openai chatGPT가 공개됨에 따라, 대형 언어 모델(LLMs)들에 대한 연구가 주목 받고 있는 것 같다. 얼마 전 Meta에서 공개한 파운데이션 LLMs인 LLaMA와 스탠포드 대학에서 LLaMA를 기반으로 학습한 모델 Alpaca에 대해서 알아보고자 한다.
여기서 파운데이션 모델이란, 대용량의 unlabeled dataset으로 사전학습하고 다양한 다운스트림 태스크에 파인튜닝하여 응용할 수 있는 모델들을 말한다.
LLaMA: Open and Efficient Foundation Language Models(2023)
(들어가기 전.. 🔎)
LLaMA 모델의 핵심은 트랜스포머 아키텍쳐를 기반으로 하면서 GPT와 같은 few-shot learning 방식을 사용하지만, 퍼블릭 데이터만 사용해서 훈련하고 추론 효율성을 높이는 데 주력했다는 점 같다. 모델 배포가 좀 더 아카데믹한 관점에 초점을 두고 있는 것으로 보인다.
LLaMA 모델의 논문을 리딩하면서 중간에 세세한 실험 과정이나 결과는 생략했고 개요나 접근 방법, 구조를 위주로 정리해 보았다.
- Abstract
7B ~ 65B 범위(*7B, 13B, 33B, 65B 버전이 공개되어 있음)의 파라미터로 훈련된 파운데이션 언어 모델 콜렉션LLaMA를 소개한다.
LLaMA 모델은 수조 개의 토큰으로 훈련되었으며, 비공개 데이터에 의존하지 않고 퍼블릭 데이터셋만을 배타적으로 사용하여 훈련했을 때 SOTA model을 얻을 수 있다. 특히, LLaMA-13B 모델은 벤치마크 데이터에서 GPT-3(175B)의 성능을 능가하고, LLaMA-65B모델은 최고 성능 모델인 Chinchilla-70B 및 PaLM-540B과 필적한다.
1. Introduction
대형 언어 모델(LLMs)은 방대한 양의 텍스트 코퍼스로 훈련되어, 텍스트 형태의 지시사항이나 몇개의 예제만으로도 새로운 태스크를 수행할 수 있는 능력을 입증했다. 이러한 few-shot properties(적은 수의 학습 데이터로 높은 성능을 보이는 것)는 모델을 충분한 크기로 확장시키면서 등장했는데, 이후 이러한 모델의 크기를 더욱 확장시키는 방식의 연구가 진행되었다.
이러한 노력은 더 많은 파라미터를 사용하는 것이 더 나은 성능을 가져온다는 가정을 기반으로 한다. 그러나, 최근 연구에서 Hoffmann et al. (2022)는 컴퓨팅 예산이 정해졌을 때, 가장 큰모델이 아닌 더 많은 데이터로 훈련된 모델이 최고의 성능을 발휘한다는 것을 입증했다.
Hoffmann et al. (2022)의 스케일링 법칙의 목적은 특정한 학습 컴퓨팅 예산에 대한 데이터셋과 모델 크기를 어떻게 확장할 지 결정하는 것이다. (즉, 학습에 사용 가능한 컴퓨팅 예산을 고려하여 최적의 데이터셋 및 모델 크기를 결정하는 것이 이 연구의 목적이라고 할 수 있다) 그러나, 이러한 목적은 언어 모델을 대규모로 서비스할 때 중요한 “추론 예산(inference budget)”을 간과하고 있다.
이러한 맥락에서, 일정 수준의 성능을 목표로 할 때, 선호하는 모델은 학습 속도가 가장 빠른 모델이 아니라, 추론 속도가 가장 빠른 모델이며, 특정 수준의 성능을 달성하기 위해 대형 모델을 훈련시키는 비용이 더 저렴할지라도, 더 오래 훈련시킨 더 작은 모델이 결국 추론에서 더 저렴할 수 있다는 것이다. 예를 들면, Hoffmann et al. (2022)는 10B 모델을 200B 토큰으로 훈련시키는 것을 권장하지만, 7B 모델이 1T 토큰 이후에도 성능이 지속적으로 개선된다는 것을 발견한다.
이 논문의 초점은 일반적으로 사용되는 토큰의 양보다 더 많은 양의 토큰을 훈련시킴으로써, 다양한 추론 예산에서 최상의 성능을 달성하는 일련의 언어 모델을 훈련하는 것이다. 이를 LLaMA라 부르고, 7B에서 65B 파라미터까지의 모델로 구성되며 최고의 기존 LLMs와 경쟁력 있는 성능을 보인다.
예를 들어, LLaMA-13B는 GPT-3 크기의 1/10배이나, 대부분의 벤치마크에서 GPT-3을 능가한다. 이 모델은 단일 GPU에서 실행할 수 있어, LLMs의 접근성과 연구를 더 폭넓게 이루어지도록 할 수 있다. 또한, 65B 파라미터 모델은 Chinchilla, PaLM-540B와 같은 최고의 LLMs에 필적한다.
Chinchilla, PaLM 또는 GPT-3와 달리, 본 연구에서는 공개적으로 이용 가능한 데이터만 사용했고, 반면 대부분의 기존 모델은 공개적으로 이용 가능하지 않거나 문서화되지 않은 데이터에 의존하고 있다. OPT(Zhang et al., 2022), GPT-NeoX(Black et al., 2022), BLOOM(Scao et al., 2022) 및 GLM(Zeng et al., 2022)과 같은 몇 가지 예외 사항이 있으나, PaLM-62B, Chinchilla에 필적할 수 있는 모델은 없다.
본 논문의 뒷부분에서는 트랜스포머 구조(Vaswani et al., 2017)에 대해 적용한 수정 사항과 학습 방법을 개요로 제시한다. 그리고 표준 벤치마크 세트에서 모델(LLaMA)의 성능을 다른 LLMs와 비교한다. 마지막으로, AI 커뮤니티에서 최근 벤치마크 중 일부를 사용하여 본 모델에 인코딩된 일부 편향과 유해성을 제시한다.
2. Approach
LLaMA의 훈련 접근법은 선행 연구(Brown et al., 2020; Chowdhery et al., 2022)의 훈련 접근법과 유사하고, Chinchilla의 스케일링 법칙(Hoffmann et al., 2022)에서 영감을 받았다. 표준 옵티마이저를 사용하여 대형 트랜스포머 모델을 대용량의 텍스트 데이터에 학습시키는 것이다.
(Brown et al., 2020) Language Models are Few-Shot Learners,
(Chowdhery et al., 2022) PaLM: Scaling Language Modeling with Pathways
(Hoffmann et al., 2022) Training Compute-Optimal Large Language Models
2.1. Pretraining Data
LLaMA의 훈련 데이터셋은 다음 Table 1 목록에 있는 여러 소스들을 혼합해서 사용하여, 다양한 도메인을 커버할 수 있다.
대부분의 데이터셋에서, LLaMA는 다른 LLMs를 훈련하는 데 사용된 데이터 소스를 재사용하는데, 오픈 소스와 양립이 가능하면서 공개적으로 사용 가능한 데이터만을 이용했다.
데이터 혼합 비율은 다음과 같다. English CommonCrawl [67%], C4 [15%], Github [4.5%], Wikipedia [4.5%], Gutenberg and Books3 [4.5%], ArXiv [2.5%], Stack Exchange [2%].
- Tokenizer
LLaMA에서는 SentencePiece에서 사용되었던 byte-pair encoding(BPE) 알고리즘을 사용하여 데이터를 토큰화한다. 모든 숫자를 개별적인 수로 분리하고, 알수 없는 UTF-8 character를 분해하기 위해 바이트(bytes)로 대체한다.
전반적으로, 전체적인 훈련 데이터셋은 토큰화(tokenization) 과정 이후 대략 1.4T의 토큰을 갖게 된다. 대부분의 훈련 데이터에서 각 토큰은 훈련 시 한 번만(only once) 사용되는데, Wikipedia와 Books 도메인은 예외적으로 약 2 에폭에서 사용한다.
2.2. Architecture
LLMs에 대한 최근 연구 동향에 따라, LLaMA의 신경망은 트랜스포머 구조를 기반으로 한다. 그리고 이전까지 제안된, PaLMs 모델과 같이 활용되었던 모델들에 대한 다양한 개선안을 활용한다. 다음은 원본 구조와 핵심적인 차이점을 비교하고, 변경점에 대한 영감을 얻은 모델들에 대해 설명한다.
- Pre-normalization [GPT3] 학습 안정성을 향상시키기 위해, 각 트랜스포머 서브 레이어의 출력 대신 입력을 정규화(normalize)한다. Zhang and Sennrich (2019)에서 제안된
RMSNorm을 정규화 함수로 사용한다.
- SwiGLU activation function [PaLM] 성능 향상을 위해, ReLU의 비선형성을 Shazeer (2020)에서 제안된
SwiGLU활성화 함수로 대체한다. PaLM 모델에서처럼 대신 차원을 사용한다.
- Rotary Embeddings [GPTNeo] LLaMA는 absolute positional embeddings(절대적 위치 임베딩)를 사용하지 않고, 대신 신경망의 각 레이어에 Su et al. (2021)의
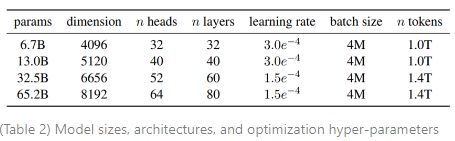
rotary positional embeddings(RoPE)를 사용한다. 다양한 크기의 LLaMA 모델에 대한 하이퍼파라미터 세팅은 Table 2에 설명되어 있다.
2.3. Optimizer
LLaMA 모델은 AdamW 옵티마이저를 사용하고 , 하이퍼파라미터로 학습된다. 또한 코싸인 학습률 스케쥴을 사용하며, 이 스케줄에서 최종 학습률은 최대 학습률의 10%이 된다. LLaMA는 가중치 감소(weight decay)를 0.1, 그리고 그래디언트 클리핑(gradient clipping)을 1.0으로 사용한다. 그리고 2,000개의 웜업 스텝을 사용하며, 모델의 크기에 따라 학습률과 배치 사이즈가 상이하다(내용은 Table 2 참조).
2.4. Efficient implementation
LLaMA 모델 훈련 속도를 향상시키기 위해, 몇가지 최적화(optimizations)가 적용된다. 첫번째, 캐쥬얼한 멀티헤드 어텐션을 효율적으로 사용하여 메모리 사용량과 런타임을 감소시킨다. 이러한 방법은 xformers 라이브러리에서 이용할 수 있고, Rabe and Staats (2021)에서 영감을 받았으며 Dao et al. (2022)의 역전파(backward)를 사용한다. 이러한 방법은 언어 모델링 태스크의 casual nature 때문에, 어텐션 가중치(attention weights)를 저장하지 않고, 마스킹된 키(key), 쿼리(query) 스코어를 연산하지 않는다.
훈련 효율성을 더욱 향상시키기 위해, LLaMA 모델에서는 체크포인트를 사용하여 역전파에서 재연산되는 활성화 함수의 양을 감소시켰다. 즉, 선형 레이어 출력과 같이 계산 비용이 큰 활성화 함수를 저장하는 것이다. 활성화 함수의 저장은 PyTorch autograd에 의존하지 않고 트랜스포머 레이어의 역전파 함수를 직접 구현하여 시행된다.
이러한 최적화 방법으로 최대한의 혜택을 보기 위해서는, Korthikanti et al. (2022)에서 설명된 것과 같이 모델과 시퀀스 병렬 처리를 통해 모델의 메모리 사용량을 줄여야 한다. 더불어, 신경망에서 활성화 함수의 계산과 GPU간 통신을 가능한 한 오버랩하여 사용한다(모든 reduce 연산 때문).
…
5. Bias, Toxicity and Misinformation
대규모 언어 모델(LLMs)은 훈련 데이터 세트에 존재하는 편향(bias)을 재생산하고 강화시키는 것으로 나타났고, 유해성이나 모욕적 컨텐츠를 생성하기도 한다. Web이 LLaMA 훈련 데이터 세트의 큰 비율을 차지하기 때문에, 이러한 유해성 콘텐츠의 생성 가능성을 확인하는 것이 중요하다.
LLaMA-65B에서의 잠재적 피해를 확인하기 위해, 다양한 벤치마크(RealToxicityPrompts, CrowS-Pairs, WinoGender, TruthfulQA)에서 평가를 수행한다.
8. Conclusion
본 논문은 SOTA 파운데이션 모델에 필적하는 오픈 소스 언어 모델 시리즈를 제안한다. LLaMA-13B는 GPT-3의 10분의 1 크기임에도 성능이 더 뛰어나고, LLaMA-65B는 Chinchilla-70B와 PaLM-540B모델에 필적한다. 선행 연구들과는 달리, 본 논문은 LLaMA를 통해 비공개 데이터를 제외하고 공개적으로 이용가능한 데이터만 학습시켜 SOTA의 성능을 달성할 수 있다는 것을 입증한다.
Alpaca: A Strong, Replicable Instruction-Following Model

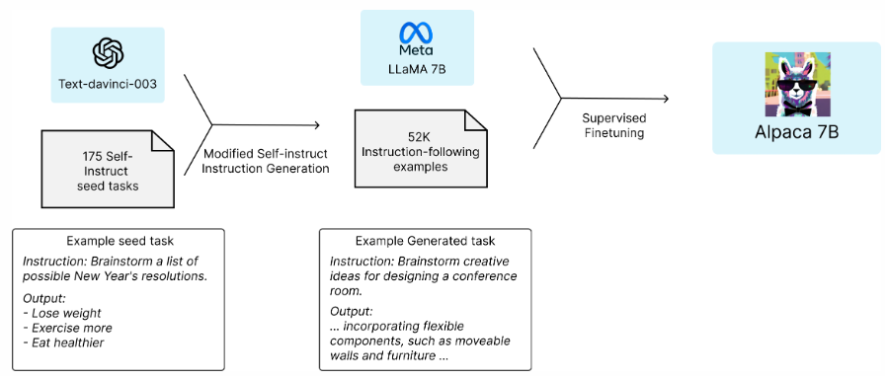
Alpaca 7B는 52K의 instruction-following demonstrations를 기반으로 LLaMA 7B을 파인튜닝한 모델이다. Alpaca는 single-turn instruction following에서 OpenAI의 text-davinci-003(GPT-3)과 유사한 성능을 보인 반면, 재생산 비용은 훨씬 더 저렴하다(<600$).
Overview
GPT-3, ChatGPT, Claude, Bing Chat과 같은 instruction-following 모델들은 점점 강력해지고 있다. 많은 사용자가 이러한 모델들과 상호작용하고 업무에 사용하기도 하지만, 아직까지 instruction-following 모델에는 많은 결함이 존재한다. 예를 들면, 거짓된 정보를 생성하거나, 사회적인 고정관념(stereotypes)을 확산시키며, 유해한 언어를 생성할 수 있다.
이러한 문제들을 해결하기 위해 학계의 참여가 중요한데, 안타깝게도 OpenAI의 text-davinci-003과 같은 instruction-following 모델은 closed-source 모델로 접근이 어려워 학계에서 이러한 모델들의 연구를 수행하는 것이 어렵다.
instruction-following 언어 모델에 대한 연구 결과로, Meta의 LLaMA 7B 모델로 파인튜닝된 Alpaca를 공개한다. Alpaca는 GPT-3을 사용하여 self-instruction 형식으로 생성된 52K의 instruction-following demonstrations를 사용하여 훈련되었다. self-instruct 평가 세트에서, Alpaca는 OpenAI의 GPT-3과 유사하면서, 재현이 훤씬 쉽고 저렴하다는 것을 입증했다.
Alpaca의 훈련 방법과 데이터를 공개하고, 추후 모델 가중치도 공개하고자 한다. 또한 인터랙티브한 데모를 제공하여 커뮤니티에서 Alpaca의 동작을 더 잘 이해할 수 있도록 지원하고자 한다. 상호 작용이 예기치 않은 기능과 실패를 불러올 수 있으며, 이는 추후 이러한 모델의 평가 지도에 도움이 될 것이다.
또한, 웹 데모에서 우려되는 동작이 있을 경우 이를 보고하여 이러한 동작을 파악하고 완화할 수 있도록 장려한다.
Training recipe
고품질의 instruction-following model을 academic budget 내에서 훈련시키기 위해서는 두 가지의 중요한 도전 과제가 있다. (1) 강력한 사전 훈련된 언어 모델과 (2) 고품질의 instruction-following 데이터이다. 첫 번째 과제에 대해서는 메타의 최신 모델인 LLaMA에서 해결되었다. 두 번째 과제에 대해서, self-instruct 논문은 기존 강력한 언어 모델을 사용하여 자동적으로 instruction data를 생성하는 방법을 제안한다.
특히, Alpaca는 LLaMA 7B 모델의 지도 학습을 사용하여 OpenAI의 text-davinci-003으로 생성된 52K의 instruction-following demonstrations로 파인튜닝된 언어 모델이다.
다음의 모형은 Alpaca model을 얻는 방법에 대해 설명한다. 데이터는 self-instruction method를 통해 생성된 instruction-following demonstrations를 사용한다. 175개의 human-written instruction output pairs에서 시작해서, self-instruct seed set에 도달한다. 그리고 나면 text-davinci-003이 in-context 예제와 같이 seed set을 사용하여 더 많은 instructions를 생성하도록 촉진한다. 생성 파이프라인을 단순화함으로써 self-instruction method를 향상시키고, 비용을 크게 감축했다. Alpaca의 데이터 생성 프로세스는 OpenAI API를 사용하면 $500 정도 비용으로 환산되는 52K의 unique instructions와 그에 상응하는 출력을 도출한다.