순환 신경망(Recurrent Neural Network)이란 ?
RNN은 시간적으로 연속성이 있는 데이터를 처리하기 위해 고안된 인공 신경망이다. RNN의 Recurrent는 이전 은닉층이 현재 은닉층의 입력이 되면서 반복되는 순환 구조를 갖는다는 의미이다. RNN이 기존 네트워크와 다른 점은 기억(memory)을 갖는다는 것이다.
이 때 기억이란 현재까지 입력된 데이터를 요약한 정보이다. 즉, 새로운 입력이 네트워크로 들어올 때마다 기억이 조금씩 수정되며, 최종으로 남겨진 기억은 모든 입력 전체를 요약한 정보가 된다.
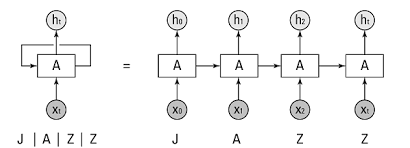
그림과 같이 첫 번째 입력()이 들어오면 첫 번째 기억()이 생성되고, 두 번째 입력()이 들어오면 기존 기억()과 새로운 입력을 참고하여 새 기억()을 만든다. 입력 길이만큼 이 과정을 반복할 수 있다. 즉, RNN은 외부 입력과 자신의 이전 상태를 입력받아 현 상태를 갱신한다.
RNN은 은닉층 노드들이 연결되어 이전 단계 정보를 은닉층 노드에 저장할 수 있도록 구성한 신경망이다. 다음 그림과 같이 에서 을 얻고, 다음 단계에서 와 를 사용하여 과거 정보와 현재 정보를 모두 반영한다. 또한, 와 의 정보를 이용하여 과거와 현재 정보를 반복해서 반영하는데, 이러한 구조가 다음 그림의 오른쪽 부분과 같다.
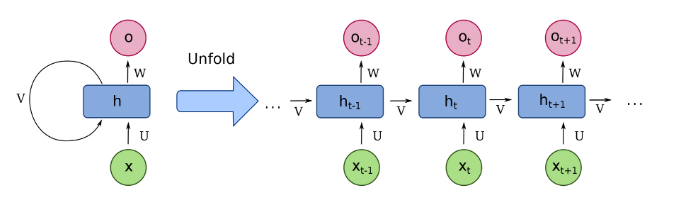
RNN에서는 입력층, 은닉층, 출력층 외에 가중치를 세 개(, , ) 가진다. 는 입력층에서 은닉층으로 전달되는 가중치이고, 는 시점의 은닉층에서 시점의 은닉층으로 전달되는 가중치다. 또한, 는 은닉층에서 출력층으로 전달되는 가중치다. 3개의 가중치(, , )는 모든 시점에 동일하다. 즉, 가중치를 공유한다.
🖨 t단계의 RNN 연산
은닉층
은닉층을 계산하기 위해서는 와 이 필요하다. 즉, 이전 은닉층X은닉층 → 은닉층 가중치+입력층 → 은닉층 가중치 X 현재 입력값으로 계산할 수 있으며 RNN에서 은닉층은 일반적으로 하이퍼볼릭 탄젠트 활성화 함수를 사용한다. 이를 수식으로 나타내면 다음과 같다.
출력층
출력층은 심층 신경망과 계산방법이 동일하다. 즉, 은닉층→ 출력층 가중치X현재 은닉층에 소프트맥스 함수를 적용한다. 이를 수식으로 나타내면 다음과 같다.
RNN의 오차(E)
RNN의 오차는 심층 신경망에서 전방향(feed-forward) 학습과 달리 각 단계(t)마다 오차를 측정한다. 즉, 각 단계마다 실제 값()와 예측 값()의 오차(평균제곱 오차, MSE)를 이용하여 측정한다.
RNN의 역전파
RNN에서 역전파는
BPTT(backpropagation through time)을 이용하여 모든 단계마다 처음부터 끝까지 역전파한다.오차는 각 단계(t)마다 오차를 측정하고 이전 단계로 전달되는데, 이를 BPTT라 한다. 즉, 3에서 구한 오차를 이용하여 가중치(, , ) 및 bias를 업데이트한다. 이 때 BPTT는 오차가 멀리 전파될 때(왼쪽으로 전파) 계산량이 많아지고 전파되는 양이 점차 적어지는 문제(
기울기 소멸문제, vanishing gradient)가 발생한다. 기울기 소멸 문제를 극복하기 위해 오차를 몇 단계까지만 전파하는 생략된 BPTT(turncated BPTT)를 사용할 수도 있고, 보편적으로는 LSTM 또는 GRU를 많이 사용한다.
순환 신경망 구현(pytorch)
import torch
import torchtext
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import timestart = time.time()
TEXT = torchtext.legacy.data.Field(lower=True, fix_length=200, batch_first=False)
LABEL = torchtext.legacy.data.Field(sequential=False)from torchtext.legacy import datasets
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL
print(vars(train_data.examples[0]))
import string
for example in train_data.examples :
text = [x.lower() for x in vars(example)['text']]
text = [x.replace("<br", "") for x in text]
text = [''.join(c for c in s if c not in string.punctuation) for s in text]
text = [s for s in text if s]
vars(example)['text'] = text
for example in test_data.examples :
text = [x.lower() for x in vars(example)['text']]
text = [x.replace("<br", "") for x in text]
text = [''.join(c for c in s if c not in string.punctuation) for s in text]
text = [s for s in text if s]
vars(example)['text'] = text텍스트 전처리
import random
train_data, valid_data = train_data.split(random_state=random.seed(0), split_ratio=0.8)
print(f'Number of training example : {len(train_data)}')
print(f'Number of validation example : {len(valid_data)}')
print(f'Number of testing example : {len(test_data)}')# 단어 집합
TEXT.build_vocab(train_data, max_size=10000, min_freq=10, vectors=None)
LABEL.build_vocab(train_data)
print(f"Unique tokens in TEXT vocabulary: {len(TEXT.vocab)}")
print(f"Unique tokens in LABEL vocabulary: {len(LABEL.vocab)}")데이터셋을 분리하여 로드한다.
RNN Cell
class RNNCell_Encoder(nn.Module) : # 워드 임베딩 및 RNN cell 정의
def __init__(self, input_dim, hidden_size) :
super(RNNCell_Encoder, self).__init__()
self.rnn = nn.RNNCell(input_dim, hidden_size) # rnn cell 구현
def forward(self, inputs) :
bz = inputs.shape[1]
ht = torch.zeros((bz, hidden_size)).to(device) # 현재 상태(h_t)
for word in inputs : # word : 현재 입력 벡터(x_t)
ht = self.rnn(word, ht) # ht : 이전 상태(h_t-1)
return ht
class Net(nn.Module) :
def __init__(self) :
super(Net, self).__init__()
self.em = nn.Embedding(len(TEXT.vocab.stoi), embedding_dim) # 임베딩
self.rnn = RNNCell_Encoder(embedding_dim, hidden_size)
self.fc1 = nn.Linear(hidden_size, 256)
self.fc2 = nn.Linear(256, 3)
def forward(self, x) :
x = self.em(x)
x = self.rnn(x)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return xRNN cell을 정의한다.
model = Net()
model.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)옵티마이저, 손실 함수 정의
def training(epoch, model, trainloader, validloader) :
correct = 0
total = 0
running_loss = 0
model.train()
for b in trainloader :
x, y = b.text, b.label
x, y = x.to(device), y.to(device)
y_pred = model(x)
loss = loss_fn(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad() :
y_pred = torch.argmax(y_pred, dim=1)
correct += (y_pred == y).sum().item()
total += y.size(0)
running_loss += loss.item()
epoch_loss = running_loss / len(trainloader.dataset)
epoch_acc = correct / total
valid_correct = 0
valid_total = 0
valid_running_loss = 0
model.eval()
with torch.no_grad() :
for b in validloader :
x, y = b.text, b.label
x, y =x.to(device), y.to(device)
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
valid_correct += (y_pred == y).sum().item()
valid_total += y.size(0)
valid_running_loss += loss.item()
epoch_valid_loss = valid_running_loss / len(validloader.dataset)
epoch_valid_acc = valid_correct / valid_total
print('epoch :', epoch,
'loss :', round(epoch_loss, 3),
'accuarcy :', round(epoch_acc, 3),
'valid_loss :', round(epoch_valid_loss,3),
'valid_accuracy :', round(epoch_valid_acc, 3))
return epoch_loss, epoch_acc, epoch_valid_loss, epoch_valid_acc모델 학습 함수를 정의한다.
epochs = 5
train_loss = []
train_acc = []
valid_loss = []
valid_acc = []
for epoch in range(epochs) :
epoch_loss, epoch_acc, epoch_valid_loss, epoch_valid_acc = training(
epoch, model, train_iterator, valid_iterator)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
valid_loss.append(epoch_valid_loss)
valid_acc.append(epoch_valid_acc)
end = time.time()
print(end-start)
학습을 진행한다.
# prediction
def evaluate(epoch, model, testloader) :
test_correct = 0
test_total = 0
test_running_loss = 0
model.eval()
with torch.no_grad() :
for b in testloader :
x, y = b.text, b.label
x, y = x.to(device), y.to(device)
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct += (y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_loss = test_running_loss / len(testloader.dataset)
epoch_test_acc = test_correct / test_total
print('epoch :', epoch,
'test_loss :', round(epoch_test_loss,3),
'test_accuracy :', round(epoch_test_acc, 3))
return epoch_test_loss, epoch_test_acc모델 평가 함수를 정의한다.
epoch = 5
test_loss = []
test_acc = []
for epoch in range(epoch) :
epoch_test_loss, epoch_test_acc = evaluate(epoch, model, test_iterator)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
end = time.time()
print(end-start)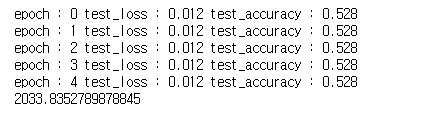
모델의 예측 결과를 확인한다.
RNN layer
start = time.time()
TEXT = torchtext.legacy.data.Field(sequential=True, batch_first=True, lower=True)
LABEL = torchtext.legacy.data.Field(sequential=False, batch_first=True)
from torchtext.legacy import datasets
train_data, test_data = datasets.IMDB.splits(TEXT ,LABEL)
train_data, valid_data = train_data.split(split_ratio=0.8)
TEXT.build_vocab(train_data, max_size=10000, min_freq=10, vectors=None)
LABEL.build_vocab(train_data)
BATCH_SIZE=100
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')데이터셋을 가져와 전처리 한다.
train_iterator, valid_iterator, test_iterator = torchtext.legacy.data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device)
vocab_size=len(TEXT.vocab)
n_classes = 2 데이터 분리, 변수 값 지정
# RNN network
class BasicRNN(nn.Module) :
def __init__(self, n_layers, hidden_dim, n_vocab, embed_dim, n_classes, dropout_p=0.2) :
super(BasicRNN, self).__init__()
self.n_layers = n_layers
self.embed = nn.Embedding(n_vocab, embed_dim)
self.hidden_dim = hidden_dim
self.dropout = nn.Dropout(dropout_p)
self.rnn = nn.RNN(embed_dim, self.hidden_dim, num_layers=self.n_layers,
batch_first=True)
self.out = nn.Linear(self.hidden_dim, n_classes)
def forward(self, x) :
x = self.embed(x)
h_0 = self._init_state(batch_size=x.size(0))
x, _ = self.rnn(x, h_0)
h_t = x[:, -1, :] # 가장 마지막 단어의 임베딩 값
self.dropout(h_t)
logit = torch.sigmoid(self.out(h_t))
return logit
def _init_state(self, batch_size=1) :
weight = next(self.parameters()).data # 모델 파라미터 저장
return weight.new(self.n_layers, batch_size, self.hidden_dim).zero_()RNN 네트워크를 정의한다.
model = BasicRNN(n_layers=1, hidden_dim=256, n_vocab=vocab_size,
embed_dim=128, n_classes=n_classes, dropout_p=0.5)
model.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)손실 함수, 옵티마이저 정의
# 모델 학습
def train(model, optimizer, train_iter) :
model.train()
for b, batch in enumerate(train_iter) :
x, y = batch.text.to(device), batch.label.to(device)
y.data.sub_(1)
optimizer.zero_grad()
logit = model(x)
loss = F.cross_entropy(logit, y)
loss.backward()
optimizer.step()
if b % 50 == 0 :
print(f'Train Epoch : {e} [{b*len(x)}/{len(train_iter.dataset)} ({100*b /len(train_iter):.0f}%)] \tLoss : {loss.item():.6f}')모델 학습 함수
def evaluate(model, val_iter) :
model.eval()
corrects, total, total_loss = 0, 0, 0
for batch in val_iter :
x, y = batch.text.to(device), batch.label.to(device)
y.data.sub_(1)
logit = model(x)
loss = F.cross_entropy(logit, y, reduction='sum')
total += y.size(0)
total_loss += loss.item()
corrects += (logit.max(1)[1].view(y.size()).data == y.data).sum()
avg_loss = total_loss / len(val_iter.dataset)
avg_accuracy = corrects / total
return avg_loss, avg_accuracy모델 평가 함수
BATCH_SIZE=100
lr=0.001
EPOCHS=5
for e in range(1, EPOCHS+1) :
train(model, optimizer, train_iterator)
val_loss, val_accuracy = evaluate(model, valid_iterator)
print(f'[EPOCH : {e}], Validation Loss : {val_loss:5.2f} | Validation Accuracy : {val_accuracy:5.2f}')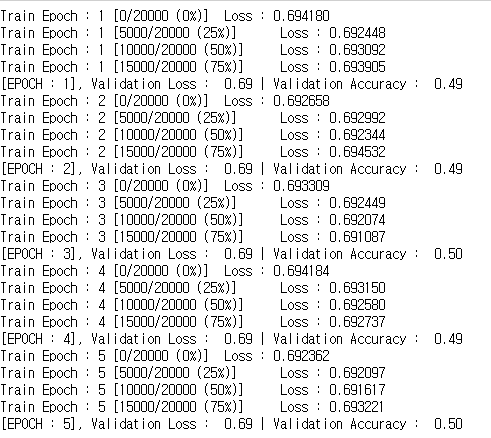
학습 및 평가
test_loss, test_acc = evaluate(model, test_iterator)
print(f'Test Loss : {test_loss:5.2f} | Test Accuracy : {test_acc:5.2f}')모델 예측
📚 reference
- (길벗) 딥러닝 파이토치 교과서 / 서지영 지음
- github
