으악 1주 1논문 하려다가 출장 일정때문에 드디어 완독해서 올리는 리뷰!!!! 😢
진짜진짜 꾸준히 조지려고 했는데 핑계지만 한동안 읽을 정신이 없었다..
아무튼!!! 올해 요 논문이 거의 마지막 리뷰 논문이 될 것 같다. ㅠㅠ 2022 바이...

본 포스팅은 BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension(2019) 논문을 읽고 내용 요약 및 정리한 내용이다.
섹션 6의 Qualitative Analysis, 섹션 7의 Related Work 부분은 생략하고 정리해 두었다.
들어가기 전 (Abstract)
BART는 seq2seq 모델을 사전학습하기 위한 denoising autoencoder(DAE, 잡음제거 오토 인코더)다.
BART는 (1) 임의의 noising function으로 텍스트를 손상시키고, (2) 모델이 원본 텍스트를 재구축할 수 있도록 학습시킨다. BART는 표준 Transformer 기반 뉴럴 기계 번역 구조를 사용하는데, 이러한 구조는 단순하면서도 BERT(양방향 인코더), GPT( left-to-right decoder), 그리고 다른 최신 사전학습 방법들을 일반화하는 것으로 볼 수 있다.
본 논문에서는 많은 잡음 부여 접근법(noising approaches)에 대해 평가하는데, 일정 구간 텍스트가 단일 마스크 토큰으로 대체되는 원본 문장의 순서를 뒤섞고 새로운 in-filling scheme을 사용함으로써 가장 최고의 성능을 찾는다.
BART는 텍스트 생성(text generation)을 위해 파인튜닝될 때 특히 효율적이며, 독해 태스크(comprehension task)에도 잘 작용한다. BART는 GLUE와 SQuAD에서 비슷한 training resources를 사용한 RoBERTa의 성능과 필적하고, abstractive dialogue, QA, summarization task와 같은 다양한 범주에서 6 ROUGE(텍스트 요약 모델의 성능 평가 지표)까지 성능을 끌어올리며, 새로운 SOTA 성능을 가져온다.
또한, BART는 타겟 언어 사전학습만으로 기계 번역의 back-translation system에서 1.1 BLEU 스코어를 상승시킨다. 본 논문에서는 BART 프레임워크 내에서 다른 사전학습 방법들을 모방하여(replicate) 어떤 요인이 앤드 테스크의 성능에 가장 큰 영향을 끼치는지 더 잘 측정하고자 한다.
1. Introduction
자기지도(Self-supervised) 방법론은 다양한 NLP 태스크에서 큰 성공을 가져왔다. 가장 성공적인 접근법은 MLM(Masked Language Model)의 변형으로, 이러한 접근법은 임의 단어들의 부분집합이 마스킹된 텍스트를 재구축(reconstruct)하도록 학습되는 denoising autoencoder(잡음 제거 오토인코더)이다. 최신 연구는 마스킹된 토큰의 분배, 마스킹된 토큰의 예측 순서, 마스킹된 토큰의 대체 문맥을 개선함으로써 발전해 왔다. 그러나 이러한 방법론들은 전형적으로 앤드 태스크의 특정 유형에만 집중하며, 적용가능성(applicability)을 제한시킨다 (예를 들면, 구간 예측, 생성 등).
본 연구는 양방향 트랜스포머(bidirectional Transformer)와 자기 회귀 트랜스포머(auto-regressive Transformer)를 결합한 모델을 학습시키는 BART를 제시한다. BART는 상당히 광범위한 앤드 태스크에 적용할 수 있는 seq2seq 모델로 구축된 잡음 제거 오토인코더다. 사전 학습은 2가지 단계로, (1) 텍스트가 임의 잡음 함수에 의해 손상되고, (2) seq2seq 모델이 원본 텍스트를 재구축하기 위해 학습된다. BART는 표준 트랜스포머 기반 뉴럴 기계 번역 구조를 사용하는데, 이러한 구조는 그 단순성에도 불구하고, BERT(양방향 인코더), GPT(우향 디코더), 그리고 다른 최신 사전학습 방법들을 일반화하는 것으로 볼 수 있다 (Figure 1 참조).
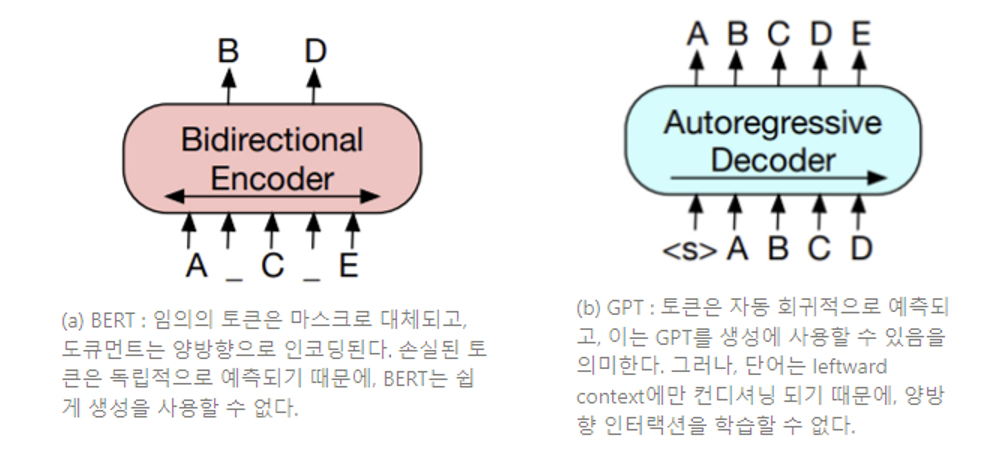
(Figure 1) BART와 BERT(Devlin et al., 2019) 그리고 GPT (Radford et al., 2018) 도식적 비교
2. Model
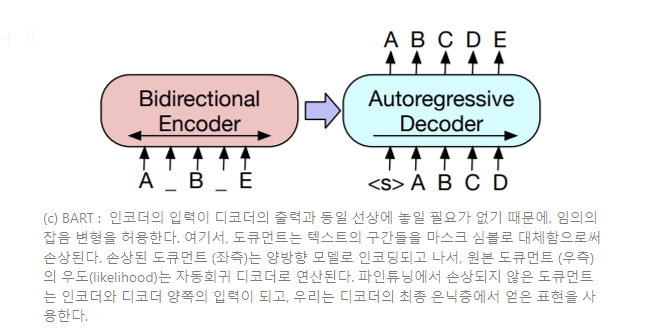
BART는 손상된 도큐먼트를 원본 도큐먼트에 사상시키는 잡음 제거 오토인코더이다. 이는 손상된 텍스트에 대하여 양방향 인코더와 우향(left-to-right) 자기회귀 디코더를 갖는 seq2seq 모델로 구현된다. 우리는 사전학습을 위해 원본 도큐먼트의 음의 로그 우도(negative log-likelihood)를 최적화한다.
BART는 Vaswani et al. (2017)의 표준 seq2seq Transformer 구조를 사용하는데, GPT를 계승하여 ReLU 활성화 함수를 GeLUs로 변경하여 사용하고, (0, 0.02)`에서 파라미터를 초기화한다. 베이스 모델은 인코더와 디코더에 6개의 층을 사용하고, 라지 모델에서는 각각 12층을 사용한다.
이러한 구조는 BERT에서 사용되는 구조와 밀접하게 연관되어 있는데, 다음과 같은 차이점이 있다 : (1) 디코더의 각 층은 인코더의 최종 은닉층에 cross-attention을 수행한다 (transformer seq2seq model에서와 같음). 그리고 (2) BERT는 단어 예측 이전에 부가적으로 피드 포워드 신경망을 사용하는데, BART에서는 이러한 신경망을 사용하지 않는다. 종합하면, BART는 동등한 크기의 BERT 모델보다 대략 10%개의 파라미터를 더 많이 갖는다.
BART는 도큐먼트를 손상시킨 후 재구축 손실, 즉 디코더의 출력과 원본 도큐먼트 간의 크로스 엔트로피 손실을 최적화함으로써 학습된다. 특정한 noising scheme에 맞추어진 기존 잡음 제거 오토인코더와는 다르게, BART는 어떠한 부류의 도큐먼트 손상에도 적용할 수 있도록 한다.
본 논문에서는 도큐먼트 변형 방법(손상 방법)들에 대해 실험하는데, 사용된 변형법은 아래서 설명하며 Figure 2에서 그 예를 보여준다.
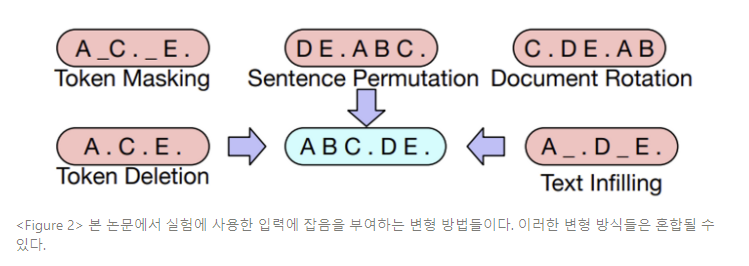
- Token Masking(토큰 마스킹) : BERT와 같이 임의의 토큰이 샘플되고 [MASK] 엘리먼트로 대체된다.
- Token Deletion(토큰 제거) : 임의의 토큰은 입력에서 제거된다. 토큰 마스킹과는 대조적으로, 모델이 어떤 위치의 입력이 손실될지 정해야 한다.
- Text Infilling(텍스트 내부 삽입) : 많은 텍스트 구간이 샘플링되는데, 구간 길이는 포아송 분포 (λ = 3)에서 도출된다. 각 구간은 단일 [MASK] 토큰으로 대체된다. 길이 0 구간은 [MASK] 토큰의 입력에 대응한다.
Text infilling은 SpanBERT에서 영감을 받은 것인데, SpanBERT는 다양한 (고정된) 기하 분포에서 구간 길이를 샘플링하고, 각 스팬을 정확히 같은 길이의 일련의 [MASK] 토큰으로 대체한다. Text infilling은 얼마나 많은 토큰이 한 구간에서 손실되었는지를 모델에 학습시킨다.- Sentence Permutation(문장 치환) : 도큐먼트는 마침표에 기반하여 문장으로 나뉘어 지고, 이러한 문장들은 임의의 순서로 뒤섞인다.
- Document Rotation(도큐먼트 순환) : 토큰은 임의로 균일하게 선택되고, 도큐먼트는 순환하여 그 토큰으로 시작할 수 있도록 한다. 이러한 태스크는 모델이 도큐먼트의 시작을 식별할 수 있도록 훈련시킨다.
3. Fine-tuning BART
BART에서 생성된 표현(representations)은 다운스트림에 적용하기 위해 몇 가지 방식으로 사용될 수 있다.
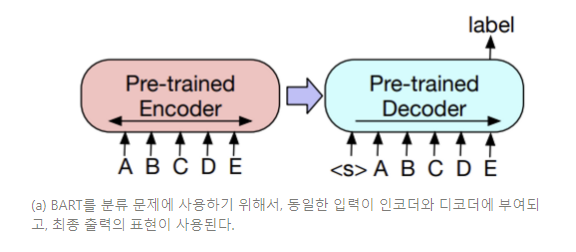
시퀀스 분류(sequence classification) 태스크를 위해, 인코더와 디코더에 동일한 입력이 부여되고, 최종 디코더 토큰의 최종 은닉층이 새로운 다중 분류 선형 분류기에 입력된다. 이러한 접근법은 BERT의 CLS 토큰과 연관되어 있다. 그러나, 우리는 디코더의 토큰 표현이 완전한 입력에서 디코더 상태에 집중할 수 있도록 최종적으로 부가적인 토큰을 추가한다. (Figure 3a)
SQuAD의 answer endpoint 분류와 같은 토큰 분류(Token Classification) 태스크를 위해, 우리는 완전한 도큐먼트를 인코더와 디코더에 입력하고, 디코더 은닉층의 최상층을 각 단어의 표현으로 사용한다. 이러한 표현은 토큰을 분류하기 위해 사용된다.
BART는 자기회귀 디코더를 갖기 때문에, abstractive QA와 summarization과 같은 시퀀스 일반화(Sequence Generation) 태스크에 직접적으로 파인튜닝 될 수 있다. 이러한 태스크에서, 정보는 마스킹된 토큰 입력으로부터 복제되지만 조작되는데(manipulated), 이는 잡음 제거 사전학습 objective와 밀접하게 연관되어 있다. 여기서, 인코더의 입력은 입력 시퀀스이며, 디코더는 출력을 자기회귀적으로 생성한다.
또한, BART를 사용하여 영어 기계 번역 디코더를 발전시키는 방법을 탐구한다. 선행 연구 Edunov et al. (2019)는 사전학습 인코더를 통합함으로써 모델이 발전할 수 있다는 것을 입증했으나, 디코더에서 사전학습 언어 모델을 사용하여 얻는 이점은 제한되어 있었다. 본 논문에서는 bitext에서 학습된 새로운 인코더 파라미터 셋을 더하여 전체 BART 모델을 (인코더와 디코더 모두) 기계 번역을 위한 하나의 단일 사전학습 디코더로서 사용하는 것이 가능함을 입증한다 (Figure 3b 참조).
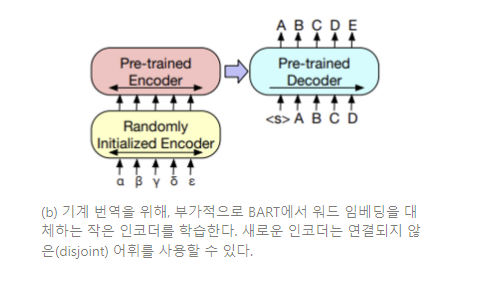
(Figure 3) 분류와 번역을 위한 BART 파인튜닝
더 명확하게, 본 연구에서는 BART의 인코더 임베딩 레이어를 임의로 새로 초기화된 인코더로 대체한다. 이러한 모델은 end-to-end로 학습되는데, 이는 새로운 인코더가 외래어를 BART가 잡음을 제거하여 영어로 만들 수 있는 입력으로 사상시키도록 학습시킨다. 새로운 인코더는 원본 BART 모델에서 분리된 어휘를 사용할 수 있다.
본 연구에서는 원천 인코더를 두 단계로 학습시키는데, 모든 경우에 BART 모델의 출력으로부터 크로스 엔트로피 손실을 역전파한다. 첫 단계에서 우리는 BART의 파라미터 대부분을 동결시키고, 임의로 초기화된 원천 인코더와 BART의 positional embedding, 그리고 BART 인코더의 첫번째 레이어에서 셀프 어텐션 입력 투영 행렬(self-attention input projection matrix)만을 업데이트한다. 두 번째 단계에서, 약간의 이터레이션으로 모든 모델 파라미터를 학습시킨다.
4. Comparing Pre-training Objectives
BART는 이전 연구보다 사전학습 동안의 잡음 부여 방법을 훨씬 더 다양하게 지원한다. 본 논문에서는 베이스 모델(768개의 은닉층을 가진 6 인코더와 6 디코더 층)을 사용하여 해당 방법들을 비교한다.
다수의 사전학습 objectives가 제안되어 왔지만, objectives간 공정한 비교를 수행하는 것은 어렵다.이는 모델의 학습 데이터, 학습 원천, 구조적 차이와 파인튜닝 절차에 차이가 있기 때문이다. 본 연구에서는 최근 식별과 생성 태스크를 위해 제안된 강력한 사전학습 접근법을 재시행하고, 가능한 사전학습 objective에 연관되지 않은 차이를 통제하고자 한다. 그러나, 성능을 향상시키기 위해 학습률과 레이어 정규화(Layer normalization)의 사용에 약간의 차이를 둔다(각각의 objective에 이를 개별적으로 튜닝함). 참조를 위해, BERT(일부 도서의 결합과 위키피디아 데이터로 1M step동안 학습된)와 BART의 시행을 비교한다. 비교된 접근법은 다음과 같다 :
- Language Model : GPT와 유사하게, left-to-right Transformer language model을 학습시킨다. 이러한 모델은 cross-attention을 제외한 BART의 decoder와 동등하다.
- Permuted Language Model : XLNet에 기반하여, 토큰 1/6을 샘플링하고 이를 임의의 순서에서 자동회귀적으로 생성한다. 다른 모델과 동일성(consistency)을 유지하기 위해, 우리는 XLNet의 상대적인 포지셔널 임베딩 또는 세그먼트 어텐션을 시행하지 않는다.
- Masked Language Model : BERT를 계승하여, 15%의 토큰을 [MASK] 심볼로 대체하고, 원본 토큰을 독립적으로 예측하기 위해 모델을 학습시킨다.
- Multitask Masked Language Model :
UniLM에서와 같이, Masked Language Model을 additional self-attention mask로 학습시킨다. Self attention mask는 다음의 비율에서 임의로 선택된다 : 1/6 left-to-right, 1/6 right-to-left, 1/3 unmasked, 1/3 에서 처음 50% 토큰은 unmasked 그리고 나머지를 left-to-right mask.- Masked Seq-to-Seq :
MASS(Song et al., 2019)에서 영감 받아, 토큰의 50%을 포함한 구간을 마스킹하고 seq2seq 모델을 학습하여 마스킹된 토큰을 예측한다.
본 연구는 Permuted LM, Masked LM과 Multitask Masked LM에서 two-stream attention을 사용하여 시퀀스의 출력부의 우도를 효율적으로 연산한다 (left-to-right 단어를 예측하기 위해 diagonal self-attention mask를 출력에 사용).
본 연구에서는 (1) 태스크를 표준 seq2seq 문제로 취급하여, 원천 입력은 인코더에 타겟은 디코더 출력이 되거나 또는, (2) 원천을 타겟의 prefix로 디코더에 더하고, 시퀀스의 타겟 부분의 손실만을 계산하는 것을 실험한다. 우리는 전자는 BART 모델에서 더 잘 작용하고, 후자는 다른 모델에서 더 잘 작용함을 발견한다.
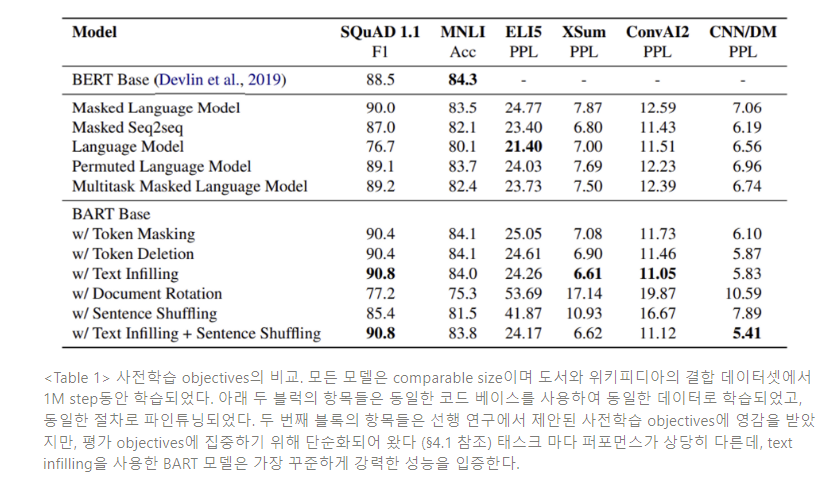
Table 1에 퍼플렉서티(perplexity)를 정리하여 모델의 파인튜닝 objective (human text의 로그 우도)를 모델링하는 능력을 가장 직접적으로 비교한다.
- SQuAD : 위키피디아 문단에서 추출한 QA 태스크. 답변은 주어진 도큐먼트 문맥에서 추출된 텍스트의 일정 구간이 된다. BERT와 유사하게, 우리는 연결된 질문과 문맥을 BART의 인코더에 입력으로 사용하고, 부가적으로 디코더에 전달한다. 이러한 모델은 각 토큰 시작과 끝 인덱스를 예측하는 분류기를 포함한다.
- MNLI : 한 문장이 다른 문장을 수반하는지를 예측하는 bitext classification task. 파인튜닝된 모델은 첨부된 EOS token과 두 문장을 연결하고, 이것들을 BART의 인코더와 디코더에 모두 전달한다. BERT와는 대조적으로, EOS token의 표현은 문장의 관계를 분류하는 데 사용된다.
- ELI5 : long-form abstractive QA dataset. 모델은 문제와 이에 뒷받침하는 도큐먼트의 연결로 처리된 답변을 생성한다.
- XSum : 상당히 추상적인 요약을 제공하는 뉴스 요약 데이터셋
- ConvAI2 : context와 persona로 처리된 대화 응답 생성 태스크
- CNN/DM : 뉴스 요약 데이터셋. 이 데이터셋의 요약은 전형적으로 원천 문장과 긴밀하게 연관되어 있다.
Table 1의 결과를 보면, 몇가지 명확한 추세가 있다.
- Performance of pre-training methods varies significantly across tasks(사전학습 방법론의 성능은 태스크마다 매우 다름) 사전학습 방식의 효율성은 태스크에 크게 의존한다. 예를 들면, 단순한 언어 모델이 최고의 ELI5 성능을, 그러나 SQUAD에서는 최저 성능을 거둔다.
- Token masking is crucial(토큰 마스킹은 중요하다) 도큐먼트를 순환시키거나 문장을 치환하는 데 기반한 사전학습 objectives는 독립적으로 좋지 않은 성능을 보인다. 성공적인 방법은 token deletion 또는 masking을 사용하거나, self-attention mask를 사용하는 것이다. Deletion은 생성 태스크에서 마스킹을 능가하는 것으로 보인다.
- Left-to-right pre-training improves generation (left-to-right 사전학습은 생성 성능을 향상시킨다) Masked Language Model과 Permuted Language Model은 생성 부문에서 퍼포먼스가 떨어지고, 이 모델들은 사전학습 동안 left-to-right auto-regressive language modeling을 사용하지 않는 유일한 모델들이다.
- Bidirectional encoders are crucial for SQuAD (SQuAD에서 양방향 인코더는 중요하다) 이전 연구에서 주목한것과 같이, left-to-right decoder만이 SQuAD의 성능이 떨어지는데, 이는 future text가 분류 결정에서 중요하기 때문이다. 그러나, BART는 양방향 레이어 수의 절반만으로 유사한 성능을 얻는다.
- The pre-training objective is not the only important factor (사전학습 objective만이 중요한 요인인 것은 아니다) Permuted Language Model은 XLNet보다 성능이 떨어진다. 이러한 차이의 일부는 상대적 포지션 임베딩이나 segement-level recurrence와 같이 다른 구조적 향상점을 포함하지 않는 것에 기인하는 것 같다.
- Pure language models perform best on ELI5 (Pure Language Model이 ELI5에서 가장 좋은 성능을 보인다) ELI dataset은 다른 태스크보다 훨씬 더 높은 퍼플렉서티를 갖는 outlier이며, 다른 모델들이 BART를 능가하는 유일한 생성 태스크이다. 순수한 언어 모델이 가장 최고의 성능을 보이는데, 출력이 입력에 의한 제한을 헐겁게 받을 때 BART가 덜 효율적임을 시사한다.
- BART achieves the most consistently strong performance (BART는 가장 꾸준히 강력한 성능을 보인다) ELI를 제외하면, text-infilling을 사용한 BART 모델이 모든 태스크에서 좋은 성능을 보인다.
5. Large-scale Pre-training Experiments
최근 연구는 사전학습이 큰 배치 사이즈와 corpora로 스케일링될 때 다운스트림 성능이 극적으로 향상됨을 입증해 왔다 (Yang et al., 2019; Liu et al., 2019). BART가 이러한 체제에서 얼마나 좋은 성능을 내는지 테스트하고 다운스트림 스크에 유용한 모델을 생성하는지 테스트하기 위해, RoBERTa 모델과 동등한 스케일을 사용하여 BART를 학습시켰다.
디코더와 인코더를 각각 12층으로 쌓고, 은닉층 크기 1024인 large model을 사전학습한다. RoBERTa를 계승하여 배치 사이즈를 8,000으로 사용하고, 모델을 50,000 step동안 학습시킨다. 도큐먼트는 GPT-2와 동일한 동일한 byte-pair encoding으로 토크나이징 된다. Section §4의 결과에 기반해서, text infilling과 sentence permutation을 결합해 사용한다. 각 도큐먼트에서 30%의 토큰을 마스킹하고, 모든 문장을 치환한다.
BART와 가장 직접적으로 비교가능한 베이스라인은 RoBERTa인데, 동일한 자원으로 사전학습되지만 다른 objective를 사용한 모델이다. 전반적으로, BART는 유사한 성능을 보이고 대부분의 태스크에서 두 모델 간 차이가 아주 적다. 이는 생성 태스크에서 BART의 발전이 분류 성능의 비용에서 온 것이 아님을 시사한다.
8. Conclusions
본 논문은 원본으로부터 손상된 도큐먼트를 사상함으로써 학습하는 사전학습 접근법, BART를 소개했다. BART는 discriminative task에서 RoBERTa와 유사한 성능을 거두며, 이와 동시에 많은 텍스트 생성 태스크에서 새로운 SOTA를 갱신한다. 후행 연구는 도큐먼트를 특정한 앤드 테스크에 맞추어 사전학습에서 도큐먼트를 손상시키는 새로운 방법에 대해 탐구해야 할 것이다.
