트위치 트래픽 특성
- 2022년 롤챔 310만명 동시 시철
- 만명 동시 스트리밍
라이브 스트리밍은 어떻게 하는걸까?
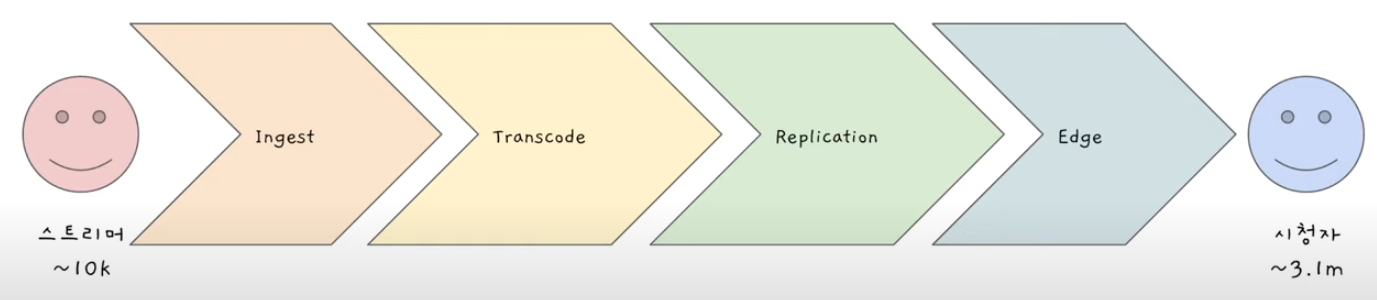
-
Ingest
스트리머의 비디오 영상이 트위치 데이터 센터로 가는 것 -
Transcode
비디오 형식을 바꾸는 것 -
Replication
복사. 안정성을 위해 -
Edge
CDN이라고도 부름
스트리머 -> Ingest -> Transcode -> Replication -> Edge -> 시청자
위와 같은 순서로 동작한다.
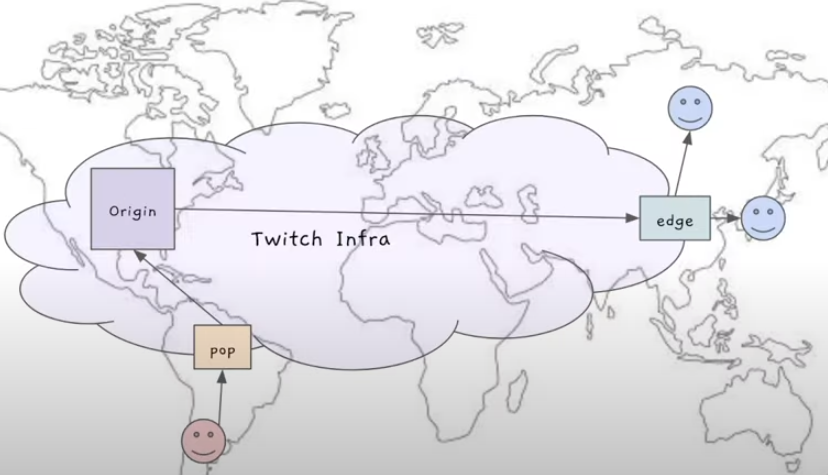
-빨간 스마일 = 스트리머
-Origin = 데이터 센터
-
스트리머가 데이터 센터로 직접 연결하는게 아니라 조그만 데이터 센터(pop)로 연결
(pop은 세계 곳곳에 있으며, 스트리머는 자신과 가장 가까운 pop에 연결) -
스트리머는 PoP과만 통신하고, PoP은 트위치의 인프라스트럭처 네트워크('Backbone'이라고 부름)를 통해 데이터 센터와 통신
PoP에서 데이터 센터로 스트리머 영상 보내주면 아래와 같은 동작을 함
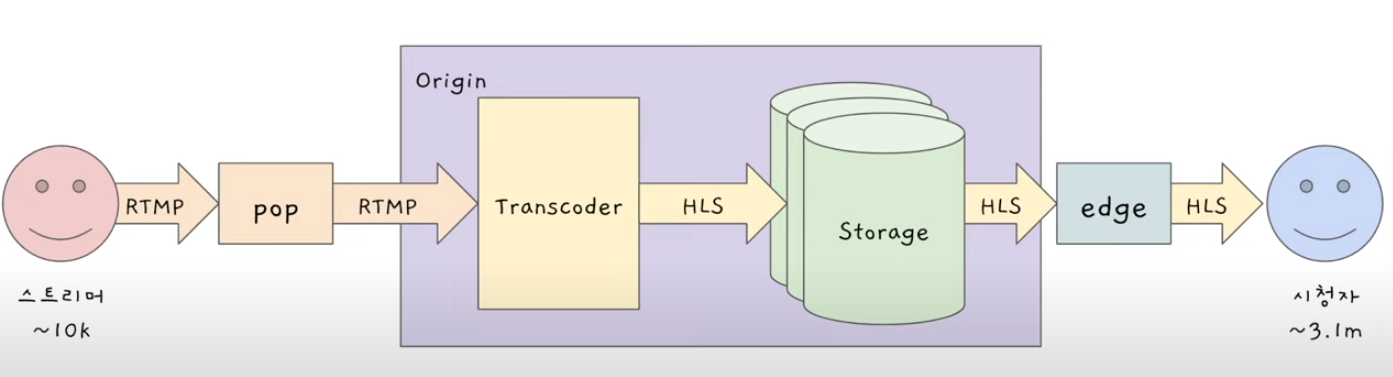
- 비디오 센터에 데이터가 도착하면, Transcoder라는 애가 RTMP 형식으로 온 비디오 영상을 HLS형식으로 변환한다.
- 그리고나서 스토리지에 저장한다.
-파란 스마일 = 시청자들
- 스토리지에 저장된 것을 시청자들이 트위치에 달라고하면, 시청자들이 직접 Origin과 연결해서 다운 받는게 아니라, edge를 통해 HLS형식으로 바뀐 비디오를 받아 플레이한다.
Scaling Ingest
트위치가 처음 시작했을 때는 데이터 센터(Origin) 하나로 시작
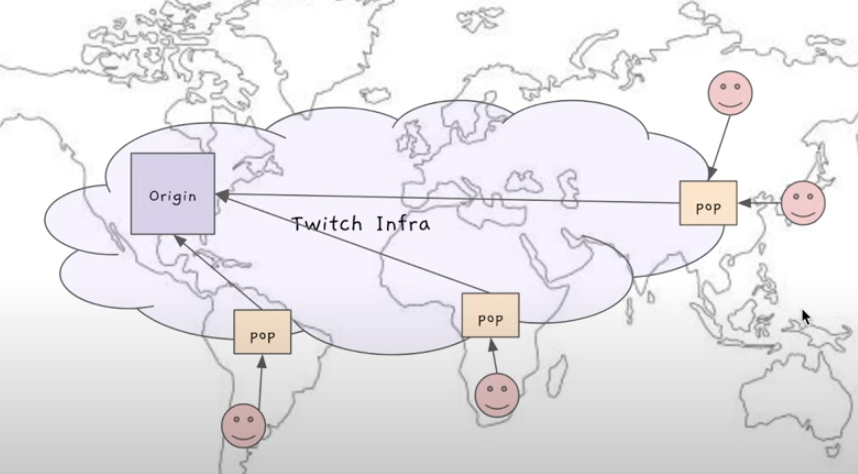
스케일하면서 데이터센터가 여러개로 됨
(위 그림에서 Origin이 여러개 있다고 보면됨)
-> 각각의 PoP이 어떤 데이터센터(Origin)과 통신해야하는지 정해줘야하는 복잡성이 생겼음
-
처음에는 HAProxy라는걸 사용 : PoP에서 Origin으로 연결
-> static하게 설정되어있음 : ex) PoP-A는 항상 특정 데이터 센터 Origin-1으로만 연결 -
데이터 센터가 많아지면서 생기는 문제들
-> 시간에 따라 특정 데이터 센터만 Resource Utilization이 올라감
-유저들이 액티브하게 트위치를 사용하는 시간은 그 나라 시간에따라 영향을 많이 받음
-각 데이터 센터가 로드를 나눠가져야 데이터 센터 하나 하나의 크기를 줄이는데, 하나의 Utilization이 올라가고 딴건 놀고있으면 각각의 데이터센터 모두 사이즈를 크게 해줘야하는 문제가있다. ❓
-> 데이터 센터가 다운됐을 때 다른 데이터 센터로 연결을 못 함
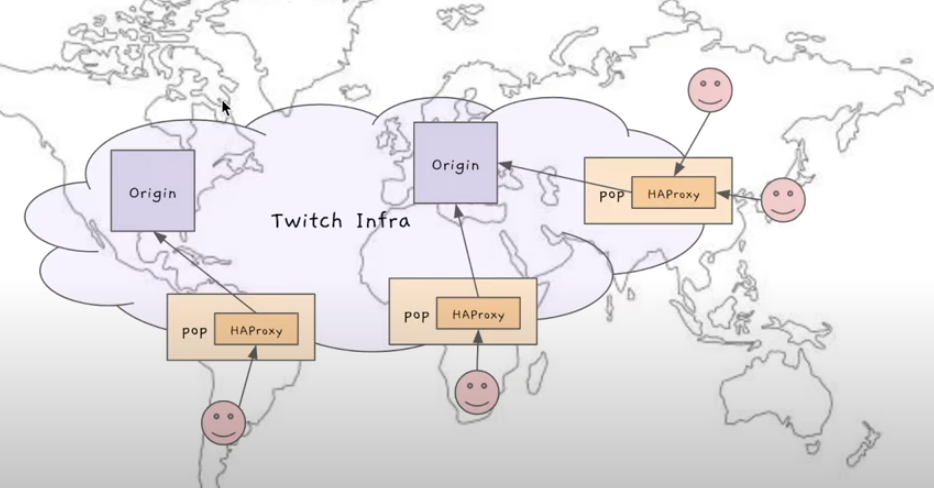 PoP안에 HAProxy가 돌고있음
PoP안에 HAProxy가 돌고있음
- HAProxy말고, Intelligest 라는걸 만듦
< 의문 >
1. Origin-1이 PoP-A, PoP-B와 통신, Origin-2가 PoP-C, PoP-D와 통신한다고 static하게 설정해두면, 특정 시간대따라 어느 Origin놀고 어느 Origin은 로드가 몰리고 그런거 상관없이 최대 크기는 항상 정해져있지않나??
Intelligest
4가지 Component가 있음
-
Intelligest media proxy (in PoP)
: HAProxy를 대체 -
Intelligest Reouting Service (in AWS)
: HAProxy보다 똑똑하게 하고싶으니까, Intelligest media proxy이 필요한 정보를 계산 -
Capacitor (in AWS) - CPU utilization monitoring
: Intelligest Reouting Service가 계산하기 위해 필요한 정보를 줌 -
The Well (in AWS) - Network utilization monitoring
: Intelligest Reouting Service가 계산하기 위해 필요한 정보를 줌
Ingest with Intelligest
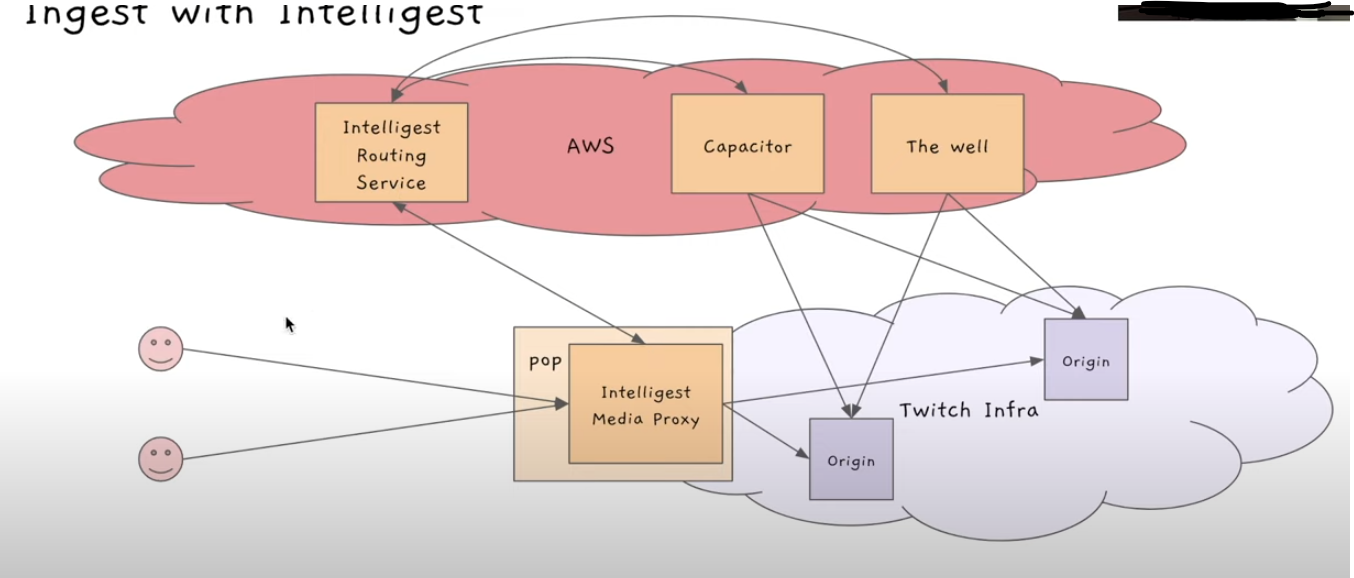
- 우선 PoP에는 HAProxy가 아닌 Intelligest media proxy가 있음
- 새로운 스트리머가 PoP에 연결하면 Intelligest media proxy가 Origin으로 무조건 연결하는게 아니라, 먼저 Intelligest Reouting Service에게 어떤 데이터 센터랑 연결할지 물어봄
- Intelligest Reouting Service는 연결해야하는 Origin을 알려줌
- PoP이 응답을 듣고, 이 스트리밍 서비스는 해당 데이터 센터로 라우팅해주고, 새로운 스트리머가 들어오면 또 물어보고..(반복)
Intelligest Reouting Service는 어떤 데이터 센터랑 연결해야하는지 결정을 어떻게 내릴까?
Capacitor, The Well을 통해 결정을 내림
- Capacitor은 각각 데이터 센터의 cpu utilization이 어떻게 되는지 항상 모니터링 하고있음
- The Well은 각각 데이터 센터의 네트워크 상황을 항상 모니터링 하고있음
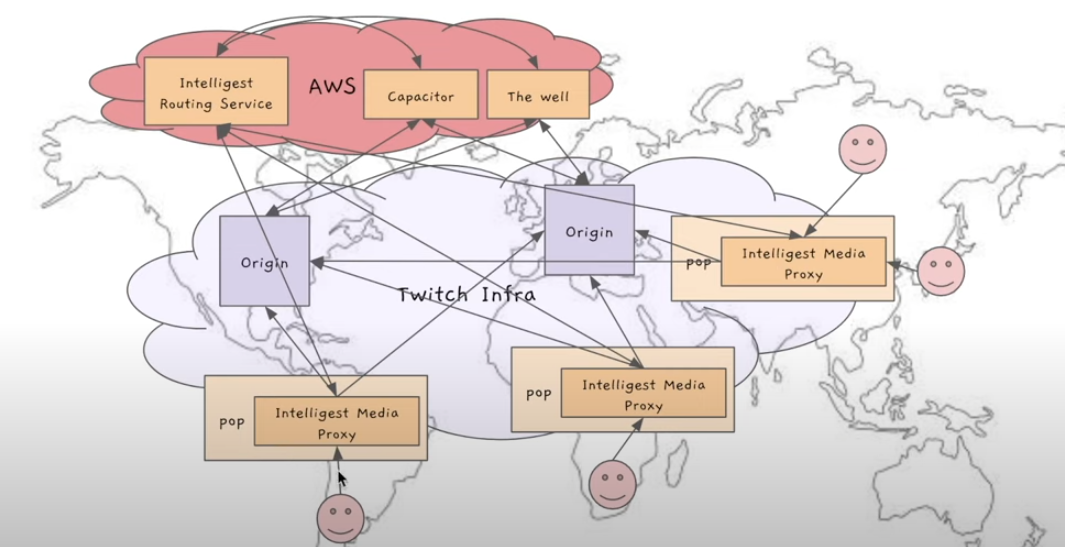
이제는 모든 PoP이 모든 데이터 센터와 통신할 수 있는 상태가 된다.
Transcode
RTMP 형식을 HLS형식으로 바꿔줌
HLS?
HTTP Live Streaming의 줄임말
- ABS(Adaptive Britrate Streaming)을 가능하게 함
- HTTP로 라이브 스트리밍을 가능하게 함
-> 즉, 새로운 프로토콜이 필요없다.
ABS?
인터넷 상태에 따라서 화질을 바꾸는 기술
HLS 프로토콜은 2가지 종류의 파일들을 만듦
-> Playlist
-> Video Chunk
자, 다시 Transcode로 와서!
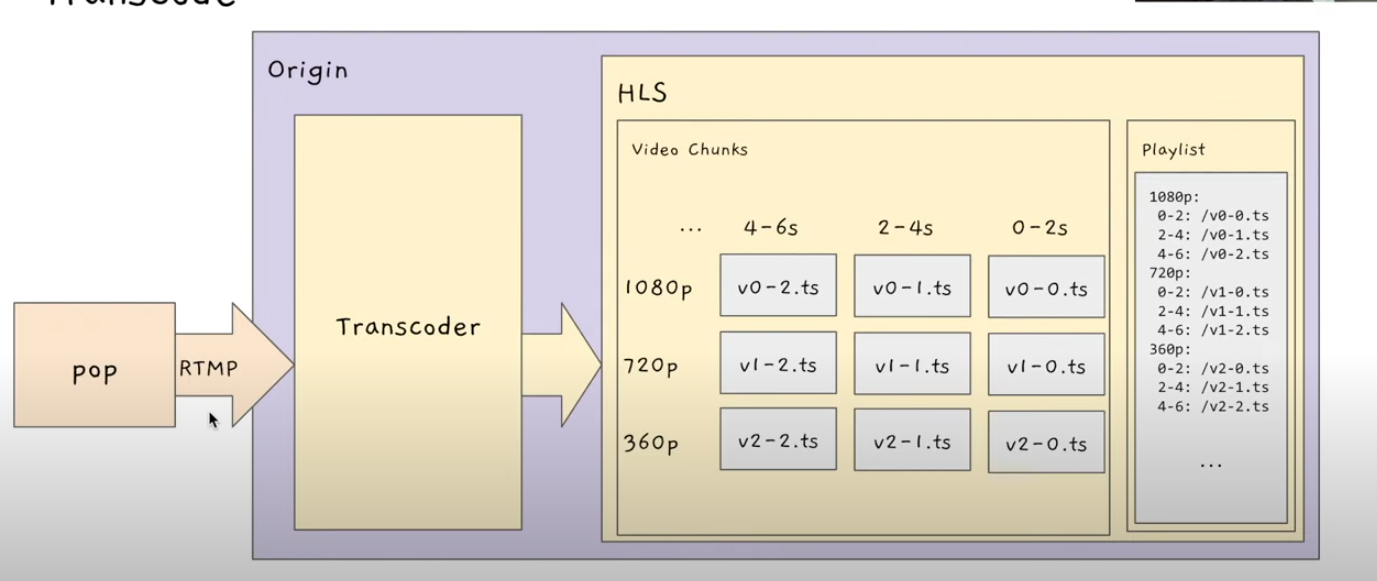
PoP에서 RTMP로 들어오는데, RTMP는 한 가지의 화질 영상이 계속 들어오는 것이다.
즉 스트리머들이 찍어서 보내고 있는 비디오 스트림이다.
그럼 Transcode가 그걸 받아서 여러가지 화질로 바꿔준다.
바꿔줄때 어떻게 바꿔줄까?
- Video Chunks
비디오 조각들로 만든다!
1080p 화질의 시작부터 첫 2초까지 영상을 잘라서 파일을 하나 만들고, 2~4초 영상을 잘라서 파일을 하나 만들고..(반복)
이걸 각각 해상도마다 만듦
- Playlist
1080p의 0~2초는 이 파일에 들어있다, 2~4초는 이 파일에 들어있다... 이런 정보를 다 Playlist에 저장함
- ABS

시청자가 들어오고, Playlist를 다운받음
(각 파일들을 어디서 다운받을 수 있는지 Playlist에 다 있음)
클라이언트의 비디오 플레이어가 지금 인터넷 상태를 확인함
상태가 안좋으면 시작은 360p로하며, 2초까지 영상이 어디에있는지 확인해서 해당 파일을 달라고 리퀘스트를 보냄.
해당 파일을 다운받아 플레이함
플레이되고있을 때는, 비디오 플레이어가 플레이 되는동안 시간이 조금 있으니까 조금 더 좋은 화질을 받고.. (반복)
계속 인터넷 상황에따라 Playlist 보면서 어떤 파일을 다운받아야할지 정해서 그 파일으 다운받아 플레이 해주는 것.
시간에따라 화질이 바뀌는 경험을 한 적 있을텐데, 이런식으로 흐름이 흘러가기 때문이다.
- Edge
결국 300만명 동시시청은 어떻게 처리할까?
300만명이 동시에 파일들을 다운받으려하면 데이터센터가 처리가 힘들것
HLS의 Playlist, video chunks가 캐시하기 쉽게 해준다.
video chunks를 만들어뒀는데, 이건 한 번 만들어두면 바뀔 필요가 없는것이기때문이다.
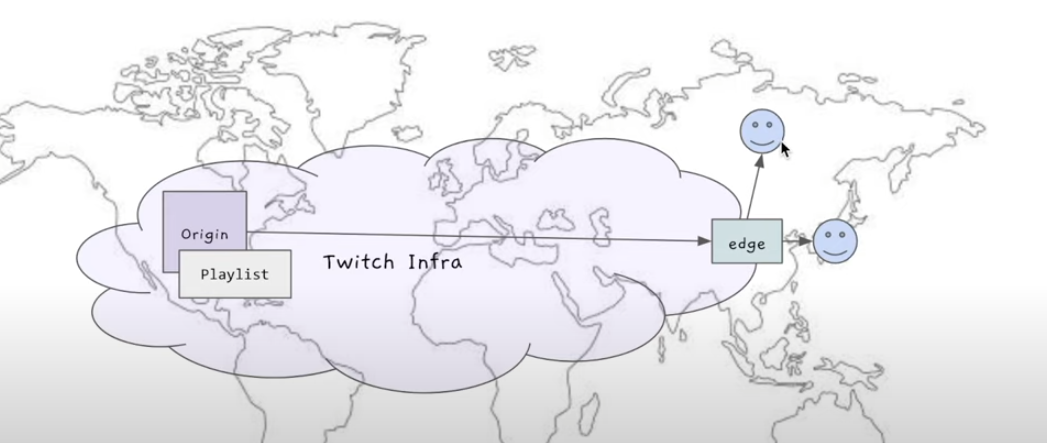
시청자가 처음에 Playlist를 다운받으려한다.
Edge한테 Playlist를 달라고 리퀘스트 보낸다. 처음에는 Edge도 Playlist가 없다.
따라서 Edge가 Origin한테 Playlist를 달라고 리퀘스트를 보낸다.
Origin이 Edge한테 Playlist를 보낸다.
Edge가 Playlist를 시청자에게 준다.
그 다음 새로운 시청자가 와서 Edge한테 Playlist를 달라고한다.
Edge는 Playlist가 이미 있으므로, 바로 시청자에게 준다.
시청자는 빨리 다운받을 수 있게 된다.
이 상황에서 좋은점은 다음과 같다.
2명의 유저를 Serve하는데 Origin과 edge와 통신은 한 번만 하면 된다.
따라서 첫 유저쪽 동네 사용자들은 전부 Edge에서 바로 Serve할 수 있다.
video chunks도 마찬가지다.
유저가 playlist를 보고 특정 video chunks를 달라고 Edge에게 리퀘스트한다.
Edge가 처음에 없으면 Origin한테 달라고 리퀘스트하며, 받아온것이 Edge에 캐시된다.
유저에게 해당 video chunk를 준다.
그 다음에 똑같은 video chunk를 달라고하면, Origin으로 갈 필요없이 바로 줄 수 있다.
이렇게하면 시청자가 300만명이 돼도, 300만명이 다 데이터 센터와 통신하는게 아니라, 동네 유저 한 명이 다운받으면 그 동네 유저들 전부가 다 바로 사용할 수 있다.
따라서 데이터센터에 오는 트래픽을 많이 절감할 수 있게 된다.
출처
트위치 시스템 디자인
