Today I Learned
프로젝트 3 랩업리포트를 직접 작성했다.
Book Rating Prediction
https://github.com/boostcampaitech7/level2-bookratingprediction-recsys-06
프로젝트 구조
├── src # AI 모델 학습을 위한 부분
│ ├── data # data 처리를 위한 .py 모듈
│ ├── ensembles # 앙상블 처리를 위한 .py 모듈
│ ├── loss # loss 계산을 위한 .py 모듈
│ ├── model # DL & ML 모델
│ └── train # 학습 관련 .py모듈
├── data #.gitignore # 데이터 저장소
├── app.py # 모델 학습을 위한 python 파일
├── config-sample.yaml # 하이퍼 파라미터 및 모델 & 서버 선택을 위한 설정 값 예시 -> config.yaml로 복사해서 사용
├── .env.sample # .env 설정의 예시값 -> .env로 복사해서 사용
├── 1.server-keygen.sh # github 연동을 위한 keygen
├── 2.init-git-clone.sh # github 연동 이후 server에 git clone 적용
├── 3.start-app.sh # app.py 실행을 위한 .sh
├── 4.kill-app.sh # app.py 실행 이후 중단을 위한 .sh
├── 5.scp-data-send-server.sh # data 파일의 변경이 있을 경우, 사용을 위한
├── 6.scp-get-output-data.sh # output directory 그대로 이전을 위한 .sh
├── .gitignore
├── README.md
└── requirements.txt프로젝트 소개
- 팀원 : 김건율, 백우성, 유대선, 이제준, 황태결
- 프로젝트 기간 : 2024/10/30 ~ 2024/11/07
- 프로젝트 평가 기준 : 예측 평점과 실제 평점의 RMSE(Root Mean Square Error)
- 데이터 : upstage 대회에서 제공(아래 설명 O)
- 프로젝트 개요
upstage의 Book Rating Prediction 대회 참가를 위한 프로젝트.
소비자들의 책 구매 결정에 대한 도움을 주기 위한 개인화된 상품 추천 대회
주어진 users, books 메타데이터와 실제 평점 데이터로 평점 76,699건을 예측
프로젝트 진행 과정
- 베이스라인 모델에 대해 스터디 진행
- 베이스라인 코드 및 구조 수정 (유대선)
- 개인 별 모델 학습 및 실험 진행
- 최종 결과 도출
데이터
- 데이터 셋 : books, users, train_ratings, test_ratings
- books : 약 15만개의 책(item) 메타데이터 / users : 약 7만명의 고객(user) 메타데이터
- train_ratings : 약 6만명의 유저가 약 13만개의 책에 대해 남긴 약 30만 건의 평점
- test_ratings : 약 2.6만명의 유저가 5.2만개의 책에 대해 남길 것으로 예상되는 약 7.6만건의 평점 예측
- Data Schema
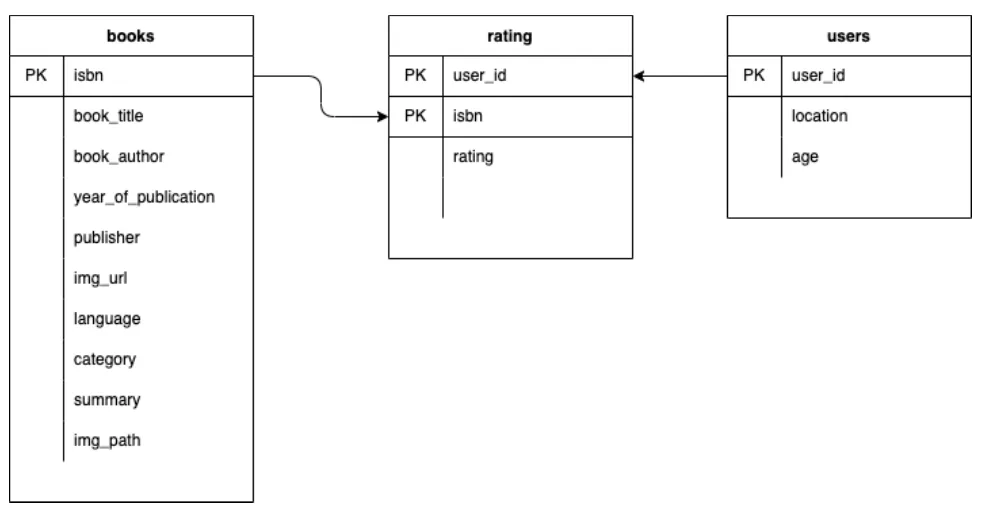
데이터 전처리
- user_id, isbn : 결측치 unknown 대체 → 범주형 전환 → 라벨 인코딩
- category : 첫번째 카테고리 선택
- language : 결측치를 최빈값으로 대체
- year_of_publication : 10년 단위로 그룹화
- age : 결측치 최빈값으로 대체 후 10살로 끊어서 그룹화
- location : country, state, city로 분리
- image : RGB변환 → 크기 조정 → 텐서 변환 → 정규화 후 numpy로 반환
- text : title과 summary를 BERT를 사용한 텍스트 임베딩 생성
Modeling
- 사용한 모델
| 모델 | 설명 | 특징 |
|---|---|---|
| FM | Factorization Machine의 기본 모델로, 특징 간 2차 상호작용을 학습 | • 선형적 구조 • 희소 데이터에 강점 |
| FFM | Field-aware FM. 각 피처를 필드별로 다른 임베딩을 학습 | • 필드별 잠재 벡터 사용 • FM보다 세밀한 상호작용 학습 |
| DeepFM | FM과 딥러닝을 결합한 하이브리드 모델 | • FM + DNN 구조 • 저차원/고차원 피처 동시 학습 |
| WDN | Wide(선형) & Deep(비선형) 구조를 결합한 모델 | • 메모리 + 일반화 능력 • 유연한 구조 |
| NCF | MF를 일반화한 GMF + MLP 모델 | • 풍부한 피처 표현 • 비선형 상호작용 학습 |
| ImageFM | 이미지(책 표지)를 FM에 통합한 확장 모델 | • 이미지 피처 활용 • CNN 특징 추출 |
| Image DeepFM | 이미지(책 표지)를 DeepFM에 통합한 모델 | • 이미지 피처 활용 • CNN + DeepFM 구조 |
| TextFM | 책 내용 요약을 사전 학습된 BERT로 임베딩해 FM에 통합한 확장 모델 | • 임베딩 된 텍스트 피처 활용 • BERT 임베딩 활용 |
| Text DeepFM | 책 내용 요약을 사전 학습된 BERT로 임베딩해 DeepFM에 통합한 모델 | • 임베딩 된 텍스트 피처 활용 • BERT + DeepFM 구조 |
| ResNet DeepFM | ResNet 구조를 DeepFM에 통합한 모델 | • 잔차 연결 활용 • 깊은 네트워크 학습 |
- 베이스라인 구조 수정
- main.py → app.py 변경
- app.py 내의 main 함수
run_model/load_config/run_app함수로 각각 분리 - 기존 baseline bash 파일 삭제하고 서버에서 자동으로 돌아가도록
.sh파일 생성 - config 파일 가독성과 편의성 및 확장성 고려하여 변경
- 효율적 코드 관리를 위한 추상화 및 Class 적용
-
학습률 수정
기본 베이스라인 학습률에선 epoch이 진행됨에 따라 train RMSE는 줄어드는 반면 valid RMSE는 발산했다. 그래서 학습률을 0.0001로 낮추고 lr_scheduler를 사용해서 갈수록 더 낮아지게 했다. -
앙상블
각 모델들로 예측한 output을 균일한 비중으로 앙상블하고, 조합을 바꿔보면서 실험했다.
3. 최종 결과
위의 모델들을 다 돌려보고 여러 조합으로 앙상블 진행 후, public score(RMSE)가 가장 잘 나온 두 결과를 최종 선택해 제출했다.
자세한 하이퍼파라미터와 실험 환경 설정은 config-sample.yaml에서 확인 가능
- FM 단일 모델에 context 데이터 적용.
- Public RMSE : 2.1773
- FM, FFM, NCF, WDN, DCN, Text DeepFM, ImageFM 모델 비중을 균일하게 앙상블.
- Public RMSE : 2.2260

Full-Stack Dev / MLOps