Today I Learned
오늘은 Multi-VAE 모델로 프로젝트를 진행했다.
Multi-VAE
implicit feedback 기반의 협업 필터링(CF)을 위해 변분 오토인코더(VAE)를 확장한 모델
-
public score Recall@10 : 0.1127
recbole로 사용시 0.1278 -
다음 모델로 multi-vae를 개선한 RecVAE 사용 예정. 직접 구현이나 recbole을 활용해볼 예정
특징
-
다항 분포 활용
베이지안 추론을 통한 파라미터 추정과 다항 분포 우도 함수 사용 -
효율적인 학습
어닐링(annealing) 기법을 통한 효과적인 파라미터 튜닝
KL 어닐링은 학습 초기에 KL 항의 가중치를 낮게 시작하여 점진적으로 증가
잠재 공간의 붕괴를(posterior collapse) 방지한다. -
입력층에 드롭아웃 적용
-
변분추론 기반 접근
사용자의 선호도를 잠재 공간에서 다변량 가우시안 분포로 모델링
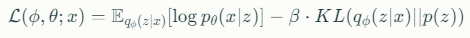
주요 하이퍼파라미터
- latent_dimension: 오토인코더의 잠재 차원 (기본값: 128)
- mlp_hidden_size: MLP 은닉층 크기 (기본값: 600)
- dropout_prob: 입력 드롭아웃 확률 (기본값: 0.5)
- anneal_cap: KL 손실 가중치 (기본값: 0.2)
기본 모델 구조
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiVAE(nn.Module):
def __init__(self, input_dim, hidden_dim=600, latent_dim=200):
super(MultiVAE, self).__init__()
# 인코더
self.encoder = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, hidden_dim),
nn.Tanh()
)
# 잠재 변수 파라미터
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_var = nn.Linear(hidden_dim, latent_dim)
# 디코더
self.decoder = nn.Sequential(
nn.Linear(latent_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, input_dim)
)
def encode(self, x):
h = self.encoder(x)
return self.fc_mu(h), self.fc_var(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
return self.decoder(z)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar- 학습 프로세스
def loss_function(recon_x, x, mu, logvar, anneal=1.0):
# 재구성 손실 (Multinomial log-likelihood)
recon_loss = -torch.sum(F.log_softmax(recon_x, dim=1) * x, dim=1).mean()
# KL 발산
kl_loss = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp(), dim=1).mean()
return recon_loss + anneal * kl_loss
# 학습 예시
def train(model, optimizer, data_loader):
model.train()
total_loss = 0
for batch_idx, data in enumerate(data_loader):
optimizer.zero_grad()
recon_batch, mu, logvar = model(data)
loss = loss_function(recon_batch, data, mu, logvar)
loss.backward()
optimizer.step()
total_loss += loss.item()
Full-Stack Dev / MLOps