Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer(2019)를 읽고 리뷰하기!
모종의 이유 때문에(??) 다시 논문 리뷰 의지를 불태워 본다.. 🔥🔥
인생 쉽지않다 그래도 열심히 살아야지 뭐.. ~

T5는 Text-to-Text Transfer Transformer인데, T가 다섯 개나 들어가서 T5라고 네이밍 했나부다 ㅎ BERT 시리즈 모델이나, 최근 LLaMA나 Alpaca도 그렇고 NLP 모델들 작명 센스 넘 맘에 든다.. 귀여워🤗
아무튼 T5는 구글에서 19년도 발표된 트랜스포머 구조 기반 모델이고, 입출력을 모두 텍스트로 취하는 "text-to-text"가 핵심인 모델이다 !
T5 논문을 읽기 시작한 지는 좀 오래됐는데, 넘 길다보니 ^.ㅠ 자꾸 짤짤이로 읽다 지치고를 반복.. 결국 라마랑 알파카 보다 훨씬 오래된 듯..ㅎ 결국 완독까지는 못하고(!!) 부분부분 건너 뛰어서 읽었다.
Abstract부터 시작하되, 몇몇 세부 section은 건너뛰고 정리해보도록 하겠다(기준은 내 맘~).
Abstract
전이학습(Transfer learning)은 다운스트림 태스크에 finetuning(미세조정)하기 전에 데이터가 풍부한 태스크에서 먼저 사전학습된 모델이다. 전이학습은 NLP(자연어 처리) 분야에서 강력한 기술로 부상했다. 전이학습의 효능은 접근법, 방법론, 그리고 적용을 다양하게 만들었다.
본 논문은 모든 텍스트 기반 언어 문제를 text-to-text 형태로 전환시키는 통합된 프레임워크를 도입함으로써 NLP의 전이학습 기술의 조경을 탐구한다. 본 연구에서 사전학습 objectives, 구조, 라벨링되지 않은 데이터셋, 전이 접근 방식, 그리고 수십 가지 언어 이해 태스크의 요인들에 대하여 비교한다. 탐구를 통해 통찰과 스케일, 그리고 “Colossal Clean Crawled Corpus(C4)”를 비교함으로써, 텍스트 요약, QA, 텍스트 분류 등 수많은 벤치마크에서 SOTA의 결과를 얻는다.
1. Introduction
NLP 태스크를 수행하기 위해 기계 학습 모델을 학습시키는 것은 보통 모델이 다운스트림 학습에 순응할 수 있는 방식으로 텍스트를 처리하는 것을 요구한다. 이는 어느 정도 모델이 텍스트를 “이해할” 수 있도록 하는 범용 지식을 발전시키는 요소로 볼 수 있다. 이러한 지식은 낮은 수준 (e.g 단어 스펠링이나 의미) 에서부터 높은 수준까지 이른다.
현대의 기계 학습 관행에서, 이러한 지식은 거의 명쾌하게 제공되지 않는다. 대신에, 이러한 지식은 보통 보조적인(auxiliary) 태스크의 일부로 학습된다. 예를 들면, 역사적으로 일반적인 접근법은 단어의 아이덴티티를 연속적인 표현으로 사상하기 위해(이상적으로, 유사한 단어는 유사한 벡터로 사상하게 된다) word vector(워드 벡터)를 사용(Mikolov et al., 2013b,a; Pennington et al., 2014)하는 것이다. 이러한 벡터들은 보통 objectives를 통해 학습되는데, 이러한 objectives의 한 예로, co-occurring word를 연속적인 공간 내에 가깝게 위치하도록 장려하는 것이 있다.
최근, 데이터가 풍부한 태스크에 전체 모델을 사전학습시키는 방식이 점점 더 일반적이 되어가고 있다. 이상적으로, 이러한 사전학습은 모델이 다운스트림 태스크에 전이될 수 있는 범용적인 목표와 지식을 발전시킬 수 있게 한다. 전이 학습을 컴퓨터 비전 분야에 적용할 때, 사전학습은 전형적으로 ImageNet과 같은 대형의 라벨링 된 데이터에서 지도 학습을 통해 수행된다.
이와 대조적으로, NLP를 위한 현대 전이학습 기술은 일반적으로 라벨링되지 않은 데이터에서 비지도학습을 사용하여 사전학습한다. 이러한 접근법은 최근 대다수의 NLP 벤치마크에서 SOTA의 성과를 거두는 데 사용되어 왔다. 특히 NLP의 비지도 사전학습(unsupervised pre-training)은 실증적인 강점을 넘어 매력적인데, 라벨링되지 않은 텍스트 데이터가 인터넷에서 대용량으로 이용가능하기 때문이다. 예를 들면, Common Crawl project는 매달 웹 페이지에서 추출하여 약 20TB의 텍스트 데이터를 생산한다. 이러한 데이터셋은 당연 놀라운 확장성을 보여왔던 신경망에 적합하다. 즉, 단순히 더 큰 데이터셋에서 더 큰 모델을 학습시킴으로써 더 좋은 성능을 얻는 것이 가능하다.
이러한 시너지는 NLP의 전이학습 방법론을 발전시키는 수많은 최근 연구를 낳았고, 다양한 사전학습 objectives, 라벨링 되지 않은 데이터셋, 벤치마크, 파인튜닝 방법 등을 산출하게 된다. 이러한 성장 분야의 빠른 진도율과 기술의 다양성이 다양한 알고리즘을 비교하고, 새로운 컨트리뷰션들의 효과를 개별적으로 이해하며, 현존하는 전이학습 방법을 이해하는 것을 어렵게 만든다. 더욱 엄밀한 이해의 필요성에 따라, 본 논문에서는 전이학습의 다양한 접근법을 연구할 수 있도록 하는 통합적인 접근법을 체계적으로 활용하고 이 분야의 현재 한계점에 도전하도록 한다.
본 논문에 내재한 근본적인 아이디어는 모든 텍스트 처리 문제를 “text-to-text” 문제로 취급하는 것이다. 즉, 텍스트를 입력으로 취급하고 새로운 텍스트를 생성하는 것을 출력으로 취급하는 것이다. 이러한 접근법은 QA, 언어 모델링, 또는 구간 추출 태스크와 같은 모든 텍스트 문제를 포함한 선행하는 NLP 태스크의 통합 프레임워크에서 영감을 받았다.
결정적으로, text-to-text 프레임워크는 동일한 모델과 동일한 objective, 동일한 훈련 절차와 동일한 디코딩 프로세스를 모든 태스크에 직접적으로 적용할 수 있도록 한다. 본 논문에서는 QA, 문서 요약, 감정 분류 등등을 포함한 광범위한 영어 기반 NLP 문제의 성능을 평가함으로써 이러한 유연성을 활용한다. 이러한 통합된 접근법을 사용하여 다양한 전이 학습 objectives, 라벨링되지 않은 데이터셋, 그리고 다른 요인들의 효율성을 비교함과 동시에 모델과 데이터셋의 규모를 이전보다 더 확장하여 NLP를 위한 전이학습의 한계점을 탐구한다.
본 연구의 목표는 이 분야가 서 있는 위치에 대한 포괄적인 관점을 제시하기 위함임을 강조한다. 본 연구는 주로 조사, 탐구, 그리고 현존하는 기술들에 대한 실증적 비교로 구성되어 있다. 또한, 많은 태스크에서 SOTA 성능을 얻기 위한 체계적인 연구(모델을 ~1100억 개 파라미터까지 훈련시키는)에서 통찰의 규모를 키워 현재 접근법들의 한계점을 탐구하기도 한다. 대규모 훈련 실험을 수행하기 위해, 웹사이트에서 스크랩된 수백 GB의 클린한 영어 텍스트로 구성된 데이터셋인 “Colossal Clean Crawled Corpus” (C4)를 도입한다. 전이 학습의 유용성은 주로 ‘데이터가 부족한 상황에서 사전학습된 모델을 활용할 가능성'에서 나온다는 것을 인식한다.
본 논문의 나머지 부분은 다음과 같이 구성되어 있다 : 다음 섹션에서, 본 논문의 베이스 모델과 모델의 시행, text-to-text 태스크로서 모든 텍스트 처리 문제를 형성하기 위한 절차와 연구에서 고려된 테스크들에 대해 논의한다. 섹션 3에서, NLP를 위한 전이학습 분야를 탐구하는 대규모 실험을 제시한다. 섹션 3의 끝부분(섹션 3.7)에서, 다양한 벤치마크에서 SOTA 결과를 얻기 위한 체계적인 연구에서 얻은 인사이트들을 결합한다. 마지막으로, 결과에 대한 요약을 제시하고 정리하여 섹션 4에서 살펴보고자 한다.
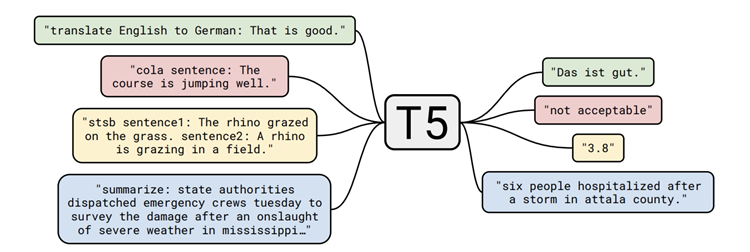
- (Figure 1) text-to-text framework의 다이어그램
번역, QA, 분류 등을 포함한 우리가 고려하는 모든 태스크들은 모델의 입력 텍스트가 되고, 일부 타겟 텍스트를 생성하기 위해 훈련된다. 이러한 과정이 다양한 태스크에 걸쳐 동일한 모델과 손실 함수, 하이퍼파라미터 등을 사용할 수 있도록 한다. 또한, 실증적 조사에 포함된 방법들에 대한 표준의 테스트베드를 제공한다. “T5”는 “Text-to-Text Transfer Transformer”로 본 논문의 모델을 나타낸다.
2. Setup
대규모의 경험적 연구 결과를 제시하기 앞서, 결과를 이해하기 위해 필요한 필수적인 background topics(Transfromer 모델 구조와 다운스트림 태스크 등)에 대해서 리뷰하고자 한다. 또한, 모든 문제를 text-to-text task로 취급하는 본 논문의 접근법에 대해 소개하고, “Colossal Clean Crawled Corpus” (C4)에 대해 설명한다. Common Crawl-based dataset은 본 논문에서 생성한 라벨링되지 않은 텍스트 데이터의 원천이다. 본 논문의 모델과 프레임워크는 “Text-to-Text Transfer Transformer” (T5)라 일컫는다.
2.1 Model
이전의 NLP 전이 학습 결과는 RNN을 효과적으로 활용했으나, 현재는 “Transformer” 구조(Vaswani et al., 2017) 기반 모델을 쓰는 것이 일반적이다. 트랜스포머는 초기에 기계 번역 분야에서 효과가 입증되었는데, 점차적으로 다양한 NLP 환경에서 사용되어 왔다. 트랜스포머 모델의 편재성(ubiquity)이 증가함에 따라, 본 논문에서 연구되는 모든 모델은 트랜스포머 구조를 기반으로 한다. 그리고 일부 특정 상황(아래 언급된 세부사항이나 섹션 3.2에서 언급될 변형 모델)을 제외하면, 이러한 트랜스포머의 원본 구조에서 크게 벗어나지 않는다.
트랜스포머의 블록은 주로 셀프 어텐션(self-attention)으로 구성되어 있다. 셀프 어텐션은 어텐션의 한 변형으로, 각 요소를 나머지 시퀀스의 가중 평균(weighted average)으로 대체하는 방식으로 시퀀스를 처리한다. original Transformer는 encoder-decoder 구조로 구성되어 있고, sequence-to-sequence 태스크를 위해 의도되었다. 현재는 단일 Transformer layer stack으로 구성된 모델과 언어 모델링(Language Modeling), 분류, 또는 span prediction tasks에 적절한 구조를 생성하는 데 사용되는 셀프 어텐션의 다양한 형태를 같이 사용하는 방법 또한 일반적인 방법 중 하나가 되었다. 본 논문의 섹션 3.2에서는 이러한 구조적 변형들에 대해서 다룬다.
전반적으로, 본 논문에서 인코더-디코더 트랜스포머의 시행은 original Transformer를 면밀히 따른다. 먼저, 토큰의 입력 시퀀스는 임베딩의 시퀀스로 사상되고, 그 다음 인코더로 넘어간다. 인코더는 “블록(blocks)”을 쌓은 형태(stack)로 구성되는데, 각 블록은 셀프 어텐션 레이어(self-attention layer)와 작은 피드 포워드 신경망(FFN) 2개의 서브 컴포넌트로 구성된다.
각 서브 컴포넌트의 입력에 레이어 정규화(LN)가 적용된다. 본 논문에서는 간소화된 레이어 정규화를 사용하는데, 간소화된 레이어 정규화는 활성화 함수 값만 재조정하며 추가적인 편향(bias)을 적용하지 않는다. 레이어 정규화를 거치고 난 후, residual skip connection(잔차 연결)은 각 서브 컴포넌트의 입력을 출력 값에 추가한다.
피드포워드 신경망, skip connection, attention weights, 그리고 전체 stack의 입력과 출력에서 드롭아웃(Dropout)이 적용된다. 디코더는 인코더와 구조적으로 유사한데, 한 가지 차이점은 디코더는 각 셀프 어텐션 레이어 이후 표준 어텐션 매커니즘을 추가한다는 것이다. 디코더의 셀프 어텐션 메커니즘은 자기회귀(autoagressive) 또는 캐쥬얼 셀프 어텐션의 형태를 사용하는데, 이러한 형태는 모델이 지난 출력을 활용할 수 있도록 한다. 최종 디코더 블록의 출력은 dense layer로 전달되어 소프트맥스 출력(softmax output)값을 생성하고, 이 dense layer의 가중치는 입력 임베딩 행렬과 공유된다. 트랜스포머에서 모든 어텐션 매커니즘은 독립적인 “헤드(heads)”로 분리되는데, 이러한 헤드의 출력은 전방으로 진행하기 앞서 연결(concatenate)된다.
셀프 어텐션(self-attention)은 순서에 의존하지 않기(order-independent) 때문에, (즉, 셀프 어텐션은 집합 연산이기 때문에) 트랜스포머에 명확한 위치 신호를 제공할 수 있다. 원본 트랜스포머 모델은 사인파(sinusoidal) 위치 신호를 사용하거나 학습된 위치 임베딩(position embeddings)을 사용했는데, 최근에는 상대적 위치 임베딩(relative position embeddings)을 사용하는 것이 보편화되었다. 상대적 위치 임베딩은 각 포지션에 고정된 임베딩을 사용하지 않고, “키(key)”와 “쿼리(query)” 간의 오프셋에 따라 다른 학습된 임베딩을 사용한다.
또한, 모델은 각 “임베딩”이 단순하게 어텐션 가중치를 연산하는 데 사용되는 로짓(logit)에 부여된 스칼라 값일 경우, 위치 임베딩의 형식을 단순화하여 사용한다. 효율성을 위해 모든 레이어의 위치 임베딩 파라미터를 공유하는데, 다만 주어진 레이어 내의 각 어텐션 헤드(attention head)는 상이한 위치 임베딩을 사용한다.
일반적으로, 키-쿼리(key-query) 오프셋의 범위에 상응하는 고정된 수의 임베딩이 학습된다. 본 논문의 연구에서는 모든 모델에서 32개의 임베딩을 사용하고, 임베딩 범위의 크기는 동일한 임베딩이 할당되는 모든 relative positions를 넘어서는 오프셋인 128까지 로그적으로 증가한다. 주어진 레이어는 128 토큰을 초과하는 relative position에는 민감하게 반응하지 않으나, 후속 레이어의 경우 이전 레이어의 국소 정보(local information)을 결합함으로써 더 큰 오프셋에 민감해질 수 있다.
요약하자면, T5 모델은 Vaswani et al. (2017)에서 제안된 원본 트랜스포머 모델과 거의 동일하지만, 레이어 노름(Layer Norm) 편향을 제거하고, 레이어 정규화를 residual path 밖으로 이동시키고 다른 위치 임베딩 전략을 사용한다는 점이 다르다.
2.2 The Colossal Clean Crawled Corpus (C4)
NLP 분야의 전이 학습에 대한 대부분의 선행 연구에서는, 비지도 학습을 위해 라벨링되지 않은 대규모 데이터를 사용한다. 본 논문에서는 라벨링 되지 않은 데이터의 질, 성격, 그리고 크기의 영향을 측정하고자 한다. 이러한 측면에서 데이터를 생성하기 위해, Common Crawl을 웹에서 스크랩된 텍스트 소스로 활용한다. Common Crawl은 NLP 분야에서 텍스트 데이터 소스로 사용되어 왔다(예를 들면, n-gram 언어 모델 훈련, commonsense reasoning 훈련 데이터, 기계 번역을 위한 parallel text minings, 사전학습 데이터 셋, 옵티마이저 테스트를 위한 대량의 텍스트 코퍼스).
Common Crawl은 대중적으로 이용 가능한 웹 저장소로, HTML 파일에서 추출된 마크업이나 다른 non-text 데이터를 제거한 “웹에서 추출된 텍스트”를 제공한다. 이러한 프로세스는 달마다 20TB의 스크랩 텍스트를 제공한다. 불행히도, 이러한 텍스트의 대부분은 자연어가 아니다. 대신, 대부분 메뉴, 오류 메시지, 중복 텍스트와 같은 의미 없는 문구(gibberish)나 표준문구(boiler-plate)로 구성된다. 더욱이, 스크랩 된 텍스트의 많은 양이 논문에서 고려하는 어떤 태스크에도 유용하지 않을 것 같은 내용을 담고 있다 (공격적인 언어, 플레이스홀더, 소스코드 등과 같은..). 이러한 문제들을 해결하기 위해, 본 논문에서는 Common Crawl의 웹 추출 텍스트를 클리닝 하기 위해 다음과 같은 휴리스틱한 방법을 사용한다.
- 종단 구두점( 반점, 느낌표, 물음표, 종료 인용부호)로 끝나는 라인만 유지한다.
- 5문장 이하의 페이지는 버리고, 최소 3글자 이상을 가진 라인만 유지한다.
- “List of Dirty, Naughty, Obscene or Otherwise Bad Words”에 속한 단어(더러운, 무례한, 음란한, 비속어)가 있는 페이지는 제거한다.
- 스크랩된 페이지의 대다수는 자바스크립트(Javascript)가 활성화 되어야 한다는 경고문을 포함한다. 따라서 자바스크립트 단어를 포함한 모든 라인을 제거한다.
- 일부 페이지는 “lorem ipsum”(내용보다 디자인 요소를 강조하기 위해 사용되는 텍스트) 플레이스홀더를 포함한다. 따라서 “lorem ipsum”구가 있는 모든 페이지를 제거한다.
- 일부 페이지에는 코드가 포함되어 있다. “{” 문구가 대다수의 프로그래밍 언어(웹에서 많이 사용되는 자바스크립트와 같이)에서 출몰하고 자연 텍스트에서는 나타나지 않기 때문에, “{” 를 포함한 모든 페이지를 제거한다.
- 데이터셋 중복을 제거하기 위해, 데이터셋에서 두 번 이상 나타난 3문장 스팬은 하나만 남기고 모두 제거한다.
추가로, 논문에서 다룬 대부분의 다운스트림 태스크가 영어 텍스트이기 때문에, 영어로 쓰이지 않은 페이지를 langdetect를 사용하여 0.99 확률로 필터링했다. 본 논문의 휴리스틱 방식은 NLP에서 많이 사용되는 Common Crawl에서 영감을 받은 것이다. 예를 들면, Grave et al. (2018)은 automatic language detector를 사용하여 텍스트를 필터링하고 짧은 라인을 제외시킨다. Smith et al. (2013), Grave et al.(2018)은 라인 중복 제거를 수행한다. 그러나, 본 논문에서는 선행 데이터 셋이 휴리스틱필터링에 더 집중되어 있고, 공개적으로 이용가능하지 않거나 데이터의 범위가 달라서 (예를 들면, 뉴스 데이터에만 한정되어 있다던지, Creative Commons content로만 구성되어 있다던지, 기계 번역을 위한 병렬 학습 데이터에만 집중되어 있다던지) 새로운 데이터 세트를 만들고자 한다.
T5의 베이스 데이터셋을 모으기 위해, 2019년 4월에 웹에서 추출된 텍스트 데이터를 받아 앞에서 설명한 필터링 과정을 적용한다. 그 결과로 사전학습에 사용되는 대부분의 데이터셋(약 750B)보다 훨씬 큰 규모이면서 reasonable하게 클린하고 내츄럴한 영어 텍스트로 구성된다. 이 데이터셋은 Colossal Clean Crawled Corpus(C4) 라고 부르며 텐서플로우 데이터셋 중 하나로 릴리즈되어 있다.
2.4. Input and Output Format
다양한 태스크에 단일 모델을 훈련시키기 위해서 모든 태스크를 “text-to-text” 형식으로 변환한다. 즉, 모델이 문맥이나 조건이 주어진 텍스트를 입력받은 후, 출력 텍스트를 생산하는 작업 방식이다. 이러한 프레임워크는 사전학습과 파인튜닝에서 모두 일관된 training objective를 제공한다. 특히, 모델은 모든 작업에서 “teacher forcing(Williams and Zipser, 1989)”을 사용하여 maximum likelihood objective로 훈련된다. 모델이 수행할 작업을 지정하기 위해서, 원본 입력 시퀀스에 태스크 명시적인 접두어(prefix)를 추가하여 모델에 제공한다.
예를 들면, “That is good.” 이라는 영어 문장을 모델에게 독일어로 번역해달라고 요청하기 위해서, 모델은 “translate English to German : That is good.이라는 시퀀스를 입력받고, “Das ist gut.”를 출력하도록 훈련된다. 텍스트 분류 태스크를 위해, 모델은 단순히 목표하는 라벨에 대응하는 하나의 단어를 예측한다. 예를 들면, MNLI benchmark는 전제(premise)가 가정을 함의(entailment)하는지, 모순(contradiction)하는지, 아니면 중립(neutral)인지 예측하는것이 목표이다. 전처리를 통해서, 입력 시퀀스는 “mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are filled with animosity.”가 되며, 해당하는 목표 단어는 “함의(entailment)”이다.
본 모델이 어떠한 라벨에도 대응되지 않는 텍스트 분류 문제에서 텍스트를 출력한다면, (예를 들면, 한 태스크에 대해 유효한 라벨이 “함의”, “중립”, “모순” 뿐일 때, 모델이 “hamburger”를 출력했다고 해보자). 이러한 경우에는 어떠한 훈련 모델에서도 모델의 이러한 행동을 관측하지 못했지만, 항상 모델의 출력이 잘못 된 것으로 여기게 될 것이다. 주어진 태스크에 사용될 텍스트의 접두어를 선택하는 것은 본질적인 하이퍼파라미터다. 본 논문에서는 접두어의 명확한 워딩을 변경하는 것의 영향이 한정되어 있다는 것을 발견했고, 다양한 접두어 선택에 대한 실험은 수행하지 않는다. 입/출력 예제 몇가지가 포함된 text-to-text 프레임워크의 다이어그램은 Figure 1에 나와 있다.
3. Experiments
3.1. Baseline
베이스라인의 목적은 전형적이고, 현대적인 관행에 대해 되돌아보기 위함이다. 본 논문에서는 표준 트랜스포머 모델(Section 2.1에서 설명)을 단순한 denoising objective를 사용하고 각 다운스트림 태스크에 개별적으로 파인튜닝한다. 다음의 서브 섹션에서는 experimental setup에 대한 세부사항을 설명한다.
3.1.1. Model
T5 모델에서는 표준 인코더-디코더 트랜스포머 모델Vaswani et al. (2017)을 사용한다. NLP 분야 전이학습에 대한 현대 접근법의 대부분이 단일 “스택(stack)”으로 구성된 트랜스포머 구조를 사용하는데 (예를 들면, 언어 모델링이나 분류, 스팬 예측에서), 표준 인코더-디코더 구조를 사용하는 것이 생성적 태스크와 분류 태스크에서 모두 좋은 결과를 얻는다는 것을 발견했다. Section 3.2에서는 다양한 모델 구조의 성능에 대해 탐구한다.
T5 베이스라인 모델은 인코더 디코더가 “” 의 크기와 구성 면에서 유사하도록 설계되었다. 구체적으로, 인코더와 디코더는 12개의 블록으로 구성되어 있다 (각 블록은 셀프 어텐션, optional 인코더-디코더 어텐션, 그리고 피드포워드 신경망으로 구성됨). 피드 포워드 신경망은 각 블록에서 의 출력 차원을 갖는 dense layer(밀집층)로 구성되어 있고, ReLU 활성화 함수와 또다른 dense layer로 이어진다. 모든 어텐션 메커니즘의 “키”와 “밸류” 매트릭스의 내부 차원은 이며 모든 어텐션 매커니즘은 12개의 헤드를 갖는다. 다른 모든 서브 레이어와 임베딩은 의 차원을 갖는다. 종합적으로, 모델은 약 220M 개의 파라미터를 갖는다. 이는 대략 모델 파라미터의 2배정도로, T5의 베이스라인 모델이 레이어 스택 2개로 구성되어 있기 때문이다. 규제(regularization)를 위해, 모델의 모든 드롭아웃 위치에 0.1의 드롭아웃을 적용한다.
3.1.2. Training
Section 2.4에서 설명한 바와 같이, 모든 태스크는 text-to-text 태스크 형태로 형성된다. 이러한 방법은 표준 최대 우도와 크로스 엔트로피 손실을 사용하여 훈련 (즉 teacher forcing을 사용하여)할 수 있도록 한다. 최적화(optimization)를 위해, AdaFactor(Shazeer and Stern, 2018)를 사용한다. test time에서는 탐욕적 디코딩(greedy decoding)을 사용한다 (즉, 모든 타임스텝에서 가장 높은 확률의 로짓을 선택하는 방법).
각 모델은 파인튜닝 전 C4 데이터셋에서 스텝동안 사전훈련된다. 최대 시퀀스 길이는 512, 배치 크기는 128 시퀀스이다. 가능한 각 배치 항목에 여러 시퀀스를 “패킹(pack)”하여 배치에 대략 토큰이 포함되게 한다. 이 배치크기와 스텝 수는 총합하면 약 토큰으로 사전학습한 것과 같다. 이러한 수치는 137B 토큰을 사용한 BERT (Devlin et al., 2018)나 약 2.2T 토큰을 사용한 RoBERTa (Liu et al., 2019c)보다 훨씬 적다. 토큰만 사용하더라도 합리적인 계산 예산을 제공하면서 충분한 사전 학습 양으로 성능을 보장한다. Section 3.6, 3.7에서는 더 많은 스텝을 사용한 사전학습의 효과에 대해 고려한다. 토큰은 전체 C4 데이터셋의 일부만 커버하므로, 어떤 데이터도 사전 학습중에 반복이 발생하지 않는다.
사전학습 동안에는 “역 제곱근(inverse square root)” 학습률 스케쥴( )이 사용된다. 여기서 n은 현재 학습 이터레이션(iteration)을 나타내며, k는 웜업(warm up) 단계 수로 모든 실험에서 로 설정된다. 이렇게 하면, 처음 단계에서 학습률 0.01이 일정하게 유지되며, 그 후 사전학습이 완료될때까지 지수적으로 학습률이 감소한다. Howard와 Ruder(2018)의 삼각 학습률(triangular learning rate)도 실험했는데 약간 더 좋은 결과를 얻었으나, 전체 학습 단계 수를 미리 알아야 하고 일부 실험에서 학습 단계 수가 변하기 때문에 더 일반적인 역 제곱근 스케줄이 선택되었다.
T5 모델은 모든 태스크에서 스텝동안 파인튜닝된다. 이러한 값은 추가적인 파인튜닝으로 혜택을 보는 고자원의 태스크(즉, 데이터 셋 크기가 큰)와 빠르게 과적합되는 저자원의 태스크(데이터셋 크기가 작은)간의 상충(trade-off)이다. 사전학습 동안, 128 길이의 512 시퀀스 배치를 (즉, 배치마다 개의 토큰이 포함됨) 계속해서 사용한다. 파인튜닝에서는 상수 학습률 0.001을 사용한다. 모든 5,000 스텝마다 체크포인트를 저장하고, 가장 높은 검증 성능을 보이는 체크포인트의 결과를 리포트한다. 다중 태스크에서 파인튜닝된 모델의 경우, 각각의 태스크 개별적으로 최고의 체크포인트를 선택한다. Section 3.7 외 모든 실험에 대해서 테스트 세트에서 모델을 선택하지 않도록 검증 세트의 결과를 보고한다.
3.1.4. Unsupervised Objective
T5 모델 사전학습에 사용되는 라벨링되지 않은 데이터를 활용하기 위해서는 라벨을 요구하지 않으면서 모델에게 다운스트림 태스크에 유용한 일반화 가능한 지식을 가르칠 수 있는 objective를 필요로 한다.
모든 모델 파라미터를 사전학습과 파인튜닝하는 전이학습 패러다임을 NLP 문제에 적용한 초기 연구에서는 사전학습에서 casual language modeling objective(시퀀스 내에서 다음 토큰을 예측하는 방식)를 사용했다 (Dai and Le, 2015; Peters et al., 2018; Radford et al., 2018; Howard and Ruder, 2018). 그러나, 최근에는 “denoising” objectives (Devlin et al., 2018; Taylor, 1953) (마스크 언어 모델링 “masked language modeling” 이라고도 함)가 더 좋은 성능을 보이고 결국 이 방식이 표준이 되었다. denoising objective에서, 모델은 입력에 없는(missing), 또는 손상된(corrupted) 토큰을 예측하도록 훈련된다. BERT의 “masked language modeling” objective와 “word dropout” 규제 테크닉 (Bowman et al., 2015)에 영감을 받아, 본 논문에서는 입력 시퀀스에서 임의로 샘플링한 후 입력 시퀀스의 15%의 토큰을 드롭아웃하는 objective를 설계한다. 모든 드롭아웃된 토큰의 순차적인 span들은 단일 sentinel token(고유 마스크 토큰)으로 대체된다. 각 sentinel token은 시퀀스에서 고유한 토큰 ID를 할당받는다. sentinel ID는 스페셜 토큰으로, 어휘(vocabulary)에 추가되며 워드피스(wordpiece)에 해당되지 않는다. 타깃은 모든 드롭아웃 토큰의 스팬에 해당하고, 입력 시퀀스에서 사용된 동일한 sentinel token에 의해 구분된다. 또한, 추가된 마지막 sentinel token은 타깃 시퀀스의 끝을 표시한다. 연속하는 토큰 스팬을 마스킹하고 드롭아웃된 토큰만 예측하는 것은 사전학습의 연산 비용을 줄여준다. 이러한 objective를 적용한 변환 결과 예제는 Figure 2에서 볼 수 있다. Section 3.3에서 사전학습 objectives에 대해 철저히 검사하고, 이 objective의 다른 변형과 비교한다.

- (Figure 2)
이 예제에서, “Thank you for inviting me to your party last week.”라는 문장을 처리한다. “for”, “inviting”, “last” (×로 마스킹 된 단어)는 임의로 선택되어 손상된 단어이다. 손상된 토큰의 각 연속한 스팬은 예제 내에서 유일한 sentinel token으로 대체된다.(와 ). “for”와 “inviting”은 연속적으로 발생하기 때문에, 단일 sentinel 로 대체된다. 그리고 나면 출력 시퀀스는 드롭아웃 스팬으로 구성되고, 입력에서 드롭아웃 스팬을 대체하는 데 사용되는 sentinel token으로 구분되며 마지막 sentinel token 을 추가한다.
3.2. Architectures
트랜스포머는 원래 인코더-디코더 구조로 소개되었는데, 대부분의 현대 NLP 전이학습 연구에서는 대안적인 구조를 사용한다. 본 Section에서 이러한 구조적 변형에 대해 리뷰 및 비교한다.
3.2.1. Model Structures
다양한 구조를 구분하는 주요인은 모델에서 “마스크(mask)”가 다양한 어텐션 메커니즘으로 사용된다는 것이다. 트랜스포머에서 셀프 어텐션 연산은 시퀀스를 입력으로 받고 동일한 길이의 새로운 시퀀스를 출력한다는 것을 기억하라. 각 출력 시퀀스의 엔트리는 입력 시퀀스 엔트리의 가중 평균을 연산하여 생산된다. 구체적으로, 가 출력 시퀀스의 번째 요소를 나타내고, 가 입력 시퀀스의 번째 엔트리를 나타낸다고 하자. 는 로 연산된다. 여기서 는 와 의 함수로 셀프 어텐션 메커니즘으로 생산된 스칼라 가중치이다. 어텐션 마스크는 주어진 출력 타임스텝에서 입력의 특정 항목에 집중을 제한하기 위해 특정 가중치를 0으로 만드는 데 사용된다. Figure 3은 본 논문에서 고려한 마스크 다이어그램이다.
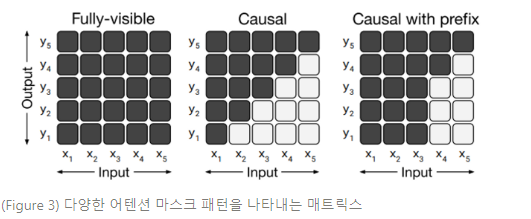
- (Figure 3)
셀프 어텐션 메커니즘의 입력과 출력은 각각 , 로 나타낸다. 행과 열의 까만 셀 부분은 셀프 어텐션 메커니즘을 통해 출력 타임스텝 에서 입력 에 집중할 수 있다는 것을 보여준다. 흰 셀 부분은 셀프 어텐션 메커니즘을 통해 해당하는 와 결합에 집중할 수 없다는 것을 보여준다.
Left : 완전히 가시적인(fully-visible) 마스크는 셀프 어텐션 메커니즘을 통해 모든 출력 타임스텝에서 전체 입력에 집중할 수 있다.
Middle : casual mask는 번째 출력 요소가 “미래”의 어떤 입력 요소에도 의존하지 않도록 한다.
Right : 접두사를 사용한 casual masking은 셀프 어텐션 메커니즘이 입력 시퀀스의 일부에 대해서만 fully-visible mask를 사용할 수 있도록 한다.
예를 들면, Figure 3 중앙의 casual mask는 일 때 모든 를 0으로 세팅한다.
본 논문에서 고려한 첫 번째 모델 구조는 인코더-디코더 트랜스포머로, 2개의 레이어 스택으로 구성된다 : Encoder는 입력 시퀀스를 전달받고, Decoder는 새로운 출력 시퀀스를 생산한다. Figure 4의 왼쪽 패널에서 이러한 구조적 변형의 도식을 보여준다.
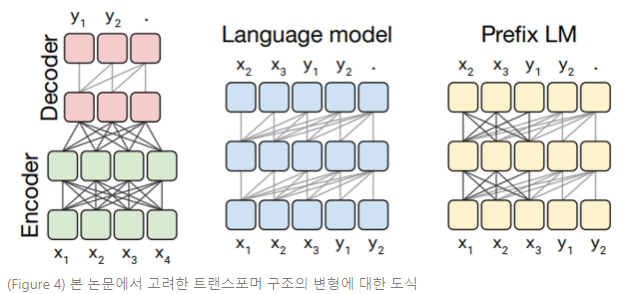
- (Figure 4)
이 도식에서, 블록(block)은 시퀀스 요소들을 나타내고 라인(line)은 어텐션 가시성(visibility)을 나타낸다. 다양한 블록 색상 그룹은 여러 트랜스포머 레이어 스택을 나타낸다. 짙은 회색 라인은 fully-visible masking을 나타내고, 밝은 회색 라인은 casual masking을 나타낸다. “.”은 예측의 끝을 나타내는 special end-of-sequence token을 나타낸다. 입출력 시퀀스는 각각 , 로 나타낸다.
Left : 표준 인코더-디코더 구조는 인코더와 인코더-디코더 어텐션에서 fully visible masking을 사용하고, 디코더에서 casual masking을 사용한다.
Middle : 언어 모델은 단일 트랜스포머 레이어 스택으로 구성되고, casual mask를 사용하여 입력과 타깃의 연결(concatenation)을 전달받는다.
Right : 언어 모델에 접두사를 추가하는 것은 입력에 fully-visible masking을 허용하는 것과 같다.
인코더는 “fully-visible” 어텐션 마스크를 사용한다. fully-visible masking은 셀프 어텐션 메커니즘을 통해 각 출력 항목을 생성할 때 모든 입력 항목에 집중할 수 있도록 한다. 이러한 마스킹 패턴은 Figure 3 왼쪽에 해당한다. 이러한 마스킹 형태는 “접두사(prefix)”에 집중할 때 적절하다. 즉, 모델에 제공된 일부 문맥은 이후 예측에 사용된다. BERT (Devlin et al., 2018)는 fully-visible한 마스킹 패턴을 사용하고 special “classification” 토큰을 입력에 추가한다. BERT의 classification token에 해당하는 타임스텝 출력은 입력 시퀀스를 분류하기 위한 예측에 사용된다.
트랜스포머 디코더에서 셀프 어텐션 연산은 “casual” 마스킹 패턴을 사용한다. 입력 시퀀스의 번째 항목을 생성할 때, casual masking은 모델이 인 입력 시퀀스의 번째 항목에 집중하지 못하도록 한다. casual masking은 훈련 동안 사용되어 모델이 출력을 생성하여 미래를 볼 수 없도록 한다. Figure 3 중앙은 이러한 마스킹 패턴의 어텐션 매트릭스를 나타낸다.
인코더-디코더 트랜스포머의 디코더는 자기회귀적으로(autoregressively) 출력 시퀀스를 생산한다. 즉, 각 출력 타임스텝에서 토큰은 모델의 예측 분포에서 샘플링되고, 이 샘플은 다음 출력 타임스텝의 예측을 생산하기 위해 모델에 입력된다. 이러한 방식으로, 트랜스포머 디코더는 (인코더 없이) 언어 모델(LM)으로 사용될 수 있다. 즉, 다음 스텝 예측만을 위해 훈련된 모델이다(Liu et al., 2018; Radford et al., 2018; Al-Rfou et al., 2019). 이러한 모델은 본 논문에서 고려한 두 번째 모델 구조를 구성한다. Figure 4 중앙은 이 구조의 도식을 나타낸다.
실제로, NLP의 전이 학습에 대한 초기 연구에서는 이러한 구조를 사전 학습 방법으로 language modeling objective와 함께 사용했다 (Radford et al., 2018).
언어 모델은 일반적으로 압축이나 시퀀스 생성에 사용된다. 그러나, 언어 모델은 단순하게 입력과 타깃을 연결함으로써 text-to-text 프레임워크에 사용될 수 있다. 예를 들면, 영어를 독일어로 번역하는 경우를 생각해 보자. 입력 문장이 “That is good.”이고 목표 문장이 “Das ist gut.”인 훈련 데이터 포인트가 있으면, 연결된 입력 시퀀스 "translate English to German: That is good. target: Das ist gut."에서 다음 스텝 예측을 통해 모델을 간단히 훈련할 수 있다. 이 예제에 대한 모델의 예측값을 얻고 싶으면, 모델에 "translate English to German: That is good. target:"와 같은 접두사를 제공하고 나머지 시퀀스를 자동으로 생성하도록 요청하면 된다. 이러한 방식으로 모델은 입력에 대한 출력 시퀀스를 예측할 수 있으며, 이는 text-to-text 태스크의 필요성을 충족한다. 최근 이러한 접근법은 일부 text-to-text 태스크를 지도 없이 수행하도록 훈련할 수 있다는 것을 입증하기 위해 사용되었다(Radford et al., 2019).
언어 모델을 text-to-text setting에서 사용하는 것은 근본적이고 흔히 인용되는 단점이 하나 있는데, 바로 casual masking은 모델 입력 시퀀스의 번째 항목 representation이 이전 항목에만 의존하도록 강제한다는 것이다. 이러한 단점이 왜 잠재적인 단점이 되는지를 알기 위해서, 모델이 예측 전에 prefix/context를 입력받는 텍스트 투 텍스트 프레임워크에 대해 생각해 보아야 한다. (예를 들면, prefix는 영어 문장이고, 모델은 독일어 번역을 예측하는 것이다) fully casual masking을 사용한 모델의 prefix state representation은 prefix 이전 항목에만 의존한다. 따라서 출력 항목을 예측할 때, 모델은 불필요하게 제한된 prefix representation에 집중하게 될 것이다. 단방향 순환 신경망 인코더를 사용하는 sequence-to-sequence 모델에서도 이와 유사한 주장을 제기했다 (Bahdanau et al., 2015).
이러한 문제점은 단순히 마스킹 패턴을 바꿈으로써 트랜스포머 기반 언어 모델에서 극복되었다. casual mask를 사용하는 대신, 시퀀스의 prefix 부분에 fully-visible masking을 사용한다. Figure 3, 4의 오른쪽 모형에서 각각 이러한 마스킹 패턴과 “prefix LM”의 도면 (본 논문에서 고려한 세 번째 모델 구조)을 설명한다. 앞서 언급했던 영어를 독일어로 번역하는 예제에서, fully-visible masking은 prefix “translate English to German: That is good. target:”에 적용되고, casual masking은 타깃 “Das ist gut.”을 예측하는 훈련 동안 사용된다. text-to-text 프레임워크에서 prefix LM을사용하는 것은 본래 Liu et al. (2018)에서 제안되었다. 최근, Dong et al. (2019)은 이러한 구조가 다양한 text-to-text 태스크에서 효과적이라는 것을 입증했다. 이러한 구조는 인코더-디코더 구조와 유사하고, 인코더와 디코더간 파라미터가 공유되고, 인코더-디코더 어텐션을 입력 시퀀스와 타깃 시퀀스 간 전체 어텐션으로 대체한 것이다.
본 논문에서 제시한 text-to-text 프레임워크에 따르면, prefix LM 구조는 분류 태스크에서 BERT 구조와 매우 유사하다. 그 이유를 알기 위해서, MNLI 벤치마크의 한 예제를 들어본다. 이 예제에서 전제는 “I hate pigeons.”이고, 가설은 “My feelings towards pigeons are filled with animosity.”이다. 그리고 정답 라벨은 “함의(entailment)”이다. 태스크 prefix가 주어지면(이 경우에는 “mnli”) 모델이 유효한 클래스 라벨 중 하나를 출력하는 것은 쉽다. 따라서, prefix LM과 BERT 구조의 주요한 차이는 분류기가 단순히 prefix LM 내 트랜스포머 디코더의 출력 레이어로 통합된다는 것이다.
3.7. Putting It All Together
- Objective i.i.d denoising objective를 SpanBERT(Joshi et al., 2019)에서 영감받은
span-corruption objective로 대체한다(Section 3.3.4에서 언급). 평균 span 길이는 3으로 하고, 원본 시퀀스의 15%를 손상시킨다. span-corruption 방식이 훨씬 더 나은 성능을 보이며, 시퀀스 길이가 더 짧기 때문에 연산 효율성이 약간 더 높은 것으로 나타났다 (Table 7 참조).
- Longer training T5 베이스라인 모델은 BERT의 사전학습 크기의 4분의 1, XLNet 사전학습 크기의 16분의 1, RoBERTa 사전학습 크기의 64분의 1을 사용한다. C4는 반복되는 데이터 없이도 충분히 긴 시간동안 학습할 수 있는 크기이다. Section 3.6에서, 추가 사전 학습이 유용하며 배치 사이즈와 훈련 스텝 수를 모두 증가시키는 것이 이러한 장점을 가져올 수 있다는 것을 발견한다. 따라서, T5 모델은 시퀀스 길이가 512인 개의 배치 사이즈에서 백만 번 동안 사전학습된다. 이는 사전 학습 토큰 약 1조개(베이스라인 모델의 32배 가량)에 해당한다. Section 3.4.1에서, 일부 다운스트림 태스크에서는 RealNews-like, WebText-like, Wikipedia + TBC 데이터셋에서 사전학습하는 것이 C4에서 사전학습하는 것보다 좋은 성능을 보였다. 그러나, 이러한 데이터셋의 변형은 1조개의 토큰에서 사전학습하는 과정에서 수백번 씩 반복될 만큼 적고, 이러한 반복이 유해하기 때문에 C4 데이터셋을 사용하는 것이다.
- Model sizes Section 3.6에서 베이스라인 모델 크기를 어떻게 키워야 성능을 향상시킬 수 있는지를 알아본다. 그러나, 더 작은 모델을 사용하는 것이 파인튜닝이나 추론에서 사용가능한 연산 리소스가 제한된 상황에서 더 유용할 수 있다. 이러한 요인 때문에, T5 모델은 다양한 크기로 훈련된다.
- Base : 베이스라인 모델의 하이퍼파라미터는 Section 3.1.1과 같다. 대략 2억 2천만개의 파라미터를 갖는다.
- Small : 베이스라인보다 더 작은 크기의 모델은 , 에 8개의 어텐션 헤드, 그리고 각 인코더와 디코더에 6개**의 레이어를 사용한다. 대략 6천만개의 파라미터를 갖는다.
- Large : 베이스라인 모델은 BERT base 크기의 인코더와 디코더를 사용하는데, 인코더와 디코더가 BERT large 크기와 비슷하도록 모델을 변형한다. large 모델은 , , 에 16개의 어텐션 헤드, 각 인코더와 디코더에 24개**의 레이어를 사용한다. 대략 7억 7천만개의 파라미터를 갖는다.
- 3B and 11B : 추가로 변형 된 2가지 모델이다. 3B, 11B에서는 모두 에 각 인코더와 디코더에 24개의 레이어를 사용하고, 이다. “3B”에서는 에 32개의 어텐션 헤드를 사용하여 총 28억개의 파라미터를 갖는다. “11B”에서는 에 128개의 어텐션 헤드를 사용하여 약 110억개의 파라미터를 갖는다.
- Multi-task pre-training Section 3.5.3에서, 사전학습에 앞서 비지도와 지도 학습 태스크의 멀티태스크 혼합물을 사전학습하는 것이 비지도 학습 태스크만 사전학습하는것만큼 잘 작동함을 입증했다. 이러한 접근법은 “MT-DNN(Liu et al., 2015, 2019b)”에서 주장한 방식이다. 또한, 이 접근법은 파인튜닝 뿐만아니라, 전체 훈련 기간동안 “다운스트림” 성능을 모니터링할 수 있다는 실질적 이점이 있다. 따라서, 본 논문에서는 실험 마지막 세트에서 멀티태스크 사전학습방식을 사용한다. 본 논문에서는 더 큰 모델은 작은 훈련 데이터 세트에서 과적합될 가능성이 높기 때문에, 더 큰 모델이 더 오랫동안 훈련될수록 라벨링되지 않은 데이터 비율이 더 큰 데서 이점을 취할 수 있다고 가정한다. 그러나, Section 3.5.3에서는 멀티태스크 훈련 후의 파인튜닝이 라벨링되지 않은 데이터의 차선 비율을 선택하는 데서 발생하는 몇가지 문제를 완화할 수 있다는 것이다. 이러한 아이디어를 바탕으로, 본 논문은 표준 예제비례 혼합법(standard example-propotional mixing, Section 3.5.2에서 설명함)을 사용 하기 전에 라벨링되지 않은 데이터의 인공 데이터 세트 크기를 다음과 같이 대체한다. : Small - 710,000, Base - 2,620,000, Large - 8,660,000, 3B - 33,500,000 및 11B - 133,000,000. 모든 모델의 변형에서, 사전 학습 중 WMT 영어-프랑스어 및 WMT 영어-독일어 데이터 세트의 효과적인 데이터 세트 크기를 1백만 예제로 제한했다.
- Fine-tuning on individual GLUE and SuperGLUE tasks 지금까지 GLUE와 SuperGLUE에서 파인튜닝 할 때, 각 벤치마크의 모든 데이터셋을 연결하여 GLUE에서 한 번, SuperGLUE에서 한 번만 모델을 파인튜닝시키면 된다. 이러한 접근법은 이 연구를 로직적으로 더 단순하게 만드는데, 이러한 접근법이 일부 태스크에서 태스크를 개별적으로 파인튜닝하는 방식에 비해 약간 성능이 떨어진다는 것을 발견했다. 개별적인 태스크로 파인튜닝하는 것의 잠재적 문제는 저자원 태스크에 빠르게 과적합될 수 있다는 것이고, 이는 모든 태스크를 한번에 훈련시킴으로써 완화 될 수 있다. 예를 들면, 저자원 GLUE, SuperGLUE 태스크에서 512 길이의 시퀀스를 개씩 처리하는 큰 배치 크기는 전체 데이터 세트가 여러 번 나타날 수 있다. 따라서, GLUE와 SuperGLUE 태스크를 각각 파인튜닝하는 동안 512 길이 시퀀스를 8개씩 처리하는 더 적은 배치 크기를 사용한다. 또한, 매 1,000 스텝마다 체크포인트를 저장하여 모델이 과적합 되기 전 파라미터에 접근할 수 있도록 한다.
- Beam search 이전까지 모든 결과는 탐욕적 디코딩 방법을 사용하여 리포트 되었다. 출력 시퀀스가 긴 태스크에서, beam search를 사용하면 성능이 향상된다는 것을 발견한다. WMT 번역과 CNN/DM 요약 태스크에서 beam width 4를, length penalty 을 사용한다.
4. Reflection
4.1. Takeaways
- Text-to-text text-to-text 프레임워크는 다양한 텍스트 태스크에 동일한 손실 함수와 디코딩 절차를 사용한 단일 모델을 훈련시키는 간단한 방법이다. 본 논문에서는 이러한 접근법이 생성 요약(abstractive summarization)과 같은 생성적 태스크나, 분류(classification)와 같은 자연어 추론, STS-B와 같은 회귀적(regression) 태스크에도 잘 적용될 수 있다는 것을 입증한다. 이 접근법은 단순하지만 태스크 명시적인 구조에 대적할만한 성능을 낼 수 있고, 모델 크기가 잘 결합되면 SOTA의 결과를 낼 수 있다.
- Architectures NLP의 전이 학습에 대한 연구들은 트랜스포머를 구조적으로 변형시키는 방식을 고려하였지만, 본 논문에서는 트랜스포머의 원본 인코더-디코더 구조를 text-to-text 프레임워크 내에서 작용시키는 것이 가장 좋은 결과를 내는 것을 발견한다. 인코더-디코더 모델은 BERT와 같이 “인코더만 사용하는(encoder-only)”, 혹은 언어 모델과 같이 “디코더만 사용하는(decoder-only)” 구조보다 2배 많은 파라미터를 사용하지만, 연산 비용은 비슷하다. 인코더와 디코더의 파라미터를 공유하는 것은 전체 파라미터 수를 반으로 줄이면서 성능을 크게 하락시키지 않는다는 것이 입증되었다.
- Unsupervised objectives 전반적으로, 가장 “denoising”한 objectives는 임의로 손상된 텍스트를 재구성하도록 모델을 훈련시키는 것으로, text-to-text setup과 유사한 성능을 보인다. 결과적으로, 본 논문에서는 비지도 사전학습이 더 효율적으로 연산되도록 짧은 타깃 시퀀스를 생성하는 objectives를 사용하는 것을 제안한다.
- Datasets 본 논문에서는 “Colossal Clean Crawled Corpus” (C4)를 제안한다. C4는 Common Crawl web dump에서 휴리스틱하게 클리닝된 텍스트이다. C4를 부가적인 필터링을 거친 데이터셋과 비교하면, 도메인 영역의 라벨링 되지 않은 데이터에서 훈련하는 것이 일부 다운스트림 태스크에서 성능을 향상시킬 수 있다는 것이 발견되었다. 그러나, 단일 영역으로 한정하는 것은 보통 더 적은 데이터 셋을 사용하게 만든다. 본 논문에서는 라벨링 되지 않은 데이터셋이 사전학습 동안 많이 반복될 정도로 적은 경우, 성능이 하락할 수 있다는 것을 발견했다. 이러한 결과가 제너릭한 언어 이해 태스크에서 C4와 같은 크고 다양한 데이터셋을 사용하도록 장려한다.
- Scaling 본 논문에서는 더 많은 데이터 훈련, 더 큰 모델 훈련, 앙상블 모델 사용과 같은 추가 연산의 이점을 취할 수 있는 다양한 전략들에 대해 비교한다. 각각의 접근법은 성능 면에서 큰 향상을 가져왔는데, 더 작은 모델을 더 많은 데이터로 훈련시키는 것이 더 적은 스텝으로 더 큰 모델을 훈련하는것보다 일반적으로 더 좋은 성능을 낸다는 것을 발견했다. 또한, 앙상블 모델이 단일 모델보다 훨씬 더 좋은 결과를 가져온다는 것을 입증했는데, 추가적인 연산을 활용하는 직교적인 방법을 제공한다. 동일한 베이스의 사전학습된 모델에서 파인튜닝된 앙상블 모델은 사전학습과 파인튜닝을 완전히 개별적으로 행한 모델보다 성능이 떨어지는데, 파인튜닝만 한 앙상블 모델이 단일 모델보다는 여전히 좋은 성능을 보인다.
- Pushing the limits 본 논문의 연구에서 얻은 통찰을 결합하여 충분히 큰 모델로 훈련시켰고 (110억 개 파라미터에 이르는) 많은 벤치마크에서 SOTA의 성능을 얻는다. 비지도 학습을 위해, C4 데이터 셋에서 텍스트를 추출하고 연속하는 토큰의 스팬을 손상시키는 denoising objective를 적용한다. 전반적으로, T5 모델은 1조 개 이상의 토큰으로 훈련되었다.
4.2. Outlook
- The inconvenience of large models 본 논문에서 당연하지만 중요한 연구 결과는, 더 큰 모델이 더 나은 성능을 보인다는 것이다. 이러한 모델을 돌리기 위한 하드웨어가 더 저렴해지고, 더 강력해지고 있다는 사실은 더 좋은 성능을 얻기 위해서 모델의 크기를 키우는 것이 유망한 방법이 된다는 것을 암시한다. 그러나, 더 작거나, 비용이 덜한 모델이 유용한 상황이 있다. 예를 들면, 클라이언트 측 추론이나 federated learning(연합 학습)과 같은 경우를 말한다. 이와 관련해서, 전이학습의 이점 중 하나는 저자원의 태스크에서 좋은 성능을 얻을 수 있는 가능성이다. 저자원의 태스크는 보통 더 많은 데이터를 라벨링할 자산이 부족한 경우에 발생한다. 따라서, 저자원 어플리케이션은 추가 비용을 발생시킬 수 있는 연산 리소스의 접근이 제한되어 있다. 결과적으로, 본 논문에서는 전이 학습이 가장 강력한 영향을 미칠 수 있는 곳에서 전이학습을 적용할 수 있도록, 더 저렴한 모델로 더 좋은 성능을 얻는 방법을 지지한다. 현재 이러한 방향으로 진행되고 있는 연구는 distillation (Hinton et al., 2015; Sanh et al., 2019; Jiao et al., 2019), 매개변수 공유 (Lan et al., 2019) 및 조건부 계산 (Shazeer et al., 2017) 등이 있다.
- More efficient knowledge extraction 사전학습의 목표 중 하나는 모델이 일반적인 목적의 “지식(knowledge)”을 갖춰 다운스트림 태스크의 성능을 향상시키기 위해서다. 본 논문에서 사용한 방법은 현재 일반적으로 사용되는 방법으로, 모델이 손상된 텍스트 스팬을 denoise하도록 훈련시키는 것이다. 이러한 가장 단순한 테크닉이 모델에게 일반적인 목적의 지식을 가르치는 데 효율적인 방법은 아닐 수 있다. 구체적으로, 1조 개의 텍스트 토큰으로 모델을 훈련시킬 필요 없이 좋은 파인튜닝 성능을 얻는 것이 유용할 수 있다. 현재 이러한 흐름을 가진 일부 연구에서는, 모델이 실제 텍스트와 기계 생성 텍스트를 구분하도록 사전학습시킴으로써 효율성을 향상시키고 있다 . (Clark et al., 2020)
- Formalizing the similarity between tasks 본 논문에서는 라벨링되지 않은 특정 도메인의 데이터가 다운스트림 태스크의 성능을 향상시킬 수 있다는 것을 관측했다 (Section 3.4). 이러한 발견은 크게 SQuAD가 위키피디아를 사용한 데이터에서 생성되었다는 사실과 같은 베이식한 관측에 의존한다. 사전학습과 다운스트림 태스크 간 “유사성”을 더욱 엄밀히 정의함으로써, 어떤 라벨링되지 않은 데이터 소스를 사용할지에 대한 원칙적인 선택을 더 쉽게 할 수 있다. 이러한 흐름에서 진행된 컴퓨터 비전 분야의 선행 연구들이 몇가지 존재한다 (Huh et al., 2016; Kornblith et al., 2018; He et al., 2018). 태스크의 연관성을 더 잘 파악하기 위해서는 지도 학습 방식의 사전학습 태스크를 선택하는 것이 도움이 될 수 있는데, 이러한 방식은 GLUE 벤치마크에서도 유용하게 사용되어 왔다.
- Language-agnostic models 본 논문에서는 영어만 사용한 사전 학습 방식이 번역 태스크에서 SOTA 성능을 가져오지 못한 것이 실망스러웠다. 또한, 사전에 어떤 단어를 인코딩할 수 있는 언어를 지정해야 하는 물류적 어려움을 피하고자 한다. 이러한 이슈를 해결하기 위해, 본 논문에서는 언어에 구애받지 않는 모델(language-agnostic model), 즉 텍스트의 언어와 관계없이 주어진 NLP 태스크에서 좋은 성능을 낼 수 있는 모델을 더 자세히 연구하고자 한다. 이는 특히 대다수 인구가 영어가 네이티브 언어가 아니기 때문에 적절한 문제이다. 본 논문의 동기는 최근 NLP의 전이학습에 대한 연구 붐이 일었기 때문이다. 이 연구가 시작되기 전, 학습 기반 방법이 효율성을 증명받지 못 한 상황에서 이러한 진보가 돌파구를 만들어 주었다. 본 논문은 SuperGLUE 벤치마크에서 인간 수준 성능을 달성하거나, 현대 전이학습 파이프라인을 위해 설계된 태스크와 같은 트렌드가 지속되길 바란다. 본 논문으 연구 결과는 직관적이고 통합된 text-to-text 프레임워크, 새로운 C4 데이터셋, 그리고 체계적인 연구에서 얻은 통찰력의 조합에서 비롯된다. 또한, 본 논문에서는 해당 분야의 경험적 개요와 현재 상황에 대한 전망을 제시한다.
