
👉🏻 Segment Anything (SAM) by Meta
Abstract
본 논문은 image segmentation을 위한 새로운 과업, 모델, 데이터셋인 Segment Anything을 소개한다. 효율적인 모델을 데이터 수집 루프에 사용하여 1,100만 개의 이미지에 대해 10억 개 이상의 마스크를 포함하는, 현재까지 가장 큰 규모의 분할 데이터셋을 구축했다. 이 모델은 프롬프트가 가능하도록(promptable) 설계 및 훈련되어 새로운 이미지 분포와 과업으로 zero-shot 전이가 가능하다. 본 논문은 수많은 과업에 대한 모델의 성능을 평가했으며, 그 zero-shot 성능이 이전의 완전 지도 학습(fully supervised) 결과와 비슷하거나 능가할 정도로 인상적이라는 것을 확인했다.
1. Introduction
웹 스케일 데이터셋으로 사전 훈련된 Large language model은 강력한 zero-shot 및 few-shot 일반화 능력으로 NLP 분야에 혁명을 일으키고 있다. 이러한 foundation model 은 훈련 과정에서 보지 못했던 과업과 데이터 분포에 대해서도 일반화가 가능하다. 이 능력은 종종 수작업으로 만든 텍스트를 이용해 language model이 특정 과업에 대한 유효한 텍스트 응답을 생성하도록 유도하는 prompt engineering을 통해 구현된다.
웹의 방대한 텍스트 코퍼스를 통해 확장 및 훈련되었을 때, 이 모델들의 zero-shot 및 few-shot 성능은 fine-tuning된 모델과 비교해도 놀라울 정도로 우수하며, 때로는 필적하기까지 한다. 경험적 추세에 따르면 이러한 현상은 모델 규모, 데이터셋 크기, 총 훈련 컴퓨팅 파워가 증가함에 따라 향상된다.
Foundation model은 컴퓨터 비전 분야에서도 탐구되어 왔지만, 상대적으로 그 범위는 제한적이었다. 아마도 가장 대표적인 사례는 웹에서 수집한 텍스트와 이미지 쌍을 정렬하는 것이다. 예를 들어, CLIP 과 ALIGN 은 대조 학습(contrastive learning)을 사용하여 두 양식을 정렬하는 텍스트 및 이미지 인코더를 훈련시킨다.
일단 훈련되고 나면, 조작된 텍스트 프롬프트는 새로운 시각적 개념과 데이터 분포에 대한 zero-shot 일반화를 가능하게 한다. 이러한 인코더는 다른 모듈과 효과적으로 결합하여 이미지 생성(예: DALL-E )과 같은 downstream task를 수행할 수도 있다. 비전-언어 인코더 분야에서 많은 발전이 있었지만, 컴퓨터 비전은 이 범위를 넘어서는 매우 다양한 문제들을 포함하며, 이러한 문제들 대부분에 대해서는 방대한 훈련 데이터가 존재하지 않는다.
본 연구의 목표는 image segmentation을 위한 foundation model을 구축하는 것이다. 즉, 강력한 일반화를 가능하게 하는 과업을 통해 광범위한 데이터셋에서 사전 훈련시킬 수 있는 프롬프트 기반 모델(promptable model)을 개발하고자 한다. 이 모델을 사용하여 prompt engineering을 통해 새로운 데이터 분포에 대한 다양한 downstream 분할 문제를 해결하는 것을 목표로 한다.
이 계획의 성공은 task, model, data라는 세 가지 핵심 요소에 달려있다. 이를 개발하기 위해, 본 논문은 이미지 분할에 관한 다음과 같은 질문들을 다룬다.
- 어떤 task가 zero-shot 일반화를 가능하게 할 것인가?
- 그에 상응하는 model 아키텍처는 무엇인가?
- 어떤 data가 이 과업과 모델을 구동할 수 있는가?
이 질문들은 서로 얽혀 있어 포괄적인 해결책이 필요하다. 본 논문은 먼저 광범위한 downstream 응용을 가능하게 하고 강력한 사전 훈련 목표를 제공할 만큼 충분히 일반적인 promptable segmentation task를 정의하는 것부터 시작한다. 이 과업은 유연한 프롬프트를 지원하고, 상호작용적 사용을 위해 프롬프트 입력 시 실시간으로 분할 마스크를 출력할 수 있는 모델을 요구한다.
모델을 훈련시키기 위해서는 다양하고 대규모의 데이터 소스가 필요하다. 안타깝게도, 분할을 위한 웹 스케일 데이터 소스는 존재하지 않는다. 이 문제를 해결하기 위해, 본 논문은 효율적인 모델을 데이터 수집에 활용하고 새로 수집된 데이터로 모델을 개선하는 과정을 반복하는 "데이터 엔진"을 구축한다.
다음으로 서로 연결된 각 구성 요소를 소개하고, 이어서 우리가 만든 데이터셋과 우리 접근 방식의 효과를 입증하는 실험들을 소개한다.
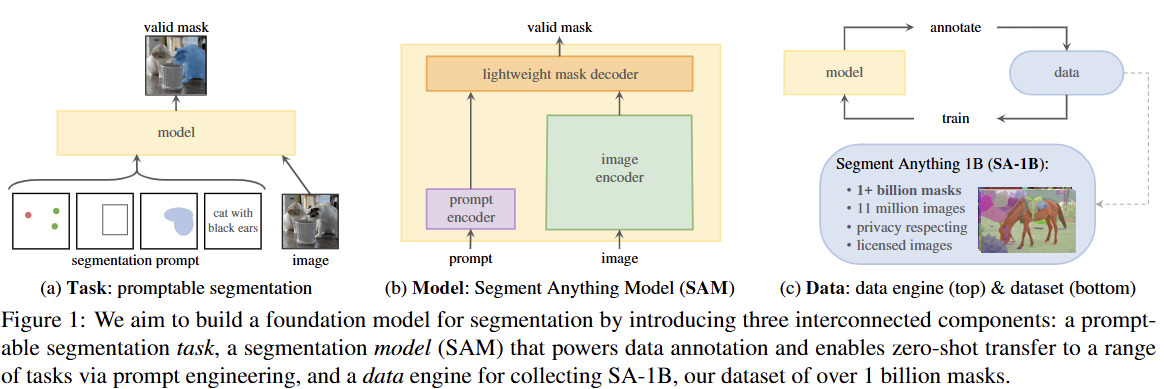
-
Task (§2). 본 논문은 foundation model 연구 흐름에서 영감을 받아 promptable segmentation task를 제안한다. 본 task의 목표는 어떤 분할 프롬프트가 주어지더라도 유효한 분할 마스크를 반환하는 것이다 (Figure 1a 참조).프롬프트는 이미지에서 분할할 대상을 간단히 지정하며, 예를 들어 객체를 식별하는 공간적 또는 텍스트 정보를 포함할 수 있다.
"유효한 출력 마스크를 요구한다"는 것은 프롬프트가 모호하여 여러 객체를 참조할 수 있는 경우 (예: 셔츠 위의 한 점이 셔츠 또는 그 셔츠를 입은 사람을 나타낼 수 있는 경우) 에도 출력이 해당 객체들 중 적어도 하나에 대한 합리적인 마스크여야 함을 의미한다.
본 논문은 promptable segmentation task를 사전 훈련 목표로 사용하고 prompt engineering을 통해 일반적인 downstream segmentation 과업을 해결하는 데 사용한다.
-
Model (§3). Promptable segmentation task와 실제 사용 목표는 모델 아키텍처에 제약을 가한다.모델은 유연한 프롬프트를 지원해야 하고, 상호작용적 사용을 위해 분할 상환 실시간(amortized real-time)으로 마스크를 계산해야 하며, 모호성을 인지할 수 있어야 한다.
본 논문은 간단한 설계(Figure 1b 참조)가 이 세 가지 제약을 모두 만족시킨다는 것을 발견했다. 본 논문은 이 모델을
Segment Anything Model (SAM)이라고 부른다.SAM의 설계 구조는 다음과 같다: (1) 강력한 이미지 인코더(image encoder)가 이미지 임베딩을 계산하고, (2) 프롬프트 인코더(prompt encoder)가 프롬프트를 임베딩한 다음, 두 정보 소스가 분할 마스크를 예측하는 경량 마스크 디코더(lightweight mask decoder)에서 결합되는 방식이다.
SAM을 image encoder와 fast prompt encoder / mask decoder로 분리함으로써, 동일한 이미지 임베딩을 다른 프롬프트와 함께 재사용할 수 있다 (그리고 그 비용은 분할 상환된다).
이미지 임베딩이 주어지면, 프롬프트 인코더와 마스크 디코더는 웹 브라우저에서 약 50ms 내에 프롬프트로부터 마스크를 예측한다.
본 논문은 점, 상자, 마스크 프롬프트에 중점을 두며, 자유 형식 텍스트 프롬프트를 사용한 초기 결과도 제시한다.
SAM이 모호성을 인지하도록 하기 위해, 단일 프롬프트에 대해 여러 개의 마스크를 예측하도록 설계하여 셔츠 대 사람 예시와 같은 모호성을 자연스럽게 처리할 수 있도록 했다.
-
Data engine (§4). 새로운 데이터 분포에 대한 강력한 일반화를 달성하기 위해, 본 논문은 기존의 어떤 분할 데이터셋보다도 크고 다양한 마스크 세트로 SAM을 훈련시킬 필요가 있음을 발견했다.Foundation model의 일반적인 접근 방식은 온라인에서 데이터를 얻는 것이지만, 마스크는 자연적으로 풍부하지 않으므로 대안 전략이 필요하다. 우리의 해결책은 "데이터 엔진"을 구축하는 것이다. 즉,
model-in-the-loop 데이터셋 주석 작업을 통해 모델을 공동 개발한다 (Figure 1c 참조). 우리의 데이터 엔진은 세 단계로 구성된다: 1. 보조-수동(assisted-manual), 2. 반자동(semi-automatic), 3. 완전 자동(fully automatic).
Stage 1. SAM은 고전적인 대화형 분할 설정과 유사하게 주석자가 마스크를 주석 처리하는 것을 돕는다.
Stage 2. SAM은 가능한 객체 위치를 프롬프트로 받아 객체의 일부에 대한 마스크를 자동으로 생성할 수 있으며, 주석자는 나머지 객체를 주석 처리하는 데 집중하여 마스크 다양성을 높이는 데 도움을 준다.
Stage 3. 전경 포인트의 규칙적인 격자를 SAM에 프롬프트로 제공하여 이미지당 평균 약 100개의 고품질 마스크를 얻는다.
-
Dataset (§5). SAM의 최종 데이터셋인 SA-1B는 1,100만 개의 라이선스가 있고 개인 정보를 보호하는 이미지에서 추출한 10억 개 이상의 마스크를 포함한다 (Figure 2 참조).데이터 엔진의 최종 단계를 사용하여 완전 자동으로 수집된 SA-1B는 기존의 어떤 분할 데이터셋보다 400배 더 많은 마스크를 보유하고 있으며, 논문에서 광범위하게 검증된 바와 같이 마스크의 품질과 다양성이 높다.
SAM을 견고하고 일반적으로 훈련시키는 데 사용되는 것 외에도, SA-1B가 새로운 foundation model을 구축하려는 연구에 귀중한 자원이 되기를 바란다.

-
Responsible AI (§6). 본 논문은 SA-1B와 SAM을 사용할 때 발생할 수 있는 잠재적인 공정성 문제와 편향을 연구하고 보고한다. SA-1B의 이미지는 지리적, 경제적으로 다양한 국가에 걸쳐 있으며, SAM은 다양한 인구 집단에 걸쳐 유사하게 수행됨을 발견했다.이 모든 것을 통해, 본 논문의 연구가 실제 사용 사례에 더 공평하게 기여하기를 바란다. 부록에 모델 및 데이터셋 카드를 제공한다.
-
Experiments (§7). 본 논문은 SAM을 광범위하게 평가한다.첫째, 23개의 다양한 새로운 분할 데이터셋을 사용하여, SAM이 단일 전경 포인트로부터 고품질의 마스크를 생성하며, 이는 종종 수동으로 주석 처리된 ground truth보다 약간 낮은 수준임을 발견했다.
둘째, prompt engineering을 사용한 zero-shot transfer 프로토콜 하에서 가장자리 감지(edge detection), 객체 제안 생성(object proposal generation), 인스턴스 분할(instance segmentation), 그리고 텍스트-마스크 예측(text-to-mask prediction)의 예비 탐색을 포함한 다양한 downstream 과업에서 일관되게 강력한 정량적 및 정성적 결과를 발견했다.
이러한 결과는 SAM이 SAM의 훈련 데이터를 넘어서는 객체 및 이미지 분포를 포함하는 다양한 과업을 해결하기 위해 prompt engineering과 함께 즉시 사용될 수 있음을 시사한다. 그럼에도 불구하고, §8에서 논의하는 바와 같이 개선의 여지는 남아있다.
2. Segment Anything Task
Task
Kirillov et al. (2023)은 자연어 처리에서 "다음 토큰 예측" 작업이 foundation model의 사전 훈련과 다양한 하위 작업 해결에 모두 활용되는 것에서 영감을 받아, 분할 분야에서도 유사한 능력을 가진 작업을 정의하고자 했다.
이들은 NLP의 프롬프트 개념을 분할 작업으로 확장하여, 프롬프트가 이미지에서 무엇을 분할해야 하는지를 나타내는 모든 정보가 될 수 있도록 정의했다.
구체적으로 프롬프트는 foreground / background 점들의 집합, 대략적인 바운딩 박스나 마스크, 자유형 텍스트, 또는 일반적으로 이미지에서 무엇을 분할할지 지시하는 모든 정보를 포함할 수 있다. promptable segmentation task의 핵심은 어떤 프롬프트가 주어져도 유효한 분할 마스크를 반환하는 것이다.
여기서 "유효한" 마스크의 요구사항은 매우 중요한데, 프롬프트가 모호하여 여러 객체를 지칭할 수 있는 경우에도 출력은 적어도 그 객체들 중 하나에 대한 합리적인 마스크여야 한다.
예를 들어 셔츠 위의 한 점이 셔츠 또는 셔츠를 입은 사람 모두를 지칭할 수 있지만, 둘 중 하나에 대한 합리적인 마스크를 생성해야 한다. 이는 언어 모델이 모호한 프롬프트에 대해서도 일관된 응답을 출력해야 한다는 기대와 유사하다.

Pre-training
사전 훈련 방법론은 각 훈련 샘플에 대해 일련의 프롬프트들을 시뮬레이션하고, 모델의 마스크 예측을 ground truth와 비교하는 자연스러운 알고리즘을 제안한다.
이 방법은 interactive segmentation에서 차용했지만, 중요한 철학적 차이가 있다. 기존 interactive segmentation의 목표는 충분한 사용자 입력을 받은 후에 결국 유효한 마스크를 예측하는 것이다.
반면 SAM의 목표는 프롬프트가 모호하더라도 어떤 프롬프트에 대해서도 항상 유효한 마스크를 예측하는 것이다. 이러한 접근법은 모호성을 포함한 사용 사례에서 사전 훈련된 모델이 효과적으로 작동하도록 보장하며, 특히 데이터 엔진에서 요구되는 자동 주석 작업에 매우 중요하다.
저자들은 이 작업에서 우수한 성능을 달성하는 것이 도전적이며, 특수한 모델링과 훈련 손실 선택이 필요하다고 언급한다. 관련 세부사항들은 Section 3에서 자세히 다룬다.
Zero-shot transfer
제로샷 전이의 핵심 아이디어는 사전 훈련 작업이 모델에게 추론 시간에 어떤 프롬프트에도 적절히 응답할 수 있는 능력을 부여한다는 것이다. 따라서 하위 작업들은 적절한 프롬프트를 설계하는 것을 통해 해결될 수 있다.
구체적인 예시로, 고양이를 위한 바운딩 박스 검출기가 있다면, 검출기의 박스 출력을 SAM에 프롬프트로 제공함으로써 고양이 인스턴스 분할을 수행할 수 있다. 이는 기존 시스템과 SAM을 결합하여 새로운 능력을 창출하는 방식을 보여준다.
일반적으로 광범위한 실용적 분할 작업들이 프롬프팅을 통해 해결될 수 있다. 저자들은 자동 데이터셋 라벨링 외에도 실험에서 다섯 가지 다양한 예시 작업들을 탐구했는데, 이는 모델의 범용성과 다양한 도메인에서의 적용 가능성을 보여준다.
Related tasks
분할 분야는 대화형 분할(interactive segmentation), 경계 검출(edge detection), 객체 제안 생성(object proposal generation), 시맨틱 분할(semantic segmentation), 인스턴스 분할(instance segmentation), 파놉틱 분할(panoptic segmentation) 등 광범위하다. 본 논문의 과업은 이러한 여러 작업에 적용될 수 있는 모델을 목표로 한다.
기존의 다중 과업(multi-task) 시스템은 고정된 여러 과업(예: 시맨틱, 인스턴스, 파놉틱 분할을 동시에 수행)을 학습하고 테스트하는 방식이었다. 하지만 본 논문에서 제안하는 모델은 학습하지 않은 새로운 과업도 추론 시점에 수행할 수 있다는 점에서 중요하다.
이 모델은 더 큰 시스템의 일부(component)로 작동하여 새로운 작업을 수행한다. 예를 들어, 기존 객체 탐지기(object detector)와 결합하여 인스턴스 분할을 수행할 수 있다.
Discussion
프롬프트(Prompting)와 구성(Composition)은 모델 설계 시점에는 알려지지 않았던 작업들을 수행할 수 있도록 단일 모델을 확장 가능한 방식으로 사용할 수 있게 하는 강력한 도구다. 이는 CLIP과 같은 파운데이션 모델이 DALL-E 이미지 생성 시스템의 구성 요소로 사용되는 방식과 유사하다. 이러한 접근 방식은 고정된 작업 세트에 대해 특별히 훈련된 시스템보다 더 넓은 범위의 애플리케이션을 가능하게 할 것으로 기대된다.
대화형 분할(interactive segmentation) 모델은 인간 사용자를 염두에 두고 설계되었지만, 본 논문에서 제안하는 프롬프트 기반 분할(promptable segmentation) 모델은 더 큰 알고리즘 시스템에 통합될 수 있다는 점에서 차이가 있다.
3. Segment Anything Model
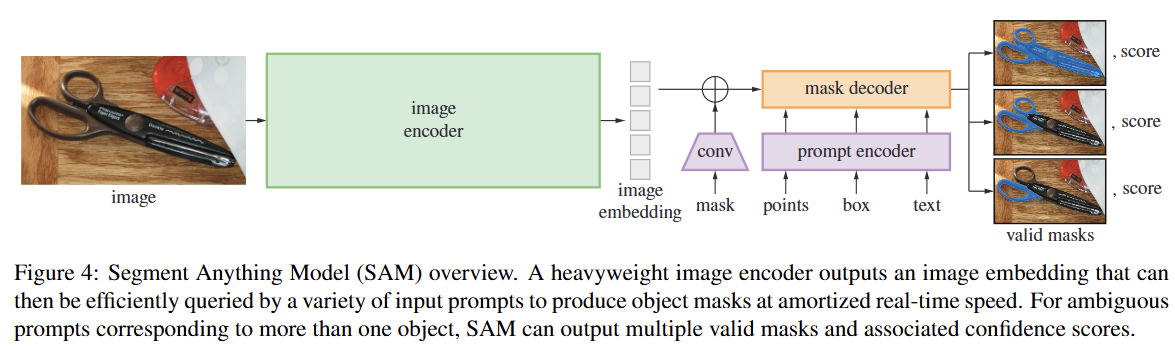
본 섹션에서는 promptable segmentation을 위한 Segment Anything Model (SAM)을 설명한다. SAM은 Figure 4에 설명된 바와 같이 이미지 인코더, 유연한 프롬프트 인코더, 빠른 마스크 디코더의 세 가지 구성 요소로 이루어져 있다.
본 논문은 분할 상환 실시간(amortized real-time) 성능을 위한 특정 절충안을 가진 Transformer 기반vision model을 기반으로 한다. 여기서는 이러한 구성 요소들을 높은 수준에서 설명한다. (자세한 내용은 부록 A 참조)
- Image Encoder
: 확장성과 강력한 사전 훈련 방법론에 동기를 부여받아, 고해상도 입력을 처리하도록 최소한으로 수정된 MAE 사전 훈련 Vision Transformer (ViT)를 사용한다. 이미지 인코더는 이미지당 한 번만 실행되며, 모델에 프롬프트를 입력하기 전에 미리 적용될 수 있다.
-
Prompt Encoder
: 두 가지 종류의 프롬프트, 즉 희소 프롬프트(sparse: 점, 상자, 텍스트)와 밀집 프롬프트(dense: 마스크)를 고려한다.점과 상자는 위치 인코딩(positional encodings)과 각 프롬프트 유형에 대한 학습된 임베딩을 합산하여 표현하며, 자유 형식 텍스트는 CLIP의 기성 텍스트 인코더를 사용한다.
밀집 프롬프트(즉, 마스크)는 convolution을 사용하여 임베딩되고 이미지 임베딩과 요소별로 합산된다.
-
Mask Decoder
: 마스크 디코더는 이미지 임베딩, 프롬프트 임베딩, 그리고 출력 토큰을 효율적으로 마스크로 매핑한다. 이 디자인은 Transformer 디코더 블록의 변형을 사용하며, 그 뒤에 동적 마스크 예측 헤드가 따라온다.수정된 디코더 블록은 프롬프트 self-attention과 양방향 cross-attention(프롬프트-이미지 임베딩, 이미지-프롬프트 임베딩)을 사용하여 모든 임베딩을 업데이트한다.
두 개의 블록을 실행한 후, 이미지 임베딩을 업샘플링하고 MLP가 출력 토큰을 동적 선형 분류기로 매핑하여 각 이미지 위치에서 마스크의 전경 확률을 계산한다.
-
Resolving Ambiguity
: 출력이 하나일 경우, 모호한 프롬프트가 주어지면 모델은 여러 유효한 마스크를 평균 내버리게 된다. 이 문제를 해결하기 위해, 단일 프롬프트에 대해 여러 출력 마스크를 예측하도록 모델을 수정했다 (그림 3 참조).3개의 마스크 출력이 대부분의 일반적인 경우(예: 전체-부분-세부 부분으로 구성된 중첩 마스크)를 처리하기에 충분하다는 것을 발견했다. 훈련 중에는 마스크들에 대한 최소 손실(minimum loss)만을 역전파한다. 마스크의 순위를 매기기 위해 모델은 각 마스크에 대한 신뢰도 점수(즉, 추정된 IoU)를 예측한다.
- Efficiency
: 전반적인 모델 설계는 효율성에 크게 동기를 부여받았다. 미리 계산된 이미지 임베딩이 주어지면, 프롬프트 인코더와 마스크 디코더는 웹 브라우저의 CPU에서 약 50ms 내에 실행된다. 이러한 실행 시간 성능은 모델의 원활하고 실시간적인 대화형 프롬프팅을 가능하게 한다.
- Losses and training
: 마스크 예측은 focal loss와 dice loss의 선형 조합으로 감독한다. Promptable segmentation 과업을 위해 기하학적 프롬프트의 혼합을 사용하여 훈련한다. 마스크당 11라운드로 프롬프트를 무작위로 샘플링하여 대화형 설정을 시뮬레이션함으로써 SAM이 데이터 엔진에 원활하게 통합될 수 있도록 한다.
4. Segment Anything Data Engine
Image Segmentation mask 데이터셋은 인터넷에 풍부하게 존재하지 않기 때문에, 11억 개의 마스크 데이터셋인 SA-1B를 수집하기 위해 데이터 엔진(Data Engine)을 구축했다. 이 데이터 엔진은 세 단계로 구성된다:
◾ 데이터 엔진(Data Engine) 구축 3단계
1. 모델 보조 수동 주석 단계 (Model-assisted manual annotation)
2. 반자동 단계 (Semi-automatic stage)
3. 완전 자동 단계 (Fully automatic stage)
1. Assisted-manual stage (보조-수동 단계)
이 첫 단계는 전통적인 대화형 분할(interactive segmentation)과 유사하다.
전문 주석가(annotator) 팀이 SAM 모델의 도움을 받아 객체의 전경/배경 지점을 클릭하여 마스크를 라벨링했다.
SAM 모델이 개선됨에 따라 마스크 당 평균 주석 시간은 34초에서 14초로 감소했고, 이미지 당 평균 마스크 수는 20개에서 44개로 증가했다. 이 단계에서 총 12만 개의 이미지로부터 430만 개의 마스크를 수집했다.
2. Semi-automatic stage (반자동 단계)
이 단계의 목표는 마스크의 다양성을 높여 모델의 분할 능력을 향상시키는 것이었다.
먼저 신뢰도 높은 마스크를 자동으로 탐지한 후, 주석가들에게 이 마스크들이 미리 채워진 이미지를 제공하고 아직 주석이 달리지 않은 추가 객체들을 라벨링하도록 요청했다.
이 단계에서는 더 까다로운 객체들을 라벨링했기 때문에 마스크 당 평균 주석 시간은 34초로 다시 증가했다. 이미지 당 평균 마스크 수는 44개에서 72개로 증가했다. 이 단계에서 18만 개의 이미지로부터 추가로 590만 개의 마스크를 수집했다.
3. Fully automatic stage (완전 자동 단계)
최종 단계에서는 주석 과정이 완전 자동으로 이루어졌다.
이는 이전 단계를 통해 모델 성능이 크게 향상되었고, 모호함을 인지하는(ambiguity-aware) 모델을 개발하여 애매한 경우에도 유효한 마스크를 예측할 수 있게 되었기 때문에 가능했다.
모델에 32×32의 정규 격자 포인트를 프롬프트로 입력하고 각 포인트에 대해 유효한 객체에 해당할 수 있는 마스크 세트를 예측했다.
이후 IoU 예측 모듈, 안정성 확인, NMS(Non-Maximal Suppression) 등의 과정을 거쳐 중복을 제거하고 신뢰도 높은 마스크만 필터링했다.
최종적으로 데이터셋의 모든 1,100만 개 이미지에 이 완전 자동 마스크 생성을 적용하여 총 11억 개의 고품질 마스크를 생성했다.
5. Segment Anything Dataset
SA-1B 데이터셋은 1,100만 개의 다양한 고해상도, 라이선스가 확보되고 개인 정보가 보호되는 이미지와 데이터 엔진으로 수집된 11억 개의 고품질 분할 마스크로 구성된다.
SA-1B는 컴퓨터 비전용 파운데이션 모델의 향후 개발을 돕기 위해 공개된다.
Image
사진작가와 직접 협력하는 제공업체로부터 1,100만 개의 새로운 고해상도 이미지(3300×4950 픽셀 평균)를 라이선스했다.
접근성을 위해 이미지의 짧은 쪽을 1,500픽셀로 다운샘플링하여 공개하며, 이는 COCO와 같은 기존 데이터셋보다 훨씬 높은 해상도다.
공개된 이미지에서는 얼굴과 차량 번호판이 블러 처리되었다.
Masks
데이터 엔진은 11억 개의 마스크를 생성했으며, 이 중 99.1%가 완전 자동으로 생성되었다.
따라서 자동 생성된 마스크의 품질이 매우 중요하며, 분석 결과 이 마스크들은 고품질이며 모델 훈련에 효과적이라는 결론을 내렸다.
이러한 결과에 따라, SA-1B 데이터셋에는 자동으로 생성된 마스크만 포함된다.
Mask quality
마스크 품질을 평가하기 위해 무작위로 샘플링된 500개 이미지(약 5만 개 마스크)에 대해 전문 주석가들이 품질을 개선하도록 요청했다.
자동 예측 마스크와 전문가 수정 마스크 쌍 간의 IoU를 계산한 결과, 94%의 쌍이 90% 이상의 IoU를 보였다.이는 기존 연구에서 추정된 주석가 간 일치도인 85-91% IoU보다 높은 수치다.
사람 평가에서도 마스크 품질이 높으며, 자동 생성된 마스크로 모델을 훈련하는 것이 데이터 엔진이 생성한 모든 마스크를 사용하는 것만큼 효과적임을 확인했다.
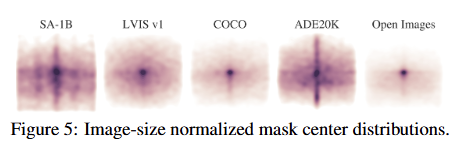
Mask properties
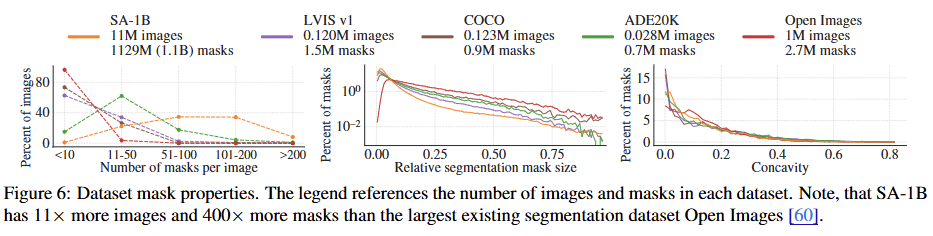
다른 대규모 데이터셋과 비교했을 때, SA-1B는 이미지 중앙 편향이 적고 이미지 모서리 부분까지 더 넓게 커버한다. SA-1B는 두 번째로 큰 Open Images 데이터셋보다 이미지 수는 11배, 마스크 수는 400배 더 많다.
이미지 당 평균 마스크 수가 다른 데이터셋보다 훨씬 많기 때문에, 상대적으로 작거나 중간 크기의 마스크 비율이 더 높다.
마스크 모양의 복잡성을 나타내는 오목함(concavity) 분포는 다른 데이터셋과 대체로 유사하다.
6. Segment Anything RAI ( Responsible AI) Analysis
SA-1B 데이터셋과 SAM 모델 사용 시 발생할 수 있는 잠재적인 공정성 문제와 편향을 조사하고 분석한다.
분석은 SA-1B의 지리적 및 소득 분포, 그리고 보호받는 인구 속성(성별, 연령, 피부색 등)에 대한 SAM의 공정성에 초점을 맞춘다.
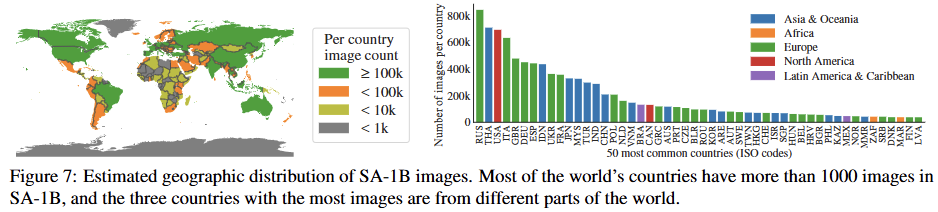
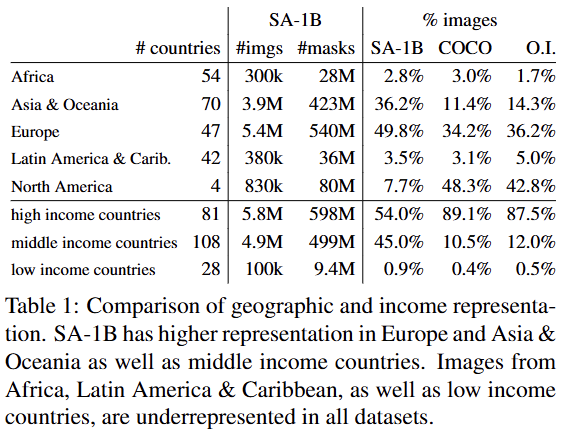
Geographic and income representation (지리적 및 소득 대표성)
이미지에 포함된 국가별 이미지 수를 시각화하고 상위 50개국을 분석했다. 상위 3개국은 서로 다른 대륙에 위치해 있다.
SA-1B는 기존 COCO나 Open Images 데이터셋에 비해 유럽, 아시아 및 오세아니아, 그리고 중간 소득 국가의 이미지 비율이 훨씬 높다.
모든 데이터셋에서 아프리카와 저소득 국가는 여전히 과소 대표되고 있다.
그럼에도 불구하고 SA-1B에서는 아프리카를 포함한 모든 지역이 최소 2,800만 개의 마스크를 보유하고 있으며, 이는 이전 데이터셋의 총 마스크 수보다 10배 이상 많은 수치다.
Fairness in segmenting people (사람 분할의 공정성)
인식되는 성별 표현(gender presentation), 연령대(age group), 피부색(skin tone)에 따른 SAM의 성능 차이를 측정하여 공정성 문제를 조사했다.
- 성별 표현: 기존 데이터셋에서는 여성이 과소 대표되는 경향이 있었지만, SAM은 여성/남성 그룹 전반에 걸쳐 유사한 성능을 보였다.
- 연령대: 젊거나 나이가 많은 그룹이 과소 대표되는 경향이 있었으나, SAM은 나이가 많은 것으로 인식되는 그룹에서 가장 좋은 성능을 보였다 (신뢰 구간은 큼).
- 피부색: 밝은 피부톤이 과대 대표되는 경향이 있었지만, SAM은 피부색 그룹 간에 유의미한 성능 차이를 보이지 않았다.
이러한 결과는 태스크 특성에서 비롯된 것으로 보이며, SAM이 더 큰 시스템의 일부로 사용될 때는 편향이 발생할 수 있음을 인정한다.

7. Zero-Shot Transfer Experiments
이 섹션에서는 SAM(Segment Anything Model)을 사용한 제로샷 전이(zero-shot transfer) 실험들을 소개한다. 여기서 '제로샷 전이'는 SAM이 학습 과정에서 보지 못했던 데이터셋과 과업에 대해 평가하는 것을 의미하며, 이는 CLIP 논문에서의 용례를 따른다.
평가에 사용된 데이터셋에는 SA-1B 데이터셋에는 없는 것으로 알려진 수중 또는 1인칭 시점 이미지 같은 새로운 이미지 분포가 포함될 수 있다.
실험은 SAM의 핵심 목표인 '어떤 프롬프트로부터든 유효한 마스크 생성하기'를 테스트하는 것부터 시작하며, 특히 모호할 가능성이 높은 단일 전경 포인트 프롬프트의 어려운 시나리오에 중점을 둔다.
이후 이미지 이해도의 여러 단계를 아우르는 4가지 추가 과업을 통해 SAM의 성능을 평가한다. 이 과업들은 SAM이 학습한 '프롬프트 기반 분할' 태스크와는 크게 다르며, 프롬프트 엔지니어링을 통해 구현된다.
(1) 경계 검출 (Edge detection): 저수준(low-level) 태스크
(2) 객체 제안 생성 (Object proposal generation): "모든 것 분할하기"에 해당하는 중수준(mid-level) 태스크
(3) 인스턴스 분할 (Instance segmentation): "탐지된 객체 분할하기"에 해당하는 고수준(high-level) 태스크
(4)자유 형식 텍스트로부터 객체 분할 (Text-to-mask): 개념 증명(proof-of-concept) 단계의 태스크
실험 설정 (Implementation)
:별도의 명시가 없는 한 모든 실험은 다음의 기본 설정을 따른다.
- SAM은 MAE로 사전 학습된 ViT-H 이미지 인코더를 사용한다.
- SAM은 데이터 엔진의 최종 단계에서 자동으로 생성된 마스크(SA-1B 데이터셋)만으로 학습되었다.
- 기타 하이퍼파라미터 등 세부 사항은 부록 A를 참조한다.
7.1. Zero-Shot Single Point Valid Mask Evaluation
-
Task
단 하나의 전경 포인트(single foreground point)만으로 객체를 분할하는 성능을 평가한다.이 태스크는 하나의 포인트가 여러 객체를 가리킬 수 있어 본질적으로 모호하고 어렵다(ill-posed).
대부분의 데이터셋 정답 마스크는 가능한 모든 경우를 포함하지 않아, 자동 평가 지표가 신뢰하기 어려울 수 있다.
따라서 표준적인 mIoU(mean Intersection over Union) 지표와 함께, 사람이 직접 마스크 품질을 1점에서 10점까지 평가하는 인간 연구(human study)를 보조적으로 사용했다.
비교를 위한 주요 베이스라인 모델로는 강력한 대화형 분할 모델인 RITM을 사용했다.
-
Datasets
평가를 위해 다양한 이미지 분포를 가진 새로운 23개의 데이터셋 모음을 구성했다.mIoU 평가는 23개 전체 데이터셋을 사용했으며, 리소스가 많이 필요한 인간 연구는 이 중 일부 데이터셋에 대해서만 수행했다.
-
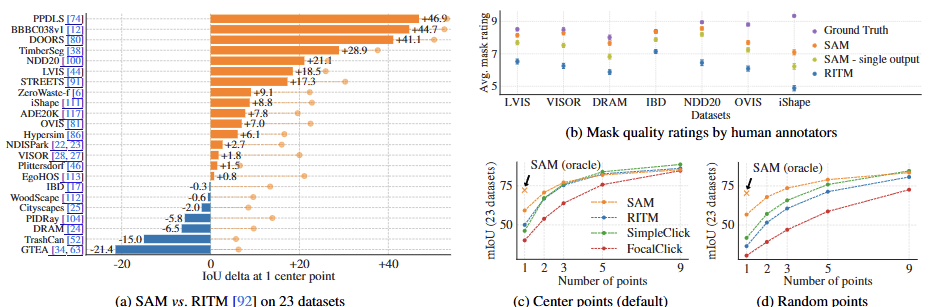
Results
자동 평가 (mIoU): 23개 데이터셋 중 16개에서 SAM이 RITM보다 높은 mIoU 점수를 기록했다. 정답 마스크와 비교하여 SAM이 예측한 3개의 마스크 중 가장 근접한 것을 선택하는
"오라클(oracle)" 평가: 모호성 문제를 해결했을 때 SAM이 모든 데이터셋에서 RITM을 능가했다.
인간 연구 평가: 주석가들은 모든 데이터셋에서 SAM의 마스크 품질을 RITM보다 일관되게 훨씬 높게 평가했다. 자동 평가 지표(mIoU)에서 SAM이 더 낮게 나온 데이터셋(DRAM, IBD 등)에서조차 인간 평가는 SAM의 압도적인 우위를 보였다. 이는 SAM이 정답과는 다르더라도 사람이 보기에 훨씬 더 타당하고 유효한 마스크를 생성했음을 의미한다.
포인트 수 증가: 프롬프트 포인트 수를 1개에서 9개로 늘리자 모델 간의 성능 격차는 줄어들었다. 이는 과업이 쉬워지기 때문이며, SAM은 다수의 포인트를 사용하는 초고정밀도(very high IoU) 환경에 최적화되지는 않았음을 보여준다.
무작위 포인트 샘플링: 기존의 중앙점 샘플링 대신 무작위로 포인트를 샘플링했을 때, SAM과 베이스라인 모델들 간의 성능 격차는 더욱 커졌다. 이는 SAM이 포인트 위치에 덜 민감하고 더 강건하게 작동함을 시사한다.

7.2. Zero-Shot Edge Detection
-
Approach
고전적인 저수준(low-level) 과업인 경계 검출에 대해 SAM의 성능을 평가했다.
자동 마스크 생성 파이프라인의 간소화된 버전을 사용했다.
구체적으로, SAM에 16×16 정규 격자(grid)의 전경 포인트를 프롬프트로 입력하여 768개의 마스크를 예측하게 했다.
중복 마스크는 NMS(Non-Maximal Suppression)로 제거한 뒤, 예측된 마스크 확률 맵에 Sobel 필터를 적용하고 표준적인 후처리 과정을 거쳐 최종 경계 맵(edge map)을 생성했다.
-
Results
정성적 평가: SAM은 경계 검출용으로 학습되지 않았음에도 불구하고, 합리적인 수준의 경계 맵을 생성했다 (Fig. 10).정답(ground truth)과 비교했을 때, SAM은 정답에는 주석 처리되지 않았지만 타당해 보이는 경계를 포함하여 더 많은 경계를 예측하는 경향을 보였다.
정량적 평가: 이러한 경향은 수치에도 반영되었다 (Table 3). 정밀도(precision)를 희생하는 대신, 50% 정밀도에서의 재현율(R50)은 높게 나타났다.
당연하게도 SAM은 평가 데이터셋(BSDS500)의 편향(어떤 경계를 억제해야 하는지 등)을 학습한 최신 방법들보다는 성능이 뒤처졌다.
결론: 그럼에도 불구하고, SAM은 BSDS500으로 학습한 HED와 같은 선구적인 딥러닝 방법과 비교할 만한 성능을 보였으며, 다른 제로샷 방법들보다는 훨씬 뛰어난 결과를 달성했다.

7.3. Zero-Shot Object Proposals
-
Approach
SAM을 객체 제안 생성(object proposal generation)이라는 중수준(mid-level) 과업에 대해 평가했다.평가는 대규모 카테고리를 가진 LVIS v1 데이터셋에서 표준적인 평균 재현율(Average Recall, AR) 메트릭을 사용하여 진행했다. 비교 대상인 베이스라인은 강력한 성능을 보이는 ViTDet-H 탐지기를 사용했다. 이 모델은 LVIS 데이터로 학습되었고 AR 점수를 높이는 데 유리하여 매우 까다로운 비교 대상이다.
SAM에서 객체 제안을 생성하기 위해, 약간 수정된 버전의 자동 마스크 생성 파이프라인을 실행하고 그 결과를 제안으로 사용했다.
-
Results
예상대로 LVIS에 대해 학습된 ViTDet-H가 전반적으로 가장 좋은 성능을 보였다.하지만 SAM은 여러 지표에서 놀라울 정도로 좋은 성능을 보였다. 특히 중간 크기 및 큰 객체, 그리고 희귀(rare) 및 일반(common) 카테고리 객체에서는 ViTDet-H를 능가했다.
SAM은 LVIS 데이터셋의 주석 편향을 학습할 수 있는 ViTDet-H와 달리, LVIS로 학습하지 않았기 때문에 작은 객체와 빈번한(frequent) 객체에서만 성능이 뒤처졌다.
모호성을 처리하여 여러 마스크를 출력하는 SAM의 능력이 중요한 역할을 했다. 3개 대신 단일 마스크만 출력하도록 수정한 버전("single out.")은 모든 AR 지표에서 성능이 크게 저하되었다
7.4. Zero-Shot Instance Segmentation
-
접근 방식 (Approach)
SAM을 인스턴스 분할기(instance segmenter)의 분할 모듈로 사용하는 고수준(high-level) 비전 과업을 평가했다.구현은 간단하다: 먼저 ViTDet이라는 객체 탐지기를 실행하고, 탐지기가 출력한 경계 상자(bounding box)를 SAM에 프롬프트로 입력한다.
이는 SAM을 더 큰 시스템에 구성 요소로 통합(composing)하는 예시를 보여준다.
-
결과 (Results)
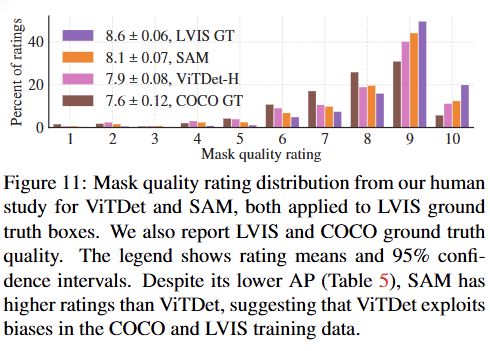
정량적 평가 (Mask AP): COCO와 LVIS 데이터셋 모두에서 ViTDet의 마스크 AP 점수가 SAM보다 높게 나타났다. SAM이 합리적으로 근접한 성능을 보였지만, 완전히 지도 학습된 ViTDet에는 미치지 못했다.
정성적 및 인간 평가: 시각적으로 확인했을 때 SAM의 마스크가 ViTDet보다 더 깔끔한 경계를 가지는 등 질적으로 더 우수해 보였다. 이를 검증하기 위해 진행한
인간 연구(human study)에서, 평가자들은 일관되게 SAM의 마스크 품질을 ViTDet보다 높게 평가했다.
결과 분석: 이러한 정량/정성 평가의 불일치는 데이터셋의 편향(bias) 때문으로 추측된다.
COCO 데이터셋은 정답 마스크의 품질이 상대적으로 낮은데, ViTDet은 이러한 COCO 특유의 편향을 학습하여 높은 AP 점수를 얻는 반면, 제로샷으로 동작하는 SAM은 이런 (바람직하지 않은) 편향을 학습할 수 없다.
LVIS 데이터셋은 품질이 더 높지만, 여전히 '구멍 없는 마스크'와 같은 특정 주석 관행이 존재하는데, ViTDet은 이를 학습하여 유리하게 활용할 수 있다.
7.5. Zero-Shot Text-to-Mask
-
접근 방식 (Approach)
자유 형식의 텍스트(free-form text)로부터 객체를 분할하는, 한 단계 더 높은 수준의 태스크를 평가했다. 이 실험은 SAM의 텍스트 프롬프트 처리 능력을 보여주기 위한 개념 증명(proof-of-concept)이다.이 실험을 위해 SAM의 학습 절차를 일부 수정했지만, 새로운 텍스트 주석(annotation)은 필요하지 않았다.
학습 시, 수동으로 수집된 마스크 영역을 잘라내어 CLIP의 이미지 인코더를 통해 이미지 임베딩을 추출했다. 이 이미지 임베딩을 SAM에 프롬프트로 제공하여 학습시켰다.
핵심 아이디어는 CLIP이 이미지와 텍스트 임베딩을 정렬(align)하도록 학습되었기 때문에, 학습은 이미지 임베딩으로 하고, 추론 시에는 텍스트 임베딩을 프롬프트로 사용할 수 있다는 점이다.
-
결과 (Results)
정성적 평가 결과, SAM은 "a wheel" 같은 단순한 텍스트 프롬프트뿐만 아니라 "beaver tooth grille"과 같은 미묘한 표현도 이해하고 객체를 분할할 수 있었다 (Fig. 12).텍스트 프롬프트만으로 원하는 객체를 정확히 분할하지 못하는 경우, 추가적으로 포인트 프롬프트를 하나 제공하면 예측이 수정되는 경향을 보였다.

7.6. Ablations
단일 중앙 포인트 프롬프트 프로토콜을 사용하여 23개 데이터셋 모음에 대해 몇 가지 ablation study를 수행했다.
-
Impact of Data Engine Stages
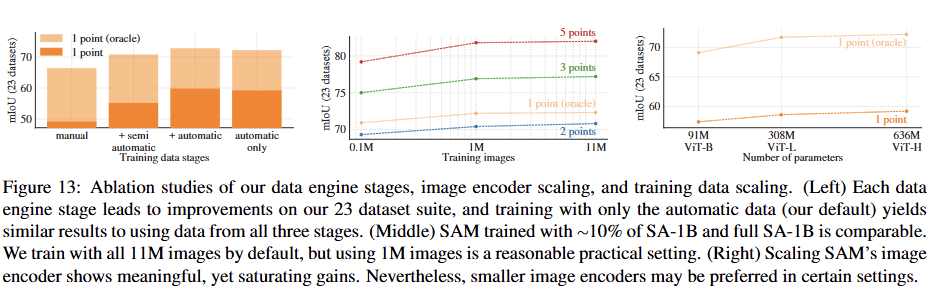
데이터 엔진의 각 단계를 거치면서 수집된 데이터를 누적하여 학습시켰을 때, 매 단계마다 mIoU 성능이 향상되는 것을 관찰했다.최종적으로 자동 생성된 마스크만 사용하여 학습했을 때, 모든 단계의 데이터를 함께 사용한 것과 비교하여 성능이 아주 약간만 감소(약 0.5 mIoU)하는 데 그쳤다.
따라서 학습 설정을 단순화하기 위해, 기본 모델은 자동 생성 마스크만으로 학습하는 방식을 채택했다.
-
Impact of Data Volume
전체 SA-1B 데이터셋(1,100만 개 이미지)을 100만 개 및 10만 개로 샘플링하여 데이터 양의 영향을 분석했다.10만 개 이미지를 사용했을 때는 성능이 크게 하락했다.
하지만 전체의 약 10%에 해당하는 100만 개 이미지만 사용했을 때도 전체 데이터셋을 사용한 것과 거의 비슷한 결과를 얻을 수 있었다. 이는 약 1억 개의 마스크를 포함하는 규모로, 많은 실제 사용 사례에서 실용적인 설정이 될 수 있다.
-
Impact of Image Encoder Scale
ViT-B, ViT-L, ViT-H 이미지 인코더를 사용하여 모델 크기의 영향을 분석했다.ViT-H는 ViT-B에 비해 성능이 크게 향상되었지만, ViT-L보다는 아주 약간의 향상만을 보였다.
이는 이미지 인코더의 크기를 계속 키우는 것이 현재로서는 큰 효과를 보기 어려우며, 성능 향상이 점차 둔화(saturating)되고 있음을 시사한다.
8. Discussion
Foundation Models
SAM의 연구는 광범위한 데이터로 학습되어 다양한 하위 작업에 적용 가능한 '파운데이션 모델'의 정의와 잘 부합한다.
하지만 파운데이션 모델이 자기지도 학습(self-supervised learning)을 강조하는 것과는 대조적으로, SAM의 능력은 대부분 대규모 지도 학습(large-scale supervised training)에서 비롯되었다.
이는 데이터 엔진을 통해 주석(annotation)을 확장할 수 있는 경우, 지도 학습이 효과적인 해결책이 될 수 있음을 보여준다.
Compositionality
SAM의 목표는 다른 시스템과 쉽게 결합하여 사용될 수 있도록 하는 것이다. 이는 CLIP 모델이 DALL-E 시스템의 구성 요소로 사용되는 것과 유사하다.
SAM이 광범위한 프롬프트에 대해 신뢰성 있는 마스크를 예측하도록 함으로써, 다른 구성 요소와의 안정적인 인터페이스를 만들고자 한다.
예를 들어, SAM은 3D 재구성 모델과 결합되거나, 웨어러블 기기에서 감지된 시선 지점(gaze points)을 프롬프트로 받아 새로운 애플리케이션을 가능하게 할 수 있다.
Limitations
SAM은 완벽하지 않으며,
미세한 구조를 놓치거나, 작은 분리된 구성 요소를 잘못 생성할 수 있다.
경계(boundary) 생성은 더 계산 집약적인 방법들만큼 선명하지 않다.
다수의 포인트가 주어지는 고정밀(high IoU) 대화형 분할 환경에서는 전용으로 설계된 다른 모델들이 SAM보다 성능이 좋을 것으로 예상된다.
무거운 이미지 인코더를 사용할 경우 전체 성능이 실시간은 아니다.
텍스트-마스크(text-to-mask) 변환 기능은 아직 탐색적인 수준이며 완전히 안정적이지는 않다.
semantic segmentation이나 panoptic segmentation 같은 특정 작업을 위한 간단한 프롬프트를 어떻게 설계할지는 아직 불분명하다.
Conclusion
Segment Anything는 image segmentation 분야를 파운데이션 모델의 시대로 끌어올리려는 시도이다.
이 연구의 핵심적인 기여는 이러한 도약을 가능하게 한 세 가지 요소, 즉 새로운 task (promptable segmentation), 모델(SAM), 그리고 데이터셋(SA-1B)이다.
SAM이 실제로 파운데이션 모델의 지위를 얻게 될지는 앞으로 커뮤니티에서 어떻게 활용되는지에 달려있다.
하지만 이 연구가 제시하는 관점, 10억 개가 넘는 마스크 데이터셋의 공개, 그리고 프롬프트 기반 분할 모델은 앞으로 해당 분야가 나아갈 길을 닦는 데 도움이 될 것으로 기대한다.
