Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks(2019) 논문을 읽고 내용 요약 및 정리한 내용이다.
본 논문은 위키독스에서 Sentence-transformer를 사용한 챗봇 구현 부분을 해보다가 SBERT에 대한 호기심이 생겨서 읽었다. (이번주부턴 진짜 1주 1논문 리뷰 해야지.. 7ㅔ을러 지지마😂) 문장 임베딩에 뛰어나 NLI 데이터셋에 잘 작용하고 오픈형 챗봇에도 쓰일 수 있는 것 같다.
모델 성능 평가(4, 5 세션 부분) 부분은 제외하고 논문 흐름대로 정리한 내용이고, 축약은 많이 하지 않았으니 전문을 읽고 싶다면 정독해보는것도 나쁘지 않을지도...?
1. Introduction
본 논문은 시맨틱하게 유의미한 sentence embeddings를 얻을 수 있는 샴 네트워크(siamese network)와 트리플렛 네트워크(triplet network)를 사용하여 BERT network를 변형한 Sentence-BERT(SBERT)를 제시한다. SBERT는 대규모의 시맨틱 유사성 비교, 클러스터링, 시맨틱 리서치를 통한 정보 회수와 같이 현재까지 BERT에서 적용되지 못한 태스크들을 사용할 수 있게 한다.
BERT는 cross-encoder를 사용한다. 두 개의 문장이 트랜스포머 네트워크에 전송되고, 타겟 밸류를 예측한다. 그러나 이러한 셋업은 조합의 경우의 수가 너무 많기 때문에, 다양한 pair regression task에 부적절하다. BERT를 사용하여 N=10,000의 문장 집합에서 가장 높은 유사도 쌍을 찾으려면, N*(N-1)/2 = 49,995,000의 추론 연산이 필요하다. 이는 최신 V100 GPU에서 약 65시간이 소요되는 작업이다.
클러스터링과 시맨틱 서치를 다루는 일반적인 방법은 시맨틱하게 유사한 문장이 가까워지도록 각 문장을 벡터 공간에 사상(mapping)하는 것이다. 가장 널리 사용되는 접근법은 BERT의 출력 레이어(BERT embeddings)를 평균하거나 또는 첫 토큰([CLS]토큰)을 사용하는 것인데, 이러한 방법은 GloVe 임베딩을 평균하는 방법보다 좋지 않은 문장 임베딩을 산출하기도 한다.
SBERT는 이러한 문제를 경감하기 위해 개발되었다. 샴 네트워크 구조는 입력 문장에 대한 고정된 크기 벡터(fixed-size vector)를 얻을 수 있게 한다. 코사인 유사도나 맨하튼, 유클리디안 거리와 같은 유사도 측정법을 사용하여 의미론적으로 유사한 문장이 탐색된다. 이러한 유사도 측정 방식은 현 시점 상당히 효율적으로 작용하며, SBERT가 클러스터링과 시맨틱 유사도 탐지에 사용될 수 있도록 한다. 만 개의 문장 집합에서 가장 유사한 문장 쌍을 찾는 작업의 컴플렉서티(complexity)는 BERT 연산 시 65시간이 소요되는데, SBERT에서 ~5초, 코사인 유사도 연산 ~0.01초로 크게 감소한다.
SBERT는 NLI 데이터로 파인튜닝되어, InferSent, Universal Sentence Encoder와 같은 SOTA 문장 임베딩 방법을 크게 능가하는 문장 임베딩을 생성한다. 7개의 STS 태스크에서 SBERT는 이전 SOTA 문장 임베딩보다 성능을 향상시켰다.
본 논문은 다음과 같이 구성된다 : Section 3에서 SBERT를 제시하고, Section 4에서 challenging Argument Facet Similarity (AFS) corpus와 common STS 태스크로 SBERT를 평가한다. Section 5는 SentEval에서 SBERT를 평가한다. Section 6에서, 우리는 SBERT의 설계 양상을 실험하기 위해 ablation study를 수행한다. 섹션 7에서 우리는 SBERT의 문장 임베딩 연산 효율성을 다른 SOTA 문장 임베딩 방법과 비교한다.
2. Related Work
본 섹션에서는 먼저 BERT에 대해 소개하고, SOTA 문장 임베딩 방법들에 대해 논의해 본다.
BERT는 사전학습 트랜스포머 네트워크로, 다양한 NLP 태스크(QA, sentence classification, sentence-pair regression …)에 대하여 SOTA 성능을 갱신한다.
Sentence-pair regression에 대한 BERT의 입력은 2개의 문장으로 구성되는데, 스페셜 토큰인 [SEP]에 의해 구분된다. 12(base model) 또는 24(large model)개의 레이어에 대한 Mutli-head attention가 적용되고 출력은 최종 라벨을 얻기 위해 단순한 regression function으로 전송된다. 이러한 셋업을 사용하여, BERT는 STS 벤치마크에서 새로운 SOTA 성능을 갱신한다.
BERT 네트워크의 큰 단점은 독립적 문장 임베딩(independent sentence embedding)이 연산되지 않는다는 것으로, 이러한 단점이 BERT에서 문장 임베딩을 얻는 것을 어렵게 만든다. 이러한 한계점을 극복하기 위해, 연구자들은 BERT에 단일 문장을 전송하고 그 결과를 평균하거나(워드 임베딩 평균과 유사하게), 스페셜 토큰인 [CLS]의 출력을 사용하여 고정된 크기의 벡터를 얻는다.
문장 임베딩은 수많은 방법론이 제안된 well-studied 분야이다.
Skip-Thought (Kiros et al., 2015)는 주변 문장(surrounding sentences)을 예측하기 위해 encoder-decoder 구조를 학습시킨다.
InferSent (Conneau et al., 2017)은 Stanford Natural Language Inferenceh와 MultiGenre NLI dataset (Williams et al., 2018)의 labeled data를 사용하여 출력에 대한 max-pooling과 함께 siamese BiLSTM 네트워크를 학습시킨다.
Conneau et al.은 InferSent가 SkipThought와 같은 비지도학습 방법의 성능을 꾸준히 능가한다는 것을 입증했다.
Universal Sentence Encoder (Cer et al., 2018)는 트랜스포머 네트워크를 학습하고 SNLI의 학습과 함께 비지도 학습을 증가시킨다.
Hill et al. (2016)는 문장 임베딩이 학습된 태스크가 문장 임베딩의 퀄리티에 상당한 영향을 끼친다는 것을 입증했다.
선행 연구(Conneau et al., 2017; Cer et al., 2018)들은 SNLI 데이터셋이 문장 임베딩을 학습시키는 데 적절하다는 것을 발견한다.
Yang et al. (2018)은 Siamese DAN과 Siamese transformer network를 사용하여 Reddit의 대화로 학습시키는 방법을 제시했는데, 이러한 방법은 STS 벤치마크 데이터셋에서 좋은 결과를 얻었다.
Humeau et al. (2019)는 BERT의 cross-encoder의 런타임 오버헤드에 대해 다루고, m개의 컨텍스트 벡터 간 스코어를 연산하는 방법(poly-encoders)을 제시하며, 어텐션을 사용하여 임베딩 후보를 사전 연산한다. 이러한 개념은 더 큰 문장 집합에서 가장 높은 스코어 문장을 찾는 데 잘 작용한다. 그러나, poly-encoders는 스코어 함수가 대칭되지 않고 O(n^2) 연산을 요구하여, clustering과 같은 유스케이스에 사용하기에 연산 오버헤드가 너무 크다는 결점이 있다.
본 연구는 사전학습된 BERT와 RoBERTa 네트워크를 사용하고 유용한 문장 임베딩을 얻기 위해서 파인튜닝만 진행한다. 이러한 작업은 학습에 필요한 시간을 크게 절약한다 : SBERT는 20분 이내로 튜닝되면서, 다른 문장 임베딩 방법보다 더 나은 결과를 산출한다.
3. Model
SBERT는 고정된 크기의 문장 임베딩을 얻기 위해, BERT/RoBERTa의 출력에 대하여 풀링(Pooling) 작업을 더한다. 풀링에는 3가지 전략이 있다 : 1) CLS 토큰 출력 사용하기 2) 모든 출력 벡터의 평균 연산(MEAN-strategy) 3) 출력 벡터의 max-over-time 연산(MAX-strategy). Default configuration은 MEAN이다.
BERT/RoBERTa를 파인튜닝하기 위해, 샴 네트워크와 트리플렛 네트워크를 생성하여 가중치를 업데이트하여 생성된 문장 임베딩이 semantically meaningful하고 코사인 유사도로 비교될 수 있도록 한다.
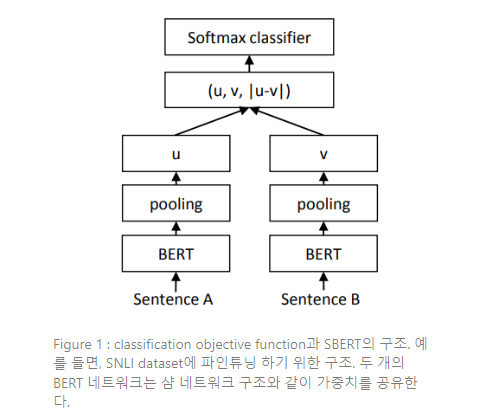
Classification Objective Function
문장 임베딩 와 를 element-wise difference 와 연결(concatenate)하고 이를 학습 가능한 가중치 로 곱한다.
위 식에서 은 문장 임베딩의 차원이고, 는 라벨의 수이다. 크로스 엔트로피 손실이 최적화된다. 이러한 구조는 Figure 1에서 설명하고 있다.
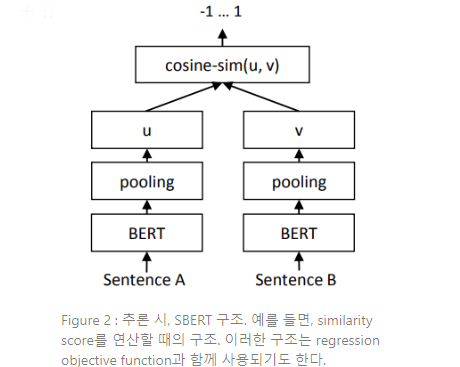
Regression Objective Function
두 문장 임베딩 와 간 코사인 유사도가 연산된다(Figure 2). objective function으로는 mean-squared-error loss를 사용한다.
Triplet Objective Function
Anchor sentence 와, positive senten
위 식에서 에 대한 문장 임베딩은 , 는 distance metric, 은 margin 이다. Margin 은 가 적어도 보다 에 만큼 가깝도록 보장한다. 계량법은 유클리디안 거리가 사용되고, 실험에서 가 사용된다.
SBERT는 SNLI와 Multi-Genre NLI dataset을 결합하여 학습된다.
SNLI는 contradiction(대조), entailment(수반), neutral(중립)의 라벨로 어노테이션 된 570,000개의 문장 쌍의 집합이다. MultiNLI는 430,000개의 문장 쌍을 포함하고, 구어체와 문어체 범위를 커버한다. SBERT는 3-way softmax classifier objective function으로 1 epoch만큼 파인튜닝된다. 파인튜닝 파라미터로는 16 batch-size, Adam optimizer와 2e-5의 learning rate를 사용하고, 학습 데이터 10%이상에는 linear learning rate warm-up을 적용한다. default pooling strategy는 MEAN이다.
4. Ablation Study
본 섹션은 SBERT의 상대적 중요성에 대해 더 잘 이해할 수 있도록 SBERT의 다양한 측면에 대하여 ablation study를 수행한다.
먼저 다양한 풀링 전략(MEAN, MAX, CLS)를 평가한다. Classification objective function에서 다양한 연결 방법을 평가한다. 각각의 가능한 구성에서, SBERT를 10개의 랜덤 시드로 학습하고 성능을 평균 한다.
Objective function(classification vs. regression)은 annotated datasets에 달려 있다. Classification objective function에서 SBERT는 SNLI와 Multi-NLI dataset에 기반하여 학습된다. Regression objective function에서, SBERT는 STS 벤치마크 데이터셋의 학습 셋으로 학습된다. STS 벤치마크 데이터셋의 dev split 성능 측정 결과는 Table 6에 나타나 있다.
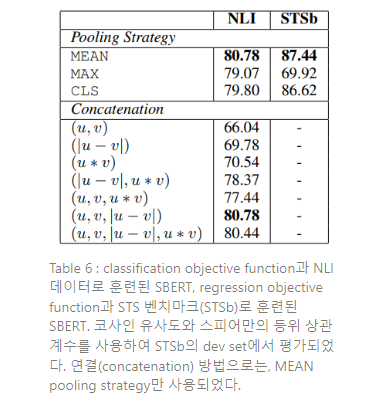
NLI 데이터에서 classification objective function로 학습할 때, 풀링 전략은 영향력이 적고, Concatenate mode의 영향력은 훨씬 더 크다. InferSent와 Universal Sentence Encoder는 를 softmax classifier의 입력으로 사용한다. 그러나, SBERT의 구조에 element-wise 를 추가하는 것은 성능을 하락시킨다.
가장 중요한 구성요소는 element-wise difference 이다. Concatenate mode가 소프트맥스 분류기를 훈련하는 것에만 관련되어 있다는 것에 주목하라. 추론 시 STS 벤치마크 데이터셋의 유사성을 예측할 때, 문장 임베딩 와 만이 코사인 유사도와 결합하여 사용된다. Element-wise difference는 두 개의 문장 임베딩 차원 간 거리를 측정하고, 유사한 쌍이 더 가깝고, 유사하지 않은 쌍이 더 멀어지도록 만든다.
Regression objective function으로 학습될 때, 풀링 전략이 큰 영향을 끼치는 것을 관측한다. 여기서 MAX 전략은 MEAN이나 CLS-token 전략보다 훨씬 좋지 않은 성능을 보인다. 이는 InferSent의 BiLSTM-layer가 MEAN 풀링 대신 MAX 풀링을 사용하는 것이 더 좋다는 것을 발견한 (Conneau et al., 2017)과는 대조적이다.
7. Computational Efficiency
문장 임베딩은 수천만의 문장에서 연산될 수 있고, 따라서 빠른 연산 속도가 필요하다. 본 섹션은 SBERT와 평균 GloVe 임베딩, InferSent (Conneau et al., 2017), Universal Sentence Encoder (Cer et al., 2018)를 비교한다.
비교 과정에서는 STS 벤치마크의 문장이 사용되었다. 평균 GloVe 임베딩은 단순히 파이썬의 dictionary lookups와 NumPy를 사용하여 for-loop로 연산된다. InferSent는 PyTorch 기반으로 연산된다. Universal Sentence Encoder는 TensorFlow Hub version를 사용하는데, 이는 텐서플로우 기반이다. SBERT도 PyTorch를 기반으로 한다. 더 나은 문장 임베딩 연산을 위해, smart batching 전략이 도입된다 : 유사한 길이의 문장들은 함께 그루핑되고, 미니 배치에서 가장 긴 엘리먼트로 패딩된다. 이러한 작업은 패딩 토큰에서 연산 오버헤드를 극적으로 감소시킨다.
CPU에서 InferSent는 SBERT보다 약 65% 빠르다. 이것은 훨씬 단순한 작업 구조 때문이다. InferSent는 단일 BiLSTM layer를 사용하는 반면, BERT는 12 stacked transformer layers를 사용한다. 그러나, 트랜스포머 네트워크의 장점은 GPU에서의 연산 효율성이다. GPU에서 SBERT를 smart batching하여 사용하면, InferSent보다 9% 빠르고 Universal Sentence Encoder보다 55% 빠르다. Smart batching는 CPU에서 89%, GPU에서 48%의 속도 향상을 이룬다. 평균 GloVe 임베딩은 큰 차이로 명확히 문장 임베딩을 연산하는 가장 빠른 방법이 된다.
8. Conclusion
본 논문은 튜닝하지 않은 BERT가 하나의 벡터 공간에 사상하는 것이 문장을 코사인 유사도와 같은 일반적인 유사도 척도와 함께 사용되기에는 적합하지 않다는 것을 입증했다. 7개의 STS 태스크에 대한 성능은 GloVe 임베딩의 평균보다 낮았다.
이러한 결점을 극복하기 위해, Sentence-BERT(SBERT)를 제시한다. SBERT는 BERT를 샴 네트워크, 트리플렛 네트워크 구조로 파인튜닝한다. 다양한 공용 벤치마크에서 SBERT의 퀄리티를 평가하고, 여기서 SOTA 문장 임베딩 방법을 크게 능가하는 성과를 얻었다. BERT를 RoBERTa로 대체하는 것이 본 연구에서는 큰 성능 향상을 가져오지 않았다.
SBERT는 연산적으로 효율적이다. GPU에서, InferSent보다 9% 정도 빠르며, Universal Sentence Encoder보다 55%정도 빠르다. SBERT는 BERT로 모델링되기에 연산적으로 적합하지 않은 태스크에 사용될 수 있다. 예를 들면, BERT를 사용하여 만 개의 문장을 hierarchical clustering으로 클러스터링하면 약 5시간이 소요되는데, 약 5천만 문장 조합이 연산되어야 하기 때문이다. SBERT를 사용하면, 우리는 약 5초로 수고를 덜 수 있다.
