
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
👉🏻 GroundingDINO by IDEA-Research
full-summary
본 논문은 오픈셋 객체 탐지(Open-Set Object Detection)를 위해 Grounding DINO라는 새로운 모델을 제안한다. Grounding DINO는 Transformer 기반의 탐지기인 DINO와 그라운딩 사전 학습(grounded pre-training)을 결합한 구조이다. 이 모델은 카테고리 이름이나 참조 표현(referring expression)과 같은 사용자 입력을 통해 임의의 객체를 탐지할 수 있는 능력을 갖추는 것을 목표로 한다.
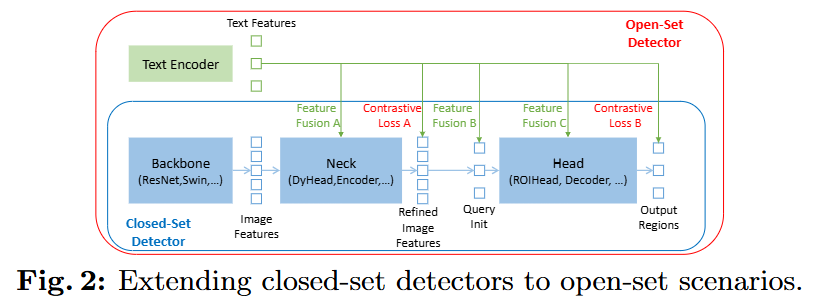
기존의 폐쇄형(closed-set) 탐지기를 오픈셋으로 확장하기 위해, 본 논문은 언어와 비전 양식을 효과적으로 융합하는 '긴밀한 융합(tight fusion)' 방식을 제안한다. 이를 위해 기존 탐지기 구조를 특징 추출, 쿼리 초기화, 박스 예측의 세 단계로 나누고, 각 단계에서 언어 정보를 긴밀하게 통합하는 방법을 설계했다.
구체적으로는 Feature Enhancer, Language-Guided Query Selection, Cross-Modality Decoder를 통해 두 양식 간의 융합을 극대화했다.
또한, 대규모 데이터를 활용한 그라운딩 학습 방법론을 채택하고, 기존 방식의 단점을 보완하기 위해 'sub-sentence level' 텍스트 특징 추출 기법을 도입했다.
실험 결과, Grounding DINO는 COCO, LVIS, ODinW 등 주요 벤치마크에서 뛰어난 제로샷(zero-shot) 탐지 성능을 보였으며, 특히 COCO 제로샷 벤치마크에서 52.5 AP를 달성하며 새로운 기록을 세웠다.
section-summary
1. 서론 (Introduction)
- 문제 정의: 기존 객체 탐지는 미리 정의된 카테고리만 탐지하는 폐쇄형(Closed-Set) 방식에 머물러 있어, 실제 세계의 다양한 객체를 다루기 어렵다. 본 논문은 언어 입력을 통해 처음 보는 객체도 탐지할 수 있는 오픈셋 객체 탐지(Open-Set Object Detection)를 목표로 한다.

-
핵심 아이디어:
긴밀한 양식 융합(Tight Modality Fusion): DINO와 같은 Transformer 기반 탐지기의 구조적 이점을 활용하여, 백본, 넥(neck), 헤드(head)의 여러 단계에서 이미지와 텍스트 특징을 긴밀하게 융합한다.대규모 그라운딩 사전 학습(Large-scale Grounded Pre-train): 객체 탐지를 구문 그라운딩(phrase grounding) 문제로 재정의하고, 대규모 데이터셋으로 사전 학습하여 모델의 제로샷 일반화 성능을 높인다.
- 주요 성과: COCO, LVIS 등 주요 벤치마크에서 SOTA(State-of-the-Art) 성능을 달성했으며, Stable Diffusion과 결합하여 이미지 편집 등 다양한 응용 가능성을 제시했다.
2. 관련 연구 (Related Work)
Detection Transformers: Grounding DINO는 DETR 계열 모델, 특히 DINO를 기반으로 한다. DINO는 대조적 디노이징(contrastive de-noising) 등의 기법으로 COCO 벤치마크에서 높은 성능을 보였으나, 사전 정의된 클래스에만 국한되는 한계가 있다.
- 오픈셋 객체 탐지: 기존 연구들은 CLIP 같은 모델의 지식을 증류하거나(ViLD) , 탐지를 그라운딩 문제로 공식화(GLIP)하는 방식을 사용했다. 그러나 이들은 특징 융합을 특정 단계(예: 넥 또는 쿼리 초기화)에서만 부분적으로 수행하여 최적의 성능을 내기 어려웠다. Grounding DINO는 전 단계에 걸친 융합을 통해 이를 개선하고자 했다.
3. Grounding DINO 방법론
-
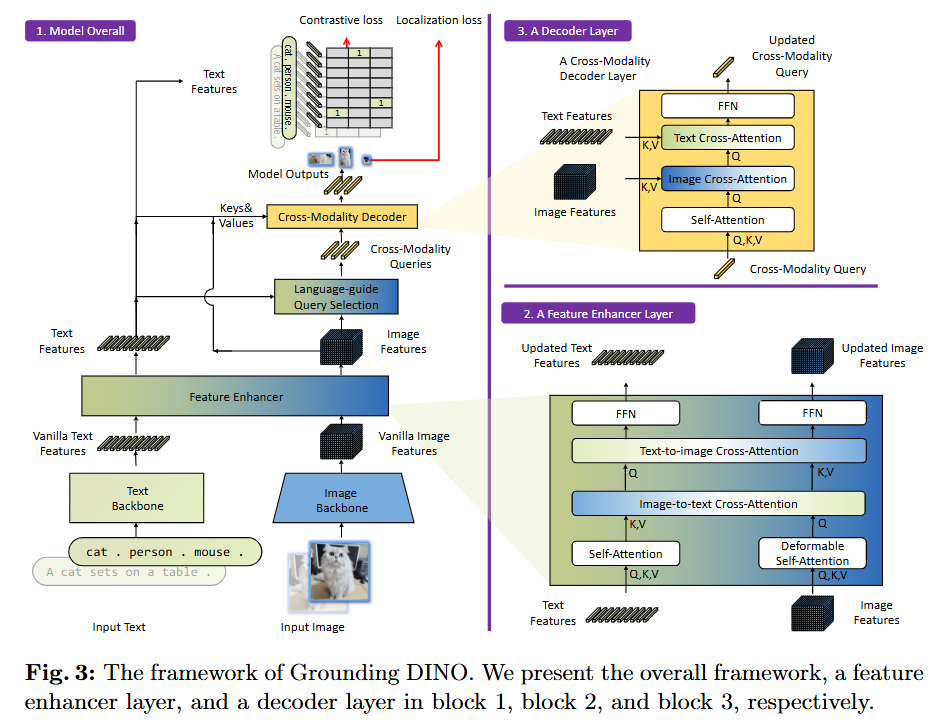
전체 구조: Grounding DINO는 이중 인코더-단일 디코더(dual-encoder-single-decoder) 구조를 따른다.
이미지 백본(예: Swin Transformer)과 텍스트 백본(예: BERT)이 각각의 특징을 추출한 후, 세 가지 핵심 모듈을 통해 융합 및 객체 탐지를 수행한다.
- 핵심 구성 요소:
- Feature Enhancer: 이미지와 텍스트의 초기 특징(vanilla features)을 입력받아, self-attention, text-to-image cross-attention, image-to-text cross-attention을 통해 양방향으로 특징을 융합하고 강화한다.
- Language-Guided Query Selection: 텍스트 특징과 이미지 특징 간의 유사도를 계산하여, 텍스트 프롬프트와 가장 관련성이 높은 이미지 영역 특징을 디코더의 초기 쿼리(query)로 선택한다. 이를 통해 탐지 과정이 언어 입력에 의해 효과적으로 안내된다.
- Cross-Modality Decoder: 선택된 쿼리들은 디코더에 입력되어 self-attention, image cross-attention뿐만 아니라 text cross-attention을 추가적으로 거친다. 이를 통해 디코더의 각 레이어에서 텍스트 정보를 지속적으로 주입받아 객체 박스를 정제한다.
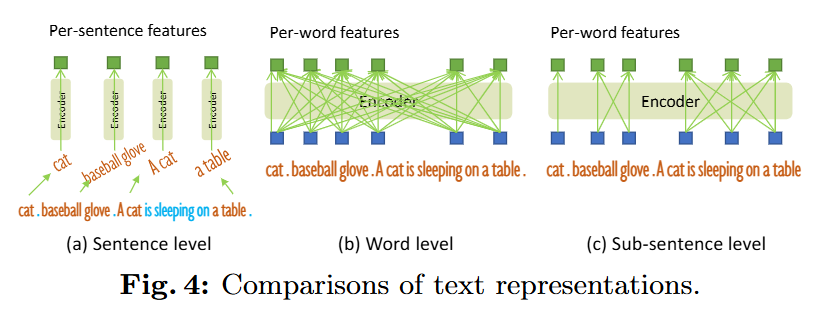
- Sub-Sentence Level Text Feature: 기존 연구들이 문장 전체를 하나의 특징으로 인코딩하거나, 단어들을 단순히 이어 붙여 불필요한 단어 간 상호작용을 유발했던 문제를 해결한다. 이 방법은 attention mask를 사용해 관련 없는 카테고리 이름 간의 상호작용을 차단함으로써, 각 단어의 고유한 특징을 유지하면서도 세밀한 정보를 활용할 수 있게 한다.
- 손실 함수: 박스 회귀를 위해 L1 손실과 GIoU 손실을 사용하고, 분류를 위해 예측된 객체와 언어 토큰 간의 대조적 손실(contrastive loss)을 사용한다.
4. 실험 (Experiments)
-
제로샷 전이(Zero-Shot Transfer):
-
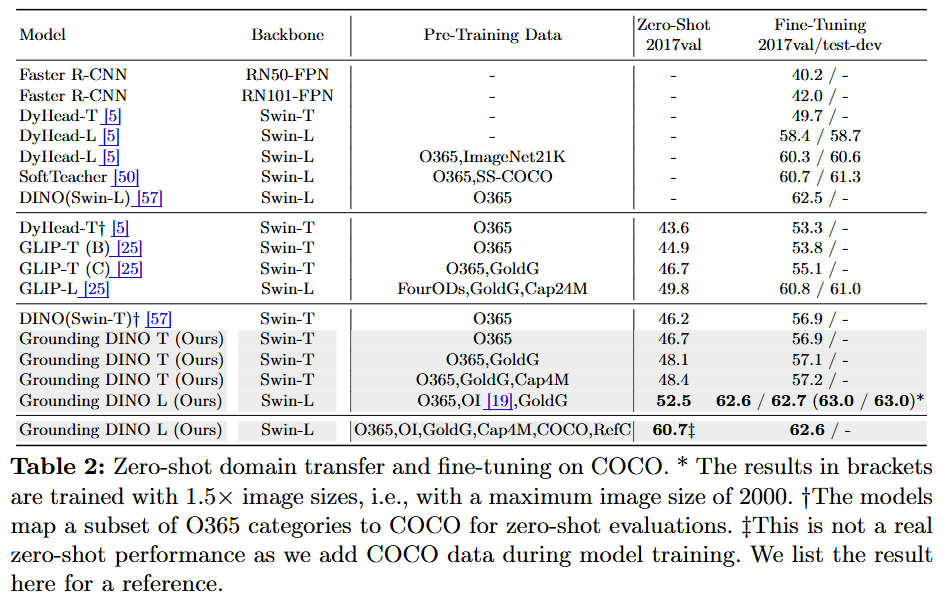
COCO: COCO 학습 데이터 없이 사전 학습된 모델만으로 평가했을 때 52.5 AP를 달성하여 GLIP과 DINO를 능가했다.
-
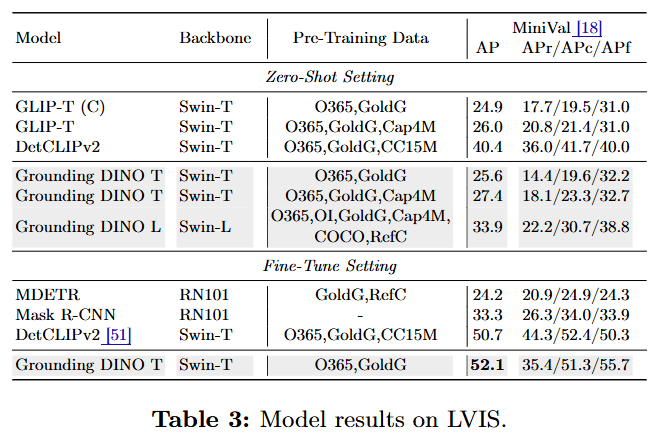
LVIS: 희귀 카테고리에서는 GLIP보다 다소 낮은 성능을 보였으나, 일반적인 객체에서는 더 나은 성능을 보였다. 또한 더 많은 데이터에 대해 더 나은 확장성(scalability)을 보였다.
-
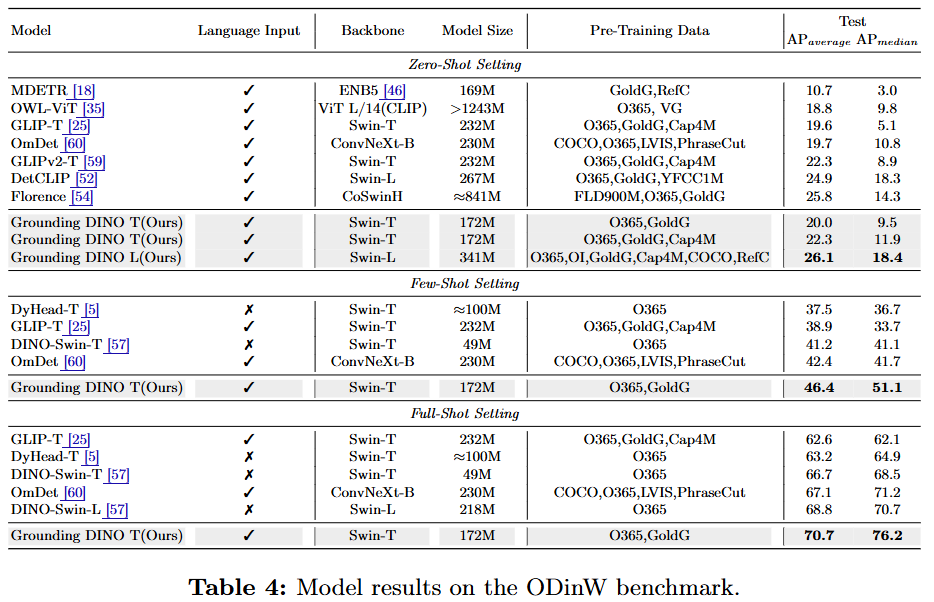
ODinW: 35개의 다양한 데이터셋으로 구성된 이 벤치마크에서 26.1 AP를 기록하며 SOTA를 달성했고, 거대 모델인 Florence보다도 높은 성능을 보였다.
-
-
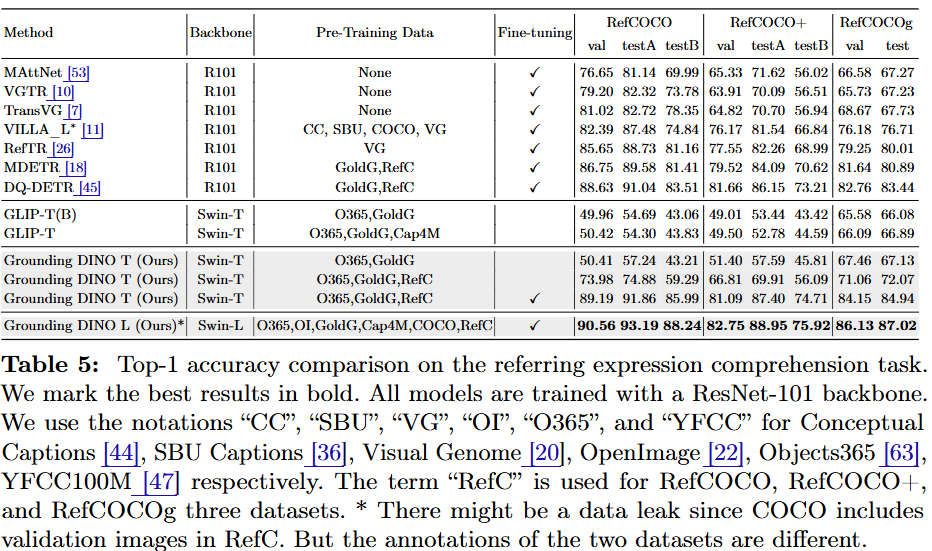
참조 객체 탐지 (Referring Object Detection):
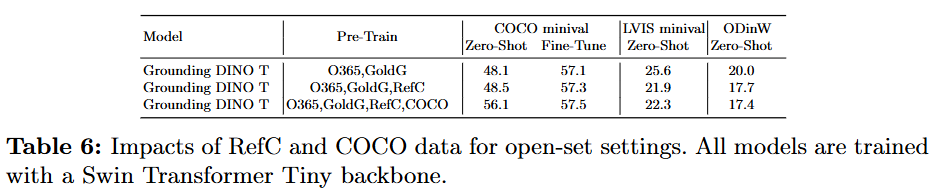
RefCOCO/+/g 데이터셋에서 사전 학습만으로는 GLIP과 마찬가지로 성능이 저조했지만, 해당 데이터를 학습에 포함시키자 상당한 성능 향상을 보였다. 이는 현재 오픈셋 모델들이 더 세밀한 탐지를 위해 개선이 필요함을 시사한다.
-
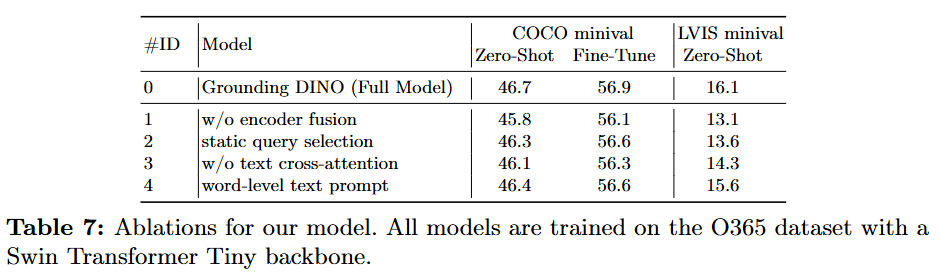
Ablation Studies:
제안된 각 모듈(encoder fusion, language-guided query selection, text cross-attention 등)을 제거하며 성능을 비교한 결과, 모든 요소가 모델 성능 향상에 긍정적으로 기여함을 확인했다. 특히 인코더 단계에서의 융합이 성능 향상에 가장 큰 영향을 미쳤다.
5. 결론 (Conclusion)
- 요약: 본 논문은 DINO를 오픈셋 객체 탐지로 확장한 Grounding DINO를 제안했다. 긴밀한 양식 융합 방식과 sub-sentence level 표현을 통해 다양한 벤치마크에서 뛰어난 성능을 입증했다.
-
한계점:
1) GLIPv2와 달리 분할(segmentation) 작업에는 사용할 수 없다.
2) 더 큰 규모의 데이터로 학습한 GLIP 모델보다는 학습 데이터가 적어 최종 성능이 제한될 수 있다.
3) 특정 경우에 거짓 양성(false positive)을 생성하는 문제가 있다.
- 향후 과제: REC 제로샷 성능에 대한 추가적인 연구가 필요함을 강조했다.
