[day-5 논문 핥기] Retrieval-Augmented Generation (RAG) for Knowledge-Intensive NLP Tasks
reading papers

Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Lewis et al., 2020)
👉🏻 Retrieval Augmented Generation(RAG) by Facebook AI Research
Full Summary
본 논문은 사전 학습된 대규모 언어 모델(Parametric Memory)의 한계를 보완하기 위해, 외부의 방대한 지식 소스(Non-parametric Memory)에서 정보를 검색(Retrieve)하여 이를 기반으로 답변을 생성(Generate)하는 RAG (Retrieval-Augmented Generation) 프레임워크를 제안한다.
Problem Statement
대규모 언어 모델(LLM)은 파라미터 내에 방대한 사실적 지식을 저장하지만, 다음과 같은 본질적인 한계를 가진다.
- 지식 업데이트의 어려움: 세상의 정보가 바뀌었을 때, 모델의 지식을 수정하거나 확장하기 위해 전체 모델을 재학습해야 하므로 비용이 많이 든다.
- 환각 (Hallucination): 모델이 학습한 지식에만 의존하므로, 사실과 다르거나 존재하지 않는 정보를 생성할 수 있다.
- 출처 불분명: 생성된 답변이 어떤 정보에 근거했는지 추적하기 어려워 신뢰성을 판단하기 어렵다.
RAG는 이러한 문제들을 해결하기 위해 LLM의 내부 지식과 외부의 명시적인 지식을 결합하는 하이브리드 접근법을 제시한다.
Proposed Method
RAG는 Retriever와 Generator 두 가지 핵심 요소로 구성된다.
-
Retriever (검색기): DPR (Dense Passage Retrieval) 모델을 사용하여, 주어진 입력(Query)과 가장 관련성이 높은 K개의 문서를 외부 지식 소스(본 논문에서는 Wikipedia index)에서 검색한다. 이 외부 지식 소스가 Non-parametric Memory에 해당한다.
-
Generator (생성기): BART와 같은 사전 학습된 Seq2Seq 모델을 사용하여, 원본 입력과 Retriever가 검색한 문서를 함께 입력받아 최종 텍스트를 생성한다. 이 생성 모델의 가중치가 Parametric Memory 역할을 한다.
본 논문은 다음과 같이 두 가지 RAG 모델을 제안한다.
RAG-Sequence: 하나의 답변 시퀀스 전체를 생성할 때 동일한 검색 문서를 참조한다.
RAG-Token: 답변의 각 토큰을 생성할 때마다 서로 다른 문서를 참조할 수 있어, 여러 문서의 정보를 종합하는 데 더 유리하다.
이 두 구성 요소는 검색할 정답 문서에 대한 명시적인 레이블 없이, 최종 출력에 대한 손실 값을 역전파하여 End-to-End 방식으로 함께 학습된다.
Experiments & Results
본 논문은 다양한 지식 집약적 NLP 태스크에서 RAG의 성능을 평가했다.
- Open-domain Question Answering: Natural Questions, WebQuestions 등 4개의 QA 데이터셋에서 기존의 파라미터 기반 모델(T5)과 검색-추출(retrieve-and-extract) 모델을 모두 능가하며 SOTA(State-of-the-Art) 성능을 달성했다. 특히, 검색된 문서에 정답이 없는 경우에도 RAG는 11.8%의 정답률을 보여, 단순 추출 모델(0%)보다 강건함을 입증했다.
- Knowledge-Intensive Generation: Jeopardy 문제 생성 및 MSMARCO 요약 태스크에서, 순수 BART 모델보다 더 사실에 기반하고(factual), 구체적이며(specific), 다양한(diverse) 결과물을 생성했다. 인간 평가에서도 RAG의 생성 결과가 BART보다 사실성과 구체성 측면에서 월등히 우수하다는 평가를 받았다.
- Fact Verification: FEVER 데이터셋에서 별도의 검색 감독(retrieval supervision) 없이도 복잡한 파이프라인 기반의 SOTA 모델에 근접하는 성능을 보였다.
Contributions & Significance
- 지식 업데이트 용이성: 모델 전체를 재학습할 필요 없이, 외부 문서 인덱스(Non-parametric Memory)를 최신 정보로 교체(index hot-swapping)하는 것만으로 모델의 지식을 쉽게 업데이트할 수 있음을 실험으로 증명했다.
- Parametric & Non-parametric 메모리의 시너지: RAG가 외부 문서에서 핵심 정보를 찾고(non-parametric), 이를 바탕으로 모델 내부의 지식(parametric)을 활용하여 유창한 문장을 완성하는, 두 메모리의 효과적인 상호작용을 보여주었다.
- 범용적 프레임워크 제시: 특정 태스크에 국한되지 않고 다양한 지식 집약적 NLP 태스크에 일관되게 적용할 수 있는 범용적인(general-purpose) fine-tuning 방법론을 제시했다. 이는 이후 수많은 RAG 관련 연구의 기틀이 되었다.
Section Summary
Introduction
-
기존 사전 학습 언어 모델의 한계
사전 학습된 신경망 언어 모델은 방대한 양의 지식을 파라미터 안에 암시적(implicit)으로 저장할 수 있다.
그러나 이러한 모델들은 저장된 지식을 쉽게 확장하거나 수정하기 어렵고, 예측의 근거를 명확히 제시하지 못하며, 사실과 다른 내용을 생성하는
환각(hallucinations)현상을 보일 수 있다는 단점이 있다. -
하이브리드 모델의 필요성
이러한 한계를 극복하기 위해 모델의 파라미터(parametric memory)와 외부 검색 기반의 비-파라미터 메모리(non-parametric memory)를 결합한 하이브리드 모델이 제안되었다.
비-파라미터 메모리를 활용하면 지식을 직접 수정 및 확장할 수 있고, 모델이 어떤 정보에 접근했는지 확인하고 해석할 수 있어 투명성이 높아진다.
REALM, ORQA와 같은 기존 연구들은 이러한 접근법의 가능성을 보여주었지만, 주로 추출형 질의응답(extractive question answering) 태스크에 국한되었다.
-
RAG (Retrieval-Augmented Generation) 모델 제안
본 논문은 Seq2Seq 모델에 검색 기반의 비-파라미터 메모리를 결합하는 범용적인 파인튜닝 방법론인 RAG(retrieval-augmented generation)를 제안한다.
RAG는 사전 학습된 Seq2Seq 모델(BART)을 파라미터 메모리로, 위키피디아의 밀집 벡터 인덱스(dense vector index)를 비-파라미터 메모리로 사용하며, 사전 학습된 신경망 검색기(neural retriever)를 통해 이 메모리에 접근한다.
-
RAG의 주요 장점 및 기여
RAG는 지식 집약적인(knowledge-intensive) 태스크에서 뛰어난 성능을 보인다. 특히 3개의 공개 도메인 QA 태스크에서 SOTA(최고 성능)를 달성했다.
언어 생성 태스크에서는 기존의 파라미터 기반 모델보다 더 구체적이고, 다양하며, 사실에 기반한(specific, diverse and factual) 언어를 생성한다.
외부 지식 소스에 접근하므로, 사람이 외부 지식 없이는 수행하기 어려운 태스크 해결에 큰 이점을 제공한다.
Methods
RAG는 입력 시퀀스()를 사용하여 텍스트 문서()를 검색하고, 이를 추가적인 맥락(context)으로 활용하여 타겟 시퀀스()를 생성하는 모델이다.
여기서 핵심은 검색된 문서()를 직접 관찰할 수 없는 잠재 변수(latent variable)로 취급하고, 이 변수를 추론 과정에서 소거(marginalize)하는 확률적 접근 방식을 사용한다는 점이다.
RAG 모델링
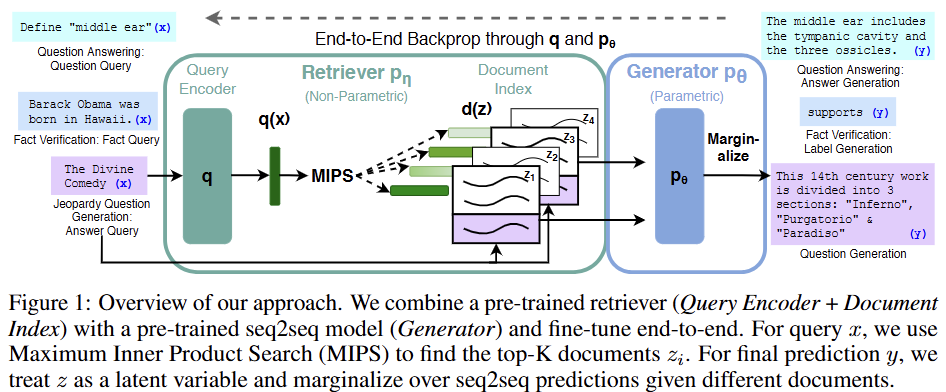
- RAG-Sequence Model
이 모델은 하나의 동일한 문서()를 사용하여 전체 답변 시퀀스()를 생성한다고 가정한다.
먼저 Retriever 를 이용해 상위 개의 관련 문서를 검색한다.
이후 Generator 는 각 문서()에 대해 전체 시퀀스()가 생성될 확률을 계산한다.
최종적으로 이 확률들을 각 문서의 검색 확률과 곱한 뒤 모두 더하여(marginalize), 최종 시퀀스 확률 를 구한다.
수식은 다음과 같다:
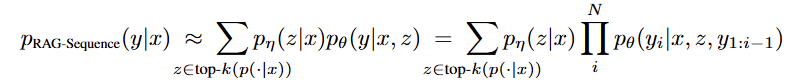
- RAG-Token Model
이 모델은 답변의 각 토큰()을 생성할 때마다 다른 문서()를 참조할 수 있다고 가정하여 유연성을 높였다.
RAG-Sequence와 같이 상위 개의 문서를 먼저 검색한다.
각 생성 단계()마다, Generator는 개의 각 문서에 대해 다음 토큰()이 나올 확률 분포를 계산한다.
이 분포들을 모든 문서에 대해 가중합(marginalize)하여 현재 단계의 최종 토큰 확률 분포를 얻고, 이 과정을 답변이 끝날 때까지 반복한다.
수식은 다음과 같다:
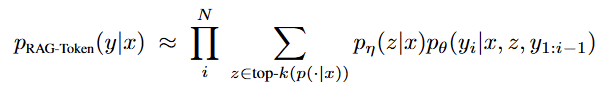
RAG 구성 요소
-
Retriever:
DPR (Dense Passage Retrieval)-
구조: 검색기 는 DPR에 기반한 Bi-encoder 아키텍처를 사용한다. 이는 문서 인코더()와 쿼리 인코더() 두 개의 독립된 BERT 모델로 구성된다.
-
검색 방식: 문서와 쿼리의 임베딩 벡터 간의 내적(inner product) 값이 가장 큰 상위 K개의 문서를 찾는다. 이는
MIPS (Maximum Inner Product Search)문제에 해당하며, FAISS와 같은 라이브러리를 통해 효율적으로 근사치를 계산할 수 있다. -
초기화: 본 논문에서는 TriviaQA와 Natural Questions 데이터셋으로 사전 학습된 DPR의 Bi-encoder를 가져와 Retriever를 초기화하고, 문서 인덱스를 구축한다. 이 문서 인덱스가 non-parametric memory 역할을 한다.
-
-
Generator:
BART-
모델: 생성기 는 400M개의 파라미터를 가진 사전 학습된 Seq2Seq Transformer 모델인 BART-large를 사용한다. BART의 파라미터는 parametric memory에 해당한다.
-
입력 방식: 검색된 내용()과 원본 입력()을 결합하기 위해, 두 텍스트를 단순히 이어붙여(concatenate) BART의 입력으로 제공한다.
-
학습 및 추론
-
학습 (Training)
-
목표: Retriever와 Generator는 End-to-End 방식으로 함께 학습된다. 학습 목표는 각 데이터 에 대해 음의 주변 로그 우도(negative marginal log-likelihood)를 최소화하는 것이다.
-
업데이트 방식: 학습 과정 전체에서 문서 인코더()와 이를 기반으로 구축된 인덱스는 고정시킨다. 오직
-
쿼리 인코더()와 BART Generator의 파라미터만 업데이트하여 학습 효율성을 높인다. 이는 주기적으로 전체 문서 인덱스를 다시 계산해야 하는 비용을 없애준다.
-
-
추론 (Decoding)
-
RAG-Token: 각 생성 단계의 확률 분포()가 일반적인 Seq2Seq 모델처럼 계산되므로, 표준 빔 서치(beam decoder)에 직접 적용하여 답변을 생성할 수 있다. -
RAG-Sequence: 전체 시퀀스()에 대해 확률이 계산되므로 일반적인 빔 서치를 한 번에 적용할 수 없다.대신, 검색된 각 문서()에 대해 개별적으로 빔 서치를 실행하여 여러 후보군()을 생성한다. 이후, 각 후보 답변의 최종 확률을 모든 문서에 대해 계산하고 이를 합산하여 순위를 매긴다. 계산 비용을 줄이기 위해 추가적인 전방 계산(forward pass)을 생략하는
Fast Decoding방식도 사용한다.
-
Experiments
1. 공통 실험 환경
- Non-parametric Knowledge Source: 모든 실험에서 단일 Wikipedia dump(2018년 12월 버전)를 비-파라미터 지식 소스로 사용했다.
- 문서 처리 및 인덱싱: Wikipedia의 각 글을 100단어 단위의 중복 없는 chunk로 분할하여 총 2,100만 개의 문서를 만들었다. 각 문서 chunk를 문서 인코더를 통해 임베딩한 후, 빠른 검색을 위해 FAISS를 사용하여 MIPS (Maximum Inner Product Search) 인덱스를 구축했다.
- 검색 문서 수 (K): 학습 시에는 각 쿼리당 상위 5개 또는 10개의 문서를 검색했다. 테스트 시에는 개발 데이터셋(dev data)을 통해 최적의 k값을 설정했다.
2. Task별 실험 설계
-
Open-domain Question Answering (QA)
-
목표: RAG가 정답을 직접 생성하는 방식이 기존의 추출형(extractive) QA나 검색 없이 파라미터 지식에만 의존하는 "Closed-Book" QA 방식과 어떻게 다른지 비교한다.
-
데이터셋: Natural Questions (NQ), TriviaQA (TQA), WebQuestions (WQ), CuratedTrec (CT)
-
학습 방식: 질문과 정답을 텍스트 쌍으로 간주하고, 정답의 negative log-likelihood를 직접 최소화하는 방식으로 RAG를 학습시켰다. WQ와 CT 같이 작은 데이터셋의 경우, NQ로 학습된 RAG 모델로 초기화하여 성능을 높였다.
-
-
Abstractive Question Answering
-
목표: RAG가 단순 추출을 넘어 자유로운 형태의 자연어 생성(NLG) 능력을 얼마나 갖추었는지 평가한다.
-
데이터셋: MSMARCO NLG task v2.1
-
특이사항: 데이터셋에서 제공하는 정답 관련 "gold passages"를 사용하지 않고, 오직 질문과 정답 쌍만 사용하여 open-domain 환경을 구성했다. 이로 인해 일부 질문은 Wikipedia만으로는 답변이 불가능할 수 있으며, 이런 경우 RAG는 파라미터 지식에 의존해 답변을 생성해야 한다.
-
-
Jeopardy Question Generation
-
목표: QA가 아닌 환경에서 RAG의 지식 집약적 생성 능력을 평가하기 위해, 정답(entity)을 보고 관련된 사실을 담은 질문(Jeopardy-style question)을 생성하는 까다로운 작업을 수행한다.
-
데이터셋: SearchQA 데이터셋의 분할
-
평가: 자동 평가로는 BLEU의 변형인 Q-BLEU-1을, 추가적으로 생성물의 사실성(factuality)과 구체성(specificity)을 측정하기 위한 인간 평가를 수행했다.
-
-
Fact Verification
-
목표: 생성(generation)이 아닌 분류(classification) 문제에 대한 RAG의 적용 가능성을 확인한다.
-
데이터셋: FEVER 데이터셋을 사용하며, 주어진 주장이 Wikipedia에 의해 '지지(supports)', '반박(refutes)', 혹은 '정보 부족(not enough info)'인지를 분류
-
학습 방식: 각 클래스 레이블을 단일 출력 토큰에 매핑하여 claim-class 쌍으로 직접 학습시켰다. 대부분의 기존 FEVER 연구와 달리, 어떤 증거 문서를 검색해야 하는지에 대한 검색 감독 정보(retrieval supervision)를 전혀 사용하지 않았다.
-
Results
Open-domain Question Answering
RAG는 NQ, TQA, WQ, CT 4개 QA 데이터셋 모두에서 새로운 SOTA(State-of-the-Art) 성능을 달성했다.
RAG는 검색 없이 파라미터 지식만 사용하는 "closed-book" 접근법(T5)과, 검색 후 정답을 추출하는 "open-book" 접근법(DPR) 모두를 능가했다.
RAG의 강점은 생성 능력에 있다. 검색된 어떤 문서에도 정답이 문자 그대로 포함되어 있지 않은 경우에도, RAG는 관련된 단서들을 종합하여 정답을 생성해낼 수 있었다.
NQ 데이터셋에서 이런 경우 11.8%의 정확도를 기록했으며, 이는 추출 기반 모델이라면 0%를 기록할 상황이다.
Abstractive Question Answering
MS-MARCO NLG 태스크에서 RAG-Sequence 모델은 BART보다 Bleu 점수와 Rouge-L 점수 모두 2.6점 높았다.
정성적으로 평가했을 때, RAG 모델은 BART에 비해 환각(hallucinate) 현상이 적고 사실적으로 더 정확한 텍스트를 생성하는 경향을 보였다.
Jeopardy Question Generation
자동 평가 지표인 Q-BLEU-1에서 RAG 모델들이 BART를 능가했다.
인간 평가에서 압도적인 우위를 보였다. 평가자들은 RAG가 BART보다 더 사실적(Factual)이라고 응답한 비율이 42.7%로, 그 반대(7.1%)보다 훨씬 높았다. 또한 더 구체적(Specific)이라는 응답도 37.4%로, 그 반대(16.8%)보다 높았다.
RAG-Token 모델은 여러 문서의 내용을 조합하는 능력이 뛰어났다. 예를 들어 "헤밍웨이"에 대한 질문 생성 시, 한 문서에서 "The Sun Also Rises" 정보를, 다른 문서에서 "A Farewell to Arms" 정보를 가져와 하나의 답변으로 합쳤다. 이는
non-parametric memory(외부 지식)가 parametric memory(내부 지식)에 저장된 특정 지식을 효과적으로 이끌어내는 사례를 보여준다.
Fact Verification
FEVER 데이터셋에서 RAG는 검색할 증거에 대한 별도의 감독(supervision) 없이도 복잡한 파이프라인으로 구성된 SOTA 모델의 성능에 근접했다 (3-way 분류에서 4.3% 이내 차이).
RAG가 검색한 문서와 FEVER 데이터셋의 정답 증거(gold evidence) 간의 일치율을 분석한 결과, 상위 10개로 검색된 문서 내에 정답 증거가 포함된 경우가 90%에 달해, 검색 메커니즘이 효과적으로 작동함을 확인했다.
Additional Results
- 생성 다양성 (Generation Diversity): RAG 모델, 특히 RAG-Sequence는 BART보다 훨씬 더 다양한 n-gram을 사용하여 덜 반복적이고 다채로운 문장을 생성했다.
- 검색기 Ablation (Retrieval Ablations): Retriever를 파인튜닝하는 것이 고정된 Retriever를 사용하는 것보다 모든 태스크에서 더 좋은 성능을 보였다. 또한 RAG의 dense retriever(DPR)가 단어 빈도 기반의 BM25 검색기보다 대부분의 태스크에서 우수했다.
- 인덱스 교체 (Index hot-swapping): RAG의 가장 큰 장점 중 하나로, 모델 재학습 없이 문서 인덱스만 교체하여 지식을 업데이트할 수 있음을 증명했다. 2016년 Wikipedia 인덱스와 2018년 인덱스를 각각 사용하여 해당 연도의 세계 지도자에 대해 질문했을 때, 각 인덱스는 자신의 시점에 맞는 정답을 높은 정확도(68-70%)로 생성했지만, 시점이 맞지 않을 경우 정확도가 급격히 하락했다(4-12%).
- 검색 문서 수(K)의 영향: 테스트 시 검색 문서 수를 늘리면 RAG-Sequence의 QA 성능은 꾸준히 향상되었지만, RAG-Token은 K=10에서 성능이 정점을 찍고 이후 하락하는 경향을 보였다.
Related Work & Discussion
Related Works
- Single-Task Retrieval: 기존 연구들은 QA, 팩트 체크, 대화 등 개별 NLP 태스크에 검색(retrieval)을 도입하여 성능을 향상시키는 데 집중했다. 반면, RAG는 여러 태스크에 범용적으로 적용할 수 있는 단일 검색 기반 아키텍처를 제안함으로써 이전의 성공 사례들을 통합하고 일반화했다.
- General-Purpose Architectures: T5, BART와 같은 연구는 검색 기능 없이 단일 사전 학습 모델로 다양한 태스크를 해결하는 데 성공했다. RAG는 이러한 범용 아키텍처에 학습 가능한 검색 모듈(retrieval module)을 추가하여 그 가능성을 더욱 확장했다.
- Learned Retrieval: 강화학습이나 잠재 변수 접근법을 사용해 특정 다운스트림 태스크에 맞춰 검색 모듈을 최적화하는 연구들이 있었다. RAG는 이러한 접근법을 단일 태스크가 아닌 다양한 태스크에 성공적으로 파인튜닝할 수 있음을 보여주었다.
- Memory-based Architectures: RAG의 문서 인덱스는 Memory Network와 유사한 외부 메모리로 볼 수 있다. 하지만 RAG의 핵심적인 차별점은 메모리가 분산된 표현(distributed representations)이 아닌 사람이 읽을 수 있는 원본 텍스트(raw text)로 구성된다는 점이다. 이 덕분에 모델의 판단 근거를 해석하기 용이하고(interpretability), 사람이 직접 문서를 편집하여 모델의 지식을 동적으로 업데이트(human-writable)할 수 있다.
- Retrieve-and-Edit Approaches: 유사한 예시를 검색해 수정하는 '검색 후 편집' 방식과 유사점도 있지만, RAG는 하나의 예시를 가볍게 편집하는 것보다 여러 검색 결과의 콘텐츠를 종합(aggregating content)하는 데 더 중점을 둔다는 차이가 있다.
Discussion
본 논문은 파라미터 메모리와 비-파라미터 메모리를 결합한 하이브리드 생성 모델인 RAG를 제시하고 그 효과를 입증했다.
- 주요 성과 요약: RAG 모델은 Open-domain QA에서 SOTA 성능을 달성했으며, 순수 파라미터 기반 모델인 BART보다 더 사실적이고 구체적인 텍스트를 생성함을 인간 평가를 통해 확인했다.
- 검색 컴포넌트의 유효성: 학습 가능한 검색 컴포넌트의 효과를 검증했으며, 모델 재학습 없이 인덱스를 교체(hot-swapped)하는 것만으로 지식을 업데이트할 수 있음을 보여주었다.
- 향후 연구 방향: 두 컴포넌트(Retriever와 Generator)를 처음부터 함께 사전 학습(jointly pre-trained)하는 연구가 유망할 수 있다고 제안했다.
- 연구의 의의: 본 연구는 파라미터 메모리와 비-파라미터 메모리가 어떻게 상호작용하고 효과적으로 결합될 수 있는지에 대한 새로운 연구 방향을 열었으며, 다양한 NLP 태스크에 적용될 수 있는 가능성을 보여주었다.
