Today I Learned
오늘 배운 내용은 최신 Sequential Models에 대해 공부했다.
Recent Sequential Recommendations
Sequential Recommendation
사용자의 행동 이력(history)의 순서와 시간을 보존하여 다음에 소비할 아이템을 예측하는 추천 시스템
-
유저가 지금까지 소비한 아이템의 sequence가 input이고 다음으로 소비할 아이템을 높은 확률 순서로 예측해야 한다.
-
성별, 나이 같은 유저 정보가 필요하지 않기 때문에 보안이 뛰어나다.
-
실시간으로 변화하는 고객의 선호도를 파악하여 추천에 반영한다.
-
Transformer 모델이 생겨나고 많은 모델들이 개발되고 있다.
Transformer는 TIL #466을 참고
Transformer-based Recommendations
- TIL-543 참고
SASRec
-
Transformer의 인코더 기반의 사용자의 과거 행동 시퀀스를 기반으로 다음 아이템을 추천하는 모델
-
Causal Masking : 해당 아이템의 이전 아이템들에게만 attention 연산을 하고 해당 아이템보다 미래의 아이템은 attention 연산에서 masking 한다. 추천에는 제일 마지막의 z값을 사용.
BERT4Rec
-
BERT4Rec: Sequential Recommendation with Bidirectional
Encoder Representations from Transformer -
BERT의 양방향(bidirectional) 구조를 추천 시스템에 적용한 순차적 추천 모델.
기존 모델들과 달리 좌우 양쪽의 컨텍스트를 모두 고려한다. -
Masked Language Modeling(MLM)
시퀀스의 일부 아이템을 랜덤하게 마스킹하고 예측해 정보 유출 없이양방향 학습을 한다. -
마지막 예측은 t+1번째 token을 masking해서 예측
Sequential Recommendation with Content Features
-
썸네일 이미지, 영상 제목, 채널명, 영상, 태그, 설명 등 contents 특징을 반영한 sequential 추천
-
contents 정보는 추천 성능 향상도 좋고 cold start 문제에 강건하다.
-
인코딩 할때는 이미지나 텍스트 같은 비정형 데이터는 pretrained model을 활용하고, 정형데이터는 embedding matrix를 활용한다.
Early Fusion Method
원본 데이터나 특징들을 학습/특징 추출 전에 통합하여 하나의 통합된 표현으로 만드는 방법
각 모달리티를 합쳐서 하나의 임베딩으로 만들어 transformer에 넣는 방식.
-
단일 학습 프로세스만 필요해 계산 효율성이 높고,
모달리티간 상효작용을 초기 단계에서 학습이 된다. -
한 모달리티가 다른 모달리티보다 더 많은 정보를 포함할 경우 학습이 편향될 수 있고 차원의 저주 문제가 발생할 수 있다.
Late Fusion Method
각 모달리티별로 독립적인 (transformer)모델을 학습하고 예측 단계에서 결과를 통합하는 방법
-
모듈성이 좋아서 새로운 모달리티 추가가 용이하고,
각각 독립적으로 최적화가 가능하다. -
하지만 모달리티간 상호작용 정보를 놓칠 수 있고, 시스템 복잡도가 높고, 최종 결과 통합 방식에 따라 성능이 크게 바뀔 수 있다.
-
일반적으로 Late Fusion이 계산 비용이 높은만큼 early에 비해 성능이 좋긴하다.
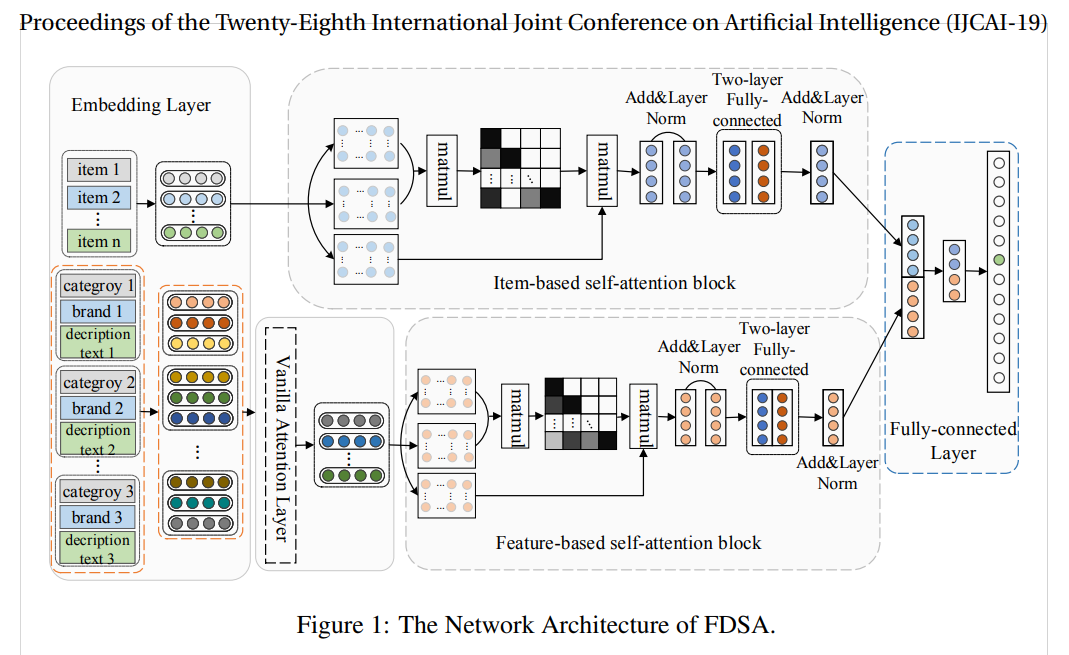
FDSA
 이미지 출처 : 논문
이미지 출처 : 논문
-
Feature-level Deeper Self-Attention Network for Sequential Recommendation (2019)
-
아이템 간의 전환 패턴뿐만 아니라 아이템의 특성(feature) 간의 전환 패턴도 고려하는 순차적 추천 모델
-
그림에서 item-based는 ID 임베딩 transformer고, feautre-based는 컨텐츠 임베딩 tranformer 부분. 두 방식을 late fusion으로 통합해 결과를 만든다.
-
아이템의 다양한 특성(카테고리, 브랜드, 텍스트 등)을 통합하여 특성 시퀀스로 변환
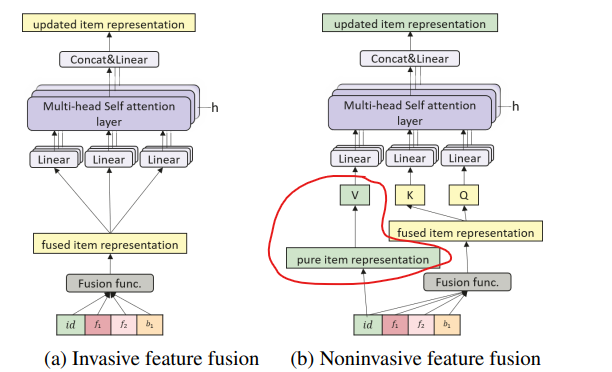
NOVA-BERT
 이미지 출처 : 논문
이미지 출처 : 논문
-
시퀀셜 추천 시스템에서 부가 정보(side information)를 효과적으로 활용하기 위해 제안된 non-invasive self-attention 메커니즘
-
기존의 직접적인 정보 통합 방식의 한계를 극복하고자 새로운 Non-invasive 접근 방식을 제시
Non-invasive 방식
-
기존 invasive 방식은 부가 정보 통합 시 아이템의 고유 특성이 희석되어 유저와 아이템들의 weight들이 다들 균등하게 되서 특징이 크게 두드러지지 않는 단점이 있다.
-
Non-invasive 방식은 Q와 K는 기존과 같이 아이템과 부가 정보가 통합된 fused item representation을 사용한다.
-
다만 Value를 순수한 아이템 정보만을 담은 pure item representation 기반으로 뽑은 임베딩으로 고정 시켜놓고 transformer 훈련을 돌린다.
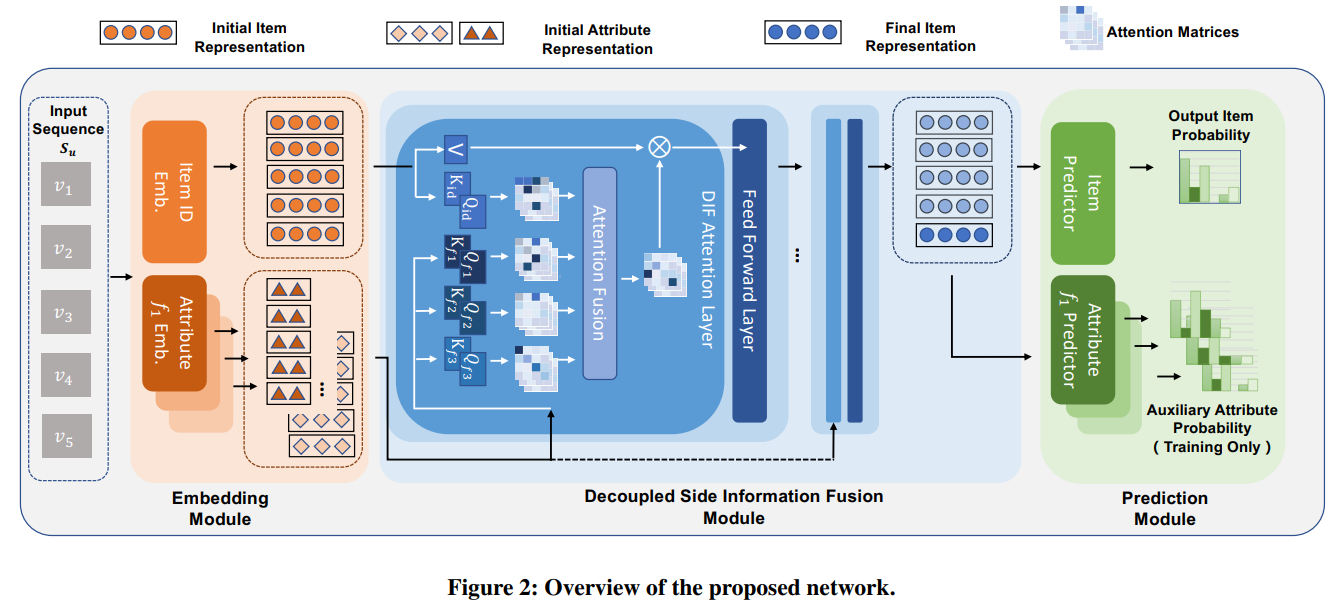
DIF-SR
 이미지 출처 : 논문
이미지 출처 : 논문
-
Decoupled Side Information Fusion for Sequential Recommendation (2022)
-
기존 모델들과 달리 부가 정보를 입력 단계가 아닌 어텐션 레이어에서 통합하는 방식의 모델
-
기존 초기 통합 방식은 서로 관련없는 정보간의 Q와 K 유사성을 계산하는 불필요한 연산이 발생하는데, 이를 해결해 계산 효율성이 높으면서 성능의 향상도 있다.
-
각 속성별로 독립적인 어텐션 매트릭스 생성하고, 아이템 표현과 부가 정보의 어텐션을 분리하여 계산해 아이템과 각 부가 정보에 대해 독립적인 Query, Key 생성한 뒤에 attention fusion 연산을 거친다.
