
최근에 객체 인식이나 세그먼테이션도 zero-shot 기반으로 수행하는 모델들이 핫한데, YOLO-series에서 새로운 open-set object detection 모델 YOLO-E가 공개되어서 한번 체험 차 포스팅 해본다.
기존에 YOLO-world 모델도 써봤지만 closed-set에 비해 성능이 크게 떨어진다고 느꼈는데, 이번에 YOLO-E는 어떨까 살짝 기대를 해보면서..
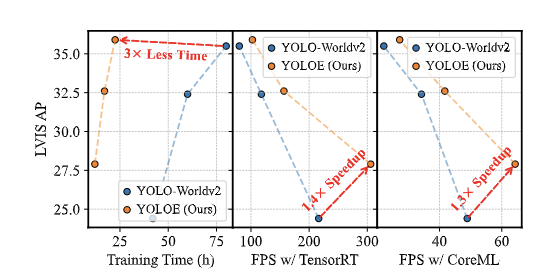
일단 YOLO-E 논문에서는 YOLO-Worldv2보다 3배 더 적은 학습 시간으로 더 높은 성능(AP)을 확보했고, 더 빠른 추론 속도를 제공한다고 한다.
YOLO-E model architecture
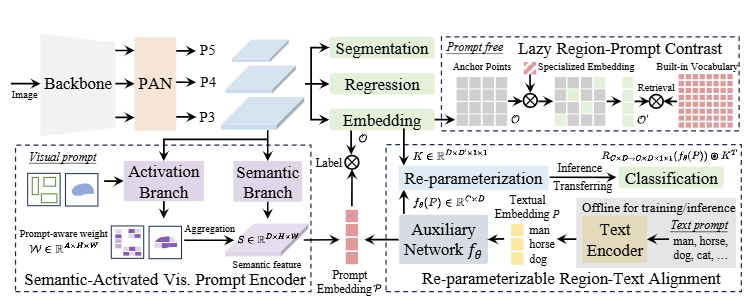
YOLO-E는 text prompt, visual prompt, prompt-free 시나리오를 모두 지원하는 객체 탐지 및 세그멘테이션 모델이다.
모델의 전반적인 구조와 작동 방식은 아래와 같다.
Overall Architecture
- Backbone
: 기존 YOLO 모델과 유사하게 CNN 기반 구조로 이미지의 계층적 특징 추출- Segmentation Head
: 기존 YOLACT 방식을 따라 prototype masks와 mask coefficients 생성- Regression Head
: 이미지 내에서 객체의 위치와 크기를 예측하고 객체의 bounding box를 결정- Object Embedding Head
: 객체의 특징을 벡터 형태로 표현 (객체 간 관계 파악, 객체 분류)
Text Prompt
Re-parameterizable Region-Text Alignment (RepRTA):훈련 도중, re-parameterizable lightweight auxiliary network를 통해 pretrained textual embedding을 개선
훈련 후, auxiliary network는 object embedding head와 함께 매칭하여 YOLO 모델 원래 구조와 동일하게 reparameterized
👉🏻 추론 시 추가적인 overhead 없이 성능 향상 가능
Visual Prompt
Semantic-Activated Visual Prompt Encoder (SAVPE):시각적 프롬프트를 효율적으로 처리하기 위해 설계된 구조로, Semantic branch에서는 프롬프트에 구애받지 않는 일반적인 특징을 추출
Activation branch에서는 시각적 프롬프트와 이미지 특징을 융합하여 프롬프트에 특화된 가중치를 생성👉🏻두 branch의 결과를 결합하여 최종 프롬프트 임베딩을 생성
Prompt-free
Lazy Region-Prompt Contrast (LRPC):프롬프트가 없는 상황에서 효율적으로 객체를 인식하는 방법
객체 탐지 문제를 검색 문제로 재구성하고, [1] 이미지 내에서 객체가 있을 가능성이 높은 영역(앵커 포인트)을 식별 [2] 식별된 영역에 대해서 large vocabulary를 통해 해당 객체의 카테고리 이름 검색
Code Implementation
YOLO-E implementation code는 공식 github를 활용하거나, ultralytics에서 YOLO-E를 임포트 해서 쓰면 된다.
Installation
# If you clone this repo, please use this
pip install -r requirements.txt
# Or you can also directly install the repo by this
pip install git+https://github.com/THU-MIG/yoloe.git#subdirectory=third_party/CLIP
pip install git+https://github.com/THU-MIG/yoloe.git#subdirectory=third_party/ml-mobileclip
pip install git+https://github.com/THU-MIG/yoloe.git#subdirectory=third_party/lvis-api
pip install git+https://github.com/THU-MIG/yoloe.git
wget https://docs-assets.developer.apple.com/ml-research/datasets/mobileclip/mobileclip_blt.pt
# predict 실행시 경로에 위 mobileclip weight가 존재해야 한다.
현재 시점 아직 완벽하게 ultralytics 호환은 안되는 듯 하지만.. 일단 뭐 모델 로드나 결과 시각화는 가능 (공식 문서 보면 아직 통합 작업중인 것 같다)
영상 까지는 테스트 못 해봤다.
from ultralytics import YOLOE
import os
import cv2
model = YOLOE("yoloe-11l-seg.pt")
image_path = "breads.jpg"
names = ["bread"]
model.set_classes(names, model.get_text_pe(names))
results = model.predict(image_path)
# Show results
results[0].show()

시험삼아 써본 결과는, 일부 바운딩 박스 인식이 안 된 부분은 쫌 아쉽긴 하지만 일단 text 기반 세그먼테이션은 정말 잘 되는 거 같다. (호오 🤔)
prompt-free를 시험해 보고 싶었는데 vram이 딸려서 못 써봤다. (pf 모델 weight가 따로 있었다)
추후에 pf 모델도 한번 써봐야겠다. 진짜 곧 SFT가 필요 없는 날이 올지도... 아니 왔으면..
라벨링 전처리 싫어잉~
