ACT : Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (2023)
reading papers
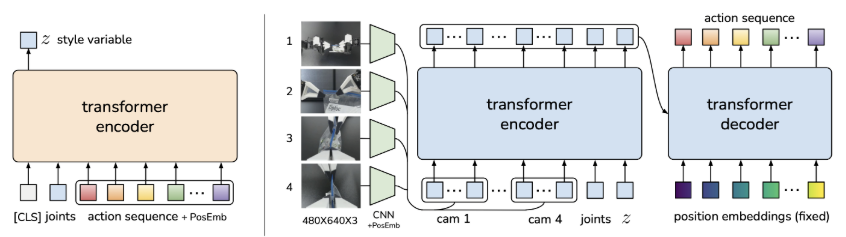
Stanford, UC Berkely, Meta ACT : Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (RSS 2023)의 논문 내용 정리
ABSTRACT
"케이블 타이 묶기"나 "배터리 끼우기"와 같은 정교한 조작 작업은 정밀성(Precision), 접촉력(Contact forces)의 세심한 조정, 그리고 폐루프 시각 피드백(Closed-loop visual feedback)을 필요로 하기 때문에 로봇이 수행하기 매우 어렵기로 정평이 나 있다.
이러한 작업을 수행하려면 일반적으로 고성능 로봇(High-end robots), 정밀한 센서, 또는 세심한 캘리브레이션(Calibration)이 필요한데, 이는 비용이 많이 들고 환경을 구축하기 어렵다.
과연 학습(Learning)을 통해 저비용의 정밀하지 않은 하드웨어(Low-cost and imprecise hardware)도 이러한 정교한 조작 작업을 수행할 수 있을까?
본 논문은 커스텀 원격 조작 인터페이스(Teleoperation interface)를 통해 수집된 실제 데모(Real demonstrations)로부터 직접 종단간 모방학습(End-to-end imitation learning)을 수행하는 저비용 시스템을 제안한다.
그러나 모방학습은 특히 고정밀 도메인(High-precision domains)에서 고유한 난관이 존재한다. 즉, 정책(Policy)의 오류가 시간이 지남에 따라 누적(Compound)될 수 있으며, 인간의 데모는 비정상성(Non-stationary)을 띨 수 있다는 점이다.
이러한 문제를 해결하기 위해, 본 논문은 행동 시퀀스(Action sequences)에 대한 생성 모델(Generative model)을 학습하는 간단하고 새로운 알고리즘인 ACT(Action Chunking with Transformers)를 개발한다.
ACT를 통해 로봇은 반투명 소스 컵 열기나 배터리 끼우기와 같이 어려운 6가지의 실제 환경 작업(Real world tasks)을 단 10분 분량의 데모만으로 80-90%의 성공률로 학습할 수 있었다.
I. INTRODUCTION
정교한 조작(Fine manipulation) 작업은 정밀한 폐루프 피드백(Closed-loop feedback)을 수반하며, 환경 변화에 대응하여 동작을 조정하고 재계획(Re-plan)하기 위한 고도화된 손과 눈의 협응(Hand-eye coordination)을 필요로 한다. 이러한 조작 작업의 예로는 양념병 뚜껑 열기나 배터리 끼우기 등이 있는데, 이는 단순한 "픽 앤 플레이스"와 같은 큰 동작보다는 "집기", "비틀어 열기", "뜯기"와 같은 섬세한 동작을 포함한다.

위 [Figure 1]의 양념병 뚜껑 열기를 예로 들어보자. 컵은 테이블 위에 똑바로 세워진 상태로 초기화된다. 오른쪽 그리퍼(Gripper)가 먼저 컵을 넘어뜨리고, 열려 있는 왼쪽 그리퍼 안으로 살짝 밀어 넣어야(Nudge) 한다.
그다음 왼쪽 그리퍼가 부드럽게 닫히며 테이블에서 컵을 들어 올린다. 이어서 오른쪽 손가락 중 하나가 아래쪽에서 컵에 접근하여 뚜껑을 비틀어 연다.
이 각 단계는 높은 정밀도, 섬세한 손과 눈의 협응, 그리고 풍부한 접촉(Rich contact)을 필요로 한다. 수 밀리미터의 오차만 있어도 작업은 실패로 돌아간다.
기존의 정교한 조작 시스템들은 정밀한 상태 추정(State estimation)을 위해 고가의 로봇과 고성능 센서를 사용한다 [29, 60, 32, 41]. 이와 대조적으로 본 논문은 접근 가능하고 재현 가능한 저비용의 정교한 조작 시스템을 개발하고자 한다. 하지만 저비용 하드웨어는 고성능 플랫폼보다 필연적으로 정밀도가 떨어지므로, 센싱(Sensing)과 계획(Planning)의 난이도가 더욱 심화된다.
이를 해결하기 위한 유망한 방향 중 하나는 시스템에 학습(Learning)을 도입하는 것이다. 인간 역시 산업용 등급의 고유 수용성 감각(Proprioception) [71]을 가지고 있지 않지만, 폐루프 시각 피드백(Closed-loop visual feedback)을 통해 학습하고 오차를 능동적으로 보정함으로써 섬세한 작업을 수행할 수 있다. 따라서 본 논문의 시스템은 상용 웹캠의 RGB 이미지를 행동(Actions)으로 직접 매핑하는 종단간 정책(End-to-end policy)을 학습한다.
이러한 픽셀-투-액션 정식화(Pixel-to-action formulation)는 정교한 조작에 특히 적합하다. 정교한 조작은 복잡한 물성(Physical properties)을 가진 객체를 다루는 경우가 많아, 전체 환경을 모델링하는 것보다 조작 정책(Manipulation policy)을 학습하는 것이 훨씬 간단하기 때문이다.
양념병 예시를 다시 보면, 컵을 밀어 넣을 때의 접촉이나 뚜껑을 비틀어 열 때의 변형(Deformation)을 모델링하려면 수많은 자유도(Degrees of freedom)에 걸친 복잡한 물리학적 계산이 필요하다.
계획(Planning)에 사용할 수 있을 만큼 정확한 모델을 설계하려면 상당한 연구와 작업별 엔지니어링 노력이 요구된다.
반면, 컵을 밀고 여는 정책은 훨씬 간단하다. 폐루프 정책은 컵과 뚜껑이 어떻게 움직일지 미리 정밀하게 예측(Anticipating)하기보다는, 그들의 다양한 위치에 맞춰 반응(React)할 수 있기 때문이다.
그러나 종단간 정책(End-to-end policy)을 학습시키는 것은 고유한 어려움이 있다. 정책의 성능은 학습 데이터 분포(Training data distribution)에 크게 의존하며, 정교한 조작의 경우 고품질의 인간 데모(Human demonstrations)는 시스템이 인간의 기교(Dexterity)를 배울 수 있게 해주어 엄청난 가치를 제공한다. 따라서 본 논문은 데이터 수집을 위한 저비용이지만 정교한 원격 조작(Teleoperation) 시스템과 데모로부터 효과적으로 학습하는 새로운 모방학습(Imitation learning) 알고리즘을 구축한다. 다음 두 문단에서 각 구성 요소를 개괄한다.
-
원격 조작 시스템(Teleoperation system).
본 논문은 두 세트의 저비용 상용(Off-the-shelf) 로봇 팔을 이용한 원격 조작 설비를 고안했다. 이들은 서로 크기만 다른 비례 버전(Scaled versions)이며, 원격 조작을 위해 관절 공간 매핑(Joint-space mapping)을 사용한다.본 논문은 더 쉬운 역구동(Backdriving)을 위해 3D 프린팅 부품으로 이 설비를 보강하였으며, 그 결과 $20k 예산 내에서 매우 유능한 원격 조작 시스템을 구축했다.
Figure 1에서 그 능력을 보여주는데, 케이블 타이 묶기와 같은 정밀한 작업, 탁구공 저글링 같은 동적인 작업, 그리고 NIST 보드 #2 [4]의 체인 조립과 같은 접촉이 풍부한(Contact-rich) 작업의 원격 조작이 포함된다.
-
모방학습 알고리즘(Imitation learning algorithm).
정밀함과 시각 피드백을 요하는 작업은 고품질의 데모가 있더라도 모방학습에 있어 상당한 난관이다. 예측된 행동의 작은 오차가 상태(State)의 큰 차이를 유발하여, 모방학습의 "누적 오차(Compounding error)" 문제 [47, 64, 29]를 악화시킬 수 있다.이를 해결하기 위해 본 논문은 일련의 행동들이 하나의 덩어리(Chunk)로 그룹화되어 단일 단위로 실행된다는 심리학 개념인 행동 청킹(Action chunking) [35]에서 영감을 얻었다.
본 논문의 경우, 정책은 한 번에 한 단계가 아니라 다음 Timesteps의 목표 관절 위치(Target joint positions)를 예측한다. 이는 작업의 유효 호라이즌(Effective horizon)을 배로 줄여주어 누적 오차를 완화한다. 또한 행동 시퀀스(Action sequences)를 예측하는 것은 마르코프 단일 단계 정책(Markovian single-step policies)으로는 모델링하기 어려운 데모 내의 멈춤(Pauses)과 같은 시간적으로 상관된 교란 변수(Temporally correlated confounders) [61]를 해결하는 데도 도움이 된다.
정책의 부드러움(Smoothness)을 더욱 향상하기 위해, 본 논문은 정책을 더 자주 조회(Query)하고 겹치는 행동 청크들을 평균 내는 Temporal ensembling을 제안한다. 본 논문은 시퀀스 모델링을 위해 설계된 아키텍처인 트랜스포머(Transformers) [65]로 Action Chunking 정책을 구현하고, 인간 데이터의 변동성(Variability)을 포착하기 위해 이를 조건부 VAE (CVAE) [55, 33]로 학습시킨다.
본 논문은 이 방법을 ACT(Action Chunking with Transformers)라 명명하였으며, 다양한 시뮬레이션 및 실제 환경의 정교한 조작 작업에서 기존 모방학습 알고리즘들보다 월등히 뛰어난 성능을 보임을 확인했다.
본 논문의 핵심 기여(Key contribution)는 원격 조작 시스템과 새로운 모방학습 알고리즘으로 구성된, 정교한 조작 학습을 위한 저비용 시스템이다. 원격 조작 시스템은 저렴한 비용에도 불구하고 높은 정밀도와 풍부한 접촉을 요하는 작업을 가능하게 한다. 모방학습 알고리즘인 ACT는 정밀한 폐루프 행동(Closed-loop behavior) 학습할 수 있으며 기존 방법들을 압도적으로 능가한다.
이 두 부분 간의 시너지(Synergy)는 반투명 양념병 열기나 배터리 끼우기와 같은 6가지의 정교한 조작 기술을 단 10분, 혹은 50개의 데모 궤적(Trajectories)만으로 80-90%의 성공률로 실제 환경(Real-world)에서 직접 학습할 수 있게 한다.
II. RELATED WORK
-
Imitation learning for robotic manipulation
모방학습은 로봇이 전문가로부터 직접 학습할 수 있게 해준다. 행동 복제(Behavioral Cloning, BC) [44]는 가장 간단한 모방학습 알고리즘 중 하나로, 모방을 관측에서 행동으로의 지도 학습으로 간주한다.이후 많은 연구들이 다양한 아키텍처를 통해 히스토리(History)를 통합하거나 [39, 49, 26, 7], 다른 학습 목적 함수(Training objective)를 사용하거나 [17, 42], 정규화(Regularization)를 포함하는 [46] 등 BC를 개선하고자 노력해 왔다.
다른 연구들은 모방학습의 Multi-task 또는 Few-shot 측면을 강조하거나 [14, 25, 11], 언어를 활용하거나 [51, 52, 26, 7], 특정 작업 구조를 이용하기도 한다 [43, 68, 28, 52]. 이러한 모방학습 알고리즘을 더 많은 데이터로 Scaling함으로써 새로운 객체, 지시 사항, 혹은 장면에 일반화할 수 있는 인상적인 시스템들이 등장했다 [15, 26, 7, 32].
본 논문은 저비용이면서도 섬세하고 정교한 조작(Fine manipulation) 작업을 수행할 수 있는 모방학습 시스템을 구축하는 데 집중한다.
본 논문은 고성능 원격 조작(Teleoperation) 시스템과 정교한 조작 작업에서 기존 방법들을 획기적으로 개선한 새로운 모방학습 알고리즘을 구축함으로써, 하드웨어와 소프트웨어 양면에서 이 문제를 해결한다.
-
Addressing compounding errors
BC의 주요 단점은 누적 오차이다. 이는 이전 시간 단계(Timesteps)의 오차가 축적되어 로봇이 학습 분포(Training distribution)에서 벗어나게(Drift off) 만들고, 회복하기 힘든 상태(Hard-to-recover states)로 이끄는 문제다 [47, 64].이 문제는 정교한 조작 환경에서 특히 두드러진다 [29]. 누적 오차를 완화하는 한 가지 방법은 DAgger [47] 및 그 변형들 [30, 40, 24]과 같이 추가적인 On-policy 상호작용과 전문가 교정을 허용하는 것이다. 그러나 전문가 Annotation은 원격 조작 인터페이스를 사용할 때 시간이 많이 소요되고 부자연스러울 수 있다 [29].
데모 수집 시점에 노이즈를 주입(Inject noise)하여 교정 행동(Corrective behavior)이 포함된 데이터셋을 얻는 방법도 있으나 [36], 정교한 조작의 경우 이러한 노이즈 주입은 작업 실패로 직결되어 원격 조작 시스템의 기교(Dexterity)를 저하시킬 수 있다.
이러한 문제를 우회하기 위해 기존 연구들은 오프라인 방식으로 합성 교정 데이터를 생성하기도 했다 [16, 29, 70]. 하지만 이들은 저차원 상태(Low-dimensional states)를 사용할 수 있는 환경이나 파지(Grasping)와 같은 특정 유형의 작업으로 제한된다.
이러한 한계들로 인해, 본 논문은 고차원 시각 관측(High-dimensional visual observations)과 호환되는 다른 각도에서 누적 오차 문제에 접근할 필요가 있다.
본 논문은 단일 행동 대신 행동 시퀀스(Action sequence)를 예측하는 Action Chunking을 통해 작업의 유효 호라이즌(Effective Horizon)을 줄이고, 겹치는 행동 청크들을 Ensemble하여 정확하면서도 부드러운 궤적을 생성할 것을 제안한다.
-
Bimanual manipulation
양팔 조작은 로보틱스에서 오랜 역사를 가지고 있으며, 하드웨어 비용의 하락과 함께 인기를 얻고 있다. 초기 연구들은 알려진 환경 동역학(Dynamics)을 바탕으로 고전 제어(Classical control) 관점에서 양팔 조작을 다루었으나 [54, 48], 이러한 모델을 설계하는 것은 시간이 많이 걸리고 복잡한 물성을 가진 객체에 대해서는 정확하지 않을 수 있다.최근에는 양팔 시스템에 강화학습(Reinforcement Learning) [9, 10], 인간 데모 모방 [34, 37, 59, 67, 32], 또는 운동 원시(Motor primitives)를 연결하는 키포인트 예측 학습 [20, 19, 50]과 같은 학습 기반 방법들이 도입되었다. 일부 연구들은 매듭 풀기, 천 펴기, 심지어 바늘 꿰기 [19, 18, 31]와 같은 세밀한 조작 작업에 집중하기도 했으나, 다빈치 수술 로봇(da Vinci surgical robot)이나 ABB YuMi와 같이 상당히 고가의 로봇을 사용하였다.
본 논문은 개당 약 $5k 수준의 저비용 하드웨어로 눈을 돌려, 이들이 고정밀 폐루프(Closed-loop) 작업을 수행할 수 있도록 하는 것을 목표로 한다.
본 논문의 원격 조작 설정은 리더(Leader) 로봇과 팔로워(Follower) 로봇 간의 Joint-space mapping을 사용하는 Kim et al. [32]과 가장 유사하다. 하지만 이전 시스템과 달리, 본 논문은 특수 인코더, 센서, 혹은 가공된 부품(Machined components)을 사용하지 않는다.
본 논문은 오직 상용 로봇과 소량의 3D 프린팅 부품만으로 시스템을 구축하여, 비전문가도 2시간 이내에 조립할 수 있도록 한다.
III. ALOHA: A LOW-COST OPEN-SOURCE HARDWARESYSTEM FOR BIMANUAL TELEOPERATION
본 논문은 접근성이 좋고 고성능인 정교한 조작(Fine manipulation)을 위한 원격 조작(Teleoperation) 시스템을 개발하고자 한다. 설계 고려 사항을 다음 5가지 원칙으로 요약한다.
1) 저비용(Low-cost): 전체 시스템 비용은 대부분의 로봇 연구실 예산 범위 내여야 하며, 단일 산업용 로봇 팔 가격과 비슷해야 한다.
2) 범용성(Versatile): 실제 물체를 다루는 광범위한 정교한 조작 작업에 적용 가능해야 한다.
3) 사용자 친화적(User-friendly): 시스템은 직관적이고 신뢰할 수 있으며 사용하기 쉬워야 한다.
4) 수리 용이성(Repairable): 고장이 났을 때 연구자들이 쉽게 수리할 수 있어야 한다.
5) 제작 용이성(Easy-to-build): 연구자들이 구하기 쉬운 재료로 빠르게 조립할 수 있어야 한다.

때 원칙 1, 4, 5에 따라 두 개의 ViperX 6자유도(6-DoF) 로봇 팔 [1, 66]을 사용하는 양팔 평행 그리퍼(Parallel-jaw grippers) 구성을 구축하게 되었다. 가격과 유지보수 문제로 인해 기교 있는 손(Dexterous hands)은 사용하지 않는다. 사용된 ViperX 팔은 가반 하중(Payload) 750g, 도달 거리(Span) 1.5m, 정밀도 5-8mm의 사양을 가진다. 이 로봇은 모듈식이라 수리가 간단하다.
모터 고장 시 저렴한 다이나믹셀(Dynamixel) 모터로 쉽게 교체할 수 있다. 로봇은 상용 제품(Off-the-shelf)으로 약 $5600에 구매 가능하다. 그러나 OEM 핑거는 정교한 조작 작업을 수행하기에 범용성이 부족하다.
따라서 본 논문은 자체적으로 3D 프린팅한 투시형(See-through) 핑거를 설계하고 그립 테이프를 부착했다(Fig 3). 이를 통해 섬세한 작업 수행 시 시야를 확보하고 얇은 플라스틱 필름 같은 물체도 견고하게 잡을 수 있다.
다음으로 ViperX 로봇을 중심으로 사용자 편의성을 극대화한 원격 조작 시스템을 설계하고자 한다. VR 컨트롤러나 카메라로 캡처한 손의 포즈를 로봇의 말단 장치(End-effector) 포즈로 매핑하는 작업 공간 매핑(Task-space mapping) 대신, 동일한 회사가 제조한 더 작고 저렴한($3300) WidowX [2] 로봇을 이용한 직접적인 관절 공간 매핑(Joint-space mapping)을 사용한다.
사용자는 작은 WidowX(리더, Leader)를 역구동(Backdriving)하여 원격 조작하며, 리더의 관절은 더 큰 ViperX(팔로워, Follower)와 동기화된다. 시스템 개발 과정에서 작업 공간 매핑 대비 관절 공간 매핑의 몇 가지 이점을 발견했다.
(1) 정교한 조작은 종종 로봇의 특이점(Singularities) 근처에서의 동작을 요구하는데, 본 시스템의 경우 6자유도이며 여유 자유도(Redundancy)가 없다. 상용 역운동학(Inverse kinematics, IK) 솔루션은 이런 상황에서 자주 실패한다. 반면 관절 공간 매핑은 관절 제한 범위 내에서 높은 대역폭(High-bandwidth) 제어를 보장하며 계산량이 적고 지연 시간(Latency)도 줄여준다.
(2) 리더 로봇의 무게가 사용자의 움직임이 너무 빨라지는 것을 방지하고 미세한 떨림을 감쇠시킨다. VR 컨트롤러를 잡는 것보다 관절 공간 매핑을 사용할 때 정밀 작업 성능이 더 좋음을 확인했다. 원격 조작 경험을 개선하기 위해 리더 로봇에 장착할 수 있는 3D 프린팅된 핸들 및 가위(Handle and scissor) 메커니즘을 설계했다(Fig. 3).
이는 운영자가 모터를 역구동하는 데 필요한 힘을 줄여주고, 이진(Binary) 개폐가 아닌 그리퍼의 연속 제어(Continuous control)를 가능하게 한다. 또한 리더 측 중력을 부분적으로 상쇄하는 고무줄 부하 분산(Load balancing) 메커니즘을 설계했다.
이는 운영자의 피로도를 줄여주어 30분 이상의 장시간 원격 조작 세션을 가능하게 한다. 설정에 대한 자세한 내용은 프로젝트 웹사이트에 포함되어 있다.
나머지 설정에는 20×20mm 알루미늄 프로파일과 강철 케이블로 보강된 로봇 케이지(Cage)가 포함된다. 총 4개의 로지텍 C922x 웹캠이 있으며, 각각 480×640 RGB 이미지를 스트리밍한다. 두 개의 웹캠은 팔로워 로봇의 손목(Wrist)에 장착되어 그리퍼를 근접 촬영할 수 있다. 나머지 두 카메라는 각각 전면과 상단에 장착된다(Fig. 3). 원격 조작과 데이터 녹화는 모두 50Hz로 이루어진다.
위의 설계 고려 사항을 바탕으로, Franka Emika Panda와 같은 단일 연구용 로봇 팔 비용과 비슷한 2만 달러 예산 내에서 양팔 원격 조작 시스템 ALOHA를 구축했다. ALOHA는 다음과 같은 작업의 원격 조작을 가능하게 한다.
- 케이블 타이 묶기, 지갑에서 신용카드 꺼내기, 지퍼백 열고 닫기와 같은 정밀 작업(Precise tasks).
- 컴퓨터 마더보드에 288핀 램(RAM) 끼우기, 책장 넘기기, NIST 보드 #2 [4]의 체인 및 벨트 조립과 같은 접촉이 풍부한 작업(Contact-rich tasks).
- 실제 탁구채로 탁구공 저글링 하기, 공을 떨어뜨리지 않고 균형 잡기, 공중에서 비닐봉지 흔들어 열기와 같은 동적 작업(Dynamic tasks).
케이블 타이 묶기, 램 끼우기, 탁구공 저글링 같은 기술은 본 논문이 알기로는 5-10배 예산의 기존 원격 조작 시스템 [21, 5]에서도 불가능한 것들이다.
IV. ACTION CHUNKING WITH TRANSFORMERS
기존의 모방학습 알고리즘들은 고빈도 제어(High-frequency control)와 폐루프 피드백(Closed-loop feedback)이 요구되는 세밀한 작업에서 저조한 성능을 보인다. 따라서 본 논문은 ALOHA를 통해 수집된 데이터를 활용하기 위해 새로운 알고리즘인 ACT(Action Chunking with Transformers)를 개발한다. 먼저 ACT의 학습 파이프라인(Pipeline)을 요약한 뒤, 각 설계 선택 사항을 상세히 다룬다.
새로운 작업에 대해 ACT를 학습시키기 위해, 본 논문은 먼저 ALOHA를 사용하여 인간 데모(Human demonstrations)를 수집한다. 이때 리더 로봇(Leader robots)의 관절 위치(즉, 인간 운영자의 입력값)를 기록하고 이를 행동(Actions)으로 사용한다.
여기서 팔로워(Follower)가 아닌 리더의 관절 위치를 사용하는 것이 중요한데, 그 이유는 저수준 PID 제어기(PID Controller)를 통해 두 로봇 간의 위치 차이에 의해 가해지는 힘(Force)의 크기가 암시적으로 정의되기 때문이다. 관측(Observations)은 팔로워 로봇의 현재 관절 위치와 4대 카메라의 이미지 피드(Image feed)로 구성된다.
다음으로, 본 논문은 현재 관측이 주어졌을 때 미래의 행동 시퀀스(Sequence of future actions)를 예측하도록 ACT를 학습시킨다. 여기서 행동이란 다음 시간 단계(Time step)에서의 양팔의 목표 관절 위치(Target joint positions)에 해당한다.
직관적으로 설명하면, ACT는 현재 관측 상황에서 인간 운영자가 이후 시간 단계들에 수행할 행동을 모방하고자 하는 것이다. 이러한 목표 관절 위치들은 다이나믹셀(Dynamixel) 모터 내부의 저수준 고빈도 PID 제어기에 의해 추적(Tracked)된다.
테스트 시에는 가장 낮은 검증 손실(Validation loss)을 달성한 정책(Policy)을 로드하여 환경에서 실행(Roll out)한다. 이때 발생하는 주된 난관은 누적 오차(Compounding errors)인데, 이는 이전 행동들로부터 발생한 오차가 로봇을 학습 분포(Training distribution)를 벗어난 상태(State)로 이끄는 현상을 말한다.
A. Action Chunking and Temporal Ensemble
픽셀-투-액션 정책(Pixel-to-action policies)과 호환되는 방식으로 모방학습(Imitation Learning)의 누적 오차(Compounding errors)에 대응하기 위해, 본 논문은 고빈도로 수집된 긴 궤적(Trajectories)의 유효 호라이즌(Effective horizon)을 줄이고자 한다.
본 논문은 개별 행동들을 그룹화하여 하나의 단위로 실행함으로써 저장과 실행을 더 효율적으로 만드는 신경과학 개념인 Action chunking에서 영감을 얻었다 [35]. 직관적으로 설명하면, Action Chunk는 사탕 포장지 모서리를 잡거나 슬롯에 배터리를 끼우는 동작에 해당할 수 있다.

본 논문의 구현에서는 청크 크기를 로 고정한다. 즉, 매 스텝마다 에이전트(Agent)는 관측(Observation)을 받고, 다음 개의 행동을 생성하며, 이 행동들을 순차적으로 실행한다 (Figure 5). 이는 작업의 유효 호라이즌이 배 감소함을 의미한다. 구체적으로, 정책은 대신 를 모델링한다.
청킹은 또한 인간 데모에서의 비마르코프적(Non-Markovian) 행동을 모델링하는 데 도움을 줄 수 있다. 구체적으로, 단일 단계 정책(Single-step policy)은 행동이 상태(State)뿐만 아니라 타임스텝(Timestep)에도 의존하기 때문에, 데모 중간의 멈춤과 같은 시간적으로 상관된 교란 변수(Temporally correlated confounders) [61]를 처리하는 데 어려움을 겪을 것이다. Action Chunking은 교란 변수가 청크 내에 있을 때, 히스토리 조건부 정책(History-conditioned policies)에서 발생하는 인과적 혼란(Causal confusion) 문제 [12]를 야기하지 않으면서 이 문제를 완화할 수 있다.
Action Chunking의 단순한 구현(Naïve implementation)은 최적이지 않을 수 있다. 새로운 환경 관측이 매 스텝마다 갑작스럽게 반영되어 로봇의 움직임이 뚝뚝 끊길(Jerky) 수 있기 때문이다. 부드러움을 개선하고 실행과 관측 사이의 이산적 전환(Discrete switching)을 피하기 위해, 본 논문은 매 타임스텝마다 정책을 조회(Query)한다. 이렇게 하면 서로 다른 행동 청크들이 중첩(Overlap)되며, 주어진 타임스텝에서 하나 이상의 예측된 행동이 존재하게 된다.
본 논문은 이를 Figure 5에 묘사하였으며, 이러한 예측들을 결합하기 위해 Temporal ensemble을 제안한다. 본 논문의 Temporal ensemble은 라는 지수 가중 방식(Exponential weighting scheme)을 사용하여 이 예측들의 가중 평균(Weighted average)을 계산한다. 여기서 는 가장 오래된 행동에 대한 가중치이다. 새로운 관측을 반영하는 속도는 에 의해 결정되는데, 이 작을수록 더 빠르게 반영됨을 의미한다.
본 논문이 제안하는 방식은 현재 행동을 인접한 타임스텝의 행동들과 집계하여 편향(Bias)을 유발하는 일반적인 스무딩(Smoothing)과 달리, 동일한 타임스텝에 대해 예측된 행동들을 집계한다는 점에 주목해야 한다. 또한 이 절차는 추가적인 학습 비용(Training cost) 없이 추론 시간(Inference-time) 계산량만 추가된다. 실제로 Action Chunking과 Temporal Ensemble 모두 정밀하고 부드러운 움직임을 생성하는 ACT의 성공에 중요함을 확인했다. 이러한 구성 요소들에 대해서는 VI-A 절의 소거 연구(Ablation studies)에서 더 자세히 논의한다.
B. Modeling human data
또 다른 난관은 노이즈가 포함된 인간 데모(Human demonstrations) 데이터로부터 학습해야 한다는 점이다. 동일한 관측(Observation)이 주어지더라도, 인간은 작업을 수행하기 위해 서로 다른 궤적(Trajectories)을 사용할 수 있다. 또한 인간은 정밀도가 덜 중요한 영역에서는 더 확률적으로 행동하는 경향이 있다 [38]. 따라서 정책(Policy)이 높은 정밀도가 요구되는 영역에 집중하는 것이 중요하다.
본 논문은 Action Chunking Policy를 생성 모델(Generative model)로 학습시킴으로써 이 문제를 해결한다. 구체적으로, 현재 관측을 조건(Condition)으로 하여 행동 시퀀스를 생성하도록 정책을 조건부 변이 오토인코더(Conditional Variational Autoencoder, CVAE) [55]로 학습시킨다. CVAE는 두 가지 구성 요소를 가지는데, 각각 Figure 4의 좌측과 우측에 묘사된 CVAE Encoder와 CVAE Decoder다.
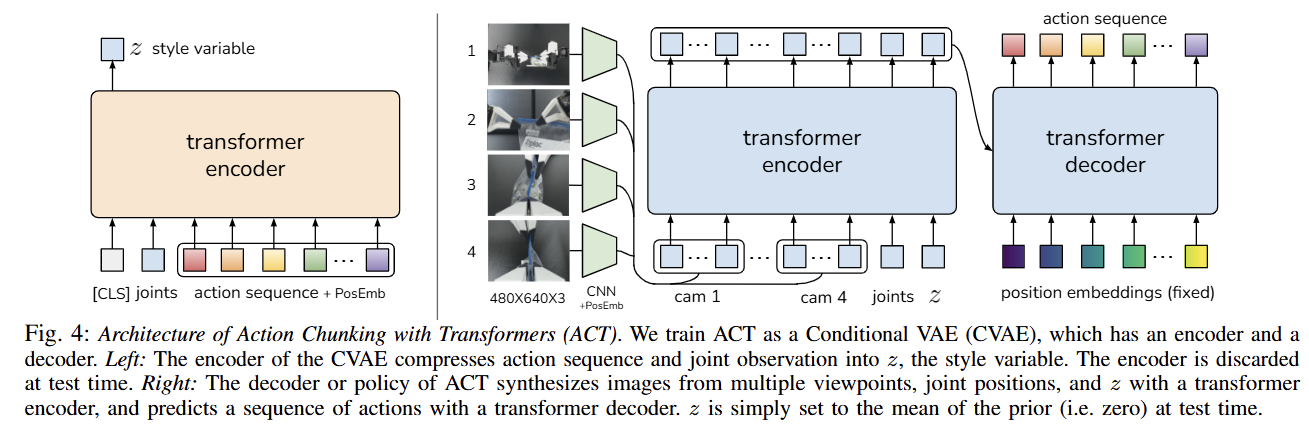
CVAE Encoder는 오직 CVAE Decoder(Policy)를 학습시키는 역할만 수행하며, 테스트 시에는 폐기(Discarded)된다. 구체적으로 CVAE Encoder는 현재 관측과 행동 시퀀스를 입력받아, Diagonal Gaussian으로 파라미터화된 스타일 변수(Style variable) 분포의 평균과 분산을 예측한다. 실제 환경에서의 더 빠른 학습을 위해, 본 논문은 이미지 관측을 제외하고 오직 고유 수용성 관측(Proprioceptive observation)과 행동 시퀀스만을 조건으로 사용한다.
CVAE Decoder, 즉 정책은 와 현재 관측(이미지 + 관절 위치) 모두를 조건으로 하여 행동 시퀀스를 예측한다. 테스트 시에는 결정론적(Deterministically)인 디코딩을 위해 를 사전 분포(Prior distribution)의 평균, 즉 0으로 설정한다.
전체 모델은 demonstration action chunks의 로그 우도(Log-likelihood)를 최대화하도록, 즉 를 목표로 학습된다. 이는 두 가지 항(재구성 손실(Reconstruction loss)과 Encoder를 가우시안 사전 분포로 정규화(Regularize)하는 항)을 가진 표준 VAE 목적 함수(Objective)를 따른다. [23]을 따르며, 본 논문은 두 번째 항에 하이퍼파라미터(Hyperparameter) 로 가중치를 부여한다.
직관적으로, 더 높은 값은 에 더 적은 정보가 전달되도록 유도한다 [62]. 종합적으로, 본 논문은 CVAE 목적 함수가 인간 데모로부터 정밀한 작업을 학습하는 데 필수적임을 발견했다. 이에 대한 더 자세한 논의는 VI-B 절에 포함되어 있다.
C. Implementing ACT
본 논문은 트랜스포머(Transformers)가 시퀀스 전반의 정보를 합성하고 새로운 시퀀스를 생성하는 데 최적화되어 있으므로, CVAE Encoder와 Decoder를 트랜스포머로 구현한다.
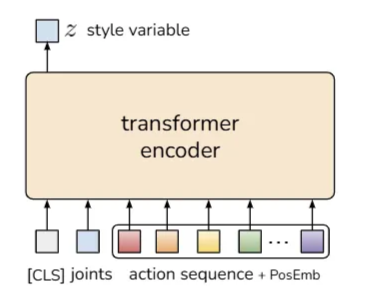
CVAE 인코더는 BERT와 유사한 트랜스포머 인코더[13]로 구현된다. 인코더의 입력은 현재 관절 위치(Joint positions)와 데모 데이터셋에서 가져온 길이 의 목표 행동 시퀀스(Target action sequence)이며, BERT와 유사하게 학습된 “[CLS]” 토큰이 앞에 붙는다. 이는 길이 의 입력을 형성한다.
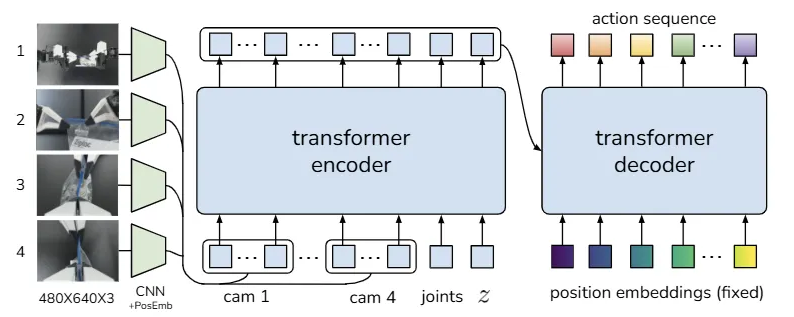
트랜스포머를 통과한 후, “[CLS]”에 해당하는 특징(Feature)은 스타일 변수(Style variable) 의 평균과 분산을 예측하는 데 사용되며, 는 디코더의 입력으로 사용된다.CVAE 디코더(즉, 정책)는 현재 관측(Observations)과 를 입력으로 받아 다음 개의 행동을 예측한다. 본 논문은 CVAE 디코더를 구현하기 위해 ResNet 이미지 인코더, 트랜스포머 인코더, 그리고 트랜스포머 디코더를 사용한다.
직관적으로, 트랜스포머 인코더는 서로 다른 카메라 시점(Viewpoints), 관절 위치, 그리고 스타일 변수로부터 정보를 합성하고, 트랜스포머 디코더는 일관성 있는(Coherent) 행동 시퀀스를 생성한다.
관측에는 각각 해상도의 4개의 RGB 이미지와 두 로봇 팔에 대한 관절 위치(총 자유도)가 포함된다. 행동 공간(Action space)은 두 로봇에 대한 절대 관절 위치인 14차원 벡터이다. 따라서 Action chunking을 사용하면, 정책은 현재 관측이 주어졌을 때 텐서를 출력한다.
정책은 먼저 ResNet18 백본[22]으로 이미지를 처리하여 RGB 이미지를 특징 맵(Feature maps)으로 변환한다. 그런 다음 공간 차원(Spatial dimension)을 따라 평탄화(Flatten)하여 의 시퀀스를 얻는다. 공간 정보를 보존하기 위해 특징 시퀀스에 2D 사인파 위치 임베딩(Sinusoidal position embedding)을 더한다[8].
4개의 이미지 모두에 대해 이를 반복하면 차원이 인 특징 시퀀스가 생성된다. 그런 다음 두 가지 특징을 더 추가하는데, 현재 관절 위치와 스타일 변수 이다. 이들은 각각 선형 레이어(Linear layers)를 통해 원래 차원에서 512로 투영(Projected)된다. 따라서 트랜스포머 인코더에 대한 입력은 가 된다.
트랜스포머 디코더는 Cross-attention를 통해 인코더 출력에 조건을 건다. 여기서 입력 시퀀스는 차원이 인 고정 위치 임베딩이며, 키(Keys)와 값(Values)은 인코더에서 온다. 이를 통해 트랜스포머 디코더는 의 출력 차원을 갖게 되며, 이는 MLP를 통해 로 다운 프로젝션(Down-projected)되어 다음 스텝에 대한 예측된 목표 관절 위치가 된다.
본 논문은 재구성(Reconstruction)에 흔히 쓰이는 L2 loss 대신 L1 loss를 사용한다. L1 손실이 행동 시퀀스를 더 정밀하게 모델링한다는 점을 확인했기 때문이다. 또한 목표 관절 위치 대신 델타(Delta) 관절 위치를 행동으로 사용할 때 성능 저하를 확인했다. 상세 아키텍처 다이어그램은 Appendix C에 포함되어 있다.
본 논문은 Algorithm 1, 2에 ACT의 학습 및 추론을 요약한다. 모델은 약 8천만(80M) 개의 파라미터를 가지며, 각 작업에 대해 처음부터(Scratch) 학습시킨다. 학습은 단일 11G RTX 2080 Ti GPU에서 약 5시간이 소요되며, 추론 시간은 동일한 머신에서 약 0.01초이다.
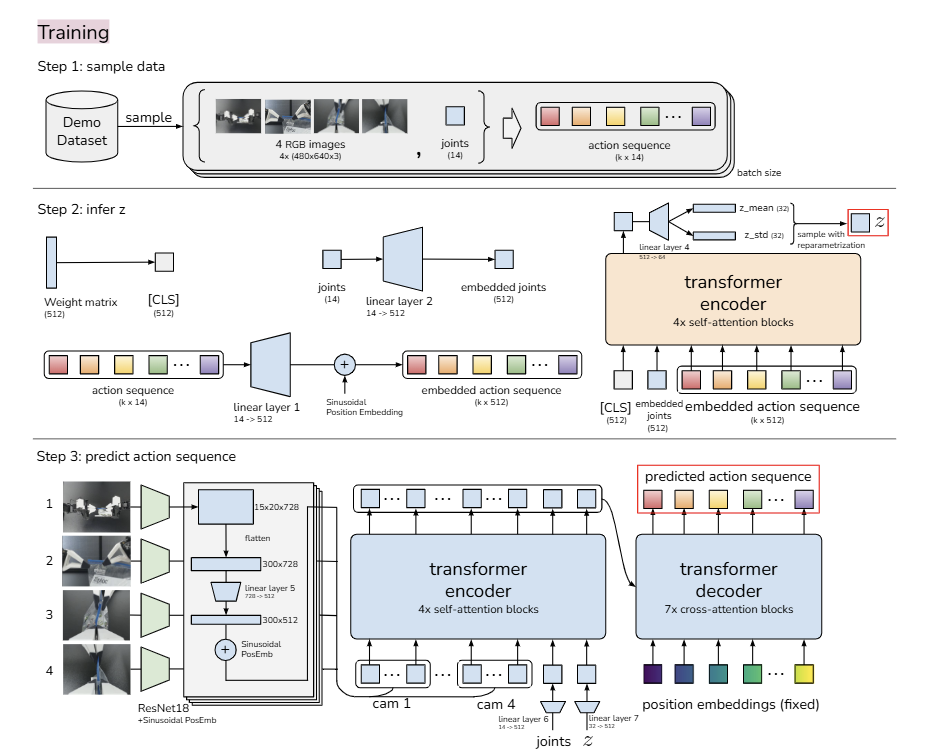
[학습 과정]
- Step 1. 데이터 샘플링 (Sample Data)
: 로봇의 현재 상태에서 미래에 수행할 Action Sequence를 데이터셋에서 가져옴 ( 개의 프레임에 해당하는 action chunk. 는 bimanipulator의 관절 수)
- Step 2. 잠재 변수 추론 (CVAE Encoder)
: Encoder는 Action Sequence를 보고, 이 행동의 종류를 파악하여 로 압축.
(입력) 복잡한 관절 움직임 데이터 ()
(확장) Linear Projection을 통해 를 차원으로 확장하여 특징 정보를 풍부하게 함
(압축 과정) Encoder가 관절 움직임 데이터를 분석하여 행동의 종류를 판별 (예: 이 움직임은 빠르게 직진한 후에 오른쪽으로 천천히 꺾어 가는 움직임이구나.)
(결과) 이러한 판단을 작은 벡터 로 압축. 학습 시에는 이 를 함께 알려줘서 헷갈리지 않게 하고 추론(테스트) 시에는 으로 두어 가장 무난한 평균 스타일로 행동하게 됨
- Step 3. 행동 시퀀스 예측 (CVAE Decoder / Policy)
비전 인코더 (Backbone): 4개의 카메라 이미지(ResNet18)와 현재 관절 각도를 입력받음. 이미지는 특징맵(Feature map)으로 변환되고 평탄화(Flatten)되어 Transformer 입력이 됨
Transformer Encoder: 여러 카메라의 시각 정보와 로봇의 현재 관절 정보를 Self-Attention으로 섞어 현재 상황을 완벽하게 이해하도록 함
Transformer Decoder: Encoder가 정리한 상황 정보(Memory)를 가져와, 뽑아둔 스타일 변수 와 위치 임베딩을 Query로 넣어줌 → 현재 상황과 의도()에 맞는 predicted action sequence를 개 예측

Algorithm 1 ACT Training
ACT는 본질적으로 CVAE(Conditional Variational Autoencoder) 구조를 따르며, 이를 통해 데이터의 불확실성(Multimodality)을 모델링한다.
- : 현재 타임스텝 (Timestep)
- : 한 번에 예측할 미래 행동의 길이 (Chunk size)
- : 현재부터 미래 까지의 행동 시퀀스 (Action Sequence). (정답지)
- : 현재의 전체 관측 정보 (Observation). (카메라 이미지 + 로봇 관절 상태)
- : 이미지 정보를 제외한 로봇 상태 정보 (Proprioception only) (알고리즘 라인 2 참조)
- : 행동의 스타일을 나타내는 잠재 변수 (Latent Variable)
학습 과정 (Training Algorithm)
학습은 "정답(미래 행동)을 보고 스타일()을 압축한 뒤, 다시 그 행동을 복원하는" 과정이라고 할 수 있다.
Step 1. Encoder - 스타일 압축
CVAE의 인코더()는 미래의 행동과 현재 로봇 상태를 보고 의 분포를 학습
• 입력으로 미래 행동()과 현재 관절 상태()를 받음
• 의 평균()과 분산()을 출력
• 실제 값은 이 분포에서 샘플링(reparameterization trick)하여 도출
Step 2. Decoder/Policy - 행동 복원
디코더()는 현재 상황과 스타일()만 가지고 행동을 예측
• 입력으로 현재의 전체 관측(, 이미지 포함)과 위에서 뽑은 스타일()을 받음
• Transformer Decoder를 통해 미래 행동 시퀀스 를 예측
Step 3. 손실 함수 (Loss Function) - 목표 설정
학습의 목표는 두 가지로, 행동을 똑같이 따라 하는 것(Reconstruction)과, 를 예쁘게 정렬하는 것(Regularization)
- 재구성 손실 (Reconstruction Loss)
• 예측한 행동()과 실제 정답 행동() 사이의 오차(Mean Squared Error)를 줄임
- 정규화 손실(Regularization Loss/KL Divergence)
• 인코더가 만든 의 분포가 표준 정규 분포()와 비슷해지도록 강제
• 이 과정이 있어야 나중에 추론할 때 를 0(평균)으로 가정하고 쓸 수 있음
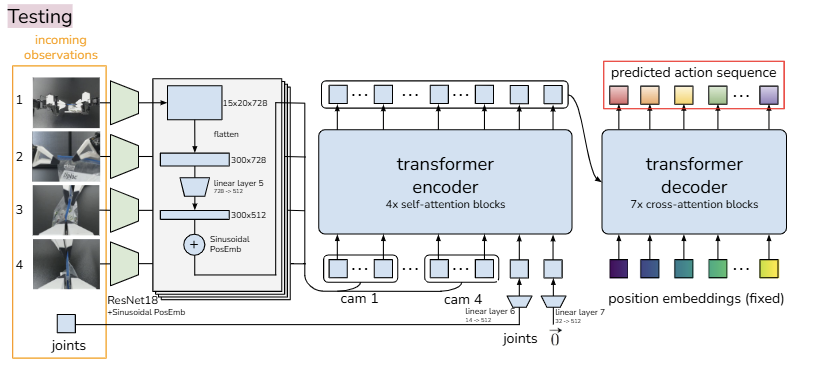
[테스트/추론 과정]
실제 로봇을 돌릴 때는 미래의 행동(정답)을 알 수 없으므로, step 2(encoder)는 생략됨
- 입력: 현재 카메라 이미지들(incoming observations) + 현재 관절 상태(joints)
- 잠재 변수 : 학습 때는 정답을 보고 를 만들었지만, 테스트 때는 를 0으로 설정(평균적인 스타일)하여 입력
- Transformer Encoder & Decoder : 학습 때와 동일하게 작동. 현재 상황(이미지)과 을 바탕으로 다음에 취해야 할 Action Chunk를 예측
- 실행: 예측된 개 행동을 실행. 이때 매 스텝마다 새로운 덩어리를 예측하고, 이를 겹쳐서 평균을 내는 Temporal Aggregation(시간적 집계) 방식을 사용하여 로봇의 떨림을 방지하고 부드러운 움직임을 구현

Algorithm 2 ACT Inference
추론 시에는 미래의 정답 행동()을 알 수 없으므로 인코더를 사용할 수 없음
- : 학습이 완료된 ACT 정책 모델 (Policy)
- : 전체 에피소드 길이 (작업 수행 시간)
- : 청크 사이즈 (Chunk size). 한 번에 예측하는 미래 행동의 길이
- : 버퍼 (Buffer). 예측된 행동들을 임시로 저장해두는 저장소
- : 행동 스타일 변수 (여기서는 0으로 고정)
- : 가중치 (Weight). 여러 예측값을 합칠 때 얼마나 신뢰할지 결정하는 값.
Step 1. 준비 단계 (Initialization)
Initialize FIFO buffers
→ 로봇이 움직일 모든 시간(부터 까지)에 대해 빈 방(Buffer)을 만든다. 앞으로의 예측되는 행동들을 버퍼에 차례로 쌓는다.
Step 2. 행동 예측 (Prediction)
매 타임스텝 마다 로봇은 현재 상황을 보고 미래를 예측
• 입력: 현재 관측()을 삽입
• : 학습 때는 를 다양하게 바꿨지만, 실전에서는 (평균값)을 넣어 가장 안정적이고 무난한 동작을 생성하도록 합니다.
• 출력: 현재 시점()부터 미래()까지의 행동 덩어리(개)가 나옵니다.
Step 3. 버퍼에 저장 (Add to Buffers)
Add to buffers
• 방금 예측한 개의 행동을 각각 해당하는 시간의 버퍼에 삽입
• 이렇게 하면, 특정 시간 의 버퍼 에는 과거()에 미리 예측해뒀던 행동들과 방금() 예측한 행동이 쌓이게 됨
Step 4. 시간적 집계 (Temporal Aggregation)
ACT가 부드럽게 움직이도록 쌓인 행동들의 평균을 구함
• : 시간 의 버퍼에 모인 모든 예측값 (예: 1초 전에 예측한 값, 0.5초 전에 예측한 값, 방금 예측한 값 등)
• 가중 평균 (Weighted Average): 이 값들을 그냥 더하는 게 아니라, 가중치 를 곱해서 평균을 냅니다.
• 가중치 : 값에 따라 얼마나 오래된 예측을 신뢰할지 결정함. 보통 최근에 예측한 값에 더 큰 가중치를 주거나, 혹은 겹치는 모든 구간을 부드럽게 잇기 위해 사용
V. EXPERIMENTS
본 논문은 정교한 조작 작업(Fine manipulation tasks)에서 ACT의 성능을 평가하기 위한 실험을 제시한다. 재현 용이성을 위해 ALOHA를 이용한 6가지 실제 환경 작업 외에도 MuJoCo [63]에서 2가지 시뮬레이션 정교한 조작 작업을 구축하였다.
A. Tasks (작업)
8개의 작업 모두 정교한 양팔 조작(Fine-grained, bimanual manipulation)을 필요로 하며 Figure 6에 묘사되어 있다.
- 지퍼백 열기(Slide Ziploc)
- 배터리 끼우기(Slot Battery)
- 양념병 열기(Open Cup)
- 벨크로 타이 묶기(Thread Velcro)
- 테이프 준비하기(Prep Tape)
- 신발 신기기(Put On Shoe)
- 큐브 전달(Transfer Cube) [시뮬레이션]
- 양팔 삽입(Bimanual Insertion) [시뮬레이션]
8개 작업 모두에서 물체의 초기 위치는 15cm 흰색 기준선(실제 환경 작업)을 따라 무작위로 변경되거나, 2D 영역(시뮬레이션 작업) 내에서 균일하게(Uniformly) 변경된다.
B. Data Collection
6가지 실제 환경 작업 모두에 대해, 본 논문은 ALOHA 원격 조작을 사용하여 데모를 수집한다. 각 에피소드는 작업의 복잡도에 따라 인간 운영자가 수행하는 데 8-14초가 소요되며, 이는 50Hz의 제어 주기를 고려할 때 400-700 타임스텝(Time steps)에 해당한다. 본 논문은 벨크로 타이 묶기(Thread Velcro) 작업(100개)을 제외하고 각 작업당 50개의 데모를 기록한다.
따라서 데모의 총량은 각 작업당 약 10-20분 분량의 데이터이며, 리셋(Resets)과 원격 조작자의 실수를 포함한 실제 소요 시간(Wall-clock time)은 30-60분 정도이다. 두 가지 시뮬레이션 작업의 경우, 스크립트 정책(Scripted policy)을 사용한 것과 인간 데모를 사용한 것의 두 가지 유형의 데모를 수집한다.
시뮬레이션에서의 원격 조작을 위해, 본 논문은 ALOHA의 "리더 로봇"을 사용하여 시뮬레이션된 로봇을 제어하며, 운영자는 모니터의 실시간 환경 렌더링 화면을 보고 조작한다. 두 경우 모두 50개의 성공한 데모를 기록한다.
C. Experiment Results
본 논문은 ACT를 4가지 기존 모방학습 방법들과 비교한다.
-
BC-ConvMLP는 가장 간단하면서도 널리 사용되는 베이스라인[69, 26]으로, 현재 이미지 관측을 합성곱 신경망(Convolutional network)으로 처리하고 그 출력 특징(Output features)을 관절 위치와 결합(Concatenated)하여 행동을 예측한다.
-
BeT [49] 또한 아키텍처로 트랜스포머(Transformers)를 활용하지만, 몇 가지 주요한 차이점이 있다. (1) action chunking(Action chunking)이 없다. 즉, 모델은 관측 히스토리가 주어졌을 때 하나의 행동만 예측한다. (2) 이미지 관측은 별도로 학습되어 고정된(Frozen) 시각 인코더(Visual encoder)에 의해 전처리된다. 즉, 인지(Perception) 네트워크와 제어(Control) 네트워크가 공동으로 최적화(Jointly optimized)되지 않는다.
-
RT-1 [7]은 고정된 길이의 과거 관측 히스토리로부터 하나의 행동을 예측하는 또 다른 트랜스포머 기반 아키텍처다. BeT와 RT-1 모두 행동 공간(Action space)을 이산화(Discretize)한다. 출력은 이산적인 빈(Bins)에 대한 범주형 분포(Categorical distribution)이며, BeT의 경우 빈 중심(Bin center)으로부터의 연속적인 오프셋(Continuous offset)이 추가된다. 반면 본 논문의 방법인 ACT는 정교한 조작에 요구되는 정밀함에 동기를 얻어 연속적인 행동(Continuous actions)을 직접 예측한다.\
-
마지막으로, VINN [42]은 테스트 시에 데모에 접근할 수 있다고 가정하는 비모수적(Non-parametric) 방법이다. 새로운 관측이 주어지면, 가장 유사한 시각적 특징을 가진 개의 관측을 검색(Retrieves)하고, 가중 k-최근접 이웃(Weighted k-nearest-neighbors)을 사용하여 행동을 반환한다. 시각적 특징 추출기(Visual feature extractor)는 비지도 학습(Unsupervised learning)으로 데모 데이터에서 미세 조정(Finetuned)된 사전 학습된(Pretrained) ResNet이다.
본 논문은 큐브 전달(Cube transfer) 작업을 사용하여 이 4가지 기존 방법들의 하이퍼파라미터를 세심하게 조정(Tune)했다. 하이퍼파라미터에 대한 자세한 내용은 부록 D에 제공된다.
기존 방법들과의 상세한 비교를 위해, 본 논문은 두 개의 시뮬레이션 작업과 두 개의 실제 환경 작업에 대한 평균 성공률을 Table I에 보고한다. 시뮬레이션 작업의 경우, 각 50회 시도의 3개 무작위 시드(Random seeds)에 걸친 평균 성능을 계산한다. 본 논문은 스크립트 데이터(구분선 왼쪽)와 인간 데이터(구분선 오른쪽) 모두에 대한 성공률을 보고한다. 실제 환경 작업의 경우, 하나의 시드를 25회 시도로 평가한다.
ACT는 모든 기존 방법 대비 가장 높은 성공률을 달성했으며, 각 작업에서 2위 알고리즘을 큰 격차로 따돌렸다. 스크립트 또는 인간 데이터를 사용한 두 시뮬레이션 작업에서, ACT는 최고 성능의 기존 방법보다 성공률 면에서 59%, 49%, 29%, 20% 더 앞섰다. 기존 방법들은 처음 두 개의 하위 작업에서는 진전(Progress)을 보였으나, 최종 성공률은 30% 미만으로 낮게 유지되었다.
두 실제 환경 작업인 지퍼백 열기(Slide Ziploc)와 배터리 끼우기(Slot Battery)에서, ACT는 각각 88%와 96%의 최종 성공률을 달성한 반면, 다른 방법들은 첫 단계를 넘어서지 못했다. 본 논문은 기존 방법들의 저조한 성능 원인을 누적 오차(Compounding errors)와 데이터 내의 비마르코프적(Non-Markovian) 행동 탓으로 돌린다. 행동은 에피소드 후반부로 갈수록 급격히 저하되며, 로봇은 특정 상태에서 무기한 멈출 수 있다. ACT는 action chunking(Action chunking)으로 두 문제 모두 완화한다. VI-A 절의 소거 연구(Ablations) 또한 청킹을 기존 방법에 통합했을 때 성능이 크게 향상될 수 있음을 보여준다. 또한 시뮬레이션 작업에서 스크립트 데이터에서 인간 데이터로 전환할 때 모든 방법의 성능 하락을 확인했다. 인간 데모의 확률성(Stochasticity)과 멀티모달성(Multi-modality)이 모방학습을 훨씬 더 어렵게 만들기 때문이다.
본 논문은 남은 3개의 실제 환경 작업에 대한 성공률을 Table II에 보고한다. 이 작업들에 대해서는 지금까지 가장 높은 성공률을 보인 BeT하고만 비교한다. 본 논문의 방법인 ACT는 컵 열기(Cup Open)에서 84%, 벨크로 타이 묶기(Thread Velcro)에서 20%, 테이프 준비(Prep Tape)에서 64%, 신발 신기기(Put On Shoe)에서 92%의 성공률을 기록하며, 이 까다로운 작업들에서 최종 성공률 0%를 기록한 BeT를 다시 한번 능가했다.
벨크로 타이 묶기에서 ACT의 성공률이 상대적으로 낮은 것을 관찰했는데, 첫 단계 92% 성공에서 최종 20% 성공으로 단계마다 성공률이 대략 절반씩 감소했다.
관찰된 실패 모드(Failure modes)는 1) 2단계에서 오른쪽 팔이 그리퍼를 너무 일찍 닫아 공중에서 타이의 꼬리를 잡지 못하는 경우, 2) 3단계에서 삽입이 충분히 정밀하지 않아 고리를 놓치는 경우다. 두 경우 모두 이미지 관측으로부터 케이블 타이의 정확한 위치를 파악하기 어렵다. 검은색 케이블 타이와 배경 사이의 대비(Contrast)가 낮고, 타이가 이미지에서 차지하는 비율이 작기 때문이다. 부록 B에 이미지 관측 예시를 포함한다.
VI. ABLATIONS
A. Action Chunking and Temporal Ensembling (action chunking 및 시간적 앙상블)
V-C 절에서 본 논문은 ACT가 단일 단계 행동만을 예측하는 기존 방법들을 크게 능가함을 관찰했으며, 이에 대한 가설로 action chunking(Action chunking)이 핵심 설계 선택임을 제시했다. 가 각 "청크"의 시퀀스 길이를 결정하므로, 를 변화시켜 이 가설을 분석할 수 있다.
은 action chunking이 없는 경우에 해당하며, 는 첫 번째 관측만을 바탕으로 전체 에피소드의 행동 시퀀스를 출력하는 완전한 개루프 제어(Open-loop control)에 해당한다. 본 실험에서는 청킹의 효과만을 측정하기 위해 시간적 앙상블(Temporal ensembling)을 비활성화했으며, 각 에 대해 별도의 정책을 학습시켰다.
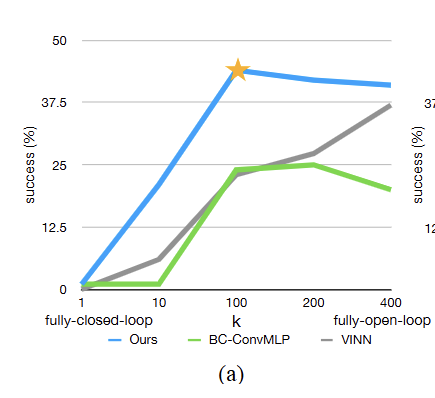
Figure 8 (a)에서 4가지 설정(인간 또는 스크립트 데이터를 사용한 2가지 시뮬레이션 작업)에 대한 평균 성공률을 도식화했으며, 파란색 선은 시간적 앙상블이 없는 ACT를 나타낸다. 성능이 일 때 1%에서 일 때 44%로 급격히 향상되다가, 가 더 높아지면 약간 감소함을 관찰했다.
이는 청킹을 많이 할수록, 그리고 유효 호라이즌(Effective horizon)이 낮을수록 일반적으로 성능이 향상됨을 보여준다. (즉, 개루프 제어에 가까움)에서의 약간의 성능 하락은 반응형 행동(Reactive behavior)의 부재와 긴 행동 시퀀스 모델링의 어려움 때문으로 판단된다.
액션 청킹의 효과와 일반성을 추가로 평가하기 위해, 두 가지 베이스라인 방법에 액션 청킹을 적용했다. BC-ConvMLP의 경우 단순히 출력 차원을 으로 늘렸고, VINN의 경우 다음 개의 행동을 검색하도록 했다.
Figure 8 (a)에 다양한 에 따른 이들의 성능을 시각화했으며, ACT와 일관되게 action chunking이 많을수록 성능이 향상되는 경향을 보였다. 비록 ACT가 여전히 두 가지 증강된 베이스라인을 상당한 격차로 앞서지만, 이 결과는 action chunking이 이러한 설정의 모방학습에 일반적으로 유익함을 시사한다.
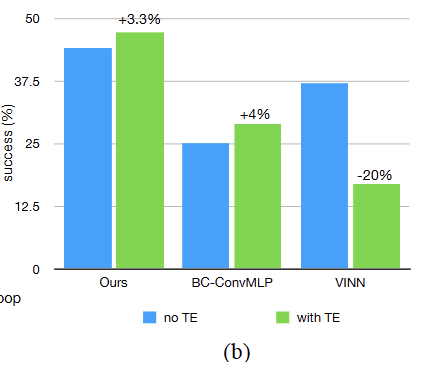
다음으로 앞서 언급한 4가지 작업과 다양한 에 대해, emporal ensembling 적용 유무에 따른 최고 성공률을 비교하여 emporal ensemble을 소거 분석한다. emporal ensemble 유무에 따른 실험은 별도로 튜닝되었다는 점을 참고해야 한다. 즉, emporal ensemble이 없을 때 최적이었던 하이퍼파라미터가 있을 때는 최적이 아닐 수 있다.
Figure 8 (b)에서 BC-ConvMLP가 4%의 이득으로 emporal ensemble의 혜택을 가장 많이 보았고, 본 논문의 방법(ACT)이 3.3% 이득으로 그 뒤를 이었다. 반면 비모수적(Non-parametric) 방법인 VINN에서는 성능 하락을 확인했다. 본 논문은 emporal ensemble이 주로 모수적(Parametric) 방법들의 모델링 오차를 평활화(Smoothing)하여 이득을 준다고 가설을 세운다. 대조적으로 VINN은 데이터셋에서 실제 정답(Ground-truth) 행동을 검색하므로 이러한 문제를 겪지 않는다.
B. CVAE를 이용한 학습 (Training with CVAE)
본 논문은 노이즈가 많고 멀티모달(Multi-modal) 행동을 포함할 수 있는 인간 데모를 모델링하기 위해 CVAE 목적 함수(Objective)로 ACT를 학습시킨다. 이 섹션에서는 CVAE 목적 함수 없이 단순히 현재 관측(Observation)이 주어졌을 때 행동 시퀀스를 예측하며 L1 손실(Loss)로 학습된 ACT와 비교한다.
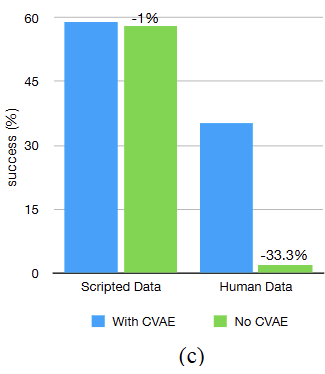
Figure 8 (c)에서 2개의 시뮬레이션 작업에 대해 집계된 성공률을 시각화하고, 스크립트 데이터(Scripted data)로 학습한 경우와 인간 데이터(Human data)로 학습한 경우를 별도로 도식화한다.
스크립트 데이터로 학습할 때는 데이터셋이 완전히 결정론적(Deterministic)이기 때문에 CVAE 목적 함수를 제거해도 성능에 거의 차이가 없음을 알 수 있다. 반면 인간 데이터의 경우, 성공률이 35.3%에서 2%로 급격히 하락한다. 이는 인간 데모로부터 학습할 때 CVAE 목적 함수가 필수적임을 보여준다.
C. 고빈도 제어는 필수적인가? (Is High-Frequency Necessary?)
마지막으로, 정교한 조작을 위해 고빈도 원격 조작(High-frequency teleoperation)의 필요성을 보여주기 위해 사용자 연구(User study)를 수행한다. 동일한 하드웨어 설정에서 주파수를 50Hz에서 5Hz로 낮추는데, 이는 고용량 심층 신경망(Deep networks)을 모방학습에 사용하는 최근 연구들과 유사한 제어 주파수이다 [7, 70]. 본 논문은 두 가지 정교한 작업, 즉 케이블 타이 묶기(Threading a zip cable tie)와 두 개의 플라스틱 컵 분리하기(Un-stacking two plastic cups)를 선정했다. 두 작업 모두 밀리미터 수준의 정밀도와 폐루프 시각 피드백(Closed-loop visual feedback)을 필요로 한다.
본 논문은 ALOHA를 사용해본 적은 없지만 다양한 수준의 원격 조작 경험을 가진 6명의 참가자를 대상으로 연구를 수행했다. 참가자들은 컴퓨터 공학 대학원생들 중에서 모집되었으며, 22-25세의 남성 4명과 여성 2명으로 구성되었다. 작업 순서와 주파수는 참가자마다 무작위로 배정되었으며, 각 참가자에게는 매 시도 전 2분의 연습 시간이 주어졌다.
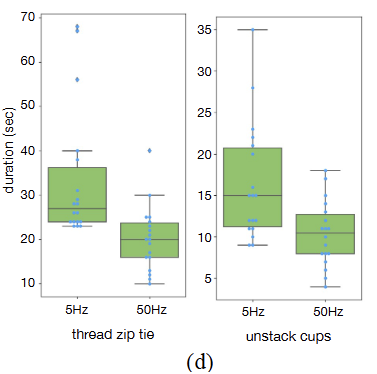
본 논문은 3회 시도에 대해 작업 수행 시간을 기록하고 데이터를 Figure 8 (d)에 시각화했다. 평균적으로 참가자들이 5Hz에서 케이블 타이를 묶는 데 33초가 걸렸으나, 50Hz에서는 20초로 단축되었다. 플라스틱 컵 분리하기의 경우, 제어 주파수를 높임으로써 작업 시간이 16초에서 10초로 줄어들었다.
종합적으로, 본 논문의 설정(즉, 50Hz)은 참가자들이 매우 기교 있고(Dexterous) 정밀한 작업을 짧은 시간 안에 수행할 수 있게 한다. 반면, 주파수를 50Hz에서 5Hz로 줄이면 원격 조작 시간이 62% 증가하는 결과를 초래한다.
본 논문은 "반복 측정 설계(Repeated Measures Designs)"라는 통계적 절차를 사용하여 50Hz 원격 조작이 5Hz보다 우수함을 p-value < 0.001 수준에서 공식적으로 검증한다.
VII. LIMITATIONS AND CONCLUSION
본 논문은 원격 조작 시스템 ALOHA와 새로운 모방학습 알고리즘 ACT로 구성된, 정교한 조작(Fine manipulation)을 위한 저비용 시스템을 제안한다. 이 두 부분 간의 시너지는 반투명 양념병 열기나 배터리 끼우기와 같은 정교한 조작 기술을 약 10분의 데모만으로 80-90%의 성공률로 실제 환경(Real-world)에서 직접 학습할 수 있게 해준다.
비록 이 시스템이 상당히 유능하지만, 와이셔츠 단추 잠그기(Buttoning up a dress shirt)와 같이 로봇이나 학습 알고리즘의 능력을 벗어나는 작업들이 여전히 존재한다. 한계점에 대한 더 자세한 논의는 Appendix F에 포함되어 있다. 종합적으로, 본 논문은 이 저비용 오픈소스 시스템이 정교한 로봇 조작(Fine-grained robotic manipulation)을 발전시키는 데 있어 중요한 발걸음이자 접근 가능한 자원이 되기를 희망한다.

논문 이렇게 빨리 분석하고 읽는 방법 좀 알려주세요!