
전에 연구실에서 adversarial attack 관련 논문들을 잠깐 찾아본 적 있었는데, 이번에 머신러닝 보안 관련 수업을 듣게 되면서 관련 분야에 대해 다시 공부해볼 기회가 생겼다.
수업 방식이 관련 논문 보고 프레젠테이션 하는 방식이라.. 이전에 정리했던 내용들을 리뷰 겸 velog에 옮겨보려고 한다.
Adversarial Attack이란 ?
모델에 imperceivable perturbation을 가한 입력(adversarial examples)을 넣어 잘못된 예측을 하도록 유도하고, 모델의 정상 작동을 방해하는 기법이다.
defense 관점에서 보면, 모델의 robustness (또는 generalization 정도)를 평가하는 방법으로도 사용될 수 있다.

위 그림은 adversarial attack을 제안한 Ian J. Goodfellow et al., "EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES," (ICRA 2015) 논문에 실린 것으로, Adversarial Attack에 대해 잘 설명해주는 그림이다.
모델이 57.7%의 confidence로 "panda"라고 인식한 그림에 어떠한 noise를 주입하면, 그 그림은 사람의 눈에는 그대로 "panda"로 보이지만 모델은 99.3%의 confidence로 "gibbon"으로 인식해 버린다.
이렇게 사람의 눈에 보이지 않으나 모델의 예측에 영향을 주도록 주입된 noise를 perturbation 이라고 한다.
White-box Attack vs. Black-box Attack
adversarial attack에는 두 가지 부류가 있다. ML을 공부한 사람이라면 white box, black box라는 용어에 대해 들어본 적이 있을 것이고, 어떤 의미인지 바로 감이 올 것이다.
- White box attack
attacker가 target model에 모든 접근 권한을 가진다. (weight, model architecture 등에 대한 정보를 알 수 있음)
→ gradient-based optimization을 통하여 target model network의 error를 최대화하는 adversarial example을 생성한다.
- Black box attack
attacker가 target model에 대한 정보를 알 수 없다. (모델에 특정 값을 입력했을때, 이에 대한 출력값만 볼 수 있음)
→ gradient computation 수행 불가. target model의 입출력을 관찰하고 모방하여 adversarial example을 생성한다.
난이도적인 측면에서 보면 당연히 white box attack이 좋지만, 실용적이지 않다. 완전한 오픈 소스 모델이 아니라면, 실제 상황에서 공격자가 모델 구조나 가중치에 대해서 알기는 어렵다. 따라서, 실용적인 측면에서 보면 black box attack을 사용하여야 한다.
Adversarial Training
위에서 잠깐 언급했지만 adversarial attack을 defense 관점에 적용하면, 모델의 robustness를 향상하는 한 방법이 될 수 있다.
adversarial training은 attack에 사용되는 adversarial example을 추가 학습 데이터로 활용하여 모델의 generalization 성능을 높이고, data augmentation 효과도 누릴 수 있다.

FGSM and PGD
FGSM(Fast Gradient Sign Method)과 PGD(Projected Gradient Descent)는 대표적인 gradient-based adversarial example generation 기법이다.
- FGSM(Fast Gradient Sign Method)
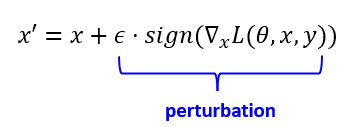
손실 함수 𝐿에 대한 입력 x의 gradient를 계산. gradient의 sign만을 취하여 입력에 더함으로써 입력 데이터에 작은 perturbation을 가하는 방법
ϵ는 perturbation 값을 제어하는 파라미터로, 작을수록 perturbation의 크기도 작아진다.
한번의 기울기 계산만 수행하므로 빠르고 계산 비용이 낮은 것이 특징이다.
- PGD(Projected Gradient Descent)

FGSM을 반복 수행하여, gradient를 update하고 더 강력한 adversarial example을 생성하는 방법
손실 함수의 기울기 방향에 따라 perturbation을 𝛼만큼 추가한다. 각 단계에서는 projection 연산을 통해, perturbation을 [−ϵ,ϵ] 범위 내로 제한한다.
PGD는 반복적으로 perturbation을 update하므로, FGSM보다 훨씬 더 강력한 adversarial example을 생성할 수 있다.
Transfer Attack
Query-based attack and Transfer attack
- Query-based attack
target model의 정보를 모르는 상황에서, 모델의 입출력 관계를 활용하여 adversarial example을 생성하는 방법
(1) 공격자가 target model에 쿼리를 보내고, (2) 이에 대한 출력 결과를 관찰한다.
(1) ~ (2)의 과정을 반복 수행하면서 모델의 예측을 변화시키는 adversarial example을 탐색한다.
많은 쿼리와 연산을 필요로 할 수 있다.
- Transfer attack
source model에 대하여 adversarial example을 생성하고, 이 example을 target model에 입력하여 target model도 잘못된 예측을 하게 하는 방법. 주로 white box model을 source model로 사용하여 black box model로 전이시킨다.
query-based attack보다 challenging 하지만, 비용 문제를 고려하면 더 실용적이라고 볼 수 있다.
transfer attack은 target model을 query할 필요 없고, attack에 필요한 computational cost가 상대적으로 낮다.
surrogate model을 훈련하여 target model을 모방한다.
여기서 surrogate model이란, 실제 환경과 유사하게 동작하도록 학습되는 대체 모델을 뜻한다.
Adversarial attack에서 surrogate model은 target model을 대신하여 사용될 수 있다. attacker는 surrogate model에 대한 정보를 이용하여 adversarial example을 생성하고, 이를 target model에 적용한다. 실제 모델의 computational cost가 높은 경우, 그리고 target model에 대한 정보가 부족한 경우에 surrogate model을 통해 adversarial example 생성 비용을 줄이고 효율적인 attack이 가능해진다.
이러한 transfer attack의 성능을 높이기 위해서는, surrogate(source) model과 target model의 유사성이 높은 것이 유리하다.
이러한 관점에서 나오게 된 방법은 Domain Adaptation 으로, source domain에서 학습한 모델을 target domain에 잘 적용할 수 있도록 두 domain 간의 차이를 줄이는(feature distribution을 유사하게 하는) 기법이다.
ADDA (Adversarial Discriminative Domain Adaptation)
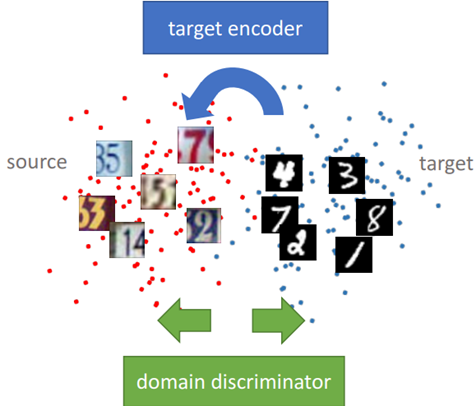
adversarial learning과 discriminative feature learning을 결합한 domain adaptation method이다.
-
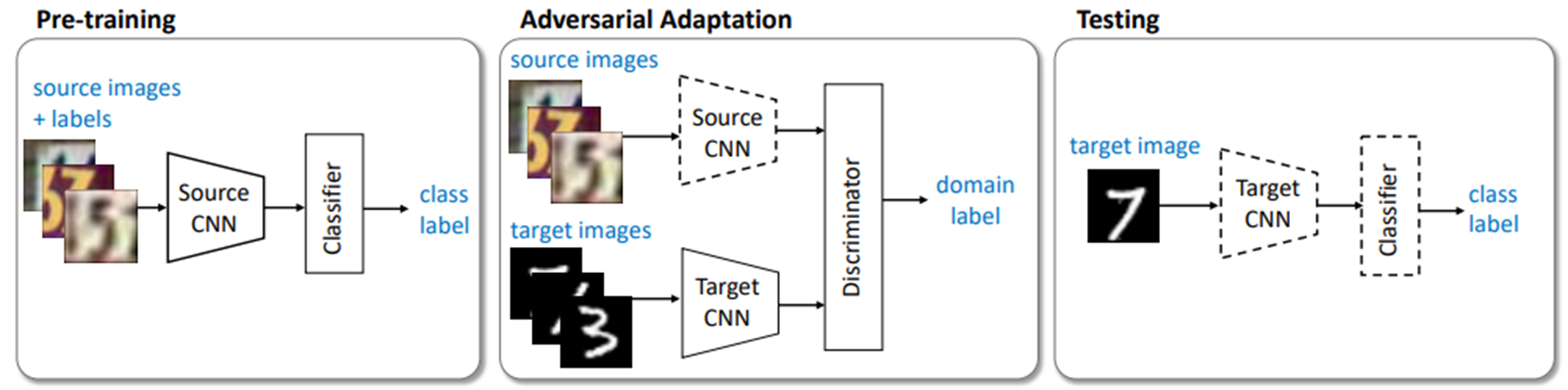
Pretraining : source domain의 labeled image를 사용하여 source CNN 모델을 사전학습하고, source domain image를 분류할 수 있도록 한다
-
Adversarial Adaptation : discriminator와 target encoder CNN을 adversarial training 한다. discriminator는 target CNN의 출력 특징맵을 구분할 수 있도록 학습 (discriminative)되며, target CNN은 discriminator를 속이도록 (adversarial) 학습된다.
결과적으로 target CNN이 target domain의 이미지를 source domain의 feature space에 잘 매핑할 수 있게 한다. -
Testing : target CNN을 사용하여, target domain의 이미지를 source domain의 feature space로 매핑한 후, pretrained source CNN 을 사용하여 분류한다.
이 방법은 target domain의 label information을 필요로 하지 않아 유용하다.
