DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks (ICRA 2017)
Paper read
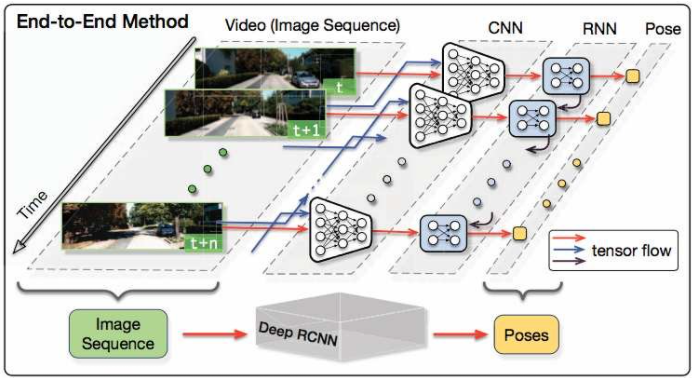
Abstract
제기한 문제점: different environment에 잘 동작하기 위해서는 정교한 fine-tuning이 필요하다., monocular slam에서 absolute scale을 잘 복원하기 위해서는 prior knowledge가 필요하다.
본 논문에서는 RCNN을 이용하여 end-to-end monocular VO를 해보고자 한다. 이는 기존 VO pipleline과는 다르게 raw RGB 이미지에서 directly pose를 추론한다. CNN을 이용해서 효율적으로 feature representation을 학습하였고, RNN 구조를 이용하여 sequential dynamics 와 relation을 내재적으로 학습할 수 있도록 디자인하였다.
KITTI VO dataset에서 traditional VO를 outperform하는 결과를 보여주었다.
Introduction
Classic pipeline: camera calibration, feature detection, feature matching (or tracking), outlier rejection (e.g RANSAC), motion estimation, scale estimation, local optimization (Bundle Adjustment)
monocular VO에서는 prior knowledge (e.g height of camera)를 이용하여 absolute scale을 알아내야 한다.
apearance representation이 뭐길래 geometric feature에 의존하는 걸까 => DL 방법이 학습된 국한된 환경에서만 잘되니까 일반적으로 잘 되게 하려면 geometric knowledge가 필요하다는 이야기 같음.
Main contribution
1) End-to-End: traditional method에서 필요했던 여러 단계의 module들이나 Absolute scale을 구하기 위한 파라미터들이 필요없어짐. 최초의 Deeplearning approach monocular VO.
2) new environments에 잘 적응할 수 있는 RCNN 모델 제안
3) Sequential 이미지를 학습하여 VO에서 중요한 motion dynamics의 정보를 학습할 수 있도록 RNN을 이용.
Related Work
monocular VO는 크게 geometric based 와 learning based로 나뉜다.
Geometric based (Sparse feature based vs Direct method)
[Sparse feature based]
MVG를 이용하여 salient feature point를 찾고 motion을 determine한다. 그러나 drift error를 발생시키는 outlier들이 있기 때문에 이를 기존 SLAM이나 SfM을 사용하여 drift correction을 해준다.
[Direct method]
연속된 이미지들의 모든 픽셀에 대한 연산을 하기 때문에 풍부한 정보를 사용할 수 있다. 일반적으로 direct method가 feature based 보다 성능이 좋아서 선호된다.
Learning based 이후로 큰 내용이 없다 ㄷㄷ
단지 모델 제안한게, 그리고 최초로 Deep VO를 end-to-end 로 구현한 것 (RCNN 제안)이 main contribution.
