
lec 10-2
Contents
- Vanishing gradient
- RBM
ㅤ
ㅤ
ㅤ
ㅤ
앞의 강의에서, 층이 깊을 때는 학습이 잘 되지 않는다고 말했다.
그 문제를 해결하기 위해 ReLu라는 새로운 atctivation function을 적용했었다.
이번에는 이 문제를 해결하기 위한 다른 방법을 알아볼 것이다.
ㅤ
ㅤ
ㅤ
ㅤ
Vanishing gradient
Hintion 교수님이 기존에 학습이 잘 되지 않는다고 했던 이유 중 하나가 잘못된 방법으로 가중치를 초기화했기 때문이라고 말했다.
이전의 ReLu를 사용하는 코드에서는, w의 초기값에 따라 학습 속도가 달랐졌다.
초기값을 모두 0으로 초기화한다면 Sigmoid 때문에 계속 값이 작아져서 뒤로 갈수록 학습이 이루어지지 않게되는 것이다.
그렇다면 초기값은 어떻게 설정해야할까?
ㅤ
ㅤ
ㅤ
ㅤ
RBM
절대로 모든 초기값을 0을 주어서는 안된다.
ㅤ
ㅤ
초기값을 정하는 문제는 Restricted Boatman Machine(RBM)이라는 원리를 이용해 풀 수 있다.
이 RBM을 사용해서 초기화시키 네트워크를 Deep Belief Net이라고 부른다.
ㅤ
ㅤ
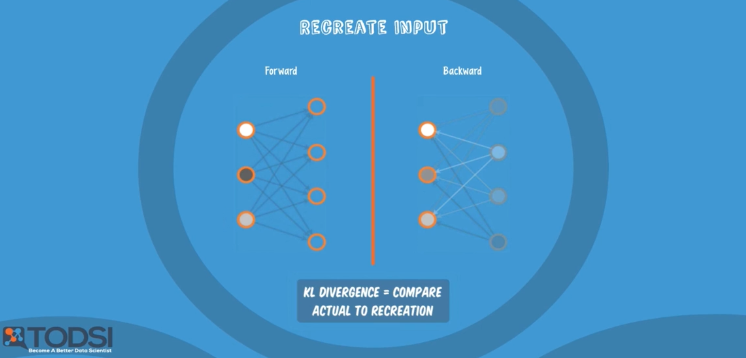
RBM은 현재 layer와 다음 layer에 대해서만 동작한다.
(forward)- 현재 layer에 들어온 x값에 대해 weight을 계산한 값을 다음 layer에 전달한다.(backward)- 이렇게 전달 받은 값을 거꾸로 이전(현재) layer에 weight 값을 계산해서 전달한다.
forward와 backward 계산을 반복해서 진행하면, 최초 전달된 x와 예측한 값(xHat)의 차이가 최소가 되는 w을 발견하게 된다.
ㅤ
ㅤ
RBM은 앞에 설명한 내용을 2개 layer(현재와 다음)에 대해 초기값을 결정할 때까지 반복하고, 다음 레이어를 또 반복하고, 이것을 마지막 layer까지 반복하는 방식이다.
그리고 이렇게 초기값을 구하는 과정을 pre-training이라고 부른다.
ㅤ
ㅤ

첫 번째 그림에서 layer의 w을 초기화하고, 두 번째 그림에서 w을 초기화하고, 세 번째 그림까지 진행하면 전체 layer에서 사용하는 모든 weight이 초기화된다.
이 과정으로 모델을 학습시키는데에는 오랜 시간이 걸리지 않아, 학습(learning)이 아닌 Fine training이라고 부른다.
ㅤ
ㅤ
하지만 RBM을 굳이 사용할 필요는 없다.
간단하게 w을 초기화하는 다른 방법이 있기 때문이다.
그것은 바로 Xavier initialization이다.
Xavier initialization은 각 노드에서 입력과 출력의 갯수에 맞게 w을 초기화한다.

