
| Robotics at Google, Everyday Robotics
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances (CoRL, 2022) 논문 읽고 내용 정리하기
읽은지는 좀 오래 됐는데 간만에 논문 리뷰 좀 올리려고 다시 훑고왔다..!!
그럼 바로 스땃또~
1. Introduction
최근 LLMs은 프롬프트 기반 복잡한 텍스트 생성, 질의응답, 다양한 주제에 대한 대화 등 다양한 자연어 태스크에서 큰 발전을 거두었다. 이러한 모델들은 웹에서 수집된 거대한 텍스트 말뭉치(text corpora)에서 방대한 양의 지식을 학습한다. 그리고 우리는 이러한 언어 모델이 지닌 일상적 작업에 대한 지식을 로봇과 같은 구체적이고 물리적인 행위를 수행하는 “embodied agent” 시스템에서 활용할 수 있을지 궁금증을 갖게 된다.
그러나, LLM은 현실 세계(physical world)에서의 경험이 없으며, 자신이 생성한 텍스트가 실제 상황에서 물리적으로 어떤 결과를 초래하는지 관측할 수 없다. 이로 인해, LLM은 우리에게 비합리적이고,유머러스한 실수를 저지를 수 있으며, 특정 물리적 상황에 대해 비논리적이고 위험한 방식으로 지시를 해석하게 될 수 있다.
예를 들어, 아래 Figure 1을 읽어 보자.
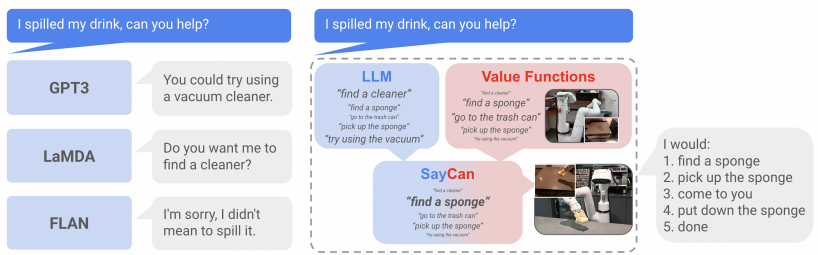
어떤 kitchen robot이 “pick up the sponge”, ”go to the table”과 같은 행동을 수행할 수 있다고 가정해 보자. 우리가 로봇에게 “I spilled my drink, can you help?” 라고 요청하면, LLM은 어떻게 답할까? 아마 Figure 1 왼쪽의 답변들(GPT3, LaMDA, FLAN)과 유사하게 “You could try using a vacuum cleaner”와 같이 그럴듯하지만 실제로는 쓸모 없는 응답을 제시하게 될 것이다. 이러한 답변은, 실제 환경에 진공청소기가 없거나, 로봇이 진공청소기를 사용할 능력이 없을 때 불가능한 행동이 된다.
적절한 prompt engineering을 통해 LLM이 high-level instruction을 sub-task로 분리할 수도 있겠지만, 이는 로봇이 현재 수행가능한 능력과 주변 환경에 대한 이해가 없다면 결국 한계가 있다. 즉, 언어 모델이 실세계에서 실행 가능한 계획을 생성하기 위해서는 로봇의 능력과 실제 환경을 고려하여야 한다.
본 논문은 이러한 동기를 바탕으로, LLM의 지식을 추출하여 로봇과 같은 embodied agent가 high-level textual instructions을 수행할 수 있도록 하는 방법을 연구한다. 이를 위해 로봇은 low-level visuomotor control이 가능하도록 atomic behaviors에 대한 사전 학습된 기술 목록을 갖추고 있다.
우리는 단순히 LLM이 명령(instruction)을 이해하는 것을 넘어, 각 행동(skill)이 high-level instruction을 성공적으로 완수하는 것에 대한 기여도를 확률로 스코어링하도록 한다.
또한, 각 행동마다 특정 상태에서의 성공 확률을 나타내는 affordance function이 존재한다면, 언어 모델이 제시한 확률과 이러한 어포던스 함수의 확률을 결합함으로써 특정 행동이 명령을 성공적으로 수행할 확률을 산출할 수 있다. 우리는 이러한 방식으로 로봇의 현재 상태와 능력을 고려한 실행 가능한 행동을 선택할 수 있게 된다. 또한 이렇게 선택된 행동은 로봇이 특정 지시에 대한 행동 계획의 fully explainable sequence를 생성하여, 계획에 대한 해석이 가능(interpretable)해진다.
본 논문에서 제안된 SayCan 은 LLM의 풍부한 지식을 physically-grounded tasks과 결합하는 접근법이다. 즉 SayCan에서는 (Say) LLM이 high-level goal을 달성하는 데 유용한 작업을 결정하는 task-grounding을 제공하고, (Can) 학습된 affordance function이 실제 세계에서 실행 가능한 행동을 결정하는 world-grounding을 제공한다. 본 논문에서는 reinforcement learning (RL)을 사용하여 language-conditioned value functions를 학습하고, 주어진 상황에서 가능한 행동에 대한 affordance를 판단할 수 있도록 한다.
본 논문은 실제 주방 환경(101개의 real-world robotic tasks)에서 mobile robot이 다양한 자연어 형태의 명령을 수행하고 제안된 방법론을 평가한다. 해당 실험을 통해 SayCan이 추상적이고 장기적인 자연어 지침을 실행할 수 있음을 입증했으며, 특히 affordance를 반영하면 그렇지 않은 기존의 접근법보다 약 2배의 성능이 향상됨을 확인했다. 또한, 다양한 LLM을 사용하여 성능을 평가함으로써 나은 언어 모델을 사용할수록 로봇의 작업 수행 성능도 자연스럽게 개선됨을 입증한다.
2. Preliminaries
Large Language Models.
언어 모델은 주어진 텍스트 시퀀스 의 확률 를 모델링하고자 한다. 일반적으로 다음과 같은 Chain rule을 통해, 각 단어의 확률을 이전 단어들의 조건부 확률로 표현한다.
최근에는 신경망 기반 Attention 구조가 등장하며, 언어 모델을 효율적으로 대규모로 확장할 수 있게 되었다. 이러한 모델에는 대표적으로 Transformers 기반 모델(BERT, T5, GPT-3, Gopher, LAMDA, FLAN , PaLM 등)이 포함되며, 이를 통해 소위 대형 언어 모델(Large Language Models, LLM)이라 불리는 모델들이 탄생했고, 방대한 규모의 텍스트 데이터를 통해 학습하여 다양한 작업과 주제에 걸쳐 일반화할 수 있는 뛰어난 성능을 보여준다.
본 연구에서는 LLM에 포함된 방대한 semantic knowledge를 활용하여, high-level instructions을 해결하기 위한 유용한 하위 작업들을 결정하고자 한다.
Value functions and RL.
본 연구의 목표는 “언어 명령으로 주어진 기술이 현 상태에서 실행 가능한지(feasible) 정확하게 예측”하는 것이다. 이를 위해, 본 논문에서는 temporal-difference(TD) 기반 강화 학습을 사용한다.
이에 앞서, 우리는 마르코프 결정 과정(Markov Decision Process, MDP)을 다음과 같이 정의한다:
- : 상태 공간(State Space)
- : 행동 공간(Action Space)
- : 상태 전이 확률(State-transition probability function)
- : 보상 함수(Reward function)
- : 할인율(Discount factor)
TD methods의 목표는 state 또는 state-action value functions (Q-function) 를 학습하는 것이다. 이 함수는 state 에서 action 를 수행하고, 이후 policy 를 따를 때 얻게 되는 미래의 할인된 보상(discounted sum of rewards)를 나타낸다. 이를 수식으로 표현하면,
이러한 Q-함수 는 다음과 같은 손실함수를 최적화하는 approximate dynamic programming을 통해 학습할 수 있다:
- : state과 action의 데이터셋
- : Q-function의 파라미터
본 논문에서는 TD 기반의 방법으로 학습된 가치 함수(value function)를 사용하는데, 이때 가치 함수는 추가로 language command에 따라 조건화된다(conditioned). 이를 통해, 특정 명령이 특정 상태에서 실행 가능한지(feasible) 여부를 결정할 수 있다.
또한, 에이전트(agent)는 보상이 희소하고(sparse reward), 할인이 적용되지 않는(undiscounted) 상황에서, (즉 성공하면 1.0, 실패하면 0.0의 reward를 얻는 경우) 강화학습을 통해 학습된 value function은 affordance function로 해석이 가능해진다. (즉, 이 때의 가치 함수는 현재 상태에서 특정 행동에 대한 성공률로 해석할 수 있다.) 본 논문은 이러한 직관을 활용하여 sparse reward tasks의 value function을 통해 affordance를 표현한다.
3. SayCan: Do As I Can, Not As I Say
Problem Statement.
SayCan은 사용자가 제공한 natural language instruction 를 입력하여, 로봇이 수행해야 할 작업(task)을 기술한다. 이 명령은 길거나(long), 추상적이거나(abstract), 모호할(ambiguous) 수 있다. 로봇에게는 행동 집합 (a set of skills) 이 주어지며, 각 skill 은 “특정 객체 집기”과 같은 short task를 수행하고, “find a sponge”와 같은 short language description 과 주어진 상태(state) 에서 스킬이 성공적으로 완료될 확률을 나타내는 affordance function 를 갖는다.
→ : 즉, 로봇에 skill π을 수행하라고 요청하면, 이를 로봇이 실제로 수행할 수 있는가?를 의미
강화학습 용어에서 는 skill π에 대한 가치 함수(value function)로, 성공적으로 완료하면 reward를 1로, 그렇지 못한 경우 0으로 설정한다.
위에서 언급했듯, 는 skill π의 textual label을 나타내고, 는 가 상태 에서 실행될 때 성공적으로 완료될 확률을 나타내며, 는 베르누이 랜덤 변수(Bernoulli random variable)이다.
LLM이 제공하는 확률 는 이 user’s instruction 에 대한 valid next step일 확률이다. 여기서 실제로 우리가 구하고자 하는 값은 주어진 skill이 실제로 명령을 성공적으로 수행할 확률로, 이를 로 아래와 같이 표현할 수 있다.
- : 특정 스킬이 명령 수행을 위해 올바른 선택일 확률 (Task-grounding)
- : 특정 상태에서 스킬이 성공 가능할 확률 (World-grounding)
Connecting Large Language Models to Robots.
대형 언어 모델은 풍부한 텍스트 데이터를 통해 학습된 지식을 활용할 수 있지만, high-level commands를 실제 로봇이 실행 가능한 low-level instructions으로 명확하게 분해하는 데 한계가 있다.
따라서 우리는 Prompt Engineering을 통해 언어 모델이 high-level instruction을 로봇이 실제 수행 가능한 낮은 수준의 명령(sequences of available low-level skills)으로 분해할 수 있도록 명확히 지도해야 한다.
prompt engineering은 언어 모델이 특정한 형태의 응답을 생성하도록 유도하는 기법으로, 본 논문에서 사용된 구체적인 프롬프트 내용 ablation study와 함께 Appendix D.3에 제시되어 있다.

D.3의 프롬프트 예제는 위 텍스트를 보면 된다.
그러나, 이러한 프롬프트 엔지니어링만으로는 출력을 embodied agent를 위한 admissible primitive skills로 제한하는 데 한계가 있으며, 때로는 실제로 허용되지 않는 행동이나 individual step으로 쉽게 구분할 수 없는 형식의 언어를 생성할 수 있다.
일반적인 언어 모델은 텍스트를 생성할 때, 각 단어를 확률적으로 예측한다. 즉, position에 나타나는 단어 에 대해 이전의 단어들 을 조건으로 하여, 생성 확률 을 계산한다. 대화형 에이전트 같은 일반적인 언어 모델 application에서는 이러한 확률 분포로부터 직접 단어를 샘플링하거나, maximum likelihood를 decoding하여 문장을 생성하게 된다.
반면, 본 논문에서는 LLM을 scoring lanugage model로 활용하여, 미리 정해진 후보 문장들(candidate completion) 중 각 문장이 얼마나 적합한지를 확률적으로 평가하는 데 사용한다.
즉, SayCan에서는 a set of low-level skills , language description 과 instruction 가 주어졌을 때, skill 의 language description이 instruction 를 실행하는 데 진전을 이룰 확률 을 계산한다. 그 다음 모델을 통해 potential completion을 쿼리하여, 언어 모델에 따른 optimal skill을 다음과 같이 계산한다.
이러한 방식으로 최적의 skill이 선택되고 나면, 반복적으로 이러한 skill을 선택하고 instruction에 추가함으로써 과정이 진행된다.
예를 들어, 사용자가 “How would you bring me a coke can?” 과 같이 high level-instruction을 제공하면, 언어 모델은 “I would: 1. $\ell_π$, 2. ..”와 같은 명시적인 시퀀스로 응답하며 대화 형식으로 계획을 구성한다. → “I would: 1. find a coke can, 2. pick up the coke can, 3. bring it to you”
SayCan.
SayCan의 핵심 아이디어는 대형 언어 모델(LLM)을 가치함수(value function)에 기반하여 현실 세계에 연결(grounding)하는 것이다.
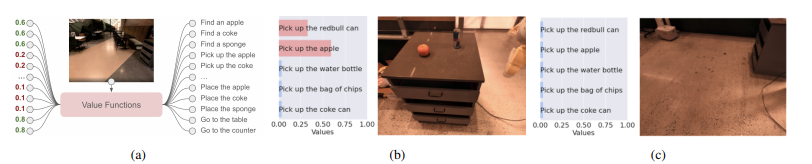
각 스킬 과 그에 대한 language description 및 해당 value function이 주어졌을 때, 이러한 가치 함수는 특정 상태에서 특정 skill이 성공적으로 완료될 확률 을 제공한다. 모든 skill에 대해 이 확률 집합은 affordance space 을 형성한다.
이때 각 스킬에 대한 어포던스 값과 LLM이 판단한 스킬의 확률을 곱하여 결합한 후, 가장 확률이 높은 스킬을 최종적으로 선택하여 실행한다:
스킬을 실행한 후 이 과정을 반복하여 다음 스킬을 선택하며, “done”과 같은 termination token이 나올 때까지 반복한다. 이러한 프로세스는(아래 그림과 알고리즘 1 참조) 매우 직관적인 확률적 해석을 갖는다:
- LLM은 명령 수행에 어떤 스킬이 유용한지에 대한 확률을 제공
- 어포던스는 각 스킬이 실제로 수행에 성공할 가능성을 제공
이 둘을 결합하여 "이 스킬이 현재 상태에서 사용자의 명령을 수행하는 데 실제로 유용할 확률"을 얻게 된다.

4. Implementing SayCan in a Robotic System
Language-Conditioned Robotic Control Policies.
SayCan 구현을 위해서 각 skill, policy, value function, short language description set을 제공해야 한다. 본 논문에서는 각 skill을 BC-Z method를 따르는 image-based behavioral cloning 또는 MT-Opt를 따르는 강화학습 방식으로 훈련한다.
- BC-Z (Behavioral Cloning with Zero-shot generalization) (2022) : arxiv.org
모방학습(Imitation Learning) 일종으로, 사람 또는 전문가가 제공한 데이터를 통해 직접 행동을 모방하도록 학습하는 방법
이미지 임베딩을 추출하고, 이를 입력으로 받아 행동 정책(policy)를 학습
- MT-Opt (Multi-Task Optimization) (2021) : arxiv.org
강화 학습(RL)의 한 종류로, 로봇이 multiple tasks를 동시에 학습하여, 하나의 일반화된 행동 정책(policy)을 얻기 위한 방법
다수의 작업을 동시에 학습(단일 Q-function)하여 새로운 작업에 일반화된 능력을 갖추게 하기 위함
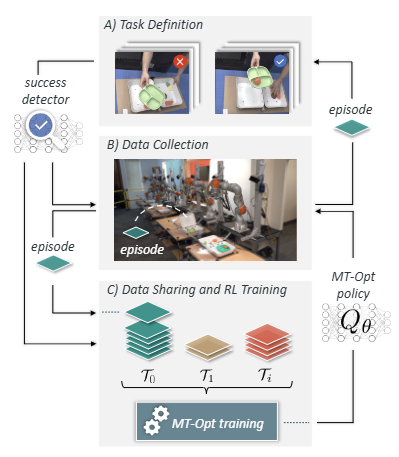
Training the Low-Level Skills.
본 논문에서는 language-conditioned policies와 value function을 얻기 위해, BC(Behavioral Cloning), RL policy 훈련 절차를 모두 활용한다. 본 논문에서 고려하는 underlying MDP(Markov Decision Process)의 설명을 완성하기 위해, policy와 value function이 사용하는 reward function과 skill specification에 대해 정의한다.
앞서 언급한 것처럼, 스킬 정의(specification)를 위해 short natural language descriptions을 사용하며, 이는 언어 모델의 임베딩(embeddings) 형태로 표현된다. 본 논문은 sparse reward function를 이용하며, 언어 명령이 성공적으로 완료된 경우 에피소드 종료 시점에 보상을 1.0으로 설정하고, 그렇지 않은 경우 0.0으로 설정한다.
여기서 언어 명령의 성공 여부는 사람에 의해 평가된다. 평가자들에게는 로봇이 주어진 명령을 수행하는 장면의 비디오와 그 명령이 함께 제공되고, 세 명의 평가자 중 최소 두 명이 성공적으로 수행되었다고 한다면 해당 에피소드는 positive reward (= 1.0)을 받게 된다.
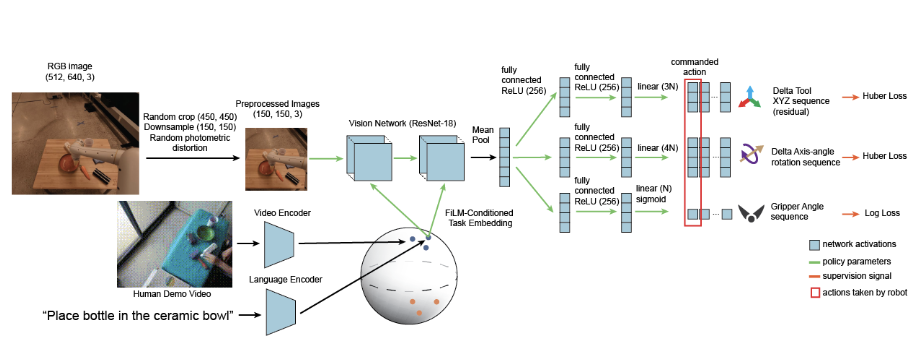
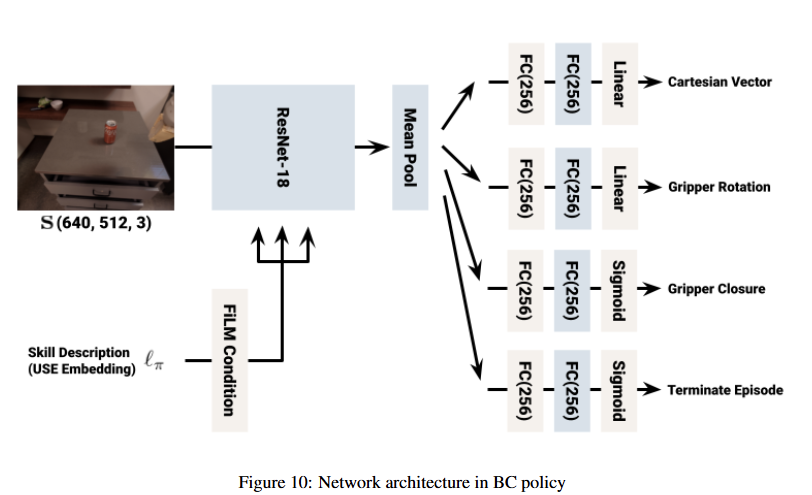
본 논문에서는 현실 세계에서 대규모의 language-conditioned BC policies을 학습하기 위해, BC-Z 방식과 유사한 policy-network 구조를 사용한다 (Figure 10).
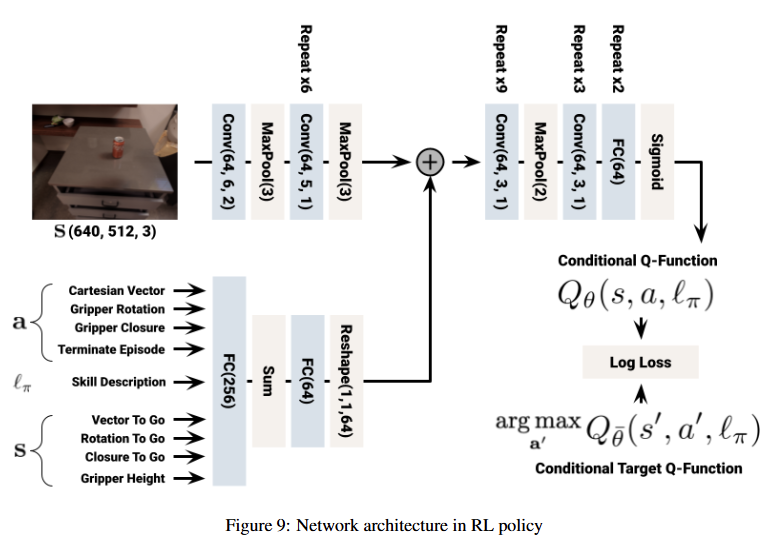
또한 language-conditioned RL policy을 학습하기 위해 Everyday Robots simulator에서 MT-Opt (Figure 9)를 사용하며, RetinaGAN을 이용한 시뮬레이션에서 sim-to-real transfer를 수행한다. (*RetinaGAN : 시뮬레이션에서 얻은 시각적 데이터를 실제 환경의 데이터처럼 변환하는 GAN-based method) → 시뮬레이션에서 학습한 정책이 현실 로봇에서도 잘 작동하도록 함
본 연구에서는 simulation demonstrations를 활용하여 초기의 정책이 일정 수준 이상 성공하도록 성능을 Bootstrapping하고, 이후 online data collection을 통해 RL 성능을 지속적으로 개선한다.
RL policy의 action space는 end-effector pose (6 DoF), 그리퍼의 손 제어(open/close), 로봇의 기초적인 이동을 위한 x-y position과 yaw delta, terminate action을 포함한다.
Robotic System and Skills
본 논문은 control policy를 위해 모바일 매니퓰레이터 로봇을 사용하여 다양한 조작 및 네비게이션 skill을 연구한다. picking, placing and rearranging 등 551개의 skill과 7개의 skill family, 그리고 17개의 객체를 다룬다.
5. Experimental Evaluation
Experimental Setup.
실험은 아래 그림과 같이 모의 주방 환경 및 실제 사무실 주방 환경에서 모바일 매니퓰레이터를 통해 진행되었다.

Instructions.
PaLM-SayCan 평가를 위해 ALFRED, BEHAVIOR 등의 벤치마크에서 영감을 받아 7개의 instruction familiy에서 총 101개의 지침을 검증하였다. 아래 표는 해당 지침들에 대한 예시이다.

Metrics.
본문에서는 제안된 방법의 성능을 평가하기 위해 2가지 metrics: plan success rate, execution success rate을 정의하고 측정한다. 평가 방법은 human rate 방식으로, 3명 중 2명 이상이 동의한 경우에만 성공으로 간주된다.
Plan Success Rate (계획 성공률): 모델이 선택한 skill이 주어진 지시에 대해 올바른지, 즉 계획 자체의 타당성을 평가Execution Success Rate (실행 성공률): 시스템이 지시를 실제로 성공적으로 수행하였는지, 즉 문자열에 지정된 작업을 달성했는지 평가
Results
아래 표는 101개의 태스크에 대한 PaLM-SayCan의 성능 지표를 기록한다.
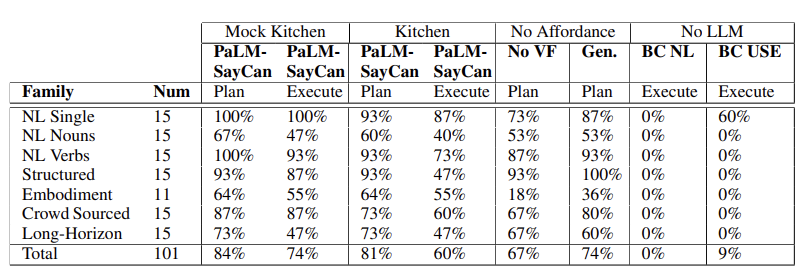
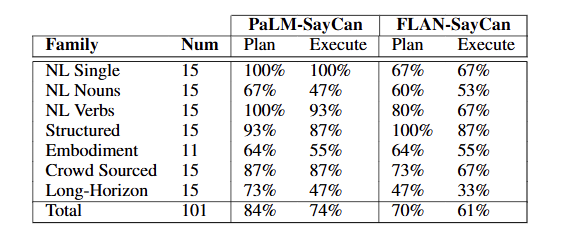
- 모의 주방 환경에서 PaLM-SayCan은 84%의 계획 성공률과 74%의 실행 성공률 달성
- 실제 주방 환경에서 PaLM-SayCan의 계획 성공률은 3%, 실행 성공률은 14% 감소함. 이는 PaLM-SayCan과 기반 정책들이 실제 환경에도 어느 정도 잘 일반화됨을 입증
- SayCan 방식(LLM+Affordance)은 단순히 언어 모델만으로 행동을 결정하는 방법(No Affordance)보다 약 2배 높은 성공률을 기록
- 더 크고 성능이 좋은 LLM을 사용할수록 로봇의 행동 성공률도 함께 증가

위 그림(Figure 5)은 2개의 long-horizon queries와 그에 대한 롤아웃 결과이다. 로봇이 주방 환경과 상호 작용하며, 조작 및 네비게이션 시퀀스를 성공적으로 수행함을 보여준다.

Figure 6은 PaLM-SayCan의 의사결정 과정과 해석 가능성을 강조한다. user instruction 내에서 “coke”가 언급되더라도, 중요한 객체가 “something to clean up”임을 이해하고 스펀지를 가져온다는 것을 보여준다.
7. Related Work
Grounding Language Models.
additional environment inputs: (부가적인 환경 정보 활용) 언어 모델에게 주변 환경에 대한 정보를 더 많이 제공하여, 시각적인 정보나 센서 데이터를 함께 학습하도록 함directly output action: (행동 직접 예측 방식) 언어 모델이 말로만 설명하는 것이 아니라, 직접 로봇의 행동을 결정하도록 학습. 언어 모델이 로봇에게 필요한 동작을 직접 지시prompt engineering: (프롬프트 엔지니어링 활용) 언어 모델에게 특정한 형식이나 스타일로 답변하도록 유도, 언어 모델이 현실 세계에 대한 지식을 더 잘 활용하도록 함pre-trained LLM representations: (사전 학습 표현을 활용) 이미 많은 텍스트 데이터로 학습된 언어 모델의 능력을 활용하여, 로봇이 새로운 환경이나 작업에 더 잘 적응하도록 함Fine-tuning: (파인튜닝 방식) 로봇이 실제로 행동하면서 얻는 데이터(예: 보상, 성공/실패 정보)를 사용하여 언어 모델을 추가적으로 학습
Learning Language-Conditioned Behavior.
- 언어와 행동을 연결하는 방법에 대한 연구는 오랫동안 진행되어 왔고, 특히 로봇이 자연어 명령을 이해하고 그에 따라 행동하도록 만드는 모방학습 또는 강화학습을 통한 language-conditioned behavior 분야가 활발히 연구되고 있음.
- 대부분의 기존 연구들은 로봇이 pick-and-place tasks와 같은 비교적 간단한 명령을 수행하도록 만드는 데 초점을 맞추고 있음. 하지만, 몇몇 연구들은 시뮬레이션 환경에서 로봇이 더 복잡하고 장기적인 작업을 수행하도록 시도
- 본 논문은 기존 연구들처럼 언어 임베딩을 사용하여 로봇의 행동을 개선하는 것을 넘어, 언어 모델을 로봇의 affordance 내에서 grounding함으로써, 로봇이 언어 모델을 사용하여 계획을 세울 수 있도록 하는 것을 목표로 함
Task Planning and Motion Planning (TAMP).
- 과거에는 Planning 문제를 해결하기 위해 사람이 직접 규칙이나 제약 조건을 정의하는 방식이 많이 사용되었음 (symbolic planning, optimization 등) → 명시적인 원시 행동이나 제약조건 필요
- 최근에는 기계 학습을 이용하여 로봇이 스스로 추상적인 작업을 이해하고, 일반적인 규칙을 학습하며, 다양한 제약 조건을 고려하여 Planning을 수행하는 연구가 진행되고 있음
- Hierarchical Reinforcement Learning을 통한 연구도 진행되고 있음
8. Conclusions, Limitations and Future Work
- Conclusions 본 논문은 대형 언어 모델(LLM)의 풍부한 task-grounding과 로봇의 실제 affordance, world-grounding을 연결하는 프레임워크인 SayCan을 제안
SayCan은 실제 로봇 환경(주방 환경)에서 다양한 자연어 명령(총 101가지)을 수행하는 데 성공하였으며, 언어 모델만 단독으로 사용했을 때보다 약 2배 높은 성공률 달성 또한, 언어 모델이 강력할수록 로봇의 수행 능력도 함께 증가한다는 점을 발견하였음
- Limitations LLM의 한계 및 편향을 그대로 상속함 (학습 데이터에 대한 의존성 등..) 로봇이 수행 가능한 기본 행동(primitive skill)의 수와 종류가 제한되어 있어, 해결 가능한 작업의 범위가 제한적. 보다 복잡한 작업이나 사전 정의되지 않은 행동을 수행하기 어려움. 복잡하고 긴 명령을 수행할 때 단계별로 작은 오류가 쌓여 최종 작업의 성공률이 떨어질 수 있음. 단계가 많아질수록 행동 실패의 가능성이 증가 로봇은 환경의 완전한 정보를 가지지 않고 부분적으로만 관찰 가능한 상황에서 작업을 수행하므로, 시각적 오류나 인지 오류로 인해 행동 결정 과정에서 실수를 할 가능성이 있음
- Future Works LLM 자체를 개선하여 상식 추론 능력을 향상시키는 방법 모색 작업 컨텍스트, 환경 정보 등 다양한 grounding source를 통합하여 로봇이 더욱 똑똑하게 작업 수행 작업 특성에 따라 자연어 외 적절한 ontology의 탐색, 다양한 방법으로 언어와의 상호 작용 결합 방안 고려 (robot planning과 language 결합 등)
