
lec 07-1
Contents
- Learning rate
- Learning rate : overshooting
- Small Learning rate
- Try serveral learning rates
- Data preprocessing (데이터 전처리)
- 데이터 전처리 쏠림 해결
- Standardizationㅤ
- Overfitting
- Solutions for over fitting
- Regularization
ㅤ
- Regularization
ㅤ
ㅤ
ㅤ
Learning rate
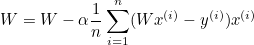
W가 경사를 타고 내려올 때, 한 번애 얼마만큼 이동할지를 의미한다.
기본적으로 0.01, 0.001과 같은 값을 가지며, 숫자가 크다면 한번에 많은 경사를 내려올 것이고, 숫자가 적다면 질 내려오지 못할 것이다.
ㅤ
ㅤ
ㅤ
ㅤ
Learning rate : overshooting
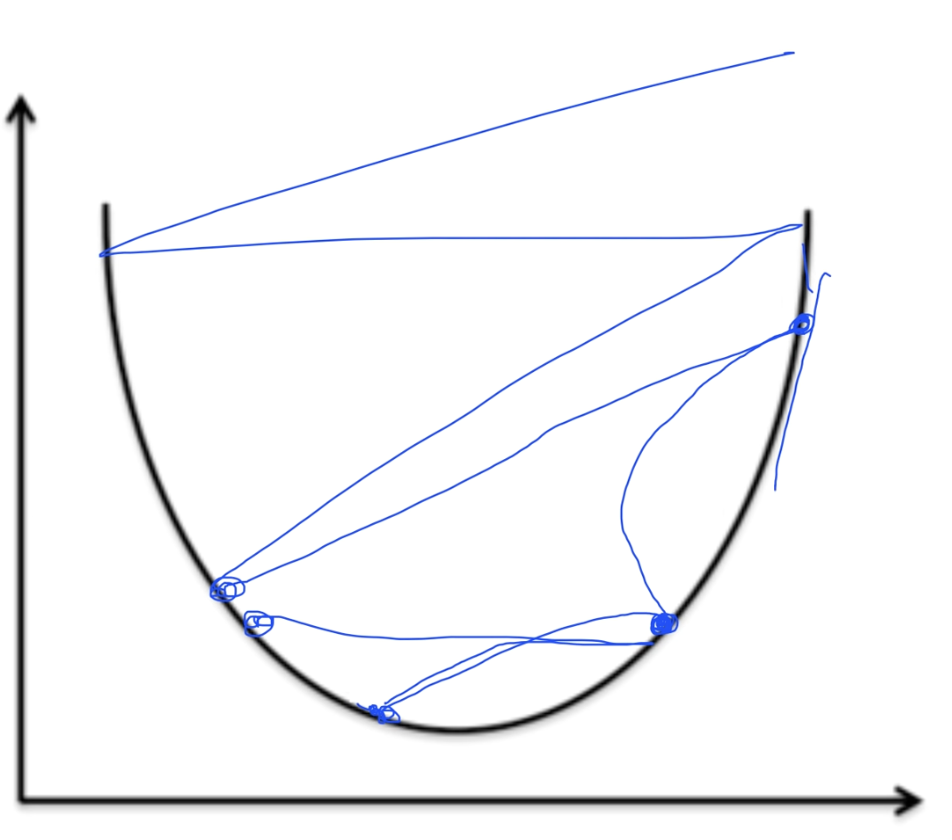
한 번에 많이 이동하게되어, 결국 마지막엔 튕겨서저 나가버린다.
이 증상을 Over shooting 이라고 한다.
ㅤ
ㅤ
Small Learning rate
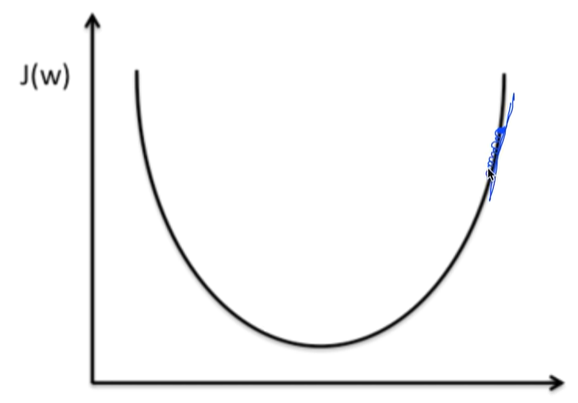
경사를 천천히 내려갈 것이다.
그렇게되면 학습은 되지만 cost를 작게 만드는 값 W가 최적화가 되지않아 학습이 제대로 되지않는다.
따라서 learning rate가 작을 때는 cost값을 계속 확인해야한다.
ㅤ
ㅤ
Try serveral learning rates
- Observe the cost function
- check it goes down in a reasonable rate
처음에는 0.01로 설정해 조금조금씩 움직임을 조정한다.
그러면서 cost값을 계속 확인한다.
ㅤ
ㅤ
ㅤ
ㅤ
Data preprocessing (데이터 전처리)
모델을 학습시키다 보면 가끔 데이터 전처리기 필요한 경우가 생긴다.
예를 들어,
특성이 두 개인 데이터를 가지고 모델을 학습 시킬 때, 특성끼리 값 차이가 얼마 나지 않는다면 아래와 같은 그래프가 나올 것이다.
중간이 파이여있는 2차원 형태로 나차낼 수 있다.
ㅤ
만약 특성 끼리 값 차이가 많이 난다면 어떻게 될까?
좁고 긴 형태를 띠게된다. 이렇게 되면 값이 튀어 나가 모델이 제대로 작동하지 않고 불안정해질 수 있다.
ㅤ
데이터 전처리 쏠림 해결
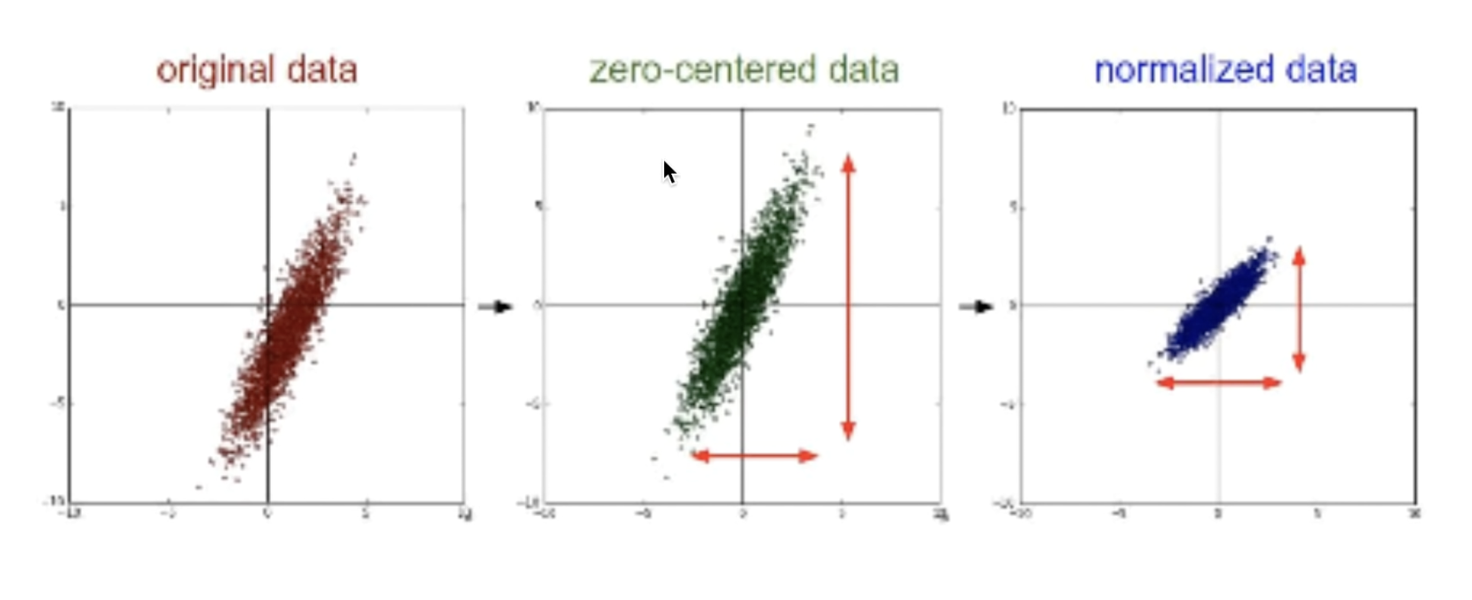
-
zero centered dara
데이터가 어디에 있든 데이터의 중심을 원점으로 움직여주는 역할을 한다. -
normalized data
대이터를 조금 압축시키는 역할을 한다.
ㅤ
대이터 전처리가 필요할 때
- Learning rate는 잘 정의되었지만 over sooting이 발생할 때
- 모델이 제대로 작동하지 않을 때
ㅤ
ㅤ
ㅤ
ㅤ
Standardization
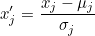
식은 다음과 같다.
평균과 분산으로 간단하게 계산하면 된다.
ㅤ
파이썬 코드는 아래와 같다.
X_std[:, 0] = (X[:, 0] - X[:, 0].mean()) / X[:, 0].std()ㅤ
ㅤ
ㅤ
ㅤ
Overfitting
학습 데이터에만 최적화 되어있어, 실제로 사용해보거나 테스트해보면 잘 맞지않는 경우가 있다.
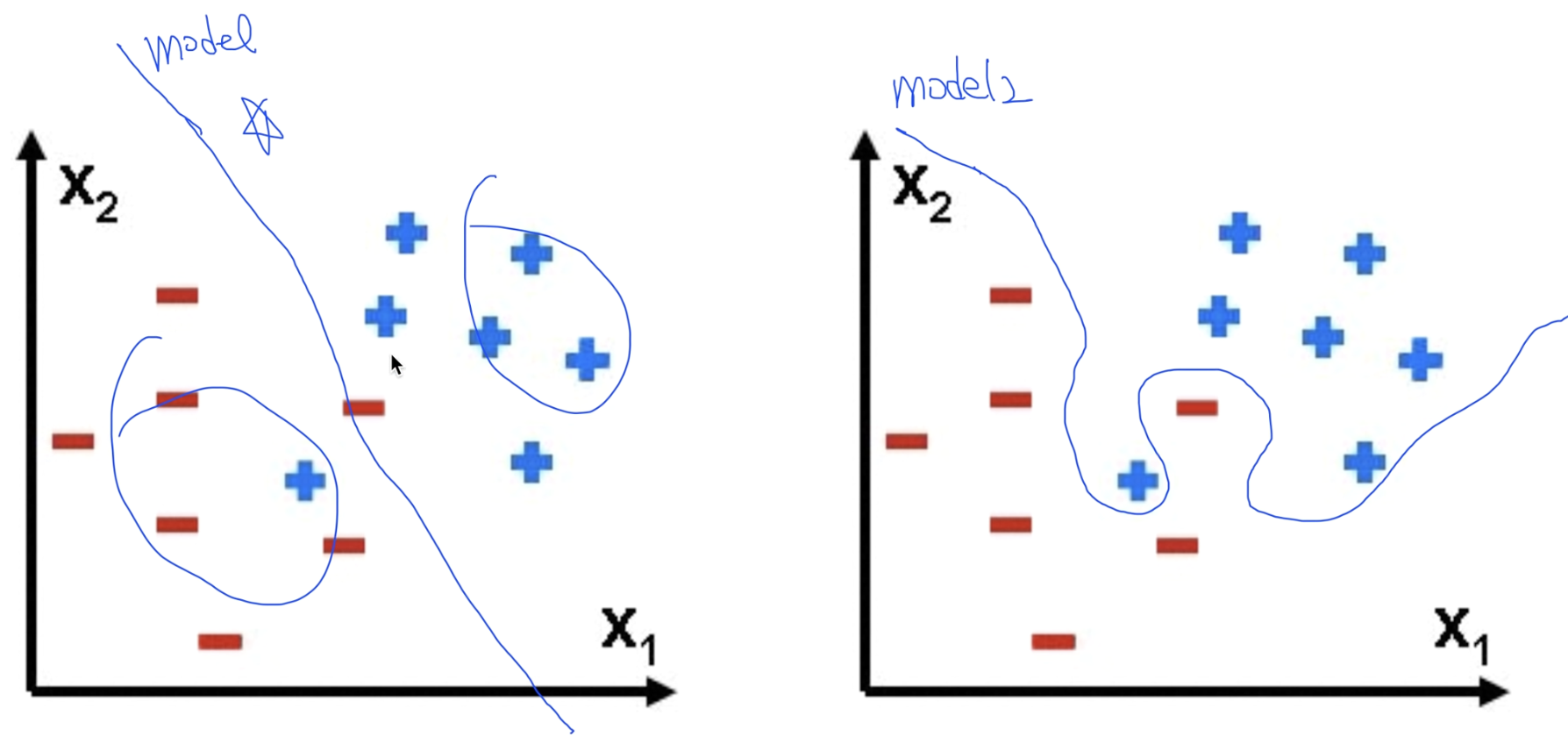
위 데이터에서 왼쪽이 Overfitting이 생기지 않은, 오른쪽이 Overfitting이 발생한 데이터이다.
ㅤ
ㅤ
ㅤ
ㅤ
Solutions for over fitting
- more training data
- Reduce the number of features
(중복된 피처의 갯수 줄이기) - Regularization
ㅤ
ㅤ
Regularization
Regularization은 일반화 시킨다라고 말한다.
일반화를 시키면 선이 꾸불꾸불하지 않고, 선을 필 수 있도록 해준다.
식은 다음과 같다.
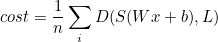
위의 식에서 cost 뒤에
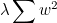
를 더해주면,
ㅤ
각 앨리먼트에 대한 제곱을 각각 더해, 값을 낮춰줌으로써 꾸불꾸불한 선을 더 필 수 있을 것이다.
앞에 붙은 λ는
Regularization strength라고 부른다.
ㅤ
Regularization strength가 0이라면
Regularization을 쓰지 않을 것이라 해석되고,
0.01과 같은 숫자라면
숫자만큼 사용한다고 해석할 수 있다.

이런 유용한 정보를 나눠주셔서 감사합니다.