
최근 Qwen 2.5-VL가 릴리즈되었다고 해서 써보는 Qwen 2.5 테크니컬 리포트 리뷰 🫠
🤗에 모델 공개만 하고 paper는 아직 공개가 안 됐길래 대신 Qwen2.5를 읽어보았다.

- paper 링크 : Qwen2.5 Technical Report
- 허깅페이스 링크 : Qwen2.5 language models
- 깃허브 링크 : QwenLM/Qwen2.5
Qwen 시리즈랑 다른 LLM도 시간날때마다 포스팅 해봐야겠다.
Qwen2.5 1분 요약
Overview
Qwen2.5는 이전 버전 Qwen 모델보다 pre-training, post-training 양쪽 측면에서 크게 개선되었다.
- pre-training data 증가를 통한 추론 능력 향상: 7T → 18T tokens
- 100만 개 이상의 샘플을 활용한 정밀한 SFT 및 multistage RL(DPO, GRPO) 적용하여 post-training 개선 : human preference, 긴 텍스트 생성과 구조적 데이터 분석능력, instruction following 향상
- 0.5B~72B 파라미터 규모의 open weight model(quantization, instruction-tuned model 포함) 및 cost-effective MoE models (Qwen2.5-Turbo, Qwen2.5-Plus) 제공
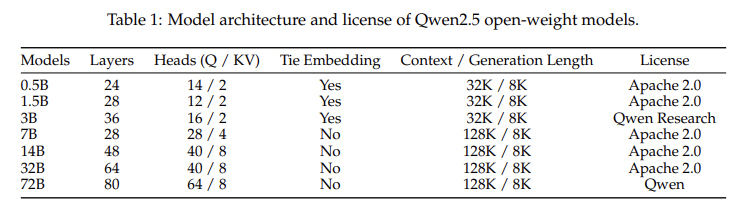
Architecture & Tokenizer
Qwen2(Yang et al., 2024a)와 동일하게 Transformer-based decoder 구조를 유지한다.
Qwen2.5의 핵심 요소는 다음과 같다:
- 효율적인 메모리 사용(KV cache utilization)을 위한
Grouped Query Attention (GQA, Ainslie et al., 2023) - non-linear activation을 위한
SwiGLU activation(Dauphin et al., 2017)사용 - encoding position information을 위한
Rotary Positional Embeddings (RoPE, Suet al., 2024) - attention mechanism의 QKV bias 및 안정적 훈련 보장을 위한
RMSNormwith pre-normalization - MoE variant 확장 (FFN을 MoE layer로 대체하고 라우팅 메커니즘 구성)
Tokenizer의 경우 기본적으로 Qwen2의 토크나이저를 활용하되, 이전 Qwen 버전에 비해 control token을 3개에서 22개로 확장
Training Techniques
-
Pre-training:
고품질 데이터에 집중 (better data filtering, better math and code data, better synthetic data, better data mixture) : 다국어 데이터 품질 향상, 데이터셋 2.5배 확장(7T -> 18T)
Scaling Law 적용 : model size N과 pre-training data size D에 따른 최적의 하이퍼 파라미터 도출
점진적 Context 확장 : RoPE 주파수 조정(ABF technique) 및 YARN,DCA 기법 사용으로 긴 컨텍스트 처리 능력 강화 및 다양한 입력 길이에 대한 일관된 품질 보장
-
Post-training:
Supervised Fine-Tuning (SFT): SFT data coverage 확장 (긴 시퀀스 생성, 수학적 문제 해결, 코딩, 명령어 추종, 구조화된 데이터 이해 능력 향상)Reinforcement Learning (RL): Two-stage RL process, "Offline RL" (추론, 지침 준수, 사실성 등 reward model이 평가하기 어려운 능력 강화) and "Online RL" (진실성, 무해성, 가독성 등 출력 품질 향상)
Evaluation & Performance
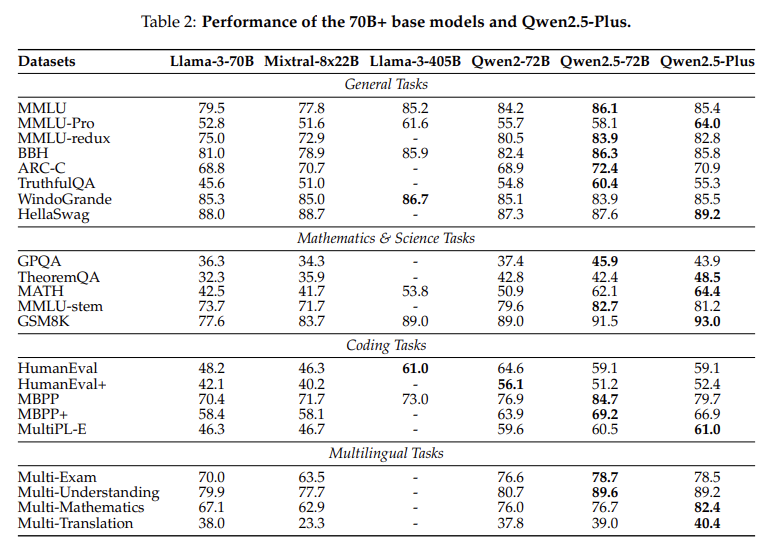
Qwen2.5-72B-Instruct는 Llama-3-405B(5배 크기)와 같은 모델보다 성능이 뛰어남
Qwen2.5-Turbo 및 Plus(MoE model)는 GPT-4o-mini 및 GPT-4o에 비해 강력한 성능 달성
1. Introduction
최근 대규모 언어 모델(LLM)의 발전은 AGI의 실현 가능성을 높이며, 모델의 언어 이해, 생성, 추론 능력을 비약적으로 향상시키고 있다. OpenAI의 "o1" 모델과 같은 최신 기술들은 단계별 추론(step-by-step reasoning)과 reflection을 통해 더 깊은 사고 능력을 구현하고 있으며, 이러한 발전은 AI가 더욱 정교한 작업을 수행할 수 있도록 돕고 있다.
최근 2년 동안 Llama(Touvron et al., 2023a;b; Dubey et al., 2024), Mistral (Jiang et al., 2023a; 2024a), Qwen(Bai et al., 2023; Yang et al., 2024a; Qwen Team, 2024a; Hui et al., 2024; Qwen Team, 2024c; Yang et al., 2024b) 등의 open-weight LLM이 등장하면서 AI 연구와 개발의 접근성이 더욱 확대되었다. 이러한 오픈소스 모델들은 연구자와 개발자들이 자유롭게 활용할 수 있도록 지원하여 AI 혁신을 가속화하고 있다.
Qwen2.5는 이러한 흐름 속에서 등장한 최신 LLM으로, 대규모 사전 학습과 정교한 사후 학습을 통해 성능이 크게 향상된 모델이다. Qwen2.5는 0.5B~72B의 오픈소스 모델을 제공하며, 모든 모델을 bfloat16과 다양한 양자화 모델이 제공된다. 또한 Qwen2.5-Turbo 및 Qwen2.5-Plus와 같은 MoE(Mixture-of-Experts) 모델도 함께 제공하여 비용 효율적인 성능을 지원한다(Qwen2.5-Turbo는 GPT-4o-mini와, Qwen2.5-Plus는 GPT-4o와 유사한 성능을 제공하면서 더 비용 효율적). 특히, Qwen2.5-72B-Instruct는 Llama-3-405B-Instruct와 경쟁할 수 있는 성능을 보이며, 비용 대비 성능이 뛰어난 것이 강점이다.
Qwen2.5는 기존 모델 대비 더 다양한 크기의 모델을 제공하고, 데이터 품질과 양을 대폭 향상했으며, 긴 컨텍스트(최대 1M 토큰) 지원, 구조적 데이터 처리 강화(JSON, 테이블 등 구조화된 데이터), 도구 활용 능력 개선 등의 특징을 갖추고 있다.
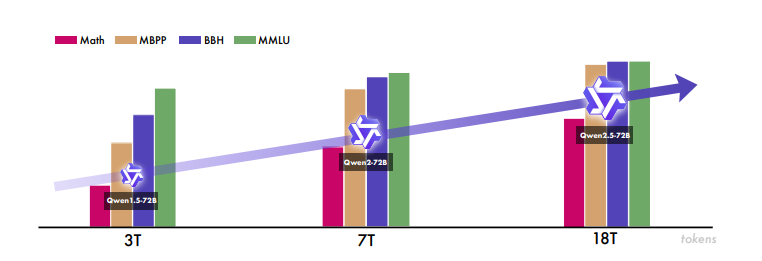
위 Figure는 Qwen 시리즈의 개발 과정에서 data scaling이 중요함을 보여준다. Qwen 2.5는 pretraining에 18T tokens를 활용하며 Qwen 시리즈 중 domain expertise 측면(Math, MBPP, BBH, MMLU)에서 가장 뛰어나며, model capability 향상에 scaling의 중요성을 강조한다.
2. Architecture & Tokenizer
Architectures
Qwen2.5 시리즈에는 오픈소스용 dense model인 Qwen2.5-0.5B / 1.5B / 3B / 7B / 14B / 32B / 72B와 API 서비스용 MoE 모델, Qwen2.5-Turbo 및 Qwen2.5-Plus가 포함되어 있다.
dense model에서는 기본적으로 Qwen2 (Yang et al., 2024a)와 같이 transformer 기반의 디코더 구조를 유지하며, 다음과 같은 key compoents를 통합한다:
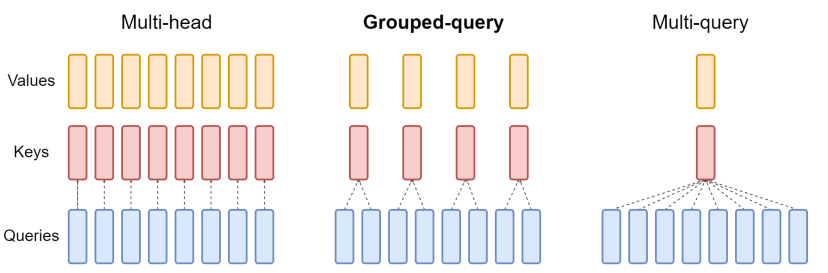
Grouped Query Attention(GQA, Ainslie et al., 2023) for efficient KV cache utilization
: GQA는 기존의 multi-head attention과 multi-query attention의 절충이라고 할 수 있다.
GQA는 query를 여러 그룹으로 나누고, 각 그룹이 하나의 key와 value를 공유하는 방식이다. 모델 품질 측면에서 Multi-head attention(MHA)에 근접한 품질을 유지하면서, Multi-query attention(MQA)보다 우수한 성능을 보인다.
효율성 측면에서 보면 MQA보다는 많지만 MHA보다 메모리 사용량이 적으며, 추론 속도의 경우에도 MQA에 근접한 빠른 추론 속도를 보이며 MHA에 비해 빠른 추론 속도를 제공한다.
| Multi-Head Attention (MHA) | Multi-Query Attention (MQA) | Grouped Query Attention (GQA) | |
|---|---|---|---|
| structure | 각 헤드는 고유한 Q, K, V를 가짐 | 각 헤드는 고유한 Q와 shared K, V를 가짐 | 각 그룹화된 Q와 shared K,V를 가짐 |
| memory usage | 높음 | 낮음 | 중간 |
| inference speed | 느림 | 빠름 | MQA에 근접하게 빠름 |
| model quality | 높음 | 낮음 | MHA에 근접 |
| training stability | 안정적 | 불안정 (QKV 구조적 제약) | 비교적 안정 |
| KV cache size | 큼 | 작음 | 중간 |
| computational complexity | 높음 | 낮음 | 중간 |
SwiGLUactivation function (Dauphin et al., 2017) for non-linear activation: Swish + GLU 조합으로 비선형성을 강화한다.
Rotary Positional Embeddings(RoPE, Suet al., 2024) for encoding position information
: RoPE(Rotary Position Embedding)는 위와 같이 임베딩 벡터를 회전 변환하여 위치 정보를 인코딩한다. 위 그림에 따르면, 차원 공간에서 Query, Key 벡터 ()를 θ₁ 만큼 회전시켜 새로운 벡터 ()로 변환한다. 이 때, 회전각 θ₁는 위치 정보 에 비례한다. (mθ₁)
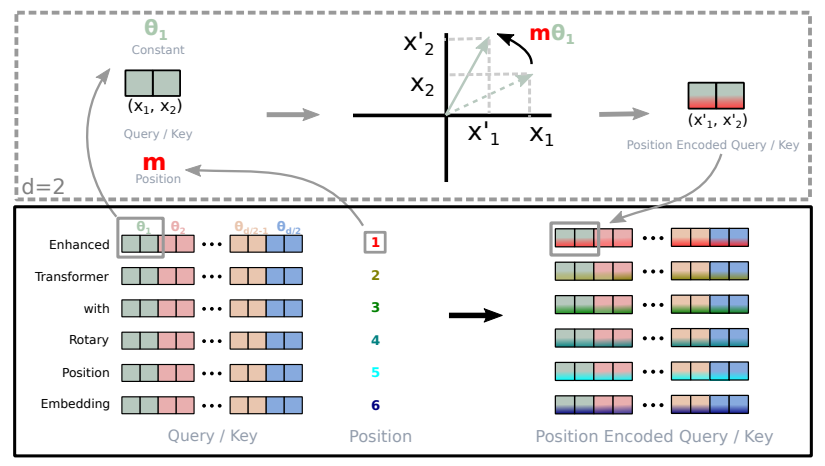
QKV bias(Su, 2023) in the attention mechanism
: Su (2023)는 RoPE에서 Q,K를 회전하여 위치 정보를 주입하기 때문에, Q,K 에 bias를 추가하면 회전 특성이 왜곡될 수 있다는 것을 발견했다. 따라서, RoPE 사용 모델에서는 Q,K bias를 제거하는 것이 더 나은 성능을 보이며 학습 안정성과 긴 컨텍스트 처리 능력 또한 개선된다.
RMSNorm(Jiang et al., 2023b) with pre-normalization to ensure stable training
: 분산과 평균 대신 root mean square(RMS)로만 계산하므로 LayerNorm보다 연산량이 적고, 학습 초기에 안정적인 수렴을 보여 LLM과 같은 대규모 모델과 긴 시퀀스 처리 시 효과적이다.
MoE Architectures
standard FFN layer를 specialized MoE layer로 대체하여, dense model을 MoE model architecture로 확장한다. 각 레이어는 multiple FNN experts와 top-k experts에 토큰을 전송하는 routing mechanism으로 구성된다.
Qwen1.5-MoE (Yang et al., 2024a)의 접근방식에 따라 fine-grained expert segmentation (Dai et al., 2024)과 shared experts routing (Rajbhandari et al., 2022; Dai et al., 2024)을 구현한다.
Tokenizer
byte-level byte-pair encoding (BBPE, Brown et al., 2020; Wang et al., 2020; Sennrich et al., 2016)을 활용한 Qwen 2의 tokenizer 를 사용한다. 해당 토크나이저는 151,643개의 regular token vocab으로 구성되어 있다.
다만 이전 Qwen 버전에서 control token set을 3개에서 22개로 확장하였고, tool functionality를 위해 새로 토큰 2개를 추가했다 (나머지는 다른 model capability에 할당). 이러한 확장이 Qwen2.5 모델의 vocab을 통합시켜 주고, 일관성을 높이며 잠재적인 호환성 이슈를 줄였다.
3. Pre-training
Qwen2.5의 pre-training process 핵심 요소는 다음과 같다:
- 정교한 필터링 및 scoring mechanism, 전략적인 데이터 혼합을 통한 고품질의 학습 데이터 선별
- 다양한 규모 모델을 효과적으로 학습시키기 위하여, hyperparameter optimization에 대한 연구 수행
- 모델의 확장 시퀀스 처리 및 이해 능력 향상을 위한 specialized long-context pretraining 통합
Pre-training Data
Qwen2와 비교하여, Qwen 2.5의 사전 학습 데이터 품질이 크게 향상되었다. 향상 측면은 다음과 같다:
Better data filtering
Qwen2-Instruct 모델을 data quality filter로 활용하여, 종합적인 다차원 분석을 통해 training sample을 평가 및 scoring한다.
이와 같은 필터링 방법은 Qwen2의 대규모 다국어 코퍼스 사전학습을 활용하므로, 고품질 데이터에 대한 더욱 섬세한 평가가 가능해진다. 따라서 고품질 training data의 유지율을 향상시키고, 여러 언어에 걸쳐 low-quality sample을 더 효과적으로 필터링할 수 있다.
Better math and code data
Qwen2.5의 pretraining 단계에서는 Qwen2.5-Math(Yang et al., 2024b)와 Qwen2.5-Coder(Hui et al., 2024)의 훈련 데이터를 통합한다. 이러한 데이터 통합 전략은 수학 및 코딩 태스크에서 SOTA의 성능을 거두는 핵심이 된다. 따라서, 사전학습 단계의 이러한 domain-specific dataset 활용은Qwen2.5가 뛰어난 수학 추론, 코드 생성을 갖추도록 한다.
Better synthetic data
Qwen2-72B-Instruct(Yang et al., 2024a) 및 Qwen2- Math-72B-Instruct(Qwen Team, 2024c)를 활용하여 수학, 코드, 지식 영역에서 고품질 합성 데이터를 생성한다. 독자적인 general reward model과 Qwen2-Math-RM-72B (Qwen Team, 2024c)를 사용한 엄격한 필터링을 통해 이러한 합성 데이터 품질을 향상시킨다.
Better data mixture
Qwen2-Instruct 모델을 사용하여 여러 도메인 콘텐츠를 분류하고 사전학습 데이터 분포 균형을 맞춘다. 본 논문의 분석에 따르면, 이커머스, 소셜미디어, 엔터테인먼트와 같은 도메인은 web-scale data에서 상당히 과대분포 되어있는 반면, 기술, 과학, 학술 연구와 같은 고품질의 정보를 포함한 도메인은 일반적으로 과소분포 되어있다. 따라서 과대 분포 도메인을 down-sampling하면서 고밸류의 도메인을 up-sampling하는 전략적인 선택을 통해, 더 균형있고 풍부한 정보를 포함하는 학습 데이터를 확보하여, Qwen 모델의 learning objectives에 부합하도록 한다.
Scaling Law for Hyper-parameters
Qwen2.5는 기존 연구(예: Kaplan et al., 2020; Hoffmann et al., 2022)를 기반으로 hyperparameter에 대한 scaling-laws를 연구한다. 이전 연구(Dubey et al., 2024; Almazrouei et al., 2023; Hoffmann et al., 2022)에서는 주로 한정된 컴퓨팅 예산에서 최적의 모델 크기를 결정하기 위해 scaling-laws를 사용했지만, 본 논문에서 모델 아키텍처 전반에 걸쳐 optimal hyperparameter 식별을 위해 scaling law를 활용한다. 특히, scaling law는 다양한 크기의 dense model과 MoE model에 대해 batch size 및 learning rate 와 같은 주요 학습 파라미터 결정에 도움이 된다.
본 연구에서는 실험을 통해, 최적의 학습 속도 와 배치 크기 가 모델 크기 과 사전 학습 데이터 크기 에 따라 어떻게 달라지는지 분석하고, 최적 하이퍼파라미터 예측을 통해 모델 아키텍처와 학습 데이터 규모에 따라 최종 손실을 모델링한다.
또한 scaling law를 활용하여 MoE models의 성능을 예측하고 크기별 dense model과 비교한다. 이 분석을 통해 MoE models의 hyperparameter configuration을 조정하여 특정 크기의 dense model(Qwen2.5-72B, Qwen2.5-14B)과 동등한 성능을 달성할 수 있도록 한다.
Long-context Pre-training
Qwen2.5에서는 최적의 학습 효율을 위하여, two-phase pre-training approach를 사용한다.
- a two-phase pre-training approach : initial phase에서 4,096 context length를 사용하고, extension phase에서 더 긴 시퀀스를 사용
Qwen2의 전략을 따라, 모든 Qwen2.5(Qwen2.5-Turbo 제외) variant model에서 최종 사전학습 단계의 context length를 4,096에서 32,768 token으로 확장시킨다. 동시에, ABF(Adjusted Base Frequency) 기법(Xiong et al., 2023)을 사용하여 RoPE의 base frequency를 10,000→1,000,000으로 증가시킨다.
Qwen2.5-Turbo에서는 4단계의 점진적 contect length 확장 전략을 사용한다. (32,768 → 65,536 → 131,072 → 262,144 tokens으로 확장)
- ABF (Adjusted Base Frequency) : RoPE의 base frequency를 조정하여 context window를 확장하는 기법. Xiong et al. (2023)은 ABF를 통해 기본 주파수를 증가시키면, RoPE 임베딩 벡터들의 회전각을 감소시켜 장거리 의존성(긴 시퀀스에서도 위치 정보를 효과적으로 인코딩)과 정보 보존(멀리 있는 토큰들의 정보를 더 잘 보존, 급격한 회전으로 인한 정보 손실 감소, 토큰 간 상대적 거리 관계를 더 잘 유지) 측면에서 효과적임을 검증했다.
더 긴 시퀀스에 대한 추론 능력 향상을 위해, 다음 두 가지 전략을 사용한다: YARN(Peng et al., 2023)과 Dual Chunk Attention (DCA, An et al, 2024)
- YaRN (Yet another RoPE extensioN method) : NTK-By-Parts scaling과 temperature 조절을 결합하여 RoPE 사용 모델의 컨텍스트 윈도우를 효율적으로 확장하는 방법. 1) NTK-By-Parts scaling은 각 차원의 RoPE 컴포넌트를 다르게 처리하는 방식으로, wavelength에 따라 다른 스케일링 전략을 사용한다 ****2) attention의 softmax 함수 이전 logit에 temperature 매개변수 를 도입하여, 모델의 언어 모델링 성능을 향상시킨다.
- DCA (Dual Chunk Attention) : 긴 시퀀스를 작은 단위로 나누어 처리하는 chunk 기반 attention mechanism으로 3가지 attention으로 구성되어 있다.
- Intra-Chunk Attention : 동일한 청크 내 토큰들의 관계를 학습 (기존 transformer의 self-attention 메커니즘과 유사하나 chunk 단위로 국한됨)하고 local 정보를 효과적으로 유지
- Inter-Chunk Attention : 서로 다른 청크 간 토큰들의 관계를 학습하고 gobal context 인식
- Successive-Chunk Attention : 인접 청크 간 연결성을 강화하여 locality를 보존
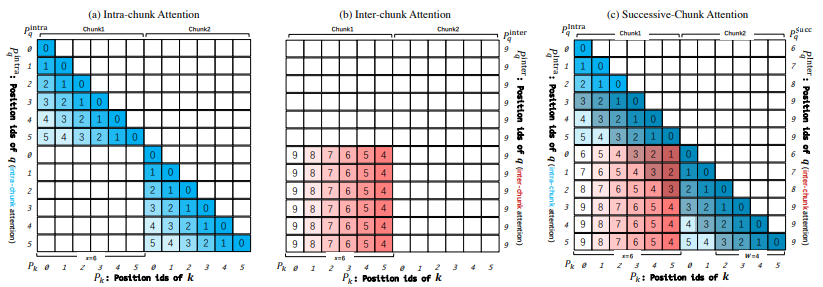
위와 같은 접근 방식을 통해, Qwen2.5-Turbo는 최대 100만 개의 토큰을, 그 외 모델은 최대 131,072개의 토큰을 처리할 수 있으며, 긴 시퀀스의 모델링을 개선함과 동시에 짧은 시퀀스에서도 강력한 모델 성능을 유지하여 다양한 입력 길이에 걸쳐 일관된 품질을 보장한다.
4. Post-training
Qwen2와 비교하여 볼 때, Qwen 2.5에서는 post-training design 면에서 2가지 중요한 개선 사항을 도입했다.
-
Expanded Supervised Fine-tuning Data Coverage:
SFT process는 고품질의 massive dataset을 활용한다. 이러한 데이터 확장을 통해, long-sequence generation, mathematical problem-solving, coding, instruction-following, structured data understanding, logical reasoning, cross-lingual transfer, robust system instruction와 같이 이전 모델에서 한계를 보였던 문제 영역들을 해결한다. -
Two-stage Reinforcement Learning: Qwen 2.5의
RL process는 다음 두 단계로 나뉜다. (1) Offline RL, (2) Online RL(1)
Offline RL: reasoning, factuality, instruction-following과 같이 reward model이 평가하기 어려운 기능 개발에 중점(2)
Online RL: reward model을 활용하여 truthfulness, helpfulness, conciseness, relevance, harmlessness, debiasing과 같은 출력 품질 감지에 중점
Supervised Fine-tuning
Qwen2.5는 100만 개 이상의 고품질 예제를 활용하여 지도 학습(SFT)을 수행한다.
1) Long-sequence Generation
- 기존 모델들은 2K token 이내의 짧은 답변을 생성하는 데 최적화 → Qwen2.5는 최대 8K token까지 더 긴 응답 생성 가능
- 모델의 응답 길이 격차 해소를 위한 long-response datasets (Quan et al., 2024) 구축
- back-translation 기법을 사용하여 학습 데이터 증가
- pretraining corpora로부터 긴 텍스트 데이터에 대한 쿼리를 생성하고, 출력 길이 제한을 적용하여 긴 문장 학습 강화
- Qwen2 모델을 사용하여 저품질 데이터 필터링
2) Mathematics
- 다양한 query sources를 포괄하는 Qwen2.5-Math의 CoT dataset을 활용하여 수학적 추론 능력 강화
- 고품질 추론 보장을 위한 reward modeling과 rejection sampling 기법 (Yuan et al., 2023)을 사용하여 단계별 추론 프로세스 생성
3) Coding
- Qwen2.5-Coder (Hui et al., 2024)의 instruction tuning data를 활용하여 코딩 역량 강화
- multiple language-specific agents를 협업 프레임워크에 통합하여 다양한 high-quality instruction-pair를 생성
- 코드 관련 Q&A 웹사이트와 GitHub에서 새로운 예제를 수집하여 instruction 데이터셋 확장
- multilingual sandbox를 활용하여 정적 코드 검사, 자동화된 유닛테스트로 code snippet 검증하여 코드 품질 및 정확성 보장
4) Instruction-following
- 고품질 instruction-following 데이터를 보장하기 위해 엄격한 코드 기반 검증 프레임워크 적용
- LLM이 직접 instruction과 검증용 코드를 생성하고, 교차 검증을 위한 포괄적인 유닛 테스트 작성
- feedback-based rejection sampling통해 학습 데이터를 정제하여 SFT 과정에서 모델이 정확하게 의도된 지침을 따르도록 보장 (Dong et al., 2024)
5) Structured Data Understanding
- comprehensive structured understanding dataset 개발: 전통적인 작업과 복잡한 구조적/반구조적 데이터 태스크 모두 포함 (tabular QA, fact verification, error correction, structural understanding)
- 모델의 응답에 reasoning chains을 통합하여 데이터셋의 범위 확장 및 복잡한 데이터 구조로부터 인사이트 도출 능력 향상
6) Logical Reasoning
- logical reasoning 능력 향상을 위해 다양한 문제 유형(객관식, 참/거짓, 서술형 질문 등) 학습
- 연역적,귀납적,유추,인과,통계적 추론과 같은 다양한 추론기법을 사용하여 문제에 체계적으로 접근하도록 함
- 반복적인 데이터 필터링 과정을 통해 오답이나 결함을 필터링하여 추론 능력 점진적 강화
7) Cross-Lingual Transfer
- translation model을 활용하여 high-resource language instruction을 low-resource language로 변환하여 응답 후보(response candidates) 데이터를 생성하고, 원본 데이터와 번역된 데이터 간 의미적 정합성 검증
- 원본 응답의 논리적 구조와 문체적 뉘앙스를 보존하며 다국어에 대한 무결성과 일관성 유지
8) Robust System Instruction
- 다양한 시스템 프롬프트를 적용하여 대화 간 응답 일관성 보장 및 모델 견고성 향상
9) Response Filtering
- 응답 품질 평가를 위해, dedicated critic model 및 multi-agent collaborative scoring system 사용 → 엄격한 모든 평가 기준을 거쳐 결함이 없는 응답만 활용하여 데이터 품질 유지
위 과정을 통해 결과적으로, 1M 이상의 SFT 예제 데이터셋을 구축했으며, Qwen2.5 model은 sequence length 32,768 tokens로 2 epochs동안 finetuning된다. 학습 최적화를 위해, learning rate를 점진적으로 감소시킨다 (). overfitting 문제 해결을 위해서는, weight decay를 0.1만큼 적용하고, gradient norms을 최대 1.0에서 clipping한다.
Offline Reinforcement Learning
Online RL과 비교할 때, Offline RL은 training signal을 미리 준비할 수 있으므로 standard answer가 있지만 reward model을 사용하여 평가하기 어려운 과제에 특히 적합하다.
전 단계(SFT)에서 응답 품질 보장을 위한 execution feedback, answer matching과 같은 전략을 다양하게 수행했다면, 현 단계(offline RL)에서는 SFT model을 통해 새로운 query set에 대한 응답을 다시 샘플링하며, 이러한 파이프라인을 재사용한다.
앞서 응답 품질 평가를 통과한 응답들을 positive examples로 사용하고, 그렇지 못한 응답을 Direct Preference Optimization (DPO) training에 negative examples로 사용한다.
- DPO (Direct Preference Optimization) : 기존 강화학습 기반 방법론(RLHF)의 복잡성을 해소하기 위해 개발된 언어 모델 최적화 기법으로, 별도의 reward model 없이 언어 모델 자체를 선호도 데이터에 직접 최적화하여 효율성과 안정성 확보
training signal의 신뢰도와 정확도를 높이기 위해, human/auto review process를 모두 활용하여, 약 15만개의 training pair로 구성된 데이터셋을 구축한다. 이러한 데이터셋은 Online Merging Optimizer (Lu et al., 2024a)를 사용하여 learning rate 에서 1 epoch 동안 학습된다.
Online Reinforcement Learning
online RL을 위한 robust reward model 개발을 위해, 정의된 일련의 라벨링 규칙을 준수한다. 데이터 라벨링에 대한 가이드라인은 다음과 같다 : Truthfulness, Helpfulness, Conciseness, Relevance, Harmlessness, Debiasing
reward model 학습 쿼리는 오픈 소스 데이터와 독점적인 query set을 혼용하여 사용한다. 다양한 학습 단계에서 SFT, DPO, RL을 사용하여 finetuning된 Qwen 모델의 체크포인트에서 응답을 생성하고, 이러한 응답의 다양성을 위해 다양한 temperature 설정에서 샘플링한다. preference pair는 수동/자동 라벨링 프로세스로 생성하고 DPO 학습 데이터도 이 데이터셋에 포함시킨다.
online RL에서는 Group Relative Policy Optimization (GRPO, Shao et al., 2024)를 사용하고, 이러한 reward model 훈련에는 RL 훈련과 동일한 query set을 사용한다. 훈련시 쿼리의 처리 순서는 reward model이 평가한 response score의 분산에 따라 결정되는데, 특히 response score의 분산이 클수록 우선적으로 처리되어 더 효과적인 학습을 보장한다 (각 query에 대해 8개의 응답을 샘플링). 모든 모델은 한 쌍의 query, reponse를 샘플로 간주하고 각각 2,048개의 샘플, global batch size 2,048로 훈련된다.
- GRPO (Group Relative Policy Optimization) : LLM의 alignment 개선을 위한 강화학습 방법으로, PPO (Proximal Policy Optimization)의 복잡성을 해결하고 그룹 기반 샘플링을 통해 상대평가를 도입(개별 응답의 보상을 그룹 평균과 표준편차로 정규화하고, 그룹 내 상대적 순위 반영)
Long Context Fine-tuning
Qwen2.5-Turbo의 컨텍스트 길이 확장을 위해 post-training에서 더 긴 SFT example을 도입하고, 긴 쿼리에서도 human preference에 잘 맞추도록 한다.
- SFT phase에서는 two-stage approach를 사용한다: 1) short instructions(~32,768 tokens)만 사용하여 model finetuning 수행(다른 Qwen2.5 모델과 동일한 데이터셋 및 훈련 단계를 거침) 2) short instruction(~32,768 tokens)과 long instruction(~262,144 tokens)을 모두 결합하여 finetuning → short task 성능 유지 및 long context의 instruction-following 성능을 효과적으로 향상
- RL phase에서는 다른 Qwen2.5모델과 유사하게, short instructions에만 집중하며, 이러한 설계는 다음 두 가지 고려사항에 따른 것이다:
- 강화학습 훈련은 계산 비용이 많이 소모됨
- 현재 long context task에 대한 적합한 reward signal을 제공하는 reward model이 부족함
더불어, short instruction에만 강화학습을 도입해도 long context 작업에서 human preference와의 alignment를 크게 향상시킬 수 있음을 발견했다.
5. Evaluation
Qwen2.5 모델의 성능을 평가하기 위한 base model 및 instruction-tuned model에 대한 벤치마크 테스트 (표 내용이 많아서 주요 성능 평가 내용만 간단하게 정리)
- Base model eval General Tasks : MMLU, MMLU-Pro, BBH 등에서 우수한 성능 달성 Mathematics & Science Tasks : GPQA, MATH, GSM8K 등에서 강점 Coding Tasks : HumanEval, MBPP, MultiPL-E 등에서 높은 스코어 달성 Multilingual Tasks : 다국어 이해, 수학, 번역 태스크에서 경쟁력 있는 결과
→ Qwen2.5-72B 모델은 5배 더 큰 Llama-3.1-405B와 비슷한 성능을 보이며, 비용 대비 효율성이 우수함을 입증한다.
→ Qwen2.5-plus(MoE)는 다수의 벤치마크에서 Qwen2.5-72B을 능가한다.
- Instruction-tuned model eval 1) Open Benchmark Evaluation:
-
MMLU-Pro : Qwen2.5-72B-Instruct는 71.1을 기록하여 Llama-3.1-70B-Instruct(66.4)를 크게 앞섬
-
LiveBench : Qwen2.5-72B-Instruct는 52.3으로, GPT-4o-mini(43.3)와 Llama-3.1-70B-Instruct(46.6)를 상회
-
MATH : Qwen2.5-72B-Instruct는 83.1으로 Llama-3.1-405B-Instruct(73.8)를 크게 앞서는 우수한 성능 달성
-
HumanEval : Qwen2.5-72B-Instruct는 86.6으로 Llama-3.1-70B-Instruct(80.5)를 능가
2) In-house Automatic Evaluation:
-
English eval : Qwen2.5-72B-Instruct는 IF(82.65), Knowledge(66.09), Comprehension(74.43), Coding(60.41), Math(59.73), Reasoning(65.90) 분야에서 고르게 우수한 성능을 거둠
-
Chinese eval : Knowledge(75.86), Comprehension(78.85) 분야에서 뛰어난 성과를 보였으며, Coding(56.71%), Math(68.39%), Reasoning(63.02%) 능력도 우수
-
Multilingual eval : (IFEval) Qwen2.5-72B-Instruct는 86.98점으로 GPT4o-mini(85.03)를 앞섬 (MMLU) 아랍어(72.44), 일본어(80.56), 한국어(61.96) 등 다양한 언어에서 우수한 성능 (MGSM8K) 88.16점으로 Mistral-Large(89.01)에 근접한 성능
3) Long Context Capabilities
-
RULER: Qwen2.5-72B-Instruct는 128K에서 평균 95.1을 기록하여, GPT-4(91.6) 능가
-
LV-Eval: 128K에서 50.9을 기록하여, GPT-4o-mini(40.7)를 크게 능가
-
Longbench-Chat: 8.72으로 GPT-4o-mini(8.48)보다 약간 우수
-
→ Qwen2.5-72B-Instruct는 많은 벤치마크에서 Llama-3.1-405B-Instruct를 능가한다.
→ Qwen2.5-Plus는 13개 중 9개 벤치마크에서 Qwen2.5-72B-Instruct보다 우수한 성능을 거둔다.
→ Qwen2.5는 다양한 태스크에서 최고수준의 성능을 보이며, 특히 Qwen2.5-72B-Instruct는 Long Context 처리에서 기존 openweight 모델과 GPT-4를 크게 앞선다.
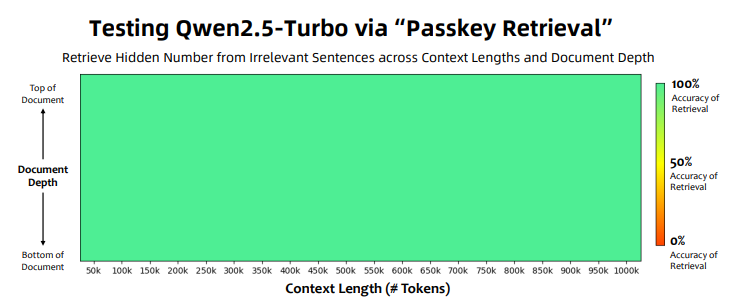
위 Figure는 Passkey Retrieval Task에서 Qwen2.5-Turbo(1M Token Length)의 성능을 보여준다. 모든 컨텍스트 길이(~1M)와 패스키의 위치(Bottom~Top)에 관계 없이 100%의 정확도를 달성했음을 보이며, 장문 처리 안정성을 입증한다.
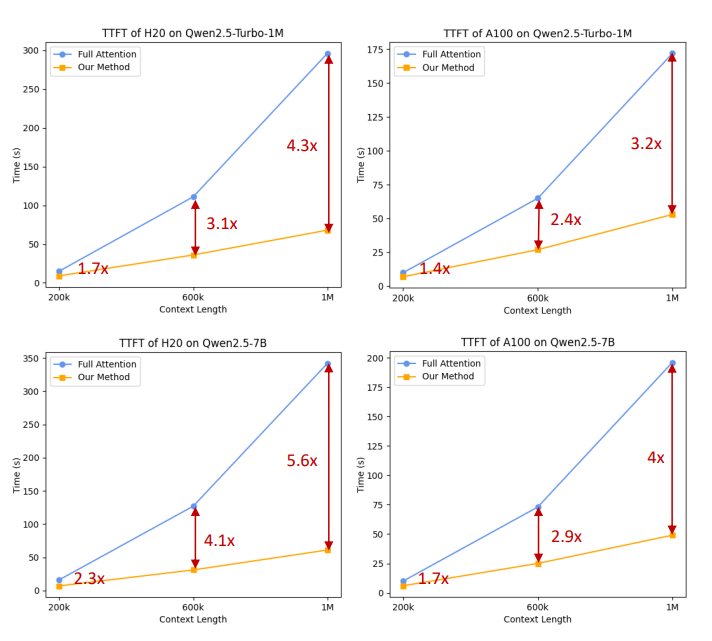
위 Figure는 Qwen2.5-Turbo의 Time to First Token(TTFT)를 보여주며, 본 논문에서 Minference(Jiang et al., 2024b)에 기반하여 개발한 sparse attention mechanism이 long context 처리에서 연산 부하를 크게 감소시키고 어텐션 연산 속도를 크게 향상시킴을 보여준다. (3.2~4.3배 속도 향상)
6. Conclusion
Qwen2.5는 18조 개의 토큰을 활용한 사전 학습, 지도 미세 조정(SFT), 다단계 강화 학습(multi-stage RL)을 포함한 정교한 post-training 기법을 통해 LLM의 성능을 크게 향상시켰다.
이러한 개선으로 human preference alignment, long text generation, structural data analysis에서 뛰어난 성능을 발휘하며, instruction-following tasks에서도 효과적이다.
Qwen2.5는 다양한 파라미터 크기(0.5B~72B)로 제공되며, 오픈소스 모델뿐만 아니라 비용 효율적인 MoE 모델(Qwen2.5-Turbo, Qwen2.5-Plus)도 포함한다. 경험적 평가에 따르면, Qwen2.5-72B-Instruct는 Llama-3-405B와 유사한 성능을 발휘하면서도 모델 크기는 6배 작아 더 효율적이다.
또한, Qwen2.5는 특수 모델의 기반이 되어 도메인별 애플리케이션 구축에도 적합한 다용성을 갖춘다.
