Neural Architectures for Named Entity Recognition(2016) 논문을 읽고 내용 요약 및 정리한 내용이다. 본 논문에서는 LSTM-CRF과 Stack-LSTM 2가지 NER 모델을 제안한다!
본 논문은 LSTM-CRF 기법 때문에 찾아 보게 된 건데, CRF 알고리즘에 대한 설명은 자세히 나오지 않아서 따로 공부해야 할 것 같다.
1. Introduction
개체명 인식(Named Entity Recognition)은 어려운 학습 문제이다. 대부분의 언어나 영역에서, 이용가능한 지도 학습 데이터는 매우 적다. 또 네이밍 될 수 있는 단어의 종류에는 제한이 적기 때문에, 적은 양의 샘플 데이터에서 일반화하기가 어렵다.
결과적으로, gazetteers와 같이 세심하게 구성된 정자의(orthographic) 특성들과 언어 특화 지식 원천들이 개체명 인식 태스크를 해결하는 데 널리 사용된다. 불행히도, 언어에 특화된 리소스와 특성은 새로운 언어와 새로운 도메인에 발전시키는 비용이 커서 NER 태스크를 적용하는 것을 어렵게 만든다.
본 논문은 적은 양의 지도학습 데이터와 라벨링되지 않은 코퍼스를 사용하는 것을 넘어, 언어 특화적인 원천이나 특성을 사용하지 않는 NER 신경망 구조를 제안한다. 본 논문의 모델은 2가지 직관을 포착하고자 설계된다.
첫 번째, 이름(name)이라는 것은 보통 multiple tokens로 구성되어 있기 때문에, 각 토큰에 대한 태깅(tagging) 결정을 공동으로 추론하는 것이 중요하다.
여기서, 본 논문은 2가지 모델 (1) sequential conditional random layer를 올린 양방향 LSTM(LSTM-CRF)과 (2) 전이 기반 파싱(transition-based parsing)에 영감을 받은 알고리즘과 stack LSTM으로 represent된 레이어를 사용하여 입력 문장의 chunk를 구성하고 라벨링하는 새로운 모델(S-LSTM)을 비교한다.
두 번째, “이름이 되기(being a name)”위한 토큰 수준의 evidence는 orthographic evidence(이름으로 태깅된 단어가 어떤 형태인지)와 distributional evidence(이름으로 태깅된 단어가 코퍼스 내 어디에서 나타나는 경향이 있는지)를 포함한다. 본 논문은 orthographic sensitivity를 포착하기 위해 character-based word representation model을 사용하고, distributional evidence를 포착하기 위해, character-based word representation을 distributional representation과 결합한다. 그리고 word representations는 이러한 representations는 모두 결합하고, dropout training을 사용하여 모델이 양쪽의 resource evidence를 모두 신뢰하도록 학습하는 것을 장려한다.
영어, 네덜란드어, 독일어, 스페인어에 대한 실험들은 네덜란드, 독일어, 스페인어, 그리고 영어에
서 SOTA와 매우 근접하며 어떠한 수작업 특성(hand-engineered features) 또는 gazetteers가 없어
도 LSTM-CRF 모델로 SOTA NER 성능을 얻을 수 있다는 것을 입증한다. 전이 기반 알고리즘도 마
찬가지로, LSTM-CRF 모델보다 성능이 약간 떨어짐에도 불구하고 몇몇 언어에서 최근 발표된 가
장 좋은 결과를 능가했다.
2. LSTM-CRF Model
본 섹션에서는 LSTMs과 CRFs에 대해 간략히 설명하고, hybrid tagging 구조를 제시한다. 이러한 구조는 Collobert et al.(2011)과 Huang et al.(2015)에서 제안한 구조와 유사하다.
2.1. LSTM
순환 신경망(RNNs)은 순차적 데이터(sequential data)에서 작동하는 신경망의 한 종류이다. RNNs
은 벡터 시퀀스()를 입력받고, 입력의 매 단계(step)마다 시퀀스에 대한 정보를 표
현하는 다른 시퀀스()를 반환한다.
RNNs는 이론적으로 장기적인 의존성(long-term dependency)을 학습할수 있지만, 실질적으로는 장기적 의존성을 학습하지 못하고 시퀀스 내의 가장 최신 정보에 편향되는 경향이 있다 (Bengio et al., 1994). 장단기 메모리 네트워크(Long Short-term Memory Networks)는 메모리 셀을 통합함으로써 이러한 문제사항을 극복하기 위해 설계되었고 장기 의존성을 포착하는 것이 입증되었다.
LSTMs는 메모리 셀에 넘기는 입력의 일부분과 망각(forget)할 이전 상태의 일부분을 제어하는 게
이트(gate)를 사용함으로써 장기 의존성을 포착한다 (Hochreiter and Schmidhuber, 1997). 식은 다음과 같다.
은 element-wise sigmoid function, 은 element-wise product이다.
각 -dimensional vector로 표현되는 개의 단어를 포함한 문장()이 주어지면, LSTM은 를 연산한다. 오른쪽 컨텍스트의 representation 도 연산한다. 이 작업은 역으로 동일한 시쿼스를 읽어오는 second LSTM을 사용하여 수행될 수 있다. 여기서 전자를 forward LSTM, 후자를 backward LSTM이라 한다. 이들은 상이한 파라미터를 사용하는 두 가지 distinct network이다. 이러한 전방, 후방 LSTM 쌍을 bidirectional LSTM이라 한다(Graves and Schmidhuber, 2005). 이 모델은 왼쪽과 오른쪽 컨텍스트를 연결(concatenate)함으로써 word representation을 얻는다.
이러한 representations는 문맥 내 단어의 representation을 효율적으로 포함하여, 많은 tagging application에 유용하다.
2.2. CRF Tagging Models
아주 단순하지만 매우 효과적인 tagging model은 를 특성(feature)으로 사용하여 각각의 출력 에 대하여 독립적인 태깅 결정을 내리는 것이다. 품사 태깅과 같은 단순한 문제에서는 이러한 모델이 성공적이지만, 출력 라벨간 강력한 의존성이 있을 때 모델의 독립적인 classification decision은 제한적이다.
NER 또한 이러한 태스크에 속하는데, 태그의 시퀀스를 이해할 수 있게 해주는 “문법(grammar)”이 독립적인 가정으로 모델링하는 것이 불가능하도록 어려운 제한사항을 만들기 때문이다(예를 들면, I-PER는 B-LOC에 후행할 수 없다).
그러므로, 본 논문은 tagging decision을 독립적으로 모델링하는 대신, conditional random field(CRF)를 사용하여 공동으로 모델링한다. 입력 문장 에 대하여, biLSTM 네트워크를 통해 출력된 매트릭스 스코어를 라 한다. 는 크기로, 이 때 는 distinct tag 개수, 는 문장 내 번째 단어에 대한 번째 태그의 스코어에 대응한다.
예측 시퀀스 에 대하여, 시퀀스의 스코어는 로 정의된다. 이 때 는 transition score의 행렬로, 는 tag 부터 tag 까지 transition score를 나타낸다. 과 는 각각 문장의 시작() 태그와 마지막() 태그이다. 따라서, 는 크기의 정방행렬이 된다.
모든 possible tag sequence에 대한 소프트맥스는 sequence 의 확률값을 산출한다.
학습하는 동안, 태그 시퀀스의 로그 확률을 최대화한다 :
여기서 는 문장 에 대하여 모든 possible tag sequence(IOB format을 확인하지 않은 것 포함)를 나타낸다. 상단의 공식에서, 논문의 네트워크가 출력 라벨의 유효한 시퀀스를 만들도록 장려한다는 것이 분명해진다. 디코딩하는 동안에, 다음 식으로 도출된 최대 스코어를 얻는 출력 시퀀스를 예측한다 :
출력값 간의 bigram interaction만을 모델링하기 때문에, 식 1과 식 2의 posteriori sequence 최대의 총합은 다이나믹 프로그래밍으로 연산될 수 있다.
2.3. Parameterization and Training
각 토큰의 tagging decision과 연관된 스코어(즉, ’s)는 Ling et al.(2015b)의 품사 태깅과 정확히 동일한 biLSTM으로 연산된 단어의 in-context 임베딩 간 내적곱(dot product)으로 정의되고, 이는 bigram compatibility scores로 결합된다 (즉, s). 이러한 구조는 Figure 1에서 볼 수 있다. 여기서 원은 관측 변수, 다이아몬드는 변수의 부모에 대한 deterministic functions, 그리고 겹친 원은 임의 변수이다.
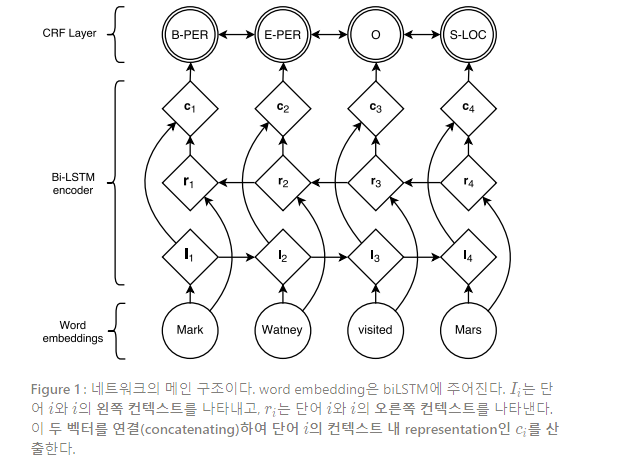
따라서, 이 모델의 파라미터는 bigram compatibility scores 의 행렬과 행렬 를 생성하는 파라미터들, 즉 biLSTM 파라미터와 선형 특성 가중치(linear feature weights), 그리고 워드 임베딩이다.
Part 2.2에서와 같이, 는 시퀀스 내 모든 단어에 대한 워드 임베딩 시퀀스를 나타내고, 는 이와 연관된 태그를 나타낸다. 섹션 4에서는 어떻게 임베딩 가 모델링되는지에 대해 다시 논의한다. 워드 임베딩 시퀀스는 biLSTM의 입력으로 주어지는데, 2.1에서 설명한 것과 같이 왼쪽과 오른쪽 컨텍스트의 representation을 반환한다.
이러한 representations는 연결(concatenate)되고() distinct tag의 수와 동일한 레이어에 선형적으로 사영(project)된다. 이러한 레이어에서는 소프트맥스 출력을 사용하는 대신, 앞서 설명한 것과 같이 CRF층을 neighboring tag로 고려하여 모든 단어 에 대한 최종 예측을 산출한다. 덧붙여, 와 CRF layer 사이에 은닉층을 더하는 것**이, 결과를 약간 더 향상시킨다. 본 모델로 보고된 결과는 모두 이 extra-layer를 포함한다. 관측 단어가 주어질 때, 파라미터들은 annotated corpus에서 NER tag의 관측 시퀀스에 대한 식 1을 최대화하기 위해 학습된다.
2.4. Tagging Schemes
NER 태스크는 문장 내 모든 단어에 개체명을 할당하는 것이다. 단일 개체명은 문장 내 여러 토큰에 걸치게 될 수 있다. 문장은 보통 IOB 포맷(Inside, Outside, Beginning)으로 표현되는데, 이 표현식에서 모든 토큰은 개체명의 시작 부분이면 B-label로 라벨링되고, 첫 번째 토큰이 아니면서 개체명 내부이면 I-label로 라벨링되고, 그렇지 않으면 O-label로 라벨링된다.
그러나, 우리는 일반적으로 사용되는 IOB의 변형인 IOBES 태깅 전략을 채택하는데, 이 방식은 싱글톤 개체(S)에 대한 정보를 인코딩하고 개체명의 마지막(E)를 명확히 마크한다. 이러한 전략을 사용하여, 단어를 I-label로 태깅하는 것이 뒤따르는 단어를 I-label로 할 것인지 E-label로 할 것인지 선택지를 높은 신뢰도(confidence)로 좁혀 준다. 그러나, 이러한 방식에서 IOB 태깅 전략보다 큰 성능 향상은 관측하지 못했다.
3. Transition-Based Chunking Model
본 논문은 이전 섹션에서 언급된 LSTM-CRF의 대안으로, transition-based dependency parsing과 유사한 알고리즘을 사용하여 입력 시퀀스를 청킹(chunk)하고 라벨링하는 새로운 구조를 탐구한다.
이러한 모델은 다중 토큰명의 representations를 직접적으로 구성한다 (e.g. Mark Watney라는 이름은
single representation으로 구성된다).
이러한 모델은 입력의 chunk를 증진적으로 구성하는 stack data 구조에 의존한다. 뒤따른 action을
예측하기 위해 사용되는 이러한 스택의 representation을 얻기 위해서, 우리는 Dyer et al. (2015) 가 제안한 stack-LSTM를 사용하는데, 여기서 LSTM은 “stack pointer”에 의해 증강(augmented)된다.
sequential LSTMs 모델이 왼쪽에서 오른쪽으로 시퀀싱을 한다면, stack LSTM 모델은 더해지고(push
operation을 사용하여) 제거되는(pop operation을 사용하여) 물체의 stack에 대한 임베딩을 허용한다. 이는 Stack-LSTM이 컨텐츠의 “summary embedding”을 유지하는 stack과 같이 작동할 수 있도록 한다. 우리는 이러한 모델을 Stack-LSTM 또는 단순히 S-LSTM 이라고 칭한다.
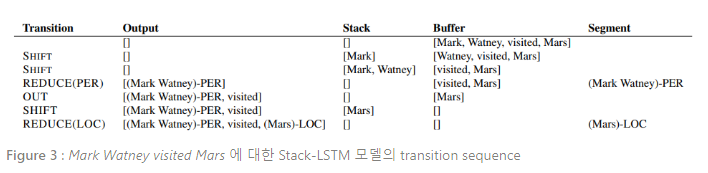
우리는 transition-based parser, 특히 arc-standard parser of Nivre (2004)에 영감을 받아 Figure 2에 주어진 transition inventory를 설계했다.
본 알고리즘에서, 우리는 두 개의 스택(과 으로 설계되며, 각각은 완성된 chunk와 scratch space를 나타냄)과 아직 처리되지 않은 단어를 보유하고 있는 를 사용한다. Transition inventory는 다음의 transition을 갖는다 :
transition은 단어를 buffer에서 stack으로 이동시키고, transition은 단어를 buffer에서 output stack으로 직접 이동시키며, transition은 스택의 윗부분에서 “청크(chunk)”를 생성하는 모든 아이템을 꺼내어(pop), 이 chunk의 representation을 출력 스택으로 밀어넣는다(push).
이 알고리즘은 스택과 버퍼가 다 비어 있을 때(empty) 종료된다. 이 알고리즘은 Figure 2에 묘사되어 있으며, Mark Watney visited Mars라는 문장을 처리하기 위해 요구되는 오퍼레이션의 시퀀스를 보여준다.

이 모델은 취했던 행동(action)의 이력 뿐만 아니라, 현재의 스택, 버퍼, 출력 컨텐츠가 주어질 때 각 타임 스텝에서 행동에 대한 확률분포를 정의함으로써 파라미터화된다.
Dyer et al.(2015)에 따라, 본 논문은 stack LSTMs를 사용하여 각각의 고정된 차원 임베딩을 연산하고, full algorithm state를 얻기 위해 이를 연결(concatenation)한다. 이러한 representation은 각 타임 스텝에서 취할 수 있는 possible action의 분포를 정의하는 데 사용된다.
모델은 입력 문장이 주어질때 reference action(라벨링된 학습 코퍼스에서 추출)의 시퀀스에 대한 조건부 확률을 최대화하기 위해 학습된다.
테스트 시 새로운 입력 시퀀스를 라벨링하기 위해, 최대 확률 action은 알고리즘이 종료 상태에 이르기까지 탐욕적으로 선택된다. 이것이 전역 최적해를 보장해주지는 않더라도, 실질적으로 유용하다. 각 토큰이 직접적으로 출력으로 이동하거나 (1 action) 또는 먼저 stack으로 이동한 후 출력으로 이동 (2 action)하기 때문에, 길이 의 시퀀스에 대한 전체 action의 수는 이 최대가 된다.
4. Input Word Embeddings
2가지 모델의 입력 레이어는 개별 단어의 vector representation이다. 한정된 NER 학습 데이터에서 단어 유형에 대한 독립적인 representations를 학습하는 것은 어려운 문제이다 : 의존적으로 예측하기에 너무 많은 파라미터가 있기 때문이다.
많은 언어들이 어떤 것이 명(name)이라는(또는 명이 아니라는) 정자적(orthographic) 또는 형태소적(morphological) 증거를 갖기 때문에, 우리는 단어의 철자에 민감한 representations를 원한다.
따라서, 본 연구는 구성된 문자의 representation에서 단어의 representation을 구성하는 모델(Character-based models)을 사용한다. 우리의 2번째 직관은 명(name)이란 독립적으로 상당히 다양하고, 대형 코퍼스에서 일반적인 문맥에 나타난다는 것이다. 그러므로, 우리는 단어 순서에 민감한 대형 코퍼스에서 학습된 임베딩을 사용한다(Pretrained embeddings). 마지막으로, 모델이 한 representation에 지나치게 의존하는 것을 방지하기 위해, 우리는 학습에 드롭아웃을 사용하고 이러한 드롭아웃이 좋은 일반화 성능에 중요함을 발견한다 (Dropout training).
기존 대부분의 접근법과 본 연구를 구분하는 중점은 학습에서 단어에 대한 hand-engineering
접두사와 접미사를 사용하는 대신, embedding features를 사용한다는 것이다. Character-level embeddings를 학습하는 것은 특정 태스크와 도메인에 특화된 representation을 학습할 수 있다는 이
점이 있다. 이러한 학습법은 형태소적으로 풍부한 언어에 유용하고, 품사 태깅과 언어 모델링 (Ling et al., 2015b) 또는 의존성 파싱(Ballesteros et al., 2015)과 같은 태스크의 OOV 문제를 다루기 용이하다고 알려져 왔다.
Figure 4는 단어의 문자로부터 워드 임베딩을 생성하는 구조에 대해 설명한다. 랜덤으로 초기화된
한 문자의 룩업 테이블이 모든 문자의 임베딩을 갖는다. 단어 내 모든 문자에 상응하는 문자 임베딩은 직접적으로, 그리고 전방과 후방 LSTM에 역순으로 주어진다. 이러한 문자들로부터 얻어진 단어 임베딩은 biLSTM으로부터 전방 및 후방 representation의 연결(concatenation)이 된다.
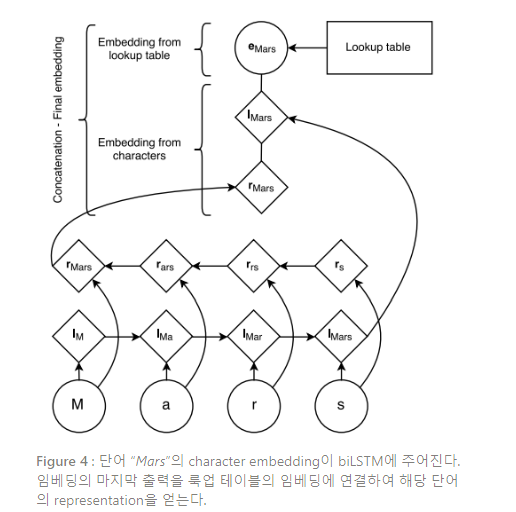
그 다음 이러한 문자 수준의(character-level) representation은 word lookup-table로부터 단어 수준의 representation과 연결된다. 테스트하는 동안, 룩업 테이블에 임베딩을 갖지 않는 단어들은 UNK embedding으로 매핑된다. UNK embedding을 학습하기 위해, 우리는 0.5 확률로 싱글톤을 UNK embedding으로 대체한다. 우리는 모든 실험에서, 전방과 후방 문자 LSTMs에 은닉 차원을 각각 25로 했는데, 그 결과 단어의 character-based representation은 50차원이 된다.
Collobert et al. (2011)에서와 같이, 본 논문은 사전학습된 워드 임베딩을 사용하여 룩업 테이블을 초기화한다. 임의로 초기화된 룩업 테이블에 사전학습 워드 임베딩을 사용하는 것이 큰 발
발전 낳는 것을 관측한다. 임베딩은 단어의 순서를 설명하는 skip-n-gram (Ling et al., 2015a)과
word2vec의 변형 (Mikolov et al., 2013a)을 사용하여 사전학습된다.
Spanish, Dutch, German, English의 워드 임베딩은 각각 Spanish Gigaword version 3, Leipzig 코퍼
스 모음집, 2010 Machine Translation Workshop 의 German 단일 언어 학습 데이터, English
Gigaword version 4(LA Times와 NY Times 부분이 제거된) 을 사용하여 학습된다. 우리는 영어에서
임베딩 차원을 100으로, 다른 언어에서 64로, 최소 단어 빈도 컷을 4로, 윈도우 사이즈를 8로 사
용한다.
모델이 양쪽 representation에 의존하도록 장려하기 위해, 본 논문은 dropout training(Hinton et al., 2012)을 사용하여 Figure 1의 biLSTM에 입력하기 직전에 최종 임베딩 레이어에 드롭아웃 마스크를 적용한다. 드롭아웃을 적용하고 모델 성능에 큰 향상이 관측된다(Table 5 참조).
5. Experiments
본 섹션에서는 모델을 학습할 때 사용된 방법과 다양한 태스크에서 얻은 결과, 그리고 모델의 성능에 대한 네트워크 구성의 영향을 제시한다.
본 논문에서 제시된 2개의 모델에서 모두 역전파 알고리즘(back-propagation algorithm)을 사용하여, 모든 training example마다 한 번씩 파라미터를 업데이트하고, 확률적 경사하강법(SGD)을 학습률 0.01, 경사도(gradient clipping) 5.0을 적용하여 네트워크를 학습시킨다.
LSTM-CRF 모델은 100개의 차원으로 설정된 전후방 LSTM에 대하여 단일 레이어를 사용한다. 차원 튜닝은 성능에 큰 영향을 끼치지 않는다. 드롭아웃은 0.5로 설정한다.
Stack-LSTM 모델은 각 스택에 100개의 차원을 가진 2개의 레이어를 사용한다. Composition functions에 사용된 action의 임베딩은 각각 16차원을 갖고, 출력 임베딩은 20차원을 갖는다.
본 연구는 다양한 개체명 인식 데이터셋을 사용하여 모델을 실험한다. 다양한 언어에 일반화되
는 모델의 능력을 입증하기 위해, CoNLL-2002와 CoNLL-2003 데이터셋 (Tjong Kim Sang, 2002; Tjong Kim Sang and De Meulder, 2003) 을 사용하여 결과를 제시한다.
모든 데이터셋은 다음 4가지 유형의 NER 을 보유한다 : 지역(location), 사람(person), 기업(organization), 그리고 3가지 카테고리에 속하지 않는 잡다한(miscellaneous) 개체.
영어 NER 데이터셋에서 모든 숫자를 0으로 대체하는 것 외에는 어떠한 데이터셋 전처리도 수행하지 않았다.
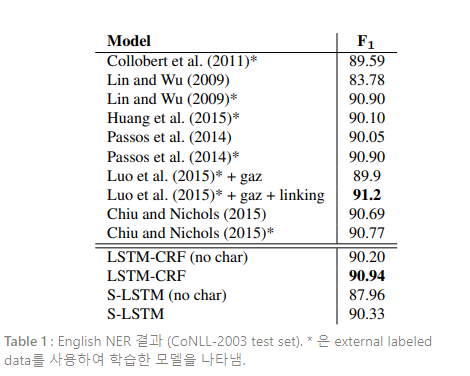
Table 1은 영어 NER에서 다른 모델과 본 연구의 모델을 비교한 결과이다. 본 태스크에서 가장 높은 스코어는 Luo et al. (2015)로, NER과 entity linking task(Hoffart et al., 2011)를 공동으로 모델링하여 91.2의 F1 score를 얻었다. 이 모델은 많은 hand-engineered 특성을 사용한다. LSTM-CRF 모델은 gazetteers와 같은 외부 데이터를 사용한 다른 모든 시스템의 성능을 능가한다. Stack-LSTM 모델 또한 Chiu and Nichols (2015)를 제외하면, 외부 특성을 사용하지 않은 이전 모델의 성능을 모두 능가한다.
Table 2, 3, 4는 German, Dutch, Spanish에 대한 각각의 NER 비교 결과이다. 이 3개의 언어에서,
LSTM-CRF 모델은 외부 라벨링 데이터를 사용한 모델을 포함한 모든 이전 모델들을 크게 능가한
다. 한가지 예외는 Dutch인데, Gillick et al. (2015)는 다른 NER 데이터셋의 정보를 이용하여 더 나
은 성능을 낸다. Stack-LSTM 또한 외부 데이터를 사용하지 않은 시스템에 비해 꾸준히 SOTA(또는
그에 준수한) 결과를 낸다.
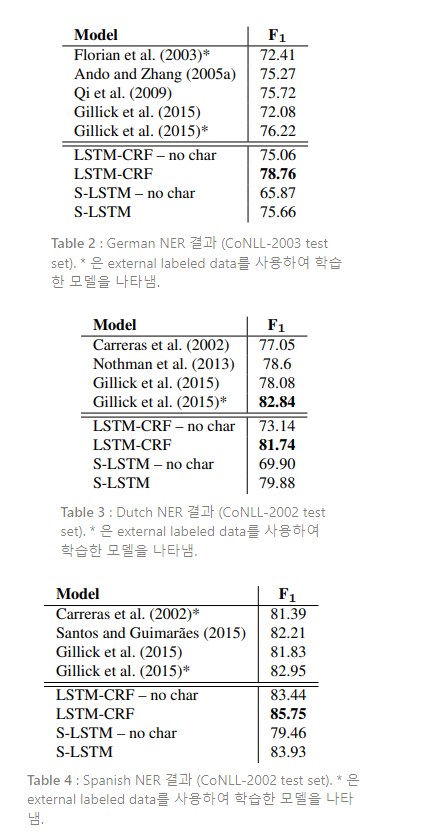
이러한 표에서 볼 수 있듯이, Stack-LSTM은 경쟁력 있는 성능을 얻기 위해 문자 기반 representation에 더 의존적이다. LSTM-CRF 모델이 biLSTM에서 더 많은 문맥 정보를 얻기 때문에 orthographic 정보를 더 적게 필요로 한다고 가정한다. 그러나, Stack-LSTM은 하나하나 더 많은 단어를 소모하고, 단어를 청킹할 때 word representation에만 의존한다.
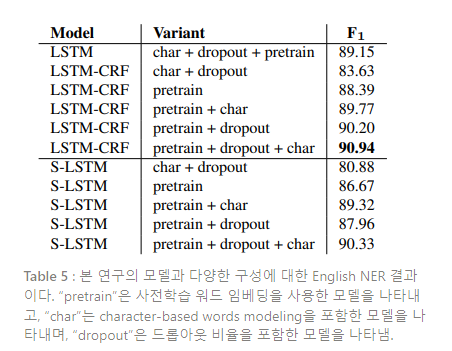
다음으로 character-level representation, 사전학습 워드 임베딩, LSTM-CRF 모델에 적용한 드롭아웃이 CRF에 갖는 영향에 대해 탐구한다. 탐구 결과는 Table 5에 주어진다. 실험 결과, 워드 임베딩을 사전학습 하는 것이 전반적인 성능에 F1 + 7.31로 가장 큰 성능 향상을 부여한 것을 발견한다. CRF layer는 +1.79, 드롭아웃의 사용은 +1.17, 그리고 character-level word embedding은 +0.74의 성능 향상을 부여했다.
6. Related Work
Carreras et al. (2002)는 CoNLL-2002에서 small fixed-depth decision tree를 결합함으로써 Dutch
and Spanish에서 가장 좋은 결과를 얻었다. 1년 후, Florian et al.(2003)는 CoNLL2003 Shared Task에서 4개의 divers classifiers 출력을 결합하여 최고의 결과를 얻었다. 이후 Qi et al. (2009)
는 많은 양의 라벨링되지 않은 코퍼스를 비지도학습시키는 신경망을 사용하여 발전시켰다.
기존에 NER을 위해 제안된 신경망 구조가 몇가지 더 있다. 예를 들면 Collobert et al. (2011)은 레
이어 상단에 CRF 층을 쌓은 CNN을 워드 임베딩 시퀀스에 사용한다. 이는 문자 단위 임베딩을 제
외하고, biLSTM층을 CNN으로 대체한 우리의 첫번째 모델과 동일하게 여길 수 있다.
더 최근에는, Huang et al. (2015)이 우리의 LSTM-CRF와 가장 유사한 모델을 제안했으나, hand-crafted spelling features를 사용했다. Zhou and Xu (2015)또한 유사한 모델을 사용했고 이를 라벨링 태스크에 적용했다. Lin and Wu (2009)은 linear chain CRF를 L2 규제와 함께 사용했는데, 웹 데이터와 spelling feautres에서 추출한 phrase cluster features를 더했다. Passos et al. (2014)또한 linear chain CRF와 spelling features, gazetteers를 사용했다.
본 논문과 같은 독립적인 언어 NER 모델들은 과거에도 제안되어 왔다. Cucerzan and Yarowsky (1999; 2002)는 character-level(word-internal)과 token-level features(context) 를 동시에 학습시킴
으로써 NER을 위한 반지도 부트스트래핑 알고리즘을 제안한다. Eisenstein et al. (2011)은 Bayesian nonparametrics를 사용하여 대부분의 비지도 학습 세팅에 개체명 데이터베이스를 구성한다. Ratinov and Roth (2009)는 NER의 몇 가지 접근법에 대해 충분히 비교하고 정규화된 average
perceptron을 사용하고 컨텍스트 정보를 집계함으로써 그들의 supervised model을 구축한다.
마침내, 현재는 NER 모델에 letter-based representation을 사용하는 것에 많은 관심이 있다. Gillick et al. (2015)은 시퀀스 라벨링 태스크를 seq2seq 학습 문제로 모델링하고 character-based
representations를 encoder model로 통합한다. Chiu and Nichols (2015)은 본 논문과 유사한
구조를 이용하지만, CNN을 사용하여 Santos and Guimaraes (2015)의 연구와 유사한 방식으로
character-level features를 학습시킨다.
7. Conclusion
본 논문은 표준 평가에 보고된 gazetteers와 같은 외부 리소스를 사용한 모델과 비교해도 최적의 NER 결과를 제공하는 시퀀스 라벨링을 위한 2가지 신경망 구조를 제안한다.
우리 모델의 핵심 측면은 단순한 CRF 구조 또는 명확하게 입력의 청크를 구성하고 라벨링하기 위한 전이 기반 알고리즘을 사용하여 출력 라벨 의존성을 모델링한다는 것이다.
Word representations는 성공을 위해 아주 중요하다.본 논문은 두 모델에 모두 morphological과 orthographic information를 포착하는 사전학습된 word representations과 character-based representation을 사용한다. 한 개의 representation class에 지나치게 의존하여 학습되는 것을 방지하기 위해, 드롭아웃이 사용된다.
