
Overfitting
overfitting이 되면 데이터를 과하게 학습해버리기 때문에 새로운 테스트 데이터에 대해 낮은 정확도를 보이게 된다.
한마디로 Overfitting된 모델은 layer의 갯수가 어느 정도까지는 잘 동작하지만, 조금이라도 많아지면 어느 순간부터 오차가 증가하는 것이다.
( training에서는 99%의 예측을 하지만, test에서는 85%의 예측을 한다. / 즉 문제집은 100점인데 시험은 85점과 비슷하다.)
ㅤ
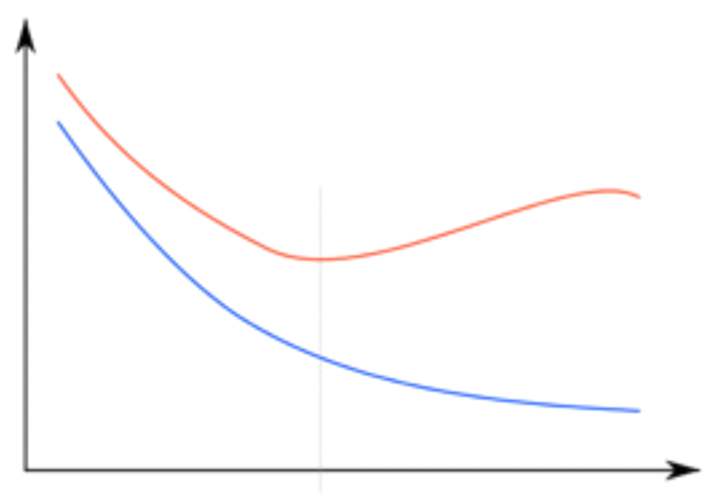
이 상황을 그래프로도 확인할 수 있다.
파란 선은 training set에 대해 동작하는 오차를 나타내고,
빨간 선은 실제 데이터에 대해 동작하는 오차를 나타낸다.
[ x = w(layer), y = error ]
ㅤ
ㅤ
ㅤ
ㅤ
Overfitting 방지
- training data를 많이 모은다.
training set, validation set, test set으로 나누어서 진행하고,
영역별 대이터의 크기도 커지기 때문에, overfitting의 확률이 낮아진다.
ㅤ
- 입력 데이터
Feature개수를 줄인다.
서로 비중이 다른 feature이 섞이면 W에 대해 경합을 하면서 좋지 않은 결과가 나온다.
Dropout을 통해 feature을 스스로 줄일 수 있는 방법도 있다.
ㅤ
Regularization한다.
W이 너무 큰 값을 갖지 않도록 제한한다.
선이 구부러지는 형태를 피할 수 있다.
ㅤ
ㅤ
l2reg (엘투 Regularization)
l2reg = 0.001 * tf.reduce_sum(tf.square(W))regularization에서 가장 많이 사용하는 방법은 l2reg이다.
보통 l2reg는 람다 값을 0.001로 주는데, 중요하다고 생각하면 0.01, 완전 중요하면 0.1로 줄 수 있다.
(즉, 람다 값에 따라 얼마다 regularization을 중요하게 생각하는지 나타낼 수 있다.)
하지만 너무 높은 값을 줘버리면 underfitting이 나타날 수 있다.
ㅤ
ㅤ
Dropout
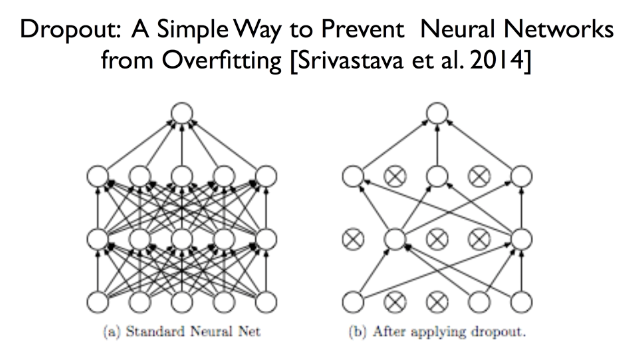
a처럼 복잡하게 연결된 몇몇의 노드를 b와 같이 인위적으로 끊는 방법이다.
( 노드를 끊을 때는 랜덤하게 끊는다. )
학습 시킬 때는 몇개의 노드를 끊어놓고, 예측할 때는 모든 노드를 다시 연결해서 예측한다.
ㅤ
ㅤ
Ensemble (앙상블)
컴퓨터가 많고 학습 데이터가 많을 때 사용할 수 있다.
여러개의 데이터를 training set으로 나누어 각각 학습시킨다.
이렇게 되면 모델의 초기값이 다르기 때문에 결과가 다르게 나올 것이다. 이후 모델을 통합시켜준다.
이 방법을 사용하면 더 좋은 정확도를 볼 수 있다 (4 ~ 5% 까지의 성능이 향상된다.).
