Qwen3-Next가 출시되었다!
Qwen 3 나온지 얼마나 됐다고;; 매드맥스 마냥 중국발 ai 신기술 폭주중...
그래서 오늘은 논문은 아니지만 Qwen에서 업로드한 블로그 포스팅을 잠깐 훑어보려고 한다.
Qwen3-Next

Introduction
본 논문은 Context Length Scaling과 Total Parameter Scaling이 대규모 모델의 미래에 있어 핵심 동향이라고 본다. long-context 및 large-parameter 설정에서 학습 및 추론 효율성을 더욱 향상시키기 위해, Qwen3-Next라는 새로운 모델 아키텍처를 설계했다.
Qwen3의 MoE 구조와 비교하여 Qwen3-Next는 하이브리드 어텐션 메커니즘(hybrid attention mechanism), 고도로 희소한 MoE(highly sparse Mixture-of-Experts) 구조, 학습 안정성을 위한 최적화, 그리고 더 빠른 추론을 위한 멀티 토큰 예측 메커니즘(multi-token prediction mechanism) 등 몇 가지 주요 개선 사항을 도입했다.
이 새로운 아키텍처를 기반으로 Qwen3-Next-80B-A3B-Base 모델을 학습시켰다. 이 모델은 800억 개의 파라미터를 가졌지만 추론 중에는 30억 개의 파라미터만 활성화된다.
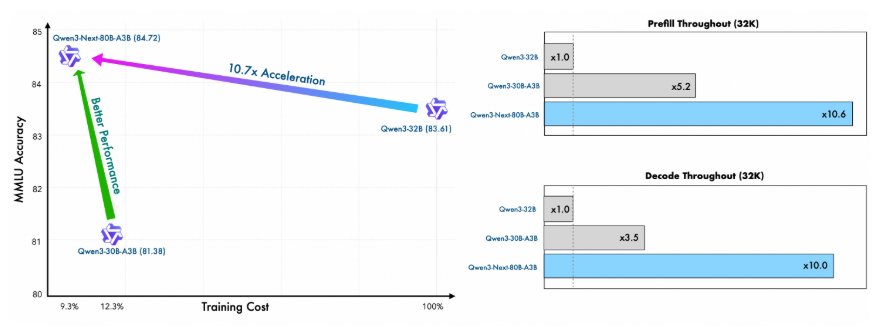
이 기본 모델은 dense Qwen3-32B 모델과 비슷하거나 약간 더 나은 성능을 달성하면서도, 학습 비용(GPU hours)은 10% 미만으로 사용한다. 추론 시, 특히 32K 토큰 이상의 context length에서는 10배 이상 높은 처리량을 제공하여 학습과 추론 모두에서 극도의 효율성을 달성한다.
Qwen3-Next-80B-A3B-Base를 기반으로 두 가지 후속 학습 버전인 Qwen3-Next-80B-A3B-Instruct와 Qwen3-Next-80B-A3B-Thinking을 개발하고 출시했다.
본 논문은 하이브리드 어텐션과 고희소성 MoE 아키텍처로 인해 발생하는 강화 학습(RL) 훈련에서의 오랜 안정성 및 효율성 문제를 해결했다. 이를 통해 RL 훈련 속도와 최종 성능 모두에서 개선을 이뤘다.
Qwen3-Next-80B-A3B-Instruct는 주력 모델인 Qwen3-235B-A22B-Instruct-2507과 비슷한 성능을 보이며, 최대 256K 토큰의 초장문 context를 요구하는 작업에서 뚜렷한 이점을 보여준다.
Qwen3-Next-80B-A3B-Thinking은 복잡한 추론 작업에서 뛰어나며, Qwen3-30B-A3B-Thinking-2507 및 Qwen3-32B-Thinking과 같은 고비용 모델을 능가한다.
또한 여러 벤치마크에서 비공개 소스 모델인 Gemini-2.5-Flash-Thinking을 앞서고, 최상위 모델인 Qwen3-235B-A22B-Thinking-2507의 성능에 근접한다.
Qwen3-Next는 이미 Hugging Face와 ModelScope에 출시되었다. 또한, 누구나 Alibaba Cloud Model Studio와 NVIDIA API Catalog를 통해 Qwen3-Next 서비스를 사용할 수 있다.
Key Features
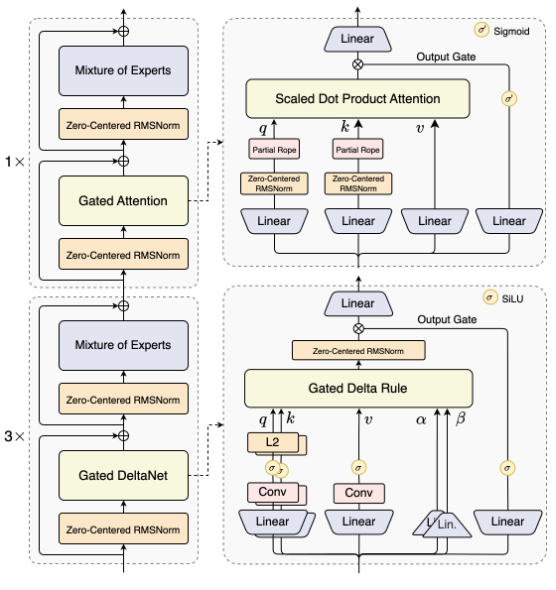
Hybrid Architecture: Gated DeltaNet + Gated Attention
Linear attention은 표준 어텐션의 이차 복잡도(quadratic complexity)를 해결하고 long context에 더 효율적이다. 그러나 linear attention만 사용하거나 표준 어텐션만 사용하는 것에는 한계가 있다. Linear attention은 빠르지만 recall 능력이 약하고, 표준 어텐션은 추론 시 비용이 많이 들고 느리다.
체계적인 실험을 통해 Gated DeltaNet이 Sliding Window Attention이나 Mamba2와 같은 일반적으로 사용되는 방법보다 더 강력한 in-context learning 능력을 제공한다는 것을 발견했다.
Gated DeltaNet과 표준 어텐션을 3:1 비율(75%의 레이어는 Gated DeltaNet 사용, 25%는 표준 어텐션 유지)로 혼합했을 때, 모델은 어떤 단일 아키텍처보다 일관되게 뛰어난 성능을 보이며, 더 나은 성능과 높은 효율성을 모두 달성했다.
표준 어텐션 레이어에는 다음과 같은 몇 가지 개선 사항을 추가했다:
-
이전 연구의
output gating mechanism을 채택하여 어텐션의 low-rank 문제를 감소 -
어텐션 헤드당 차원을 128에서 256으로 증가
-
rotary position encoding을 위치 차원의 첫 25%에만 적용하여 더 긴 시퀀스에 대한 외삽(extrapolation) 능력을 향상
Ultra-Sparse MoE: Activating Only 3.7% of Parameters
Qwen3-Next는 고도로 희소한 MoE 설계(highly sparse MoE design)를 사용한다: 총 800억 개의 파라미터를 가지지만, 추론 단계마다 약 30억 개만 활성화된다.
실험에 따르면, global load balancing을 사용할 경우 활성화되는 expert 수를 고정한 채 총 expert 파라미터 수를 늘리면 학습 손실(training loss)이 꾸준히 감소하는 것으로 나타났다.
Qwen3의 MoE(총 128개 expert, 8개 routed)와 비교하여, Qwen3-Next는 총 512개의 expert로 확장했으며, 10개의 routed expert와 1개의 shared expert를 결합하여 성능 저하 없이 리소스 사용을 극대화한다.
Training-Stability-Friendly Designs
Attention output gating 메커니즘은 Attention Sink 및 Massive Activation과 같은 문제를 제거하여 모델 전반의 수치적 안정성을 보장하는 데 도움이 되는 것으로 나타났다.
Qwen3에서는 QK-Norm을 사용했지만, 일부 layer norm 가중치가 비정상적으로 커지는 것을 발견했다. 이를 해결하고 안정성을 더욱 향상시키기 위해, Qwen3-Next는 Zero-Centered RMSNorm을 채택하고, norm 가중치에 weight decay를 적용하여 무한한 성장을 방지한다.
또한 초기화 중에 MoE router 파라미터를 정규화하여, 훈련 초기에 각 expert가 편향 없이 선택되도록 보장한다. 이는 무작위 초기화로 인한 노이즈를 줄인다.
이러한 안정성에 초점을 맞춘 설계는 소규모 실험을 더 신뢰할 수 있게 만들고 대규모 훈련이 원활하게 실행되도록 돕는다.
Multi-Token Prediction
Qwen3-Next는 native Multi-Token Prediction (MTP) 메커니즘을 도입한다. 이는 Speculative Decoding에 대한 높은 수락률을 가진 MTP 모듈을 생성할 뿐만 아니라 전반적인 성능도 향상시킨다.
특히, Qwen3-Next는 MTP의 다중 단계 추론(multi-step inference) 성능을 최적화한다. 이는 학습과 추론 간의 일관성을 유지하는 다중 단계 훈련(multi-step training)을 통해 실제 시나리오에서 Speculative Decoding의 수락률을 더욱 향상시킨다.
Pre-training
- Pretraining Efficiency & Inference Speed
Qwen3-Next는 Qwen3의 36T 토큰 사전 학습 말뭉치에서 균일하게 샘플링된 15T 토큰의 서브셋으로 학습된다.
이 모델은 Qwen3-30A-3B에 필요한 GPU hours의 80% 미만을 사용하고, Qwen3-32B의 계산 비용의 9.3%만을 사용하면서도 더 나은 성능을 달성한다. 이는 뛰어난 학습 효율성과 가치를 보여준다.
- Inference stage
하이브리드 아키텍처 덕분에 Qwen3-Next는 추론에서도 뛰어난 성능을 보인다:
-
Prefill Stage: 4K context length에서 throughput은 Qwen3-32B보다 거의 7배 높다. 32K를 초과하면 10배 이상 빠름 -
Decode Stage: 4K context에서 throughput은 거의 4배 높다. 32K를 초과하더라도 여전히 10배 이상의 속도 이점을 유지
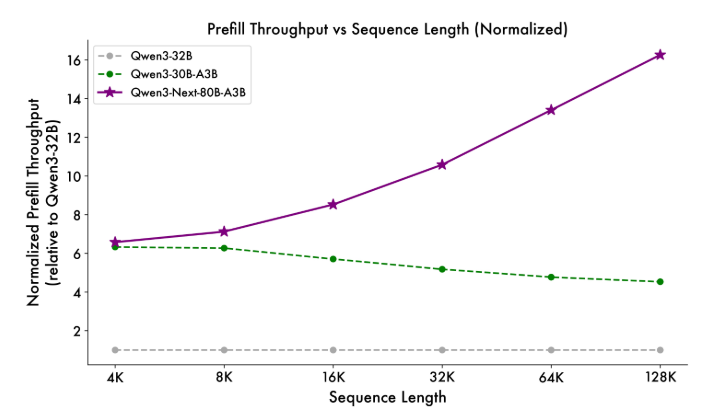
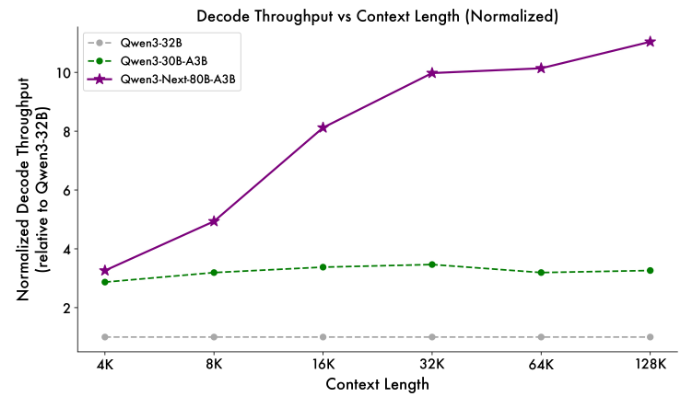
- Base Model Performance
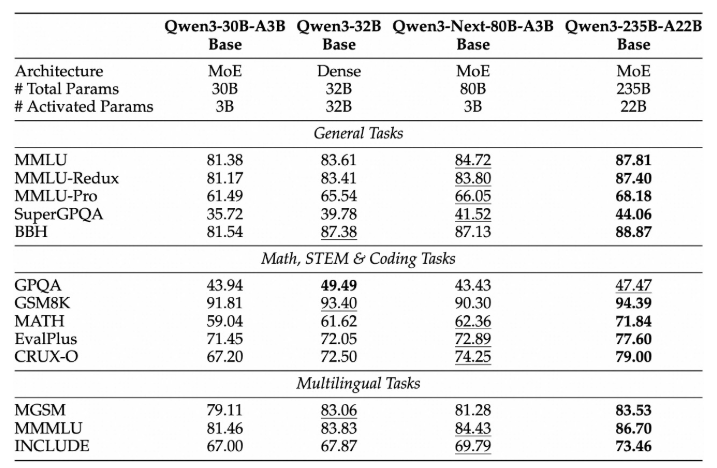
Qwen3-Next-80B-A3B-Base는 Qwen3-32B-Base가 사용하는 non-embedding 파라미터의 1/10만 활성화하지만, 대부분의 벤치마크에서 더 뛰어난 성능을 보이며 Qwen3-30B-A3B를 크게 능가한다. 이는 탁월한 효율성과 강력한 성능을 입증한다.
Post-trainig
- Instruct Model Performance
Qwen3-Next-80B-A3B-Instruct는 Qwen3-30B-A3B-Instruct-2507과 Qwen3-32B-Non-thinking을 크게 능가하며, 주력 모델인 Qwen3-235B-A22B-Instruct-2507에 거의 필적하는 결과를 달성한다.
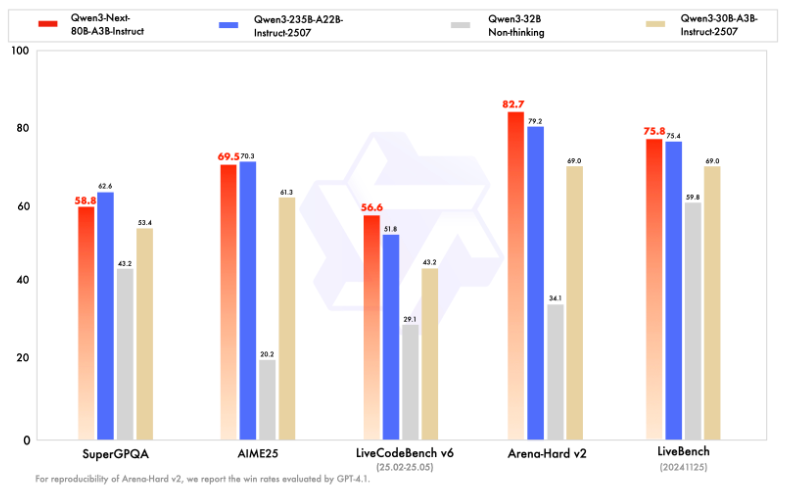
RULER에서 Qwen3-Next-80B-A3B-Instruct는 모든 길이에서 (더 많은 attention layer를 가진) Qwen3-30B-A3B-Instruct-2507을 능가하며, 256K context 내에서는 (전체적으로 더 많은 layer를 가진) Qwen3-235B-A22B-Instruct-2507마저도 능가한다.
이는 long-context 작업에 대한 Gated DeltaNet + Gated Attention 하이브리드 설계의 강력함을 입증한다.

- Thinking Model Performance
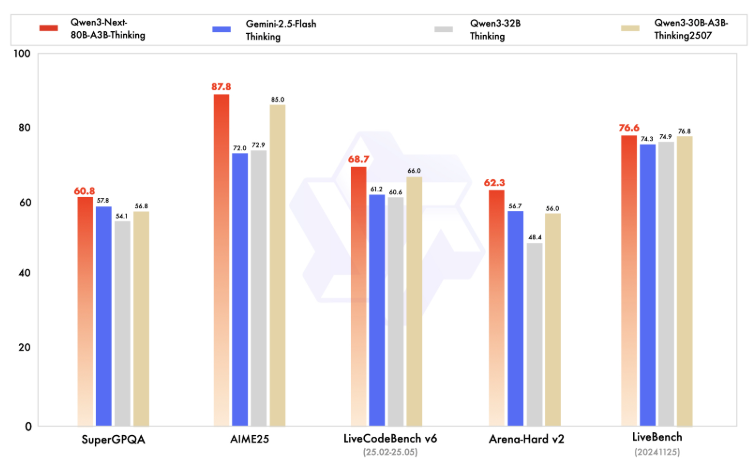
Qwen3-Next-80B-A3B-Thinking은 Qwen3-30B-A3B-Thinking-2507 및 Qwen3-32B-Thinking과 같은 고비용 모델보다 뛰어난 성능을 보인다. 이 모델은 여러 벤치마크에서 closed-source 모델인 Gemini-2.5-Flash-Thinking을 능가하며, 주요 지표에서 최신 주력 모델인 Qwen3-235B-A22B-Thinking-2507에 근접한다.
Summary
Qwen3-Next는 모델 아키텍처의 중요한 발전을 나타내며, linear attention과 attention gate를 포함한 어텐션 메커니즘의 혁신과 MoE 설계의 희소성 증가를 도입했다.
Qwen3-Next-80B-A3B는 thinking 및 non-thinking 모드 모두에서 더 큰 모델인 Qwen3-235B-A22B-2507과 동등한 성능을 제공하면서, 특히 long-context 시나리오에서 훨씬 빠른 추론 속도를 제공한다.
이번 출시를 통해 오픈소스 커뮤니티가 최첨단 아키텍처 발전과 함께 진화할 수 있도록 지원하는 것을 목표로 한다.
앞으로 이 아키텍처를 더욱 개선하여 전례 없는 수준의 지능과 생산성을 목표로 하는 Qwen3.5를 개발할 것이다.
