〰️ 내용
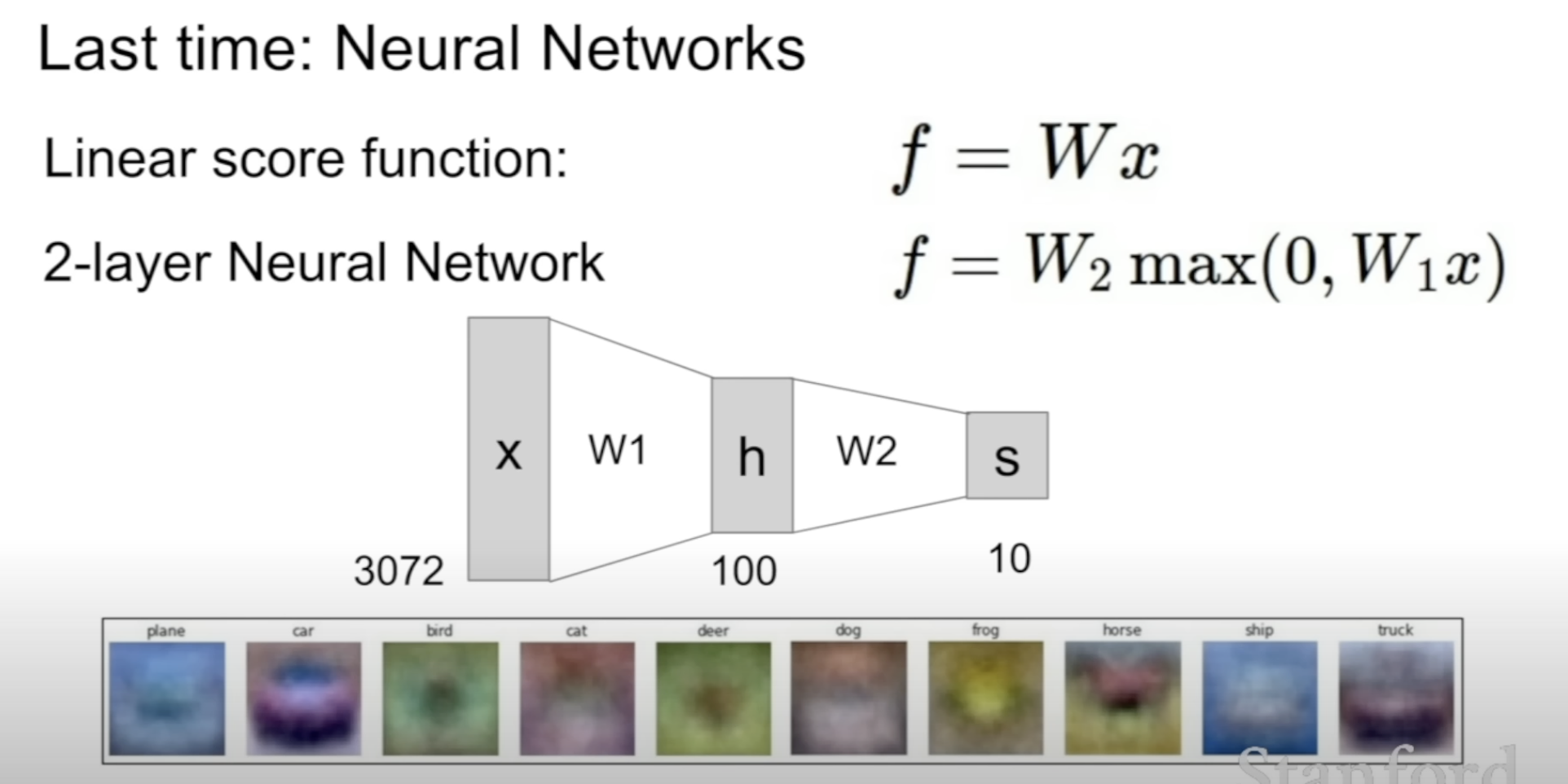
We get a Neural Network by stacking the linear layers on top of each other
with non-linearity in between
[1] Work done before modern CNN and usage
Yann LeCun : backpropagation to train the CNN applied to document recognition
AlexNet : Take advantage of the large amount of data on the web using GPU
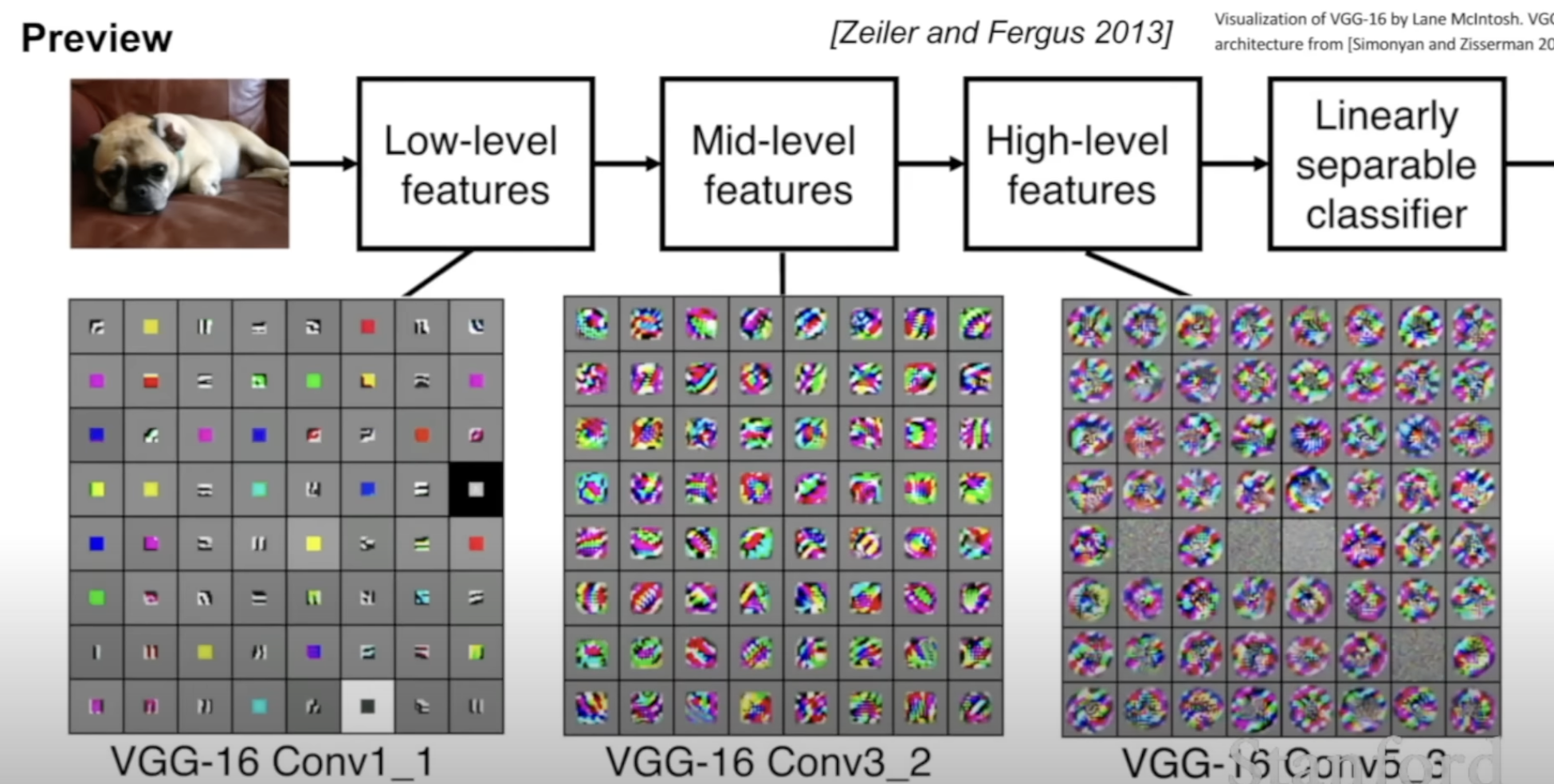
[2] How do CNN work? functional perspective
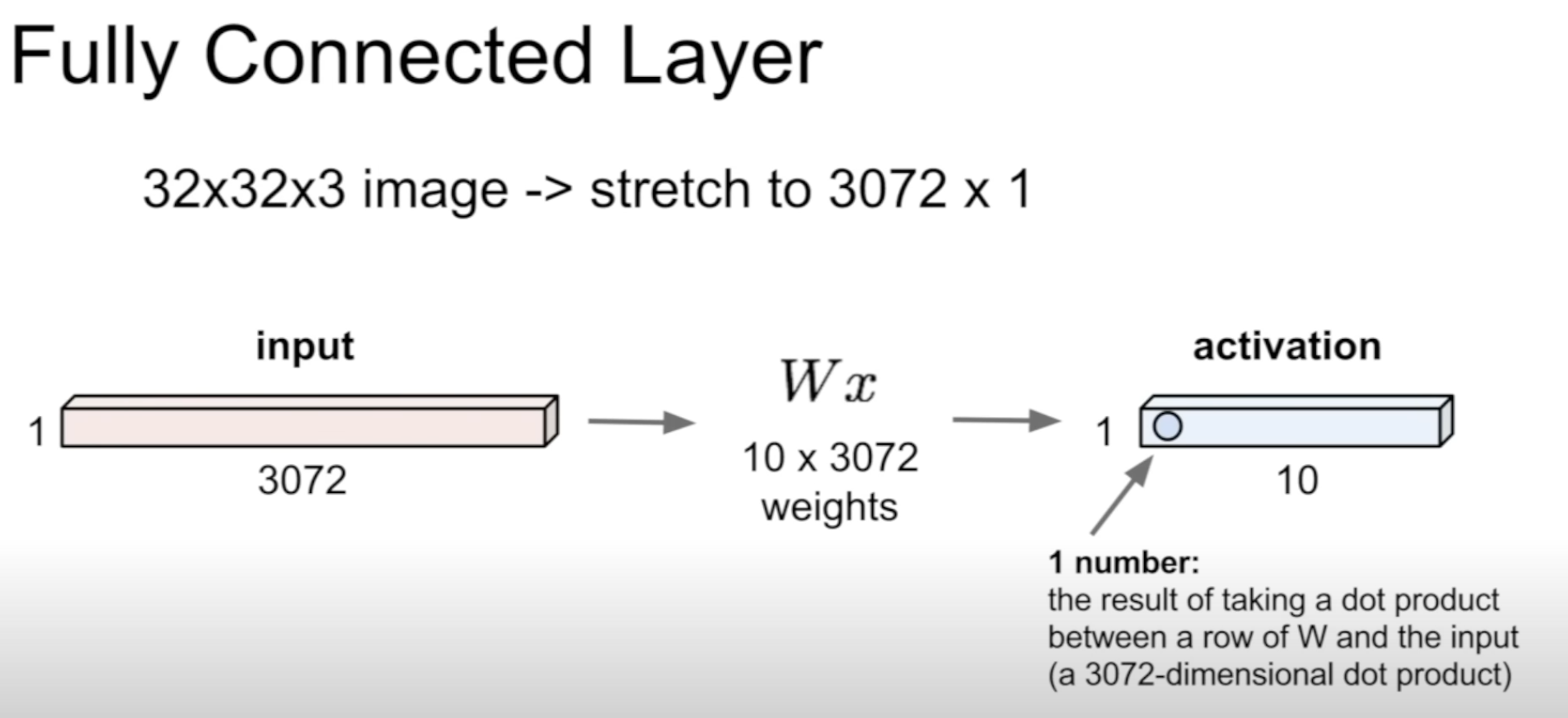
Does not preserve spatial structure
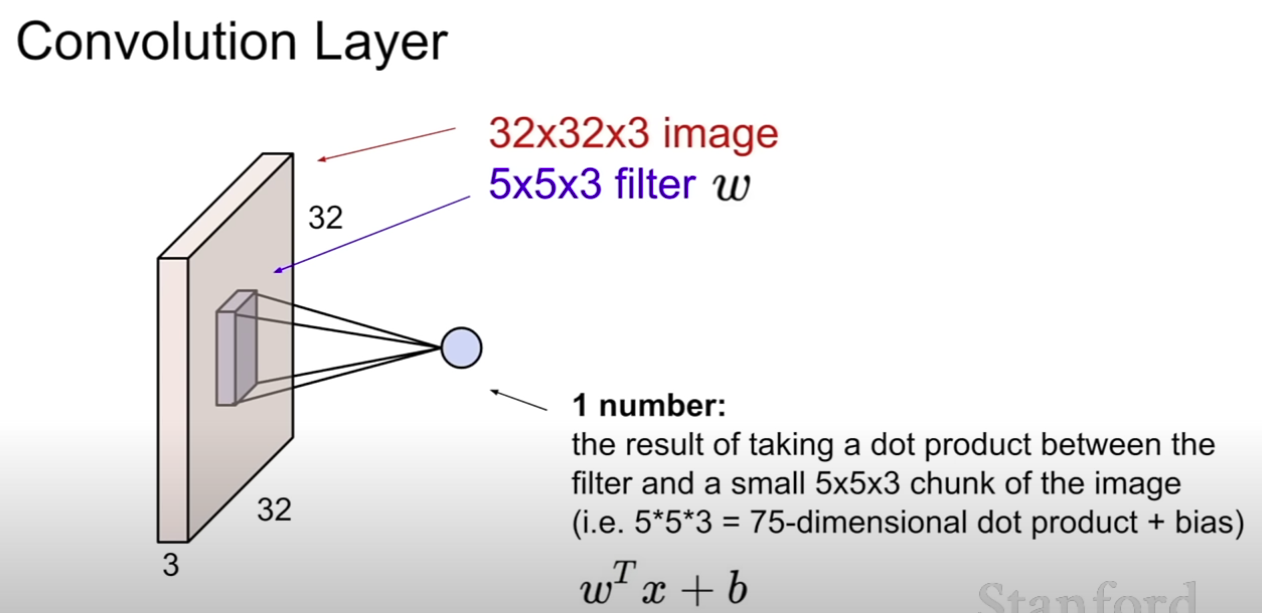
Does preserve spatial structure
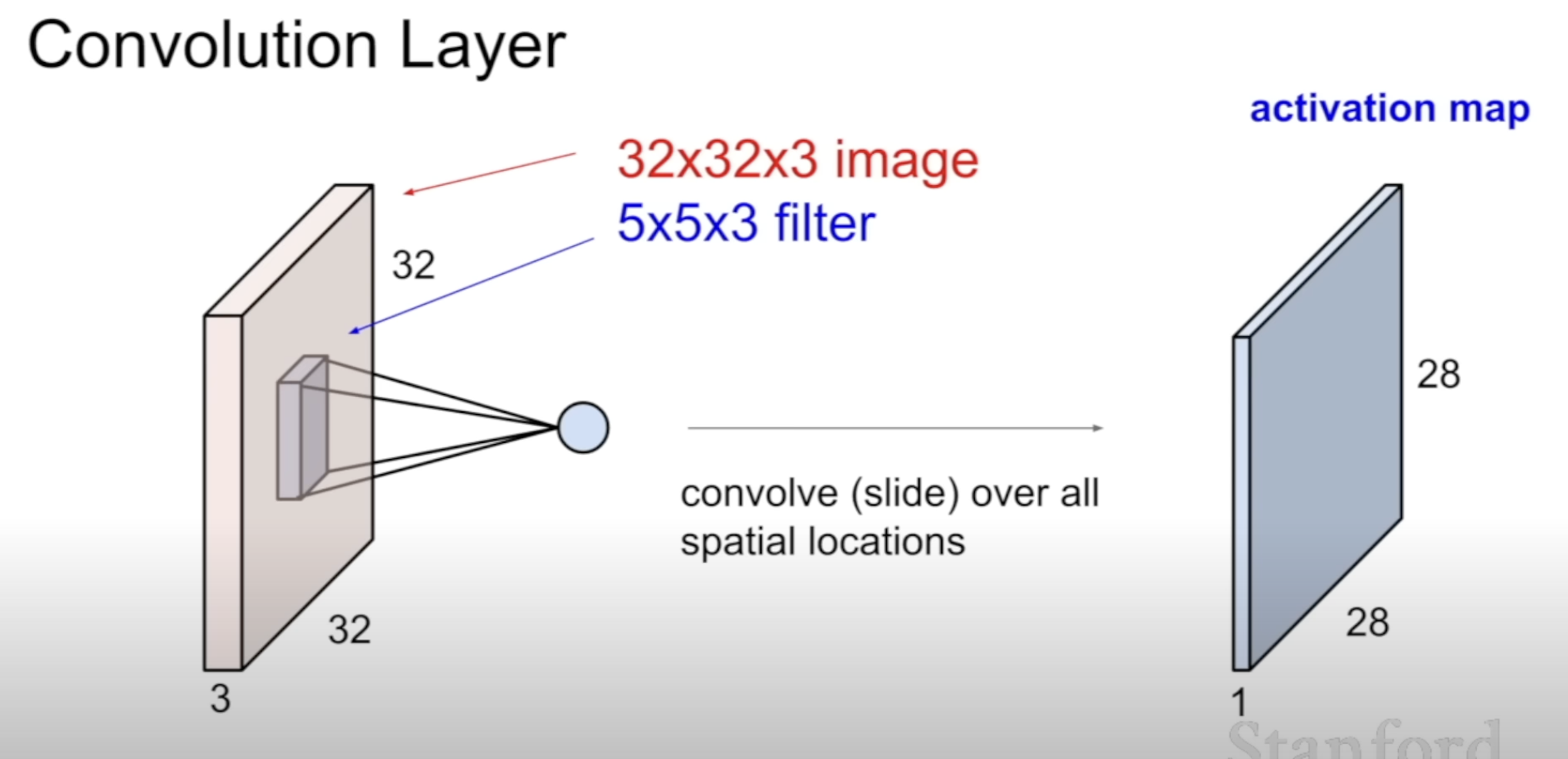
Can be outputted different size depending on the slide
What does the numbers in 32 X 32 X 3 mean?
32 X 32 : square grid of pixels of size 32
3 : depth of the image (RGB)
How exactly is this 28 X 28 activation map produced?
It depends on the filter size & stride
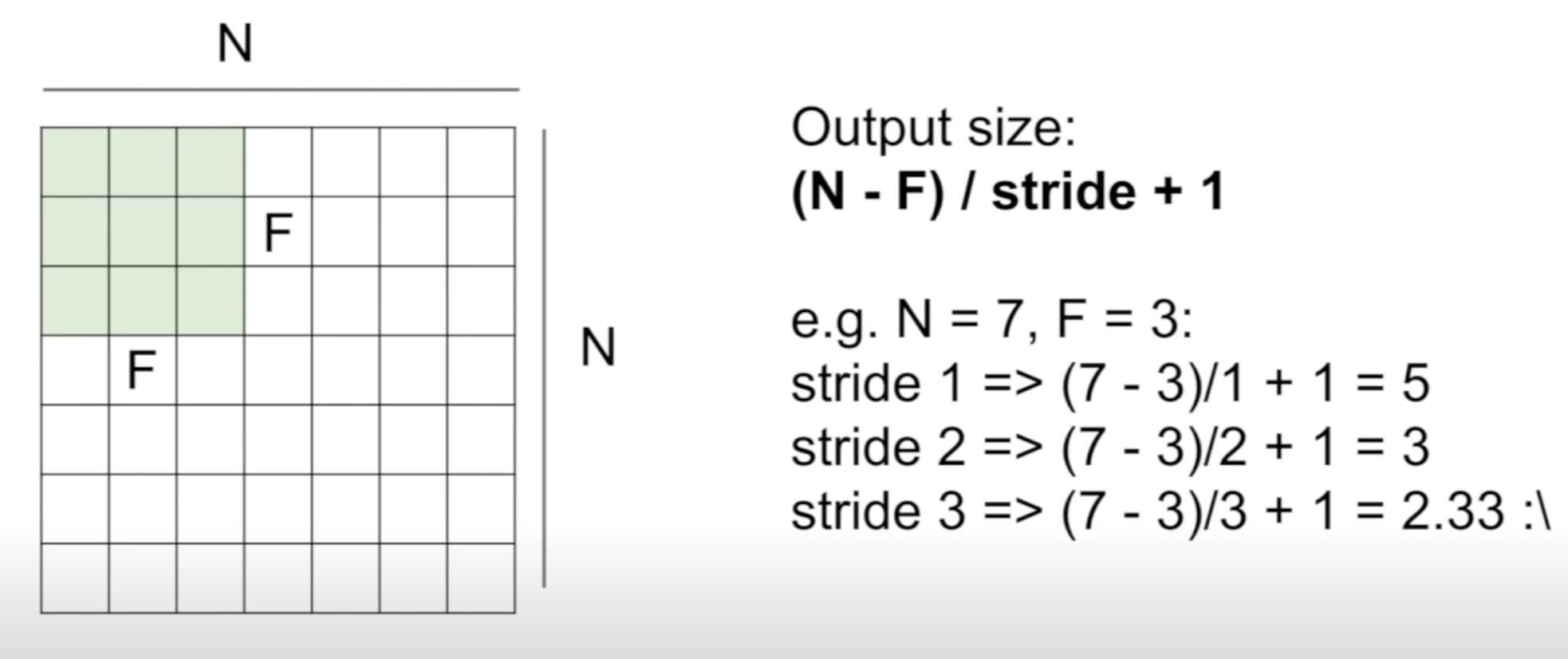
By the formula in this picture, the above is N = 32, F = 5

Zero padding the border to maintain the input size
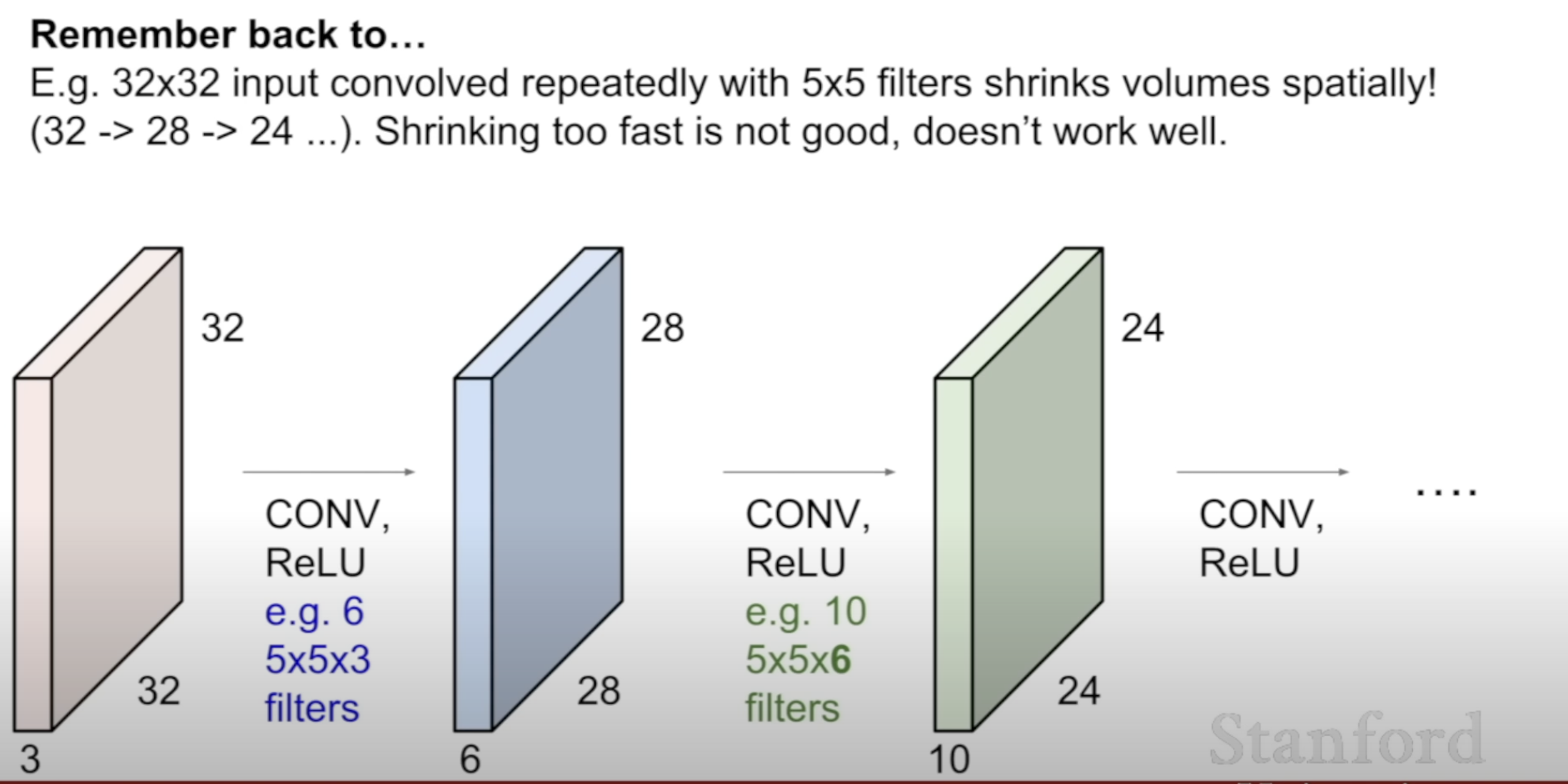
Without padding, size of the input 32 X 32 -> 24 X 24
This is why padding size depends on the F (filter size)
Without padding : (N - F + 1) X (N - F + 1)
With padding : (N - F + 1 + 2P) X (N - F + 1 + 2P)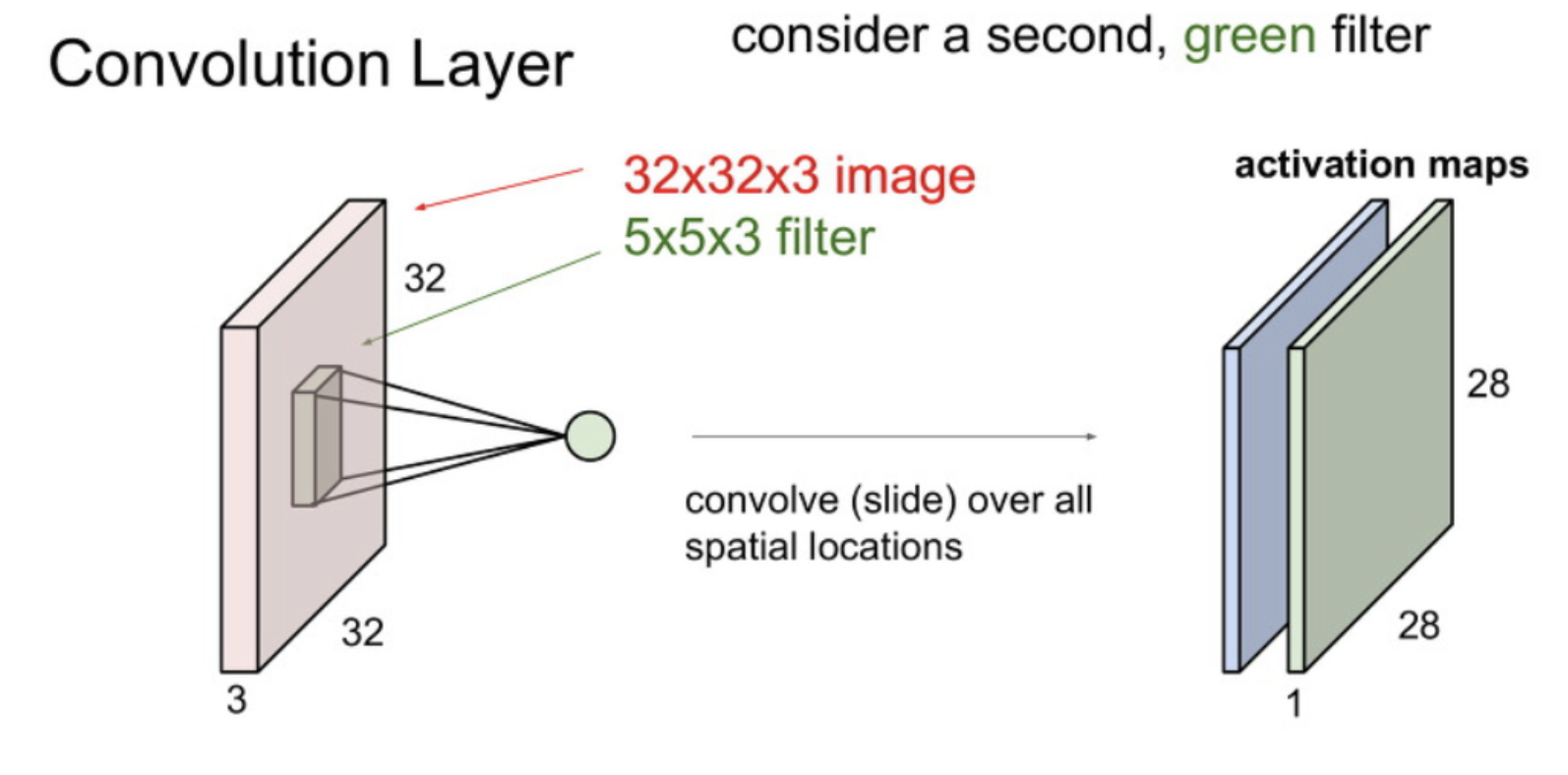
We use various filters to represent different features
each filter produces an activation map
Depending on the filter size, a number is extracted by dot product
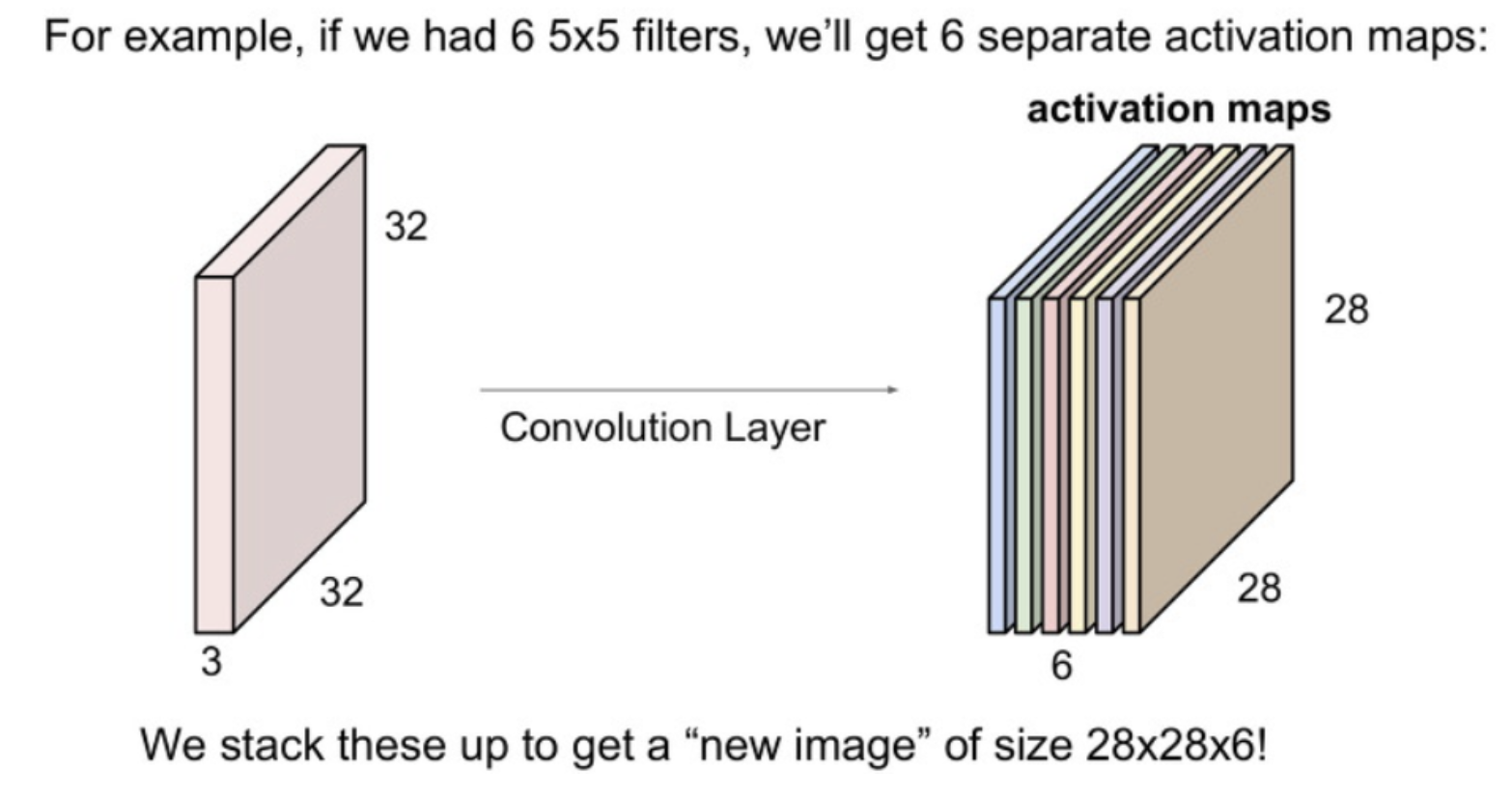
If we use 6 filters, we get a 28 X 28 X 6 output
What we get from stacking up multiple filters

Stride of 1 / 2 is common
Padding is whatever fits to preserve the space
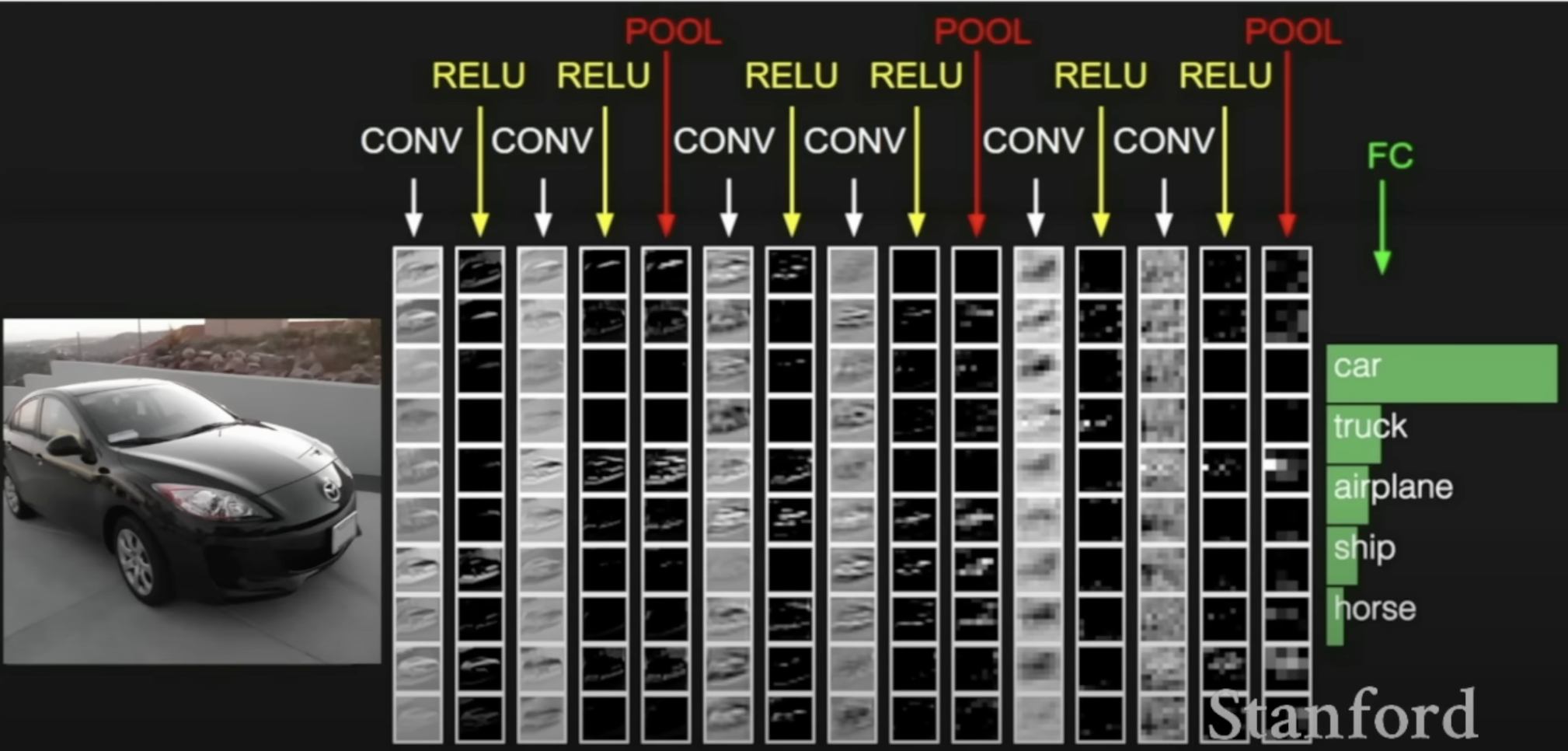
The whole CNN Network : how it works
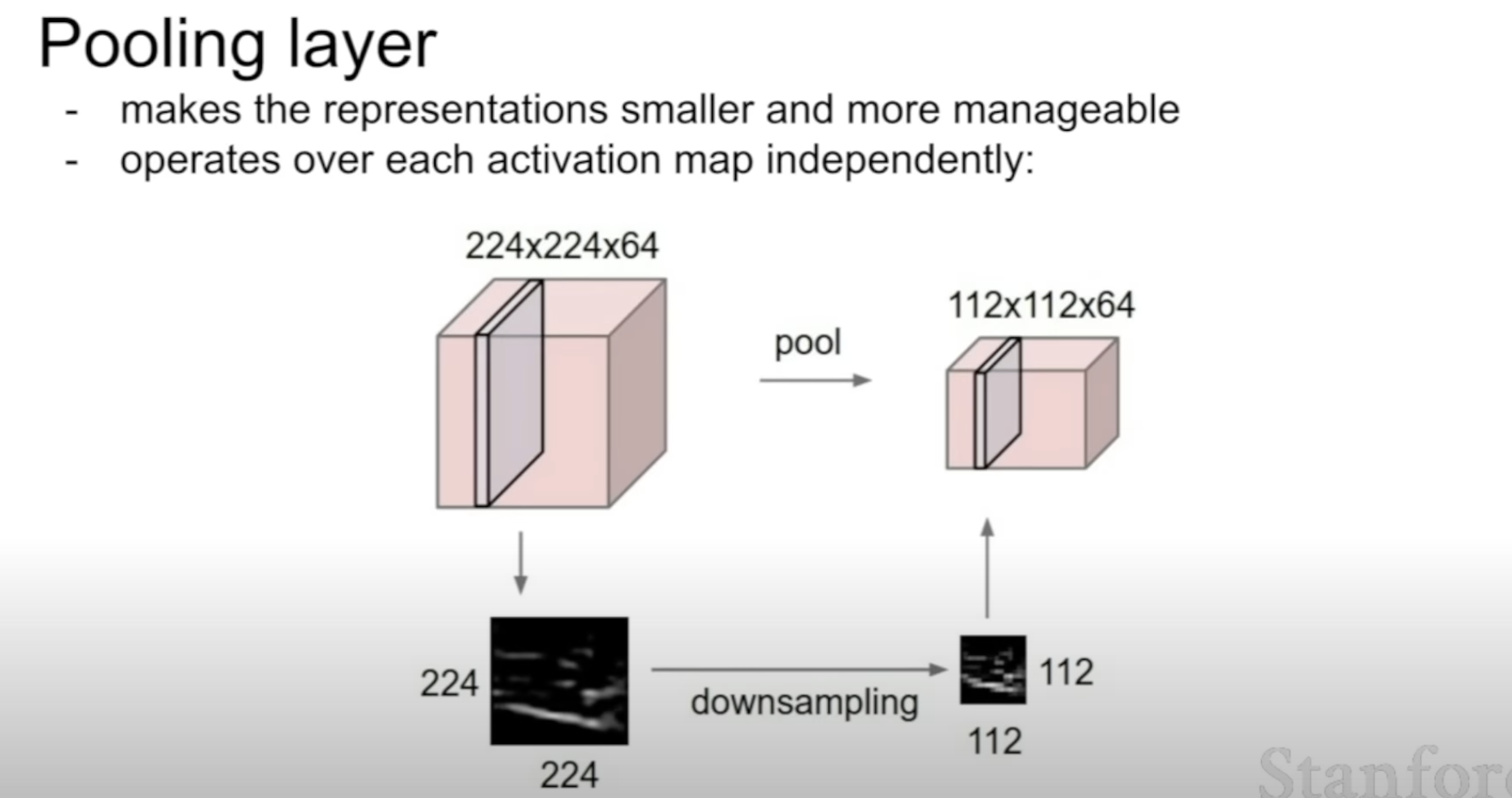
What Pooling layer does
Downsizes spacially, not depth
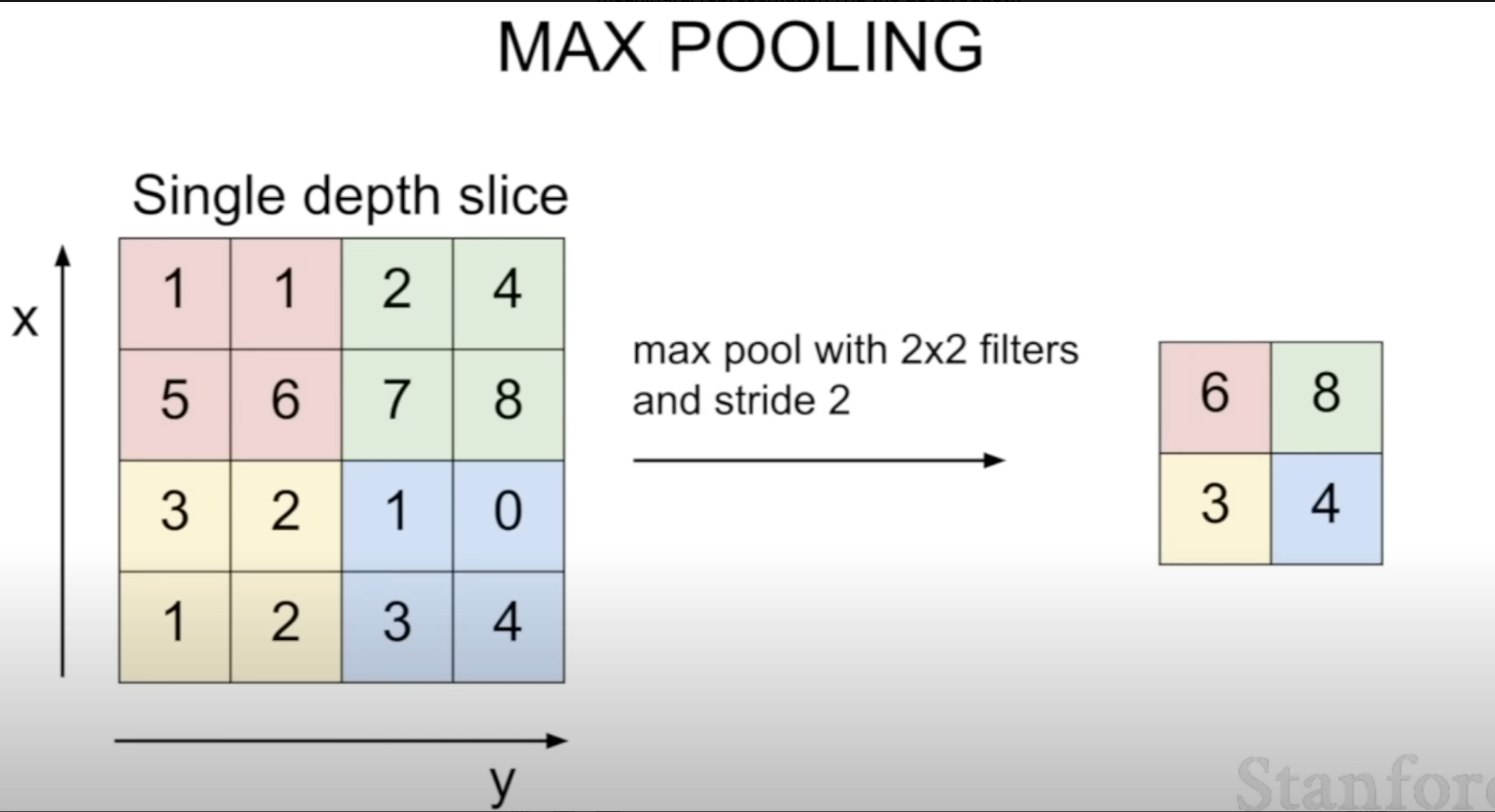
The stride is often chosen in pooling layer to not overlap

Pooling layer summary
〰️ 질문

Due to the padding, 32 X 32 X 10

Each filter has 5 X 5 X 3 + 1 parameters
10 filters, so in total 760 parameters
〰️ 첨언
stride & padding
stride : 몇칸씩 보면서 넘길거임?
작게하면 국소적인 정보까지
크게하면 전체적인 정보를
padding : input size를 유지시켜주려고 zero padding 등이 쓰임
1 x 1 convolution
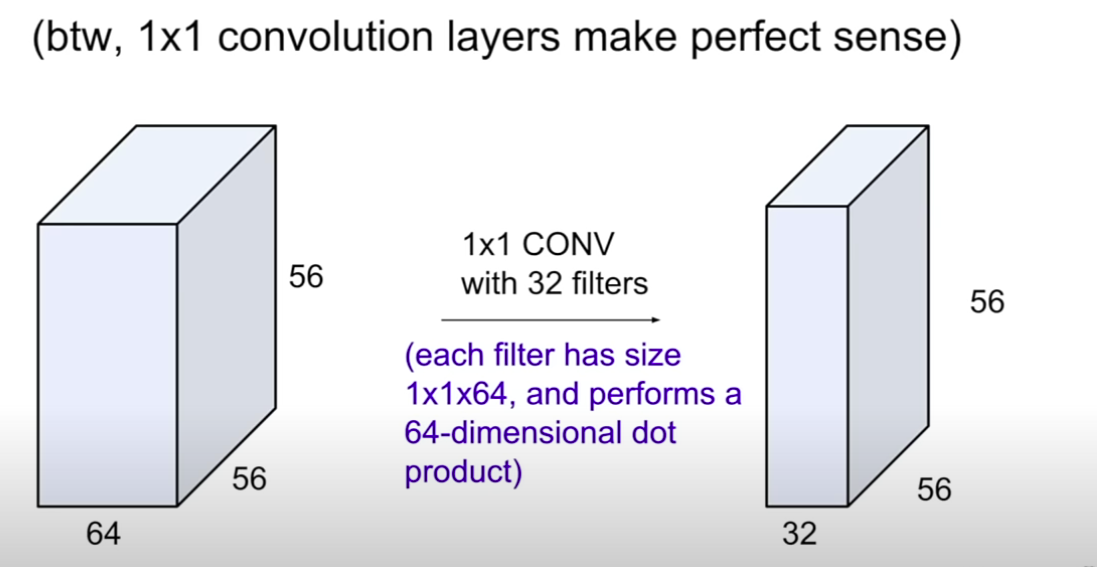
1 x 1 convolution은 64 -> 32로 채널 수를 줄여주는 역할 -> 계산량 감소
1 x 1 convolution은 채널간의 관계를 학습하여, 더 의미있는 feature로 축소
pooling layer : 256 x 256 x 64 -> 128 x 128 x 64 (spacially)
공간 차원을 줄인다
1 x 1 convolution : 256 x 256 x 64 -> 256 x 256 x 32 (depth)
채널 차원을 줄인다
