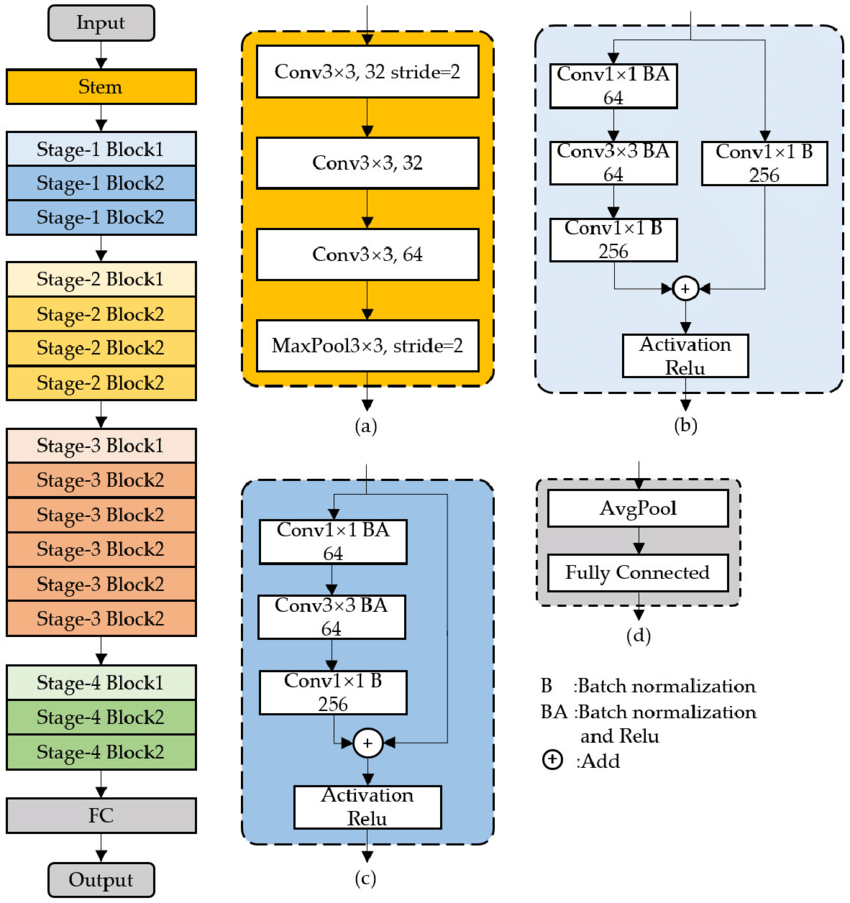
ResNet
ResNet은 깊어진 신경망을 효과적으로 학습하기 위한 방법으로, residual 개념을 고안한 모델이다. 네트워크 깊이가 깊어질수록 성능이 좋아지다가 어느 시점에서 오히려 성능이 나빠지는데, 이러한 문제 해결을 위해 residual block을 도입했다. residual block은 기울기가 잘 전파될 수 있도록 하는 일종의 shortcut(skip connection)을 만들어 준다.
block은 계층의 묶음, 즉 합성곱층을 하나의 블록으로 묶은 것이다. 다음 그림과 같이 색상별로 블록을 구분했는데, 이러한 계층이 하나의 residual block이다. 그리고 residual block을 여러 개 쌓은 것을 ResNet이라 한다.
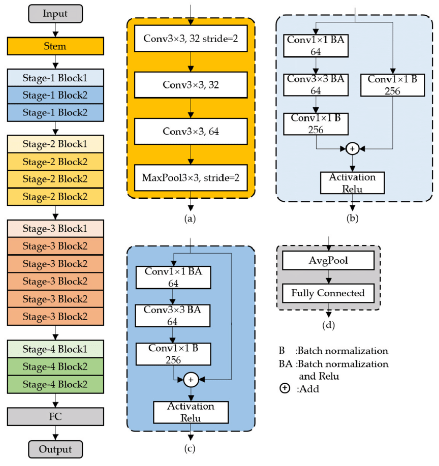
그러나 이러한 구조에서 계층의 깊이가 깊어질수록 파라미터가 무제한으로 커지게 된다. 이를 해결하기 위해 병목 블록(bottleneck block)을 둔다. ResNet34는 기본 블록(basic block)을 사용하고, ResNet50은 병목 블록을 사용한다. 기본 블록의 파라미터 수는 39.3216M인 반면, 병목 블록의 파라미터 수는 6.6932M이다. 병목 블록을 사용하면 깊이가 깊어짐에도 파라미터 수가 감소하는 효과를 줄 수 있다.
ResNet50의 합성곱층을 보면 ResNet34와 다르게 3X3 합성곱층 앞뒤로 1X1 합성곱층이 붙어 있는데, 1X1 합성곱층의 채널 수를 조절하며 차원을 줄였다 늘릴 수 있기 때문에 파라미터 수를 줄일 수 있는 것이다. 이러한 부분이 병목과 같다 하여 병목 블록이라 한다.
위 그림 (b), (c)를 보면 (+) 기호가 있는데(기본 블록과 병목 블록에서 모두 사용), 이를 identity mapping이라 한다. identity mapping이란 입력 x가 어떠한 함수를 통과하더라도 다시 x라는 형태로 출력되도록 하는 것이다.
또 다른 핵심 개념은 downsample이다. 다운샘플은 특성 맵(feature map) 크기를 줄이기 위한 것으로, 풀링과 같은 역할을 한다. 영역간 형태를 맞추지 않으면 아이덴티티 매핑을 할 수 없어, 아이덴티티에 대한 다운샘플이 필요하다.
ResNet은 기본적으로 VGG19의 구조를 뼈대로 하며, 이에 합성곱층을 추가해서 깊게 만든 후 숏컷을 추가하는 방식이다.
ResNet 구현
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as data
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
import matplotlib.pyplot as plt
import numpy as np
import copy
from collections import namedtuple
import os
import random
import time
import cv2
from torch.utils.data import DataLoader, Dataset
from PIL import Image
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')사용할 라이브러리 호출
class ImageTransform() :
def __init__(self, resize, mean, std) :
self.data_transform = {
'train' : transforms.Compose([
transforms.RandomResizedCrop(resize, scale=(0.5, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean, std)
]),
'val' : transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(resize),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
}
def __call__(self, img, phase) :
return self.data_transform[phase](img)이미지 데이터 전처리
# define variables
size = 224
mean = (0.485, 0.456, 0.456)
std = (0.229, 0.224, 0.225)
batch_size = 32변수 값을 정의한다.
cat_dir = r'../080289-main/chap06/data/dogs-vs-cats/Cat/'
dog_dir = r'../080289-main/chap06/data/dogs-vs-cats/Dog/'
cat_images_filepaths = sorted([os.path.join(cat_dir, f) for f in os.listdir(cat_dir)])
dog_images_filepaths = sorted([os.path.join(dog_dir, f) for f in os.listdir(dog_dir)])
image_filepaths = [*cat_images_filepaths, *dog_images_filepaths]
correct_images_filepaths = [i for i in image_filepaths if cv2.imread(i) is not None]random.seed(42)
random.shuffle(correct_images_filepaths)
train_images_filepaths = correct_images_filepaths[:400]
val_images_filepaths = correct_images_filepaths[400:-10]
test_images_filepaths = correct_images_filepaths[-10:]
print(len(train_images_filepaths), len(val_images_filepaths), len(test_images_fileapths))데이터셋을 불러오고, 훈련/검증/테스트 셋으로 분리한다.
class DogvsCatDataset(Dataset) :
def __init__(self, file_list, transform=None, phase='train') :
self.file_list = file_list
self.transform = transform
self.phase = phase
def __len__(self) :
return len(self.file_list)
def __getitem__(self, idx) :
img_path = self.file_list[idx]
img = Image.open(img_path)
img_transformed = self.transform(img, self.phase)
label = img_path.split('/')[-1].split('.')[0]
if label == 'dog' :
label = 1
elif label == 'cat' :
label = 0
return img_transformed, label이미지 레이블을 구분한다.
train_dataset = DogvsCatDataset(train_images_filepaths, transform=ImageTransform(size, mean, std),
phase='train')
val_dataset = DogvsCatDataset(val_images_filepaths, transform=ImageTransform(size, mean, std),
phase='val')
index = 0
print(train_dataset.__getitem__(index)[0].size())
print(train_dataset.__getitem__(index)[1])이미지 데이터셋을 정의한다.
# load data to memory
train_iterator = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valid_iterator = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
dataloader_dict = {'train' : train_iterator, 'val' : valid_iterator}
batch_iterator = iter(train_iterator)
inputs, label = next(batch_iterator)
print(inputs.size())
print(label)이미지 데이터를 불러온다.
class BasicBlock(nn.Module) :
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=False) :
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stirde, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
if downsample : # 다운샘플이 적용되는 부분(출력 데이터크기가 다를 경우 사용)
conv = nn.Conv2d(in_channels, out_channels, kernel_size=1,
stride=stride, bias=False)
bn = nn.BatchNorm2d(out_channels)
downsample = nn.Sequential(conv, bn)
else :
downsample = None
self.downsample = downsample
def forward(self, x) :
i = x
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
if self.downsample is not None :
i = self.downsample(i)
x += i # identity mapping
x = self.relu(x)
return x
기본 블록(basicBlock)을 정의한다.
다운샘플은 입력 데이터의 크기와 네트워크를 통과한 출력 데이터 크기가 다를 경우에 사용한다. 다운샘플을 하기 위해서는 합성곱에 스트라이드를 적용한다.
아이덴티티 매핑을 적용한다. 특정 층에 존재하는 출력 결과를 다음 합성곱층을 통과한 출력 결과에 더해 주는 작업(=skip connection)이다(shortcut 이라고도 함).
class Bottleneck(nn.Module) :
expansion = 4 # 병목 블록을 정의하기 위한 하이퍼파라미터
def __init__(self, in_channels, out_channels, stride=1, downsample=False) :
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1,
stride=1, bias=False) # 1x1 합성곱층
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
self.conv3 = nn.Conv2d(out_channels, self.expansion * out_channels,
kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*out_channels)
self.relu = nn.ReLU(inplace=True)
if downsample :
conv = nn.Conv2d(in_channels, self.expansion*out_channels, kernel_size=1,
stride=stride, bias=False)
bn = nn.BatchNorm2d(self.expansion*out_channels)
downsample = nn.Sequential(conv, bn)
else :
downsample = None
self.downsample = downsample
def forward(self, x) :
i = x
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x)
if self.downsample is not None :
i = self.downsample(i)
x += i
x = self.relu(x)
return x병목 블록을 정의한다. 병목 블록은 ResNet50, ResNet101, ResNet152에서 사용되며, 1X1 합성곱층, 3X3 합성곱층, 1X1 합성곱층으로 구성된다. (기본 블록은 3X3 합성곱층 두 개를 갖는다.)
class ResNet(nn.Module) :
def __init__(self, config, output_dim, zero_init_residual=False) :
super().__init__()
block, n_blocks, channels = config
self.in_channels = channels[0]
assert len(n_blocks) == len(channels) == 4
self.conv1 = nn.Conv2d(3, self.in_channels, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channels)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self.get_resnet_layer(block, n_blocks[0], channels[0])
self.layer2 = self.get_resnet_layer(block, n_blocks[1], channels[1], stride=2)
self.layer3 = self.get_resnet_layer(block, n_blocks[1], channels[2], stride=2)
self.layer4 = self.get_resnet_layer(block, n_blocks[1], channels[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(self.in_channels, output_dim)
if zero_init_residual :
for m in self.modules() :
if isinstance(m, BottleNeck) :
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock) :
nn.init.constant_(m.bn2.weight, 0)
def get_resnet_layer(self, block, n_blocks, channels, stride=1) :
layers = []
if self.in_channels != block.expansion * channels :
downsample = True
else :
downsample = False
layers.append(block(self.in_channels, channels, stride, downsample))
for i in range(1, n_blocks) :
layers.append(block(block.expansion*channels, channels))
self.in_channels = block.expansion * channels
return nn.Sequential(*layers)
def forward(self, x) :
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
h = x.view(x.shape[0], -1)
x = self.fc(h)
return x, h
```python
ResNetConfig = namedtuple('ResNetConfig', ['block', 'n_blocks', 'channels'])ResNet 네트워크를 정의한다.
# 기본
resnet18_config = ResNetConfig(block=BasicBlock,
n_blocks=[2, 2, 2, 2,],
channels=[64, 128, 256, 512])
resnet34_config = ResNetConfig(block=BasicBlock,
n_blocks=[3, 4, 6, 3,],
channels=[64, 128, 256, 512])기본 블록을 사용하는 resnet의 config를 정의한다.
# 병목
resnet50_config = ResNetConfig(block=Bottleneck,
n_blocks=[3, 4, 6, 3],
channels=[64,128,256,512])
resnet101_config = ResNetConfig(block=Bottleneck,
n_blocks=[3,4,23,3],
channels=[64,128,256,512])
resnet152_config = ResNetConfig(block=Bottleneck,
n_blocks=[3,8,36,3],
channels=[64,128,256,512])병목 블록을 사용하는 resnet의 config를 정의한다.
pretrained_model = models.resnet50(pretrained=True)
print(pretrained_model)사전 훈련된 ResNet을 로드 및 확인한다.
output_dim = 2
model = ResNet(resnet50_config, output_dim)
print(model)ResNet50을 사용한다.
# 손실함수 정의
optimizer = optim.Adam(model.parameters(), lr=1e-7)
criterion = nn.CrossEntropyLoss()
model = model.to(device)
criterion = criterion.to(device)optimizer와 loss function을 정의한다.
def calculate_topk_accuracy(y_pred, y, k=2) :
with torch.no_grad() :
batch_size = y.shape[0]
_, top_pred = y_pred.topk(k, 1)
top_pred = top_pred.t()
correct = top_pred.eq(y.view(1, -1).expand_as(top_pred))
correct_1 = correct[:1].reshape(-1).float().sum(0, keepdim=True)
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
acc_1 = correct_1 / batch_size
acc_k = correct_k / batch_size
return acc_1, acc_k모델의 정확도 측정함수를 정의한다.
def train(model, iterator, optimizer, criterion, device) :
epoch_loss = 0
epoch_acc_1 = 0
epoch_acc_5 = 0
model.train()
for (x, y) in iterator :
x = x.to(device)
y = y.to(device)
optimizer.zero_grad()
y_pred = model(x)
loss = criterion(y_pred[0], y)
acc_1, acc_5 = calculate_topk_accuracy(y_pred[0], y)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc_1 += acc_1.item()
epoch_acc_5 += acc_5.item()
epoch_loss /= len(iterator)
epoch_acc_1 /= len(iterator)
epoch_acc_5 /= len(iterator)
return epoch_loss, epoch_acc_1, epoch_acc_5모델의 학습 함수를 정의한다.
def evaluate(model, iterator, criterion, device) :
epoch_loss = 0
epoch_acc_1 = 0
epoch_acc_5 = 0
model.eval()
with torch.no_grad() :
for (x, y) in iterator :
x = x.to(device)
y = y.to(device)
y_pred = model(x)
loss = criterion(y_pred[0], y)
acc_1, acc_5 = calculate_topk_accuracy(y_pred[0], y)
epoch_loss += loss.item()
epoch_acc_1 += acc_1.item()
epoch_acc_5 += acc_5.item()
epoch_loss /=len(iterator)
epoch_acc_1 /= len(iterator)
epoch_acc_5 /= len(iterator)
return epoch_loss, epoch_acc_1, epoch_acc_5모델 평가 함수를 정의한다.
def epoch_time(start_time, end_time) :
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secsbest_valid_loss = float('inf')
epochs = 10
for epoch in range(epochs) :
start_time = time.monotonic()
train_loss, train_acc_1, train_acc_5 = train(model, train_iterator, optimizer,
criterion, device)
valid_loss, valid_acc_1, valid_acc_5 = evaluate(model, valid_iterator, criterion,
device)
if valid_loss < best_valid_loss :
best_valid_loss = valid_loss
torch.save(model.state_dict(), '../080289-main/chap06/data/ResNet-model.pt')
end_time = time.monotonic()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
print(f'Epoch : {epoch+1:02} | Epoch Time : {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss : {train_loss:.3f} | Train Acc @1 : {train_acc_1*100:6.2f}% | Train Acc @5 : {train_acc_5*100:6.2f}%')
print(f'\tValid Loss : {valid_loss:.3f} | Valid Acc @1 : {valid_acc_1*100:6.2f}% | Valid Acc @5 : {valid_acc_5*100:6.2f}%') 모델을 학습시킨다.
import pandas as pd
id_list = []
pred_list = []
_id = 0
with torch.no_grad() :
for test_path in test_images_filepaths :
img = Image.open(test_path)
_id = test_path.split('/')[-1].split('.')[1]
transform = ImageTransform(size, mean, std)
img = transform(img, phase='val')
img = img.unsqueeze(0)
img = img.to(device)
model.eval()
outputs = model(img)
preds = F.softmax(outputs[0], dim=1)[:, 1].tolist()
id_list.append(_id)
pred_list.append(preds[0])
res = pd.DataFrame({
'id' : id_list,
'label' : pred_list
})
res.sort_values(by='id', inplace=True)
res.reset_index(drop=True, inplace=True)
res.to_csv('../080289-main/chap06/data/ResNet.csv', index=False)
res.head(10)테스트 데이터셋으로 모델을 예측한다.
import pandas as pd
id_list = []
pred_list = []
_id = 0
with torch.no_grad() :
for test_path in test_images_filepaths :
img = Image.open(test_path)
_id = test_path.split('/')[-1].split('.')[1]
transform = ImageTransform(size, mean, std)
img = transform(img, phase='val')
img = img.unsqueeze(0)
img = img.to(device)
model.eval()
outputs = model(img)
preds = F.softmax(outputs[0], dim=1)[:, 1].tolist()
id_list.append(_id)
pred_list.append(preds[0])
res = pd.DataFrame({
'id' : id_list,
'label' : pred_list
})
res.sort_values(by='id', inplace=True)
res.reset_index(drop=True, inplace=True)
res.to_csv('../080289-main/chap06/data/ResNet.csv', index=False)
res.head(10)class_ = classes = {0 : 'cat', 1 : 'dog'}
def display_image_grid(images_filepaths, predicted_labels=(), cols=5) :
rows = len(images_filepaths) // cols
fig , ax = plt.subplots(nrows=rows, ncols=cols, figsize=(12, 6))
for i, image_filepath in enumerate(images_filepaths) :
image = cv2.imread(image_filepath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
a = random.choice(res['id'].values)
label = res.loc[res['id'] == a, 'label'].values[0]
if label > 0.5 :
label = 1
else :
label = 0
ax.ravel()[i].imshow(image)
ax.ravel()[i].set_title(class_[label])
ax.ravel()[i].set_axis_off()
plt.tight_layout()
plt.show()
display_image_grid(test_images_fileapths)
예측 결과를 시각화하여 확인한다.
📚 reference
- (길벗) 딥러닝 파이토치 교과서 / 서지영 지음
- github
