-
Inference
Used to answer queries about PM, e.g., PM(X∣Y)
-
Learning
Used to estimate a plausible model M from data D
Query
1. Likelihood
- Evidence e is an assignment of values to a set E variables in the domain.
- E={Xk+1,...,Xn}
- Simplest query:
P(e)=x1∑...x2∑P(x1,...,xk,e)
- this is often referred to as computing the likelihood of e
- Notice that E and X1,...,Xk are disjoint set.
2. Conditional Probability
P(X∣e)=P(e)P(X,e)=∑xP(x=x,e)P(X,e)
P(X∣e) is the a posteriori belief in X, given evidence e.
- Marginalization: the process of summing out the "unobserved" or "don't care" variables z is called.
P(Y∣e)=z∑P(Y,Z=z∣e)
3. Most Probable Assignment
- most probable joint assignment (MPA) for some variables of interest.
- What is the most probable assignment of
maxx1,...,x4P(x1,...,x4∣e)? where e is the evidence, and x1,...,x4 are random variables of interest?MPA(Y∣e)=arg maxy∈Y P(y∣e)=arg maxy∈Yz∑P(y,z∣e)
- maximum a posteriori configuration of Y.
- Used in classification / explanation tasks.
example)
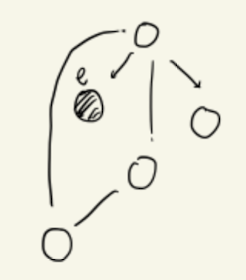
P(X1,X2,X3,X4,E)
Now we want,
maxx1,...,x4P(x1,...,x4∣e)
How can we compute the Posterior Distribution?
Applications of A Posteriori Belief
- Prediction: what is the probability of an outcome given the starting condition?
A=>B=>C
- Diagnosis: what is the probability of disease/fault given symptoms?
A=>B=>C
Landscape of inference algorithms
Exact inference algorithms (Classical)
- Elimination algorithms
- Message-passing algorithms (sum-product, belief propagation)
- Junction tree algorithms
Approxmiate inference techniques (Modern)
- Stochastic simulation / sampling methods
- Markov chain Monte Carlo methods
- Variational algorithms
Variable Elimination
A=>B=>C=>D=>E
- Query: P(e)
P(e)=d∑c∑b∑a∑P(a,b,c,d,e)=d∑c∑b∑a∑P(a)P(b∣a)P(c∣b)P(d∣c)P(e∣d)
- Eliminate nodes one by one all the way to the end,
P(e)=d∑P(e∣d)p(d) The computational complexity of the chain elimination is O(n∗k2) where n is number of elimination steps, and k is the dimension of the Vector.
Example) Markov Chain
Let transition matrix M be a 3x3 matrix in a markov chain, where there are three states.
- Let X, nodes in a markov chain be the state that
- What is the probability distribution of a random walk the the transition matrix, M?
p(x5=i∣x1=1)=x4,x3,x2∑p(x5∣x4)p(x4∣x3)p(x3∣x2)p(x2∣x1=1)=[M4v]i
- What is the probability distribution of a random walk when t→∞?
If we denote the stationary distribution as π,The problem formation above looks similar to the eigenvalue decomposition form, Mv=λv, with λ=1.(πM)T→MTπT=1∗πT In other words, the transposed transition matrix MT has eigenvectors as πT with eigenvalue of 1.
We can find the stationary distribution of a given transition matrix through eigenvalue decomposition of the transition matrix. Stationary distribution is the eigenvector with λ=1.
Message Passing
- Doesn't work in a cyclical graph
Message backpropagation can be stuck in a cycle.
- Variable Elimination through Message Passing allows us to marginalize out unnecessary variables, with better Complexity.
Example: Variable Elimination
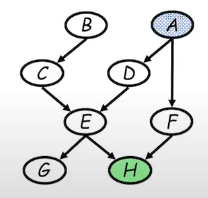
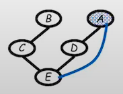
-
Given the graph above, what is the posterior probability, P(A∣h)?
-
Initial factors:
P(a,b,c,d,e,f,g)=P(a)P(b)P(b∣c)P(d∣a)P(e∣c,d)P(f∣a)P(g∣e)P(h∣e,f)
Joint probability factorizes in such manner because the graph is a directed model.
-
Choose elimination order: H,G,F,E,D,C,B
-
Step1:
- Conditioning (fix the evidence node h on its observed value h~
mh(e,f)=p(h=h~∣e,f)mh(e,f)=h∑p(h∣e,f)σ(h=h~)
where σ(h=h~) is a dirac-delta function.
So far we have removed P(h=h~∣e,f), and introduced a new term mh(e,f). Now e and f become dependent.
Through introducing a term for Message Passing, we are essentially converting a Directed Graphical Model to an Undirected Graphical Model.
Delta function is a function with 1 on the value that the observation h holds and 0, otherwise.
Now,
P(a)P(b)P(b∣c)P(d∣a)P(e∣c,d)P(f∣a)P(g∣e)P(h∣e,f)→P(a)P(b)P(b∣c)P(d∣a)P(e∣c,d)P(f∣a)P(g∣e)mh(e,f)
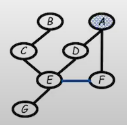
- Step2:
-Eliminate G
Since there is no term that depends on G, we can eliminate G without having to introduce any new message factor.mg(e)=g∑P(g∣e)=1
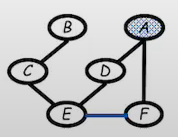
- Step3:
-Eliminate F
If we eliminate F, we need to connect (E,A) together, since a new factor will be introduced to make them dependent.
P(a)P(b)P(b∣c)P(d∣a)P(e∣c,d)P(f∣a)P(g∣e)P(h∣e,f)→P(a)P(b)P(b∣c)P(d∣a)P(e∣c,d)P(f∣a)P(g∣e)mh(e,f)→P(a)P(b)P(b∣c)P(d∣a)P(e∣c,d)mf(a,e)
- Step4:
-Eliminate Eme(a,c,d)=e∑p(e∣c,d)mf(a,e)
P(a)P(b)P(b∣c)P(d∣a)P(e∣c,d)P(f∣a)P(g∣e)P(h∣e,f)→P(a)P(b)P(b∣c)P(d∣a)P(e∣c,d)P(f∣a)P(g∣e)mh(e,f)→P(a)P(b)P(b∣c)P(d∣a)P(e∣c,d)mf(a,e)→P(a)P(b)P(b∣c)P(d∣a)me(a,c,d)
md(a,c)=d∑P(d∣a)me(a,c,d)
P(a)P(b)P(c∣b)P(d∣a)P(e∣c,d)P(f∣a)P(g∣e)P(h∣e,f)→P(a)P(b)P(c∣b)P(d∣a)P(e∣c,d)P(f∣a)P(g∣e)mh(e,f)→P(a)P(b)P(c∣b)P(d∣a)P(e∣c,d)mf(a,e)→P(a)P(b)P(c∣b)P(d∣a)me(a,c,d)→P(a)P(b)P(c∣b)md(a,c)
-
Step5:
-Eliminate C
-
Step6:
-Eliminate B
mb(a)=b∑p(b)mc(a,c)
P(a)P(b)P(c∣b)P(d∣a)P(e∣c,d)P(f∣a)P(g∣e)P(h∣e,f)→P(a)P(b)P(c∣b)P(d∣a)P(e∣c,d)P(f∣a)P(g∣e)mh(e,f)→P(a)P(b)P(c∣b)P(d∣a)P(e∣c,d)mf(a,e)→P(a)P(b)P(c∣b)P(d∣a)me(a,c,d)→P(a)P(b)P(c∣b)md(a,c)→P(a)P(b)mc(a,b)→P(a)mb(a)
- Final Step:
-Wrap-up
We have created message passing from A to H, using graph elimination. Since the initial state we were eliminating from was the joint distribution of the variables in the graph, we can finally calculate the conditional distribution, P(a∣h~).
p(a,h~)=p(a)mb(a) p(h~)=a∑p(a)mb(a) →P(a∣h~)=∑ap(a)mb(a)p(a)mb(a)
- Complexity Analysis
If we were to integrate every single variables, the complexity would be O(K6), since we are marginalizing out 6 Variables. However, through Message Passing, at each step the complexity would be O(K2), resulting in total of 6∗O(K2)
Overview of Graph elimination
-
Begin with the undirected GM or moralized Bayesian Network (meaning changing the Directed Graph to an Undirected Graph.
-
Graph G(V,E) and elimination ordering I
-
Eliminate next node in the ordering I
- Removing the node from the graph
- Connecting the remaining neighbors of the nodes
-
The reconstituted graph G′(V,E′)
- Retain the edges that were created during the elimination procedure
- The graph-theoretic property: the factors resulted during variable elimination are captured by recording the elimination clique. (Notice that Intermediate terms of form mx(Y,Z) correspond to the cliques resulted from elimination.
