기 때문에 이 과정을 통해서 각 토큰의 순서 정보를 모델에 전달한다.
사인-코사인 함수를 기반으로 위치 인코딩을 하는 방법이 있다.
multi-head self attention
-
단일 self attention을 사용하는 것보다 파라미터의 수도 늘고 연산 비용도 늘어난다.
-
하지만 단일 Self-Attention 헤드는 입력 시퀀스의 특정 측면만을 포착할 수 있기 때문에 multi-head를 사용한다.
-
self attention 메커니즘을 여러개의 헤드로 나누어 동시에 수행한다.
각 헤드는 서로 다른 sub space에서 정보를 학습해 다양한 문맥적 관계를 포착한다. -
Xi 하나 당 Qi , Ki, Vi를 임의의 head 갯수만큼 만들어 self-attention을 수행한다.
최종 적으로 나온 Zi들을 concat해서 붙이고 Wo로 linear transform해서 Z로 만들면 끝.
Feed-Forward Layer
이렇게 나온 Z를 Feed-Forward Layer라는 FC(fully connected) layer를 통과시켜 Z'로 변환 시켜서 설명력을 조금 더 높일 수 있다.
Decoder
Masked Multi-Head self Attention
-
시퀀스의 다음 단어를 예측하는 과정에서, 모델이 현재 예측해야 할 위치 이후의 단어를 보지 못하도록 막는(마스킹) 역할
-
마스킹은 decoder의 제일 첫 단에만 적용한다.
-
디코더가 각 위치에서 다음 토큰을 예측하는데 미래의 토큰정보를 미리 알게되면 학습과정에서 부정확한 정보를 활용할 수 있으므로 가린다. 미래 토큰의 가중치를 무한대 음수로 설정해 softmax 후 0이 되게 만들어 참조되지 않게 한다.
-
Masked Multi-Head Attention 다음 단의 Multi-Head Attention의 key와 value는 encoder의 key value를 사용한다. query는 decoder에서 나온 것.
그 외
-
transformer block을 여러번 거친 후 linear와 softmax layer를 거치면 최종 output이 된다. softmax를 거치면 0~1 사이의 확률 분포가 된다. 최종 output vector의 합이 1이된다.
-
디코딩은 EOS(end of sentence) 토큰이 나올 때 까지 반복한다.
-
Feed-Forward Layer, Positional Encodeing은 Encoder와 같다.
Vision Transformer(ViT)
CV 분야에서 CNN 대신에 Transformer를 사용해 이미지를 처리하는 방식.
-
토큰 대신 이미지를 특정 크기(ex.16x16)의 패치로 분할해서 트랜스포머에 넣어 처리하도록 한다.
-
단점은 Transformer가 기본적으로 파라미터 수가 많기 때문에 비용이 많이 든다.
-
극단적으로 큰 dataset에서만 잘 작동한다.
-
여기서도 위치 정보가 없기 때문에 posisional embedding이 필요하다.
BERT
2018년 구글에서 발표한 사전 학습된 NLP 모델
-
Transformer 모델의 Encoder 부분만 사용한다.
Self-Attention 메커니즘을 활용해 문장 내에서 단어간의 관계를 효과적으로 학습한다. -
human rating 없이 Self-Supervised Learning이 가능하다.
-
텍스트의 양방향(Bidirectional) 문맥을 학습할 수 있다.
일반적으로는 -> 한 방향으로만 처리하는데 BERT는 모든 단어가 앞뒤의 모든 단어를 참조한다. -
Masked Language Model (MLM)
입력 문장의 일부 단어를 임의로 마스킹하고, 그 마스킹된 단어를 예측하는 방식으로 학습한다. -
Next Sentence Prediction (NSP)
두 문장이 주어졌을 때, 두 번째 문장이 첫 번째 문장에 이어지는지(연속적인 문장인지)를 예측한다. 이 과정으로 문장 간의 관계를 학습한다. MLM보단 덜 중요하다.
피어세션
- 트랜스포머에선 입력된 단어들을 벡터로 변환하기 위해, 일반적으로 단어 임베딩 테이블을 사용한다. 학습 가능한 매개변수로 구성되어 있으며, 각 단어에 대해 고정된 차원의 벡터를 제공한다.
pytorch.nn.Embedding 클래스 사용
import torch
import torch.nn as nn
# 임베딩 테이블 생성
num_embeddings = 10 # 어휘 크기 (단어의 총 개수)
embedding_dim = 4 # 임베딩 벡터의 차원
# nn.Embedding 생성
embedding = nn.Embedding(num_embeddings, embedding_dim)
# 입력 시퀀스: 각 숫자는 단어의 인덱스를 나타냄
input_indices = torch.tensor([1, 2, 3, 4])
# 인덱스를 임베딩 벡터로 변환
embedded = embedding(input_indices)
print(embedded)
회고
-
임베딩 Embedding
참고 사이트 : ibm - 임베딩
사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾼 결과 혹은 과정.
or
데이터의 중요 부분은 유지한 채 고차원 데이터를 저차원 공간으로 변환하여 표현하는 기법.
일종의 정보압축, 차원 축소. 비슷한 데이터 끼리는 임베딩 후 가깝게 위치하기 때문에 유사도 측정에도 사용된다. -
Attention부터 내용이 급격하게 어려워져서 Transformer 쪽은 이해를 잘 하지 못했다. 쉬는 동안 강의 복습하면서 제대로 이해하도록 해보자.
