💡 데이터 불균형 해결법
데이터 불균형을 해결하는 방법에는 대표적으로 undersampling(과소표집)과 oversampling(과대표집) 방법이 있다.
undersampling
- 다수 클래스 데이터를 일부만 선택하여 데이터의 비율을 맞춤
- 데이터의 소실이 매우 크고, 중요한 정상 데이터를 잃게 될 수 있음
oversampling
- 소수 클래스 데이터를 복제 또는 생성하여 데이터의 비율을 맞춤
- 정보가 손실되지 않는다는 장점이 있으나, 과적합(over-fitting)을 초래할 수 있음
본 포스팅에서는 oversampling 주요 기법을 다루려고 하는데, SMOTE와 ADASYN이 이에 해당한다.
🔍 방법론 비교
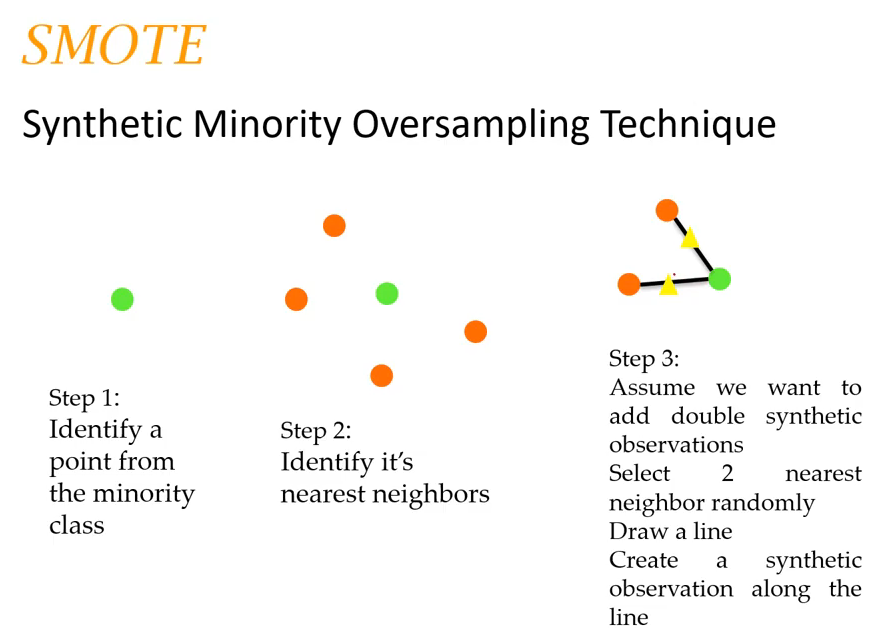
1. SMOTE(Synthetic Minortiy Over-sampling Technique)
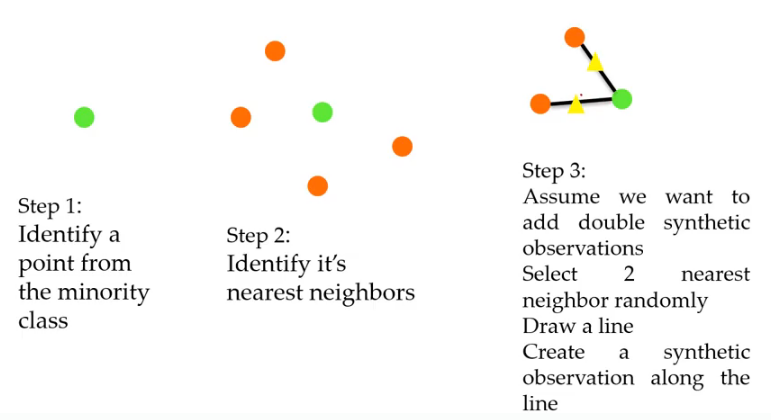
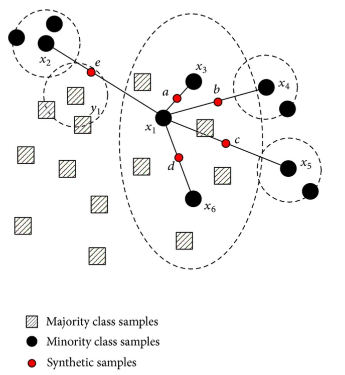
소스 클래스의 중심 데이터와, 그 주변 데이터 사이 가상의 직선을 만들고, 그 위에 데이터를 생성한다.
2. Borderline-SMOTE
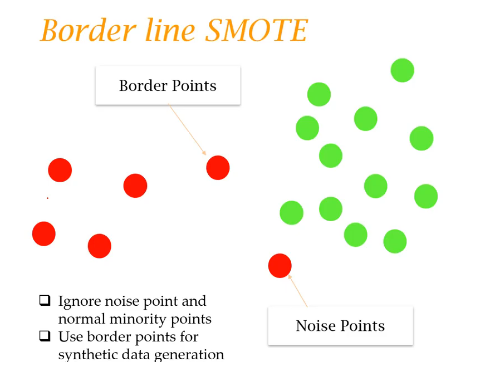
noise point와 정상적인 소수 데이터를 무시하고, 경계점의(borderline) 데이터를 사용하여 가상 데이터를 생성한다.
3. ADASYN
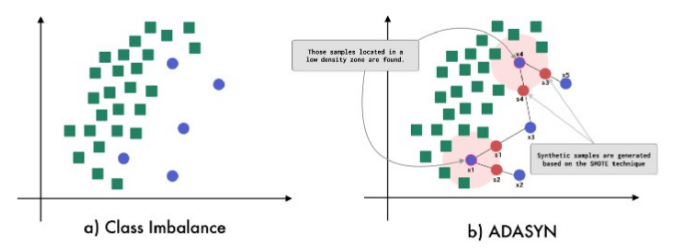
모든 소수 클래스에서 다수 클래스의 관측 비율을 계산(밀도를 고려)하여 SMOTE를 적용함으로써, 데이터가 더 큰 분산을 갖도록 한다(더 고르게 분포, scatter 된 형식)
👉 적용해 보기
준비물 : 불균형 데이터
나는 실무 데이터를 활용했고 oversampling 전 origin dataset은 2개의 클래스(0, 1)로 구분된 데이터에서 0과 1이 3:1 비율로 분포하고 있었다.
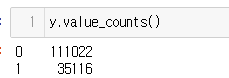
엄청 드라마틱하게 imbalance 한 건 아니지만~ 실무에서 활용했을 때 유용한지가 궁금했기 때문에..
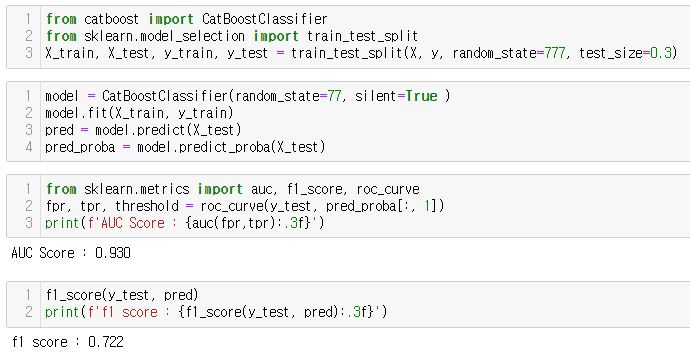
부스팅 알고리즘을 활용하여 분류한 결과, AUC가 0.93, F1이 0.72로 F1이 좋지 않은 결과를 낸다.
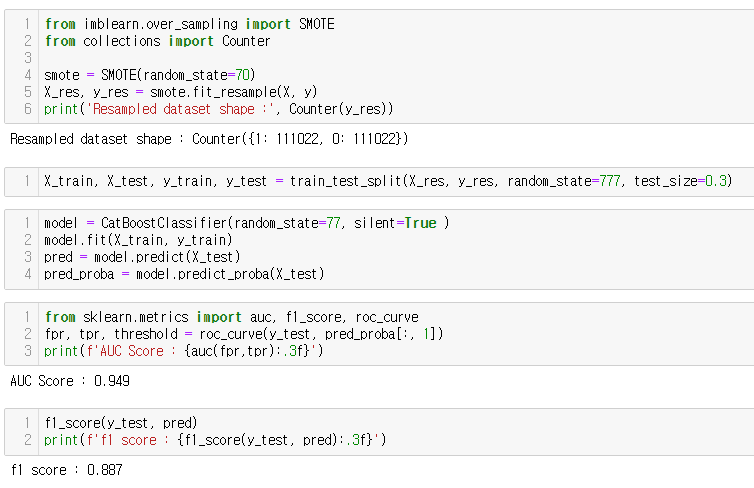
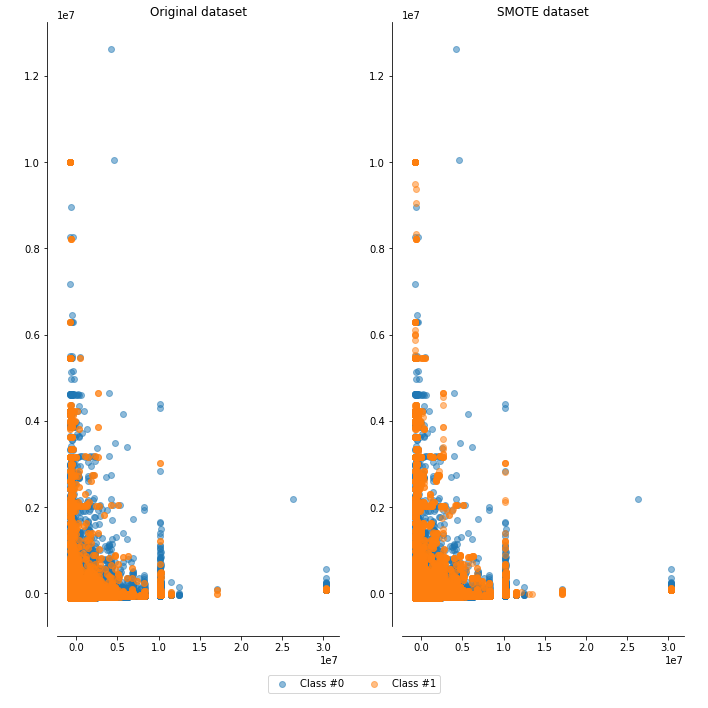
1. SMOTE
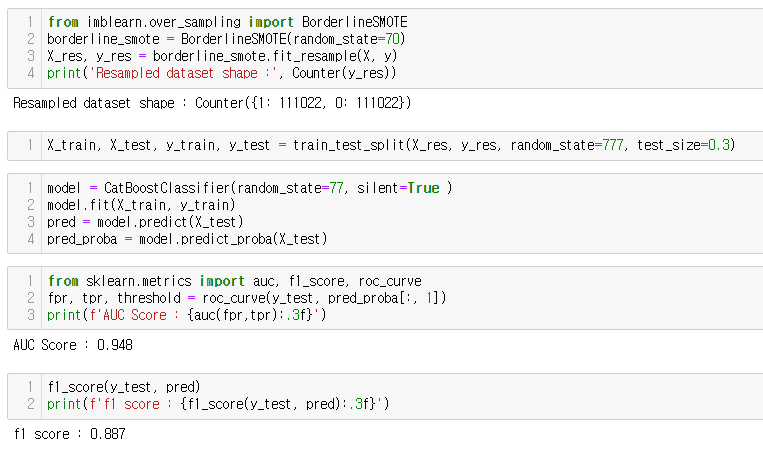
2. borderline-SMOTE
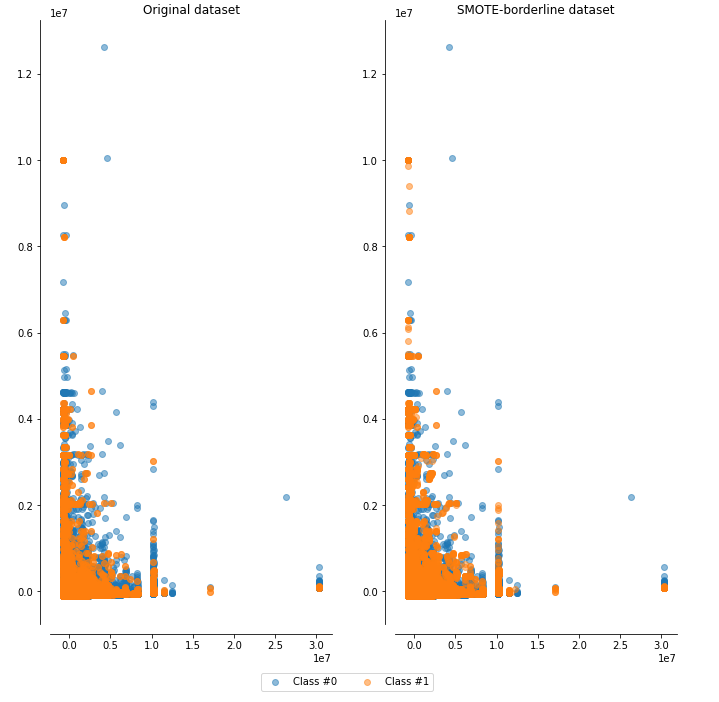
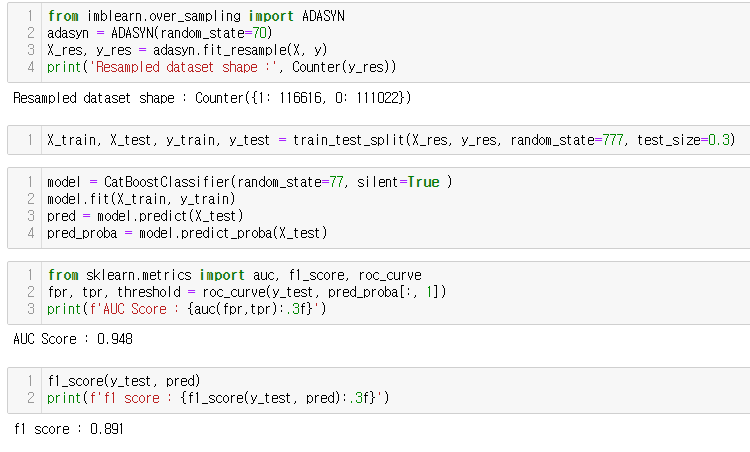
3. ADASYN
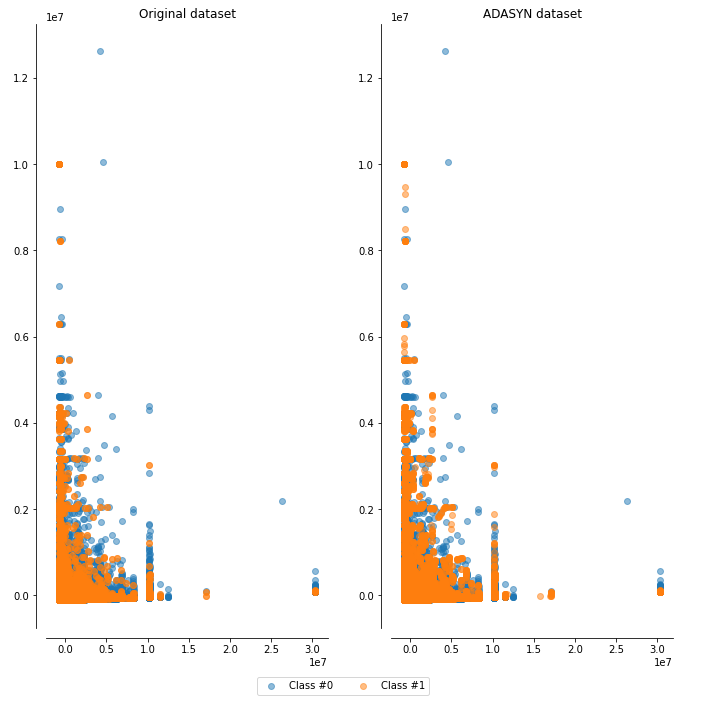
결과 비교
이 데이터셋에서는 방법론 별로 성능에 큰 차이는 없었지만, original dataset과 비교했을때 성능이 향상됨을(특히 F1-score) 알 수 있다.
📚 reference

춘식이랑 함께하는 개발일지.. 그런데 이제 먼작귀를 곁들인