Today I Learned
트리 모델 베이스로 빠르게 피처들을 성능 테스트해볼 수 있는 기본 모델을 만들기로 했다.
LightGBM Ranker
-
일단은 간단하게 피처들을 테스트해볼 빠르고 가벼운 모델이 필요했다.
-
FM이나 Sequential 모델은 리소스와 시간이 많이 소모되므로 일단 피처 테스트용으로 머신러닝 쪽 모델을 찾던 중 Light GBM 모델에도 Ranker 모델이 있었다.
-
실제로는 자주 사용되는 모델은 아니지만 보조적 역할로 가끔 쓰이는 것같고, 특정 도메인이나 작은 규모의 프로젝트, 프로토타입이나 베이스라인 모델로 활용되는 것 같다.
-
Light GBM 베이스라서 대규모 데이터에서도 빠른 학습이 가능할 것으로 생각되어 일단 구현 시도
-
여러번의 시도를 해봤으나 아직까지는 추천이 이상한 방향으로 한쪽에 치우쳐져서 수정 시도중..
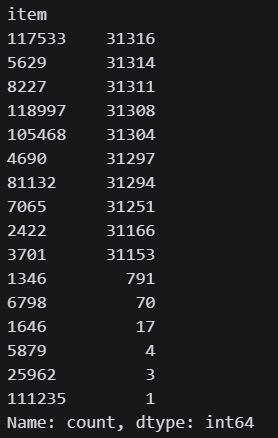
-
negative 샘플링이 없어서 학습 자체가 제대로 안됨. 그걸 넣자니 모델 복잡도가 너무 올라서 가벼운 목적으로 진행이 안됨. 일단 이 모델은 drop.추후 다시 실험
구현 시도 코드
from lightgbm import LGBMRanker
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import GroupShuffleSplit
import lightgbm as lgb
from tqdm import tqdm
def create_recommendation_model(items_df, train_df, genre_list):
# 1. 특성 엔지니어링
for genre in genre_list:
items_df[f'genre{genre}'] = items_df['genre'].apply(lambda x: 1 if genre in x else 0)
# # 2. 사용자-아이템 상호작용 특성 생성
# 아이템별 시청 횟수
item_watch_count = train_df.groupby('item')['user'].count().reset_index()
item_watch_count.columns = ['item', 'itemWatchCount']
# 3. 학습 데이터 생성
train_features = train_df.merge(items_df.drop(['title', 'director', 'writer'], axis=1), on='item', how='left')
train_features['year'] = train_features['year'].astype(int)
train_features['watched'] = 1
train_features = train_features.merge(item_watch_count, on='item', how='left')
# 4. LightGBM Ranker 모델 학습
features = [col for col in train_features.columns if col not in ['user', 'item', 'time', 'genre', 'watched']]
print(features)
# 그룹(유저)별로 train/validation 분할
splitter = GroupShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
train_idx, valid_idx = next(splitter.split(train_features, groups=train_features['user']))
# train/validation 데이터 분할
train_data = train_features.iloc[train_idx]
valid_data = train_features.iloc[valid_idx]
# 그룹 사이즈 재계산
train_group_sizes = train_data.groupby('user').size().values
valid_group_sizes = valid_data.groupby('user').size().values
model = LGBMRanker(
objective='rank_xendcg',
metric='ndcg',
n_estimators=200,
learning_rate=0.1,
max_depth=6,
random_state=42,
early_stopping_rounds=100,
n_jobs=-1
)
model.fit(
train_data[features],
train_data['watched'],
group=train_group_sizes,
eval_set=[(valid_data[features], valid_data['watched'])],
eval_group=[valid_group_sizes],
eval_metric=['ndcg@10'],
)
print(f"Best iteration: {model.best_iteration_}")
print(f"Best score: {model.best_score_}")
return model, features, items_df
def generate_recommendations(model, features, items_df, train_df, user_id, n_recommendations=10):
# 해당 사용자가 아직 보지 않은 영화 찾기
watched_items = set(train_df[train_df['user'] == user_id]['item'])
candidate_items = set(items_df['item']) - watched_items
# 후보 아이템에 대한 특성 생성
candidate_features = items_df[items_df['item'].isin(candidate_items)].copy()
candidate_features['user'] = user_id
# 아이템 시청 횟수 추가
item_watch_count = train_df.groupby('item')['user'].count().reset_index()
item_watch_count.columns = ['item', 'itemWatchCount']
candidate_features = candidate_features.merge(item_watch_count, on='item', how='left')
# 예측 및 상위 N개 아이템 선택
predictions = model.predict(candidate_features[features])
candidate_features['predScore'] = predictions
recommendations = candidate_features.nlargest(n_recommendations, 'predScore')['item'].tolist()
return recommendations
def modeling(items_df:pd.DataFrame, train_df:pd.DataFrame, genre_list) -> pd.DataFrame:
# 모델 학습
model, features, processed_items_df = create_recommendation_model(items_df, train_df, genre_list)
# 학습된 하나의 모델로 모든 사용자에 대한 추천 생성
all_users = train_df['user'].unique()
recommendations_df = []
for user_id in tqdm(all_users, desc="Generating recommendations"):
user_recommendations = generate_recommendations(
model, features, processed_items_df, train_df, user_id
)
recommendations_df.extend([
{'user': user_id, 'item': item}
for item in user_recommendations
])
return pd.DataFrame(recommendations_df)
Full-Stack Dev / MLOps