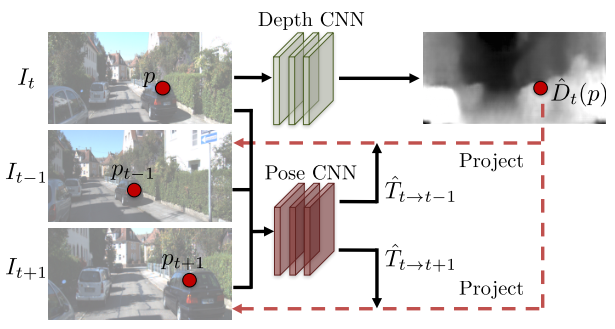
Depth라고 생각할 수 있는 출력값과 pose라고 생각할 수 있는 출력 벡터를 이용하여 아래 식을 통해 target의 주변 이미지 , 을 warping하여 relocate하고, target 이미지()를 복원하도록 학습할 수 있는 것이 핵심이다.
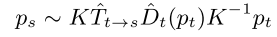
Target pixel을 camera coordinate 관계를 이용하여 source pixel을 알아낼 수 있다.
View synthesis하는 과정에서 CNN의 여러 implicitly 학습된 information(geometric reasons)을 이용하겠다.
Abstract
Video sequence로 부터 monocular depth와 camera motion을 학습하기 위한 unsupervised learning 방법을 제안
오로지 monocular video sequence만 학습에 필요, pose network, loss를 사용, Totally unsupervised learning
Introduction
imperfect geometry(같은계열: textureless 한 즉 geometric appearance, physical gt에 대한 대응하는 특성이 없으면)는 학습시엔 모델을 속일 수 있으나, 전혀 다른 another set of scene이 나오면 망한다.
따라서 entire view synthesis pipeline을 만들고자 한다.
Related work
Structure from motion
기존 sfm method들은 accurate image correspondence에 의존했지만, 이는 분명 많은 경우에(low texture, complex geometry, occlusion 등) 한계점이 존재한다. 그래서 이러한 문제를 딥러닝적으로 풀려는 시도가 있었다.
딥러닝적 접근은 external supervision을 주거나 위 문제를 해결할 수 있었다는 점에서 좋은 시도였다.
Warping based view synthesis
warping-based methods are forced to learn intermediate predictions of geometry and/or correspondence. In this work, we aim to distill such geometric reasoning capability from CNNs trained to perform warping-based view synthesis.
warping based veiw synthesis를 목적으로 만들어진 CNN의 내재된 geometric reasons들을 이용해보겠다.
Learning single-view 3D from registered 2D views
2D이미지들 가지고 3D를 deep learning으로 만들 수 있더라 ~ 여러 연구 소개
Approach
View synthesis as supervision
하나의 이미지로부터, 다른 pose의 이미지를 예측 => 과정에서 depth와 camera pose를 알 수 있다.
source coordinate 에서 target coordinate frame 이 뭘까 => homogeneous coordinate이기 때문에 바뀌어야한다.
뎁스라고 생각할 수 있는 출력값과 pose라고 생각할 수 있는 출력 벡터를 이용하여 아래 식을 통해 target의 주변 이미지 I_t-1, I_t+1을 warping하여 relocate하고, target 이미지(I_t)를 복원하도록 학습할 수 있는 것이 핵심이다.
target pixel을 camera coordinate 관계를 이용하여 source pixel을 알아낼 수 있다.
알아낼 수 있는데, 한가지 문제점이, homogenous coordinate을 쓰기 때문에, 2D 이미지 상에서는 continuous한 픽셀 위치를 가지는 것이 문제이다. 이를 해결하기 위해 기존 spatial transformer networks에서 이미지를 warping할 때 사용되었던 differentiable bilinear sampling mechanism을 사용한다.
이렇게 바뀐 이미지에 대해서
Differentiable depth image-based rendering
