〰️ 내용
Until now
-
Express functions in terms of in computational graphs
-
Neural Networks, which are linear layers stacked (non-linearities in between)
-
CNN, which are type of NN which use convolution layers to preserve spatial structure
-
learn the weights and parameters through optimization using GD
[1] Activation Functions
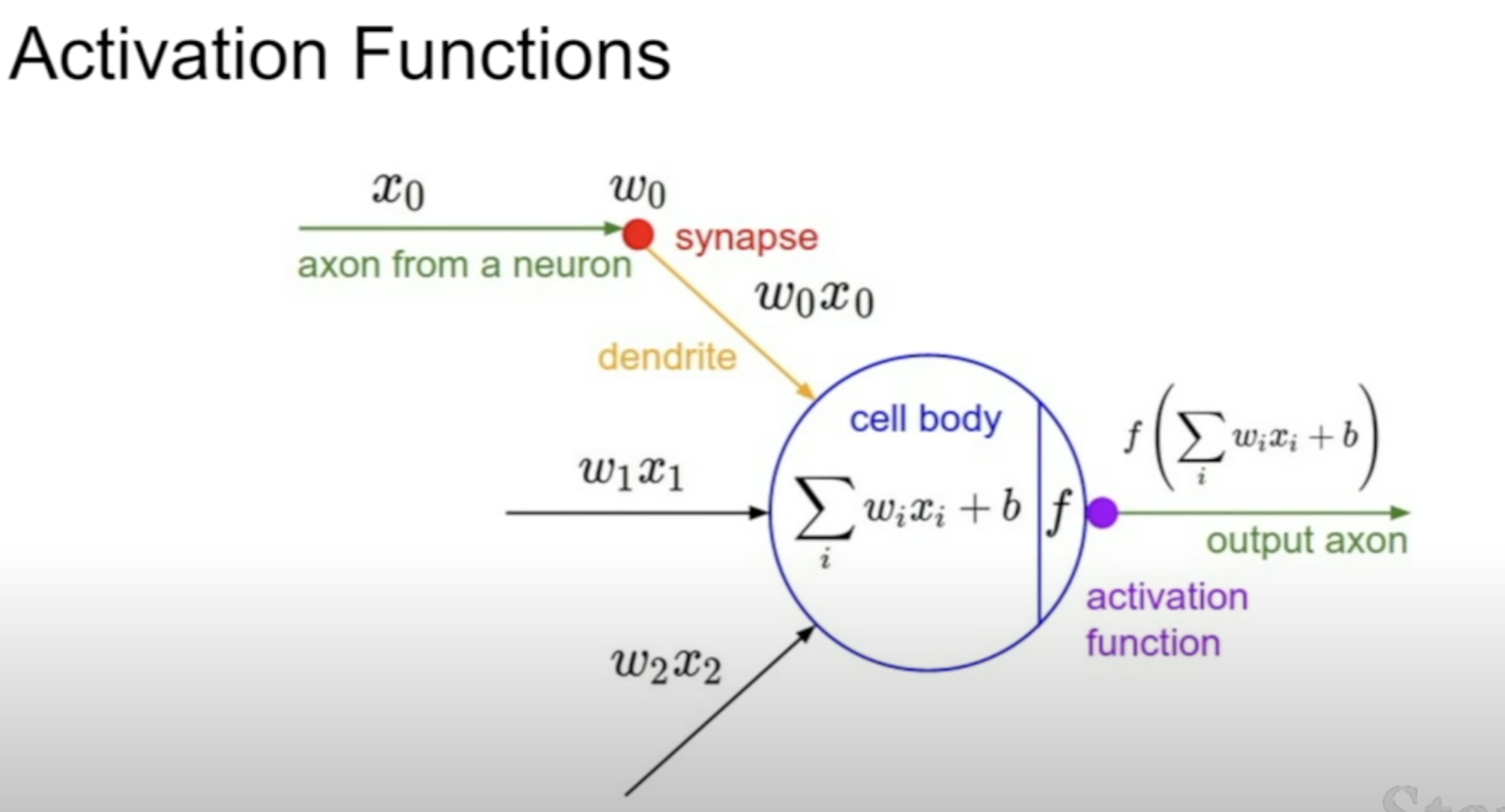
Where Activation Functions are applied in our system (after the matrix mul.)
(1) Sigmoid
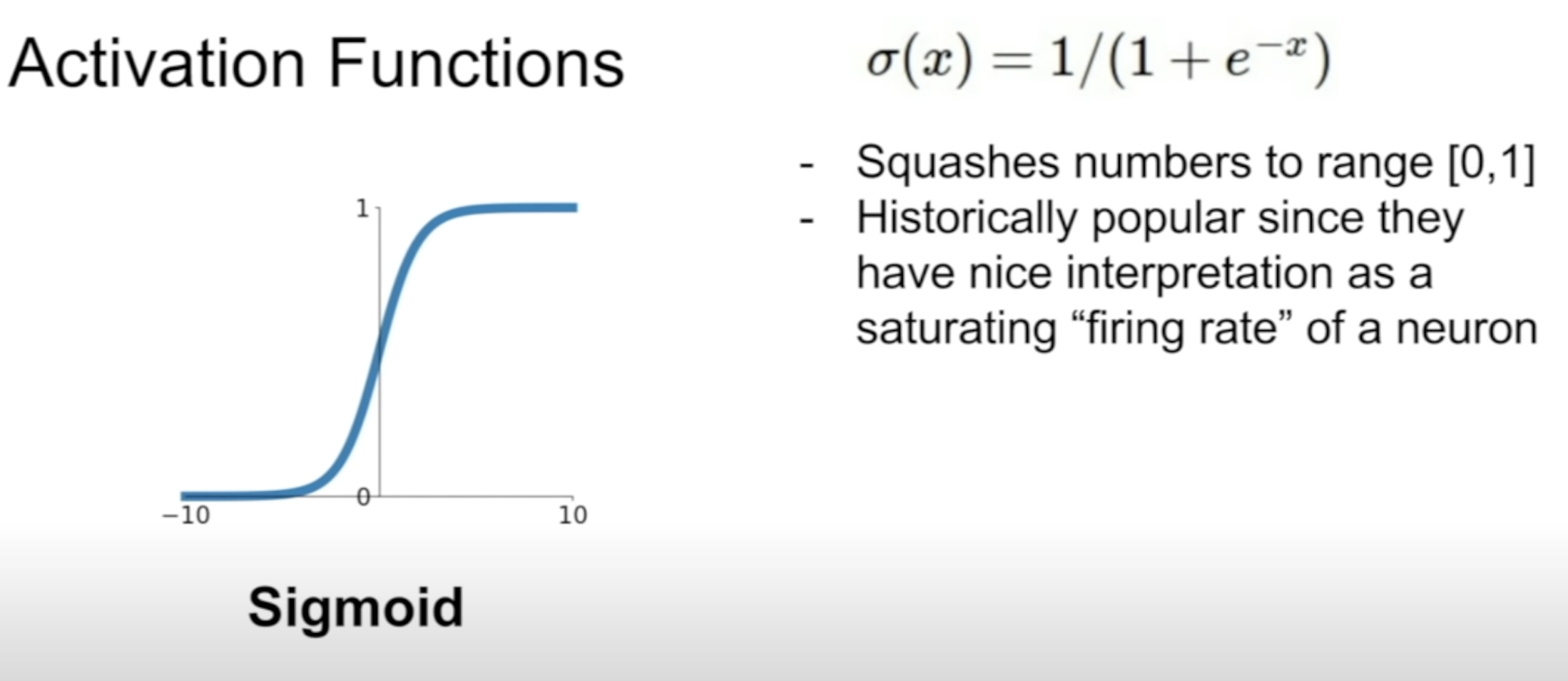
-
squashes the numbers to [0, 1] -> probablity interpretation possible 😃
-
Saturation causes killing gradients
-
Sigmoid outputs are NOT zero-centered
(2) Tanh

- squashes the numbers to [-1, 1]
- Saturation is still killing gradients
- the outputs are zero-centered 😃
(3) ReLU
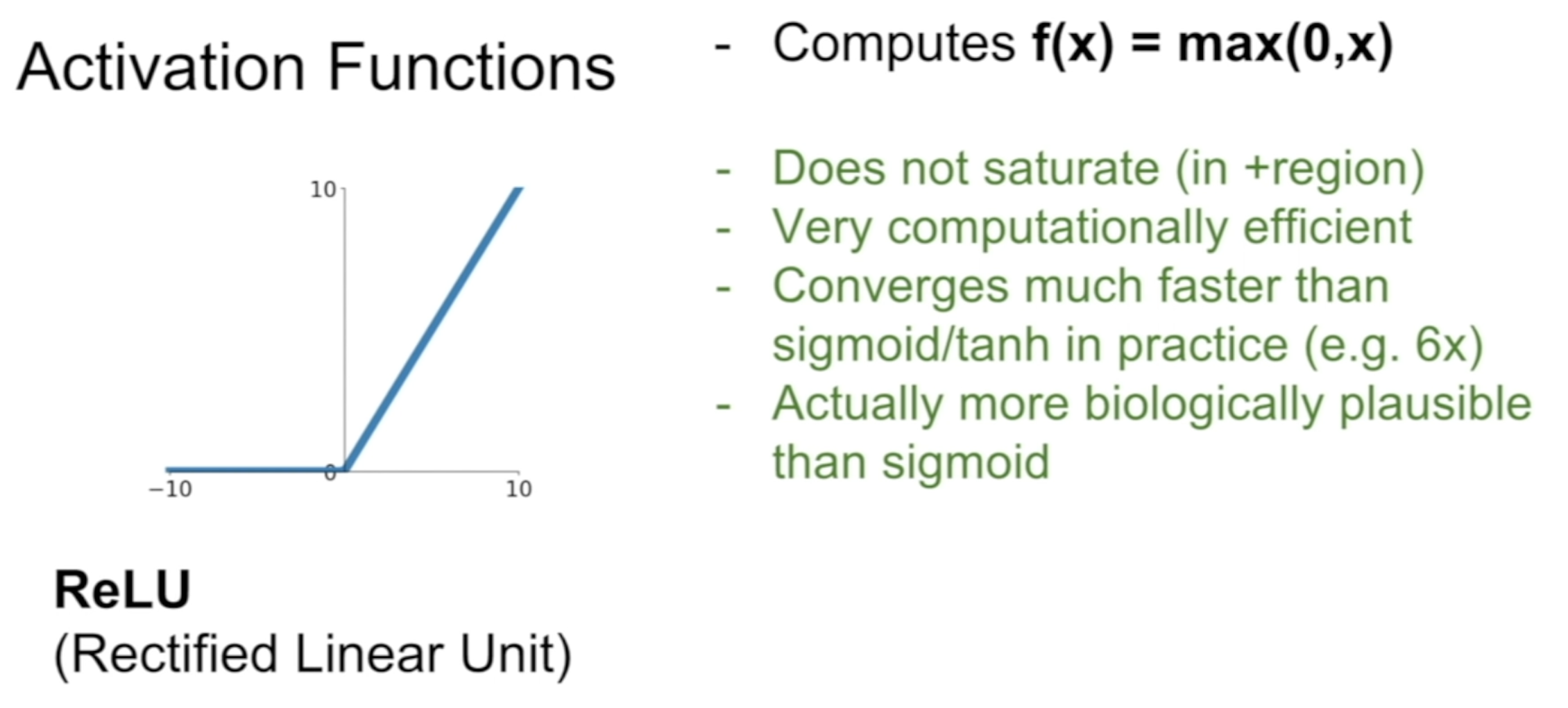
- NO Saturation 😃
- Easy calculation 😃
- NOT zero-centered
- Killing the gradients when x < 0
(4) Leaky ReLU
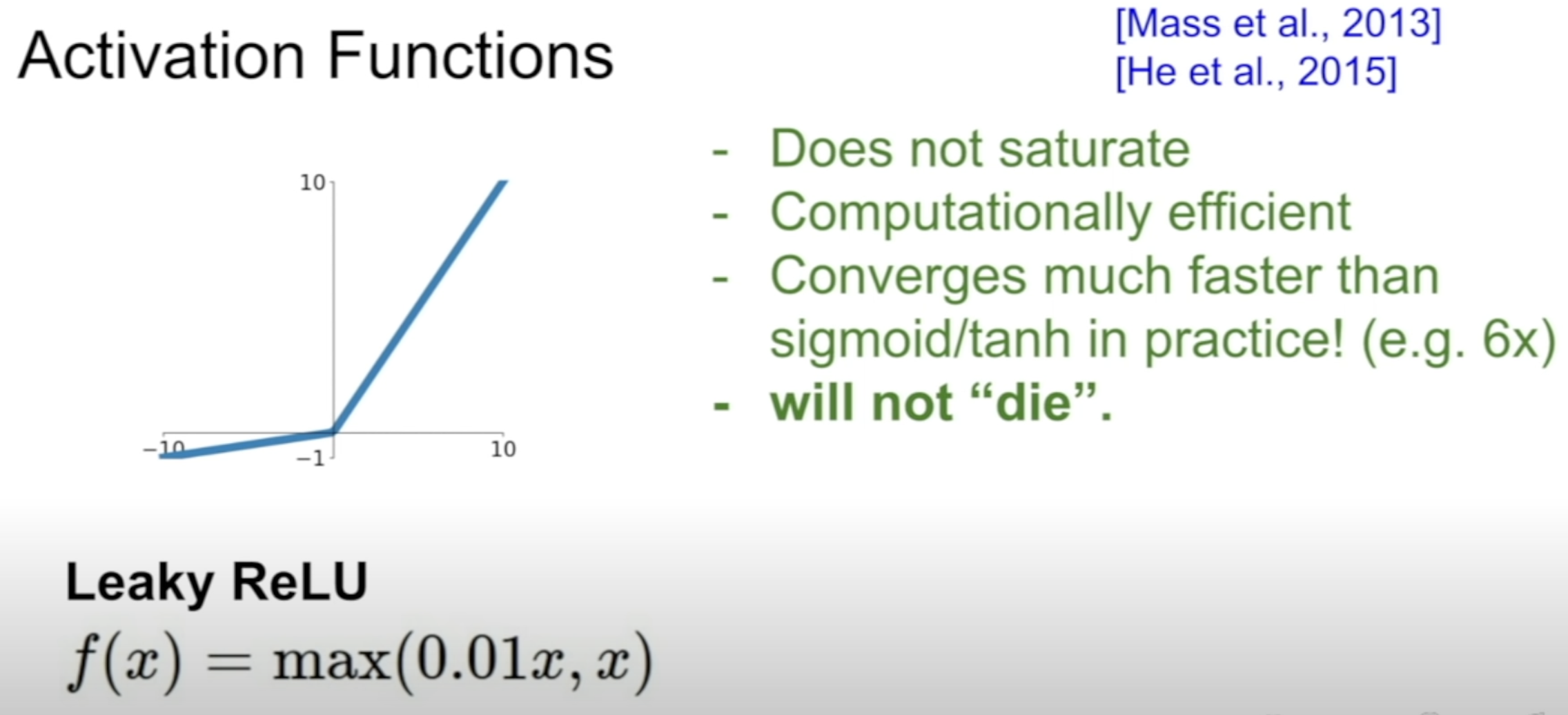
- Dead ReLU problem solved! 😃
[2] Data Preprocessing
Why the need for zero-mean?
For Activation Functions to NOT fall into saturation regions.

How this zero-mean is used in CNN
[3] Weight Initialization

- Works fine for small networks
- Problem arises in deeper networks
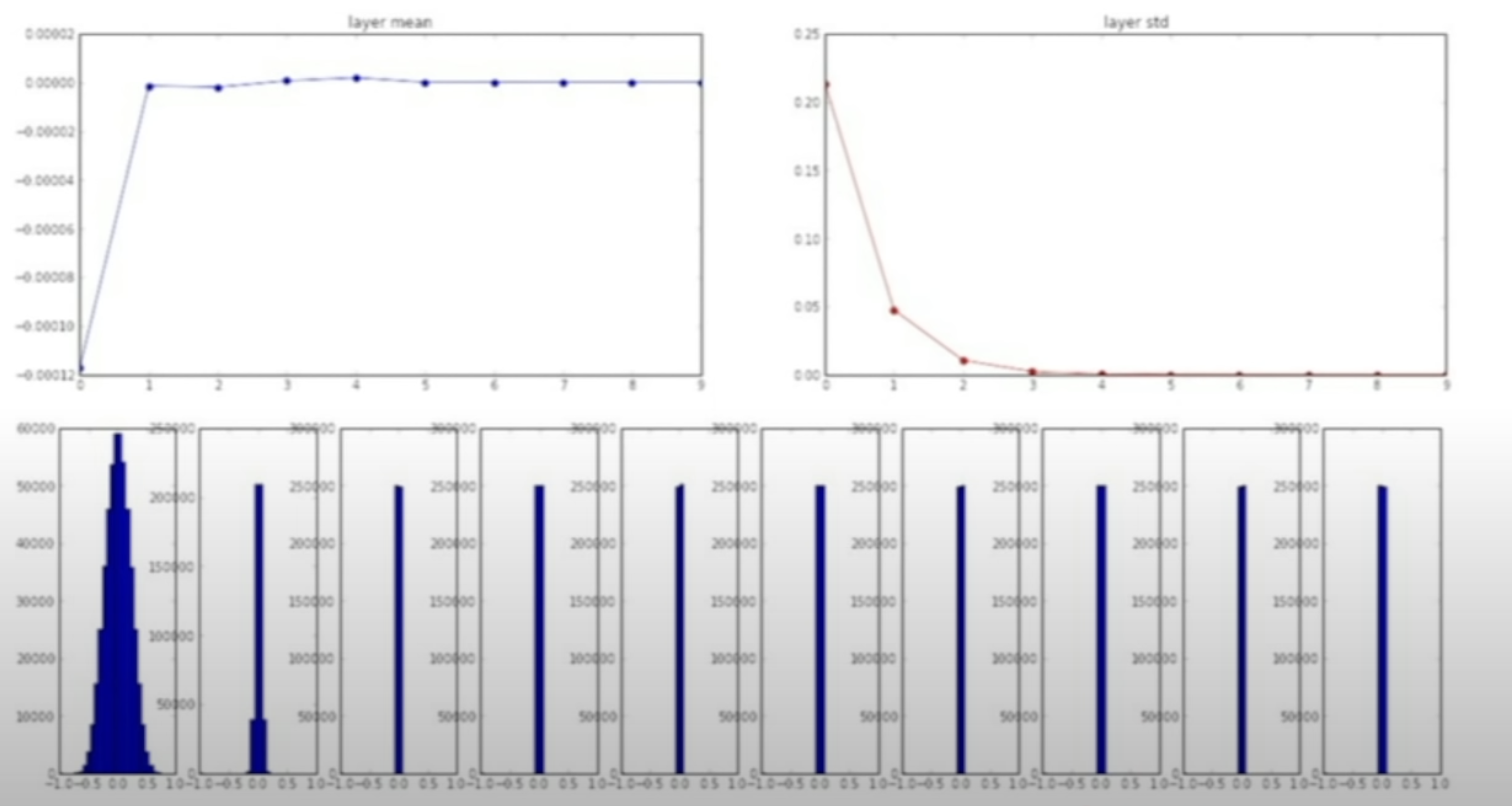
Can check that the std falls down to 0.
Why is this a problem?
[]
Then how about just making the weights big?
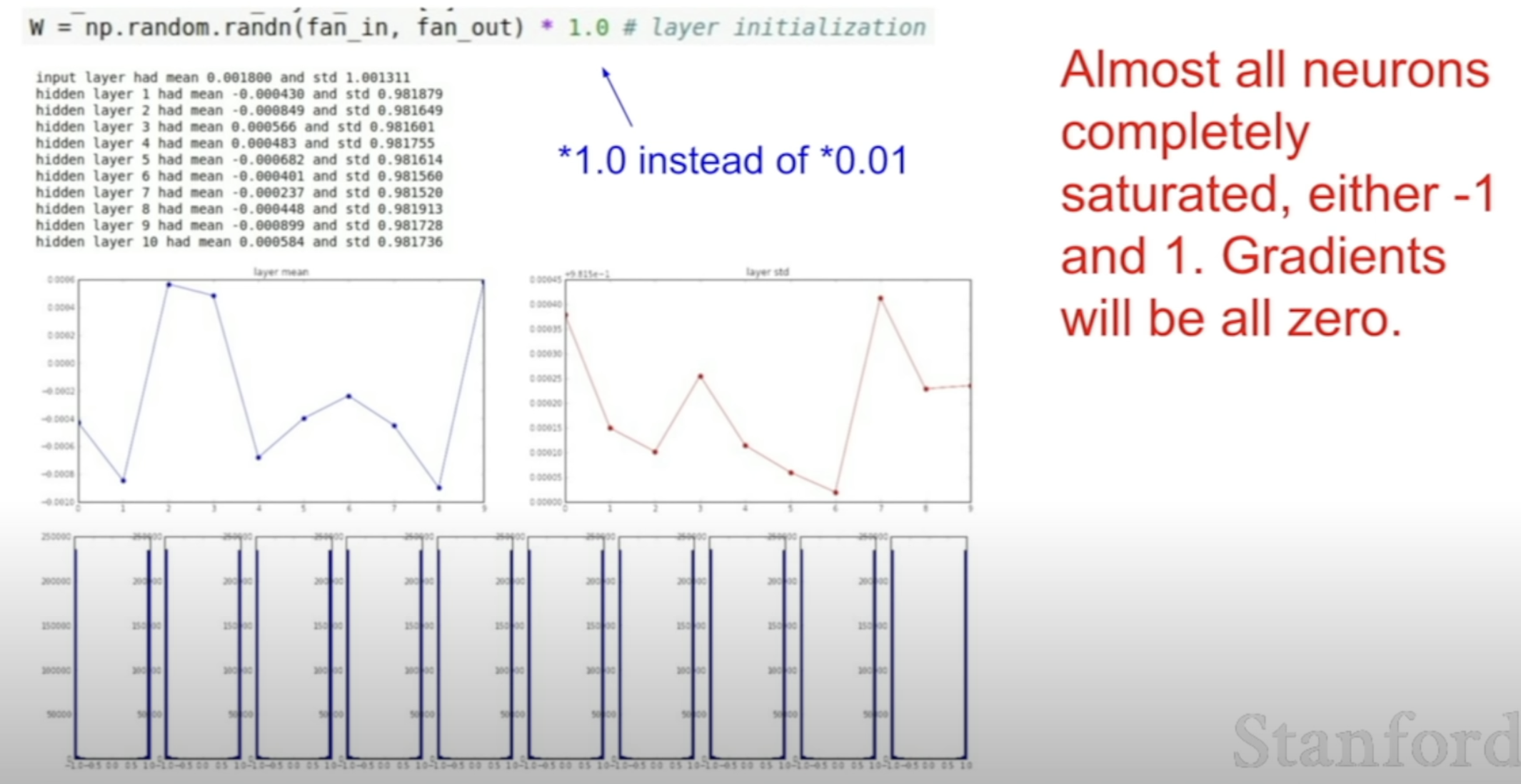
The neurons become saturated!
Xavier Initialization
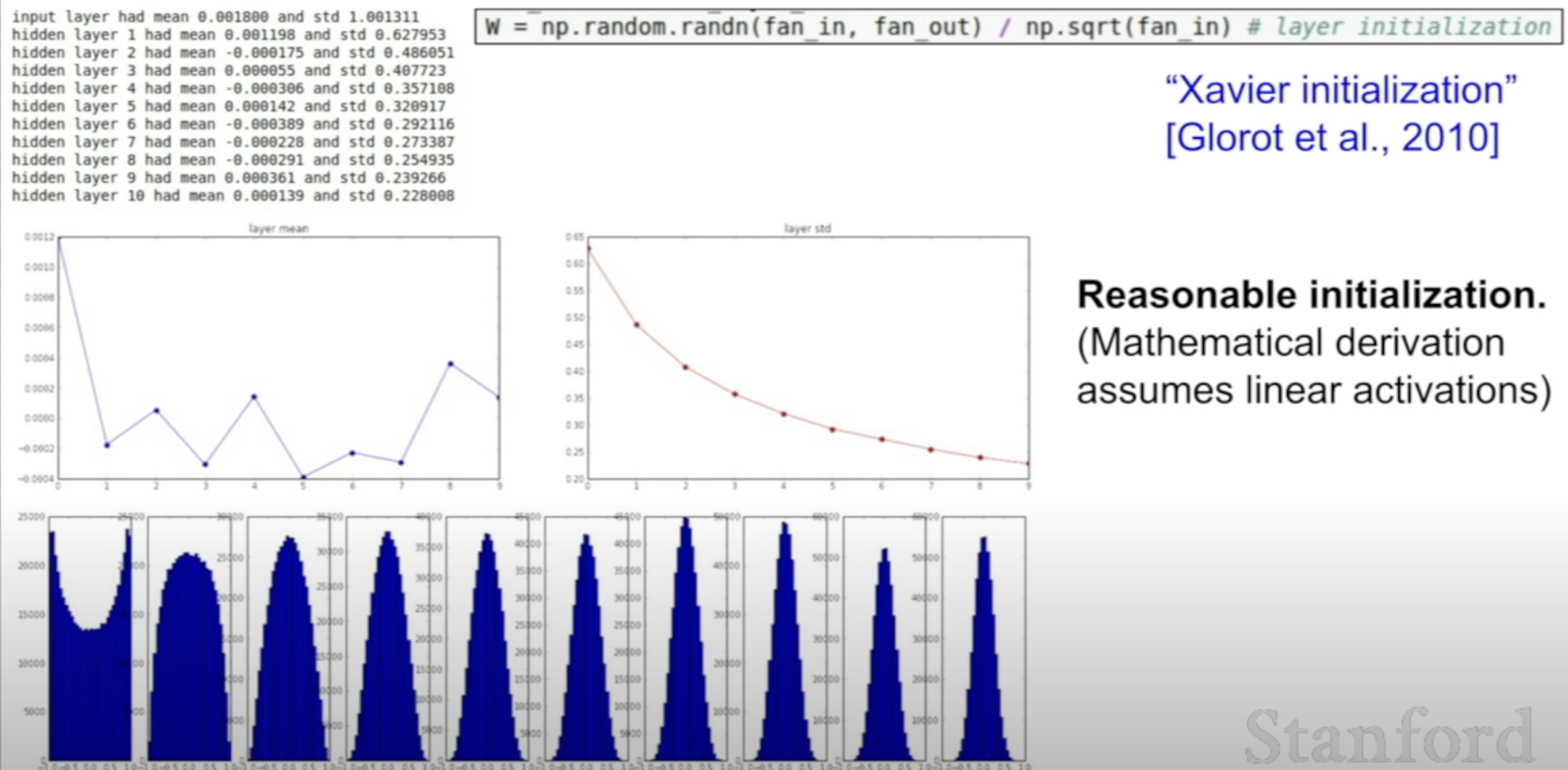
Xavier Initialization as an alternative
[4] Batch Normalization


- N : batch size
- D: feature size
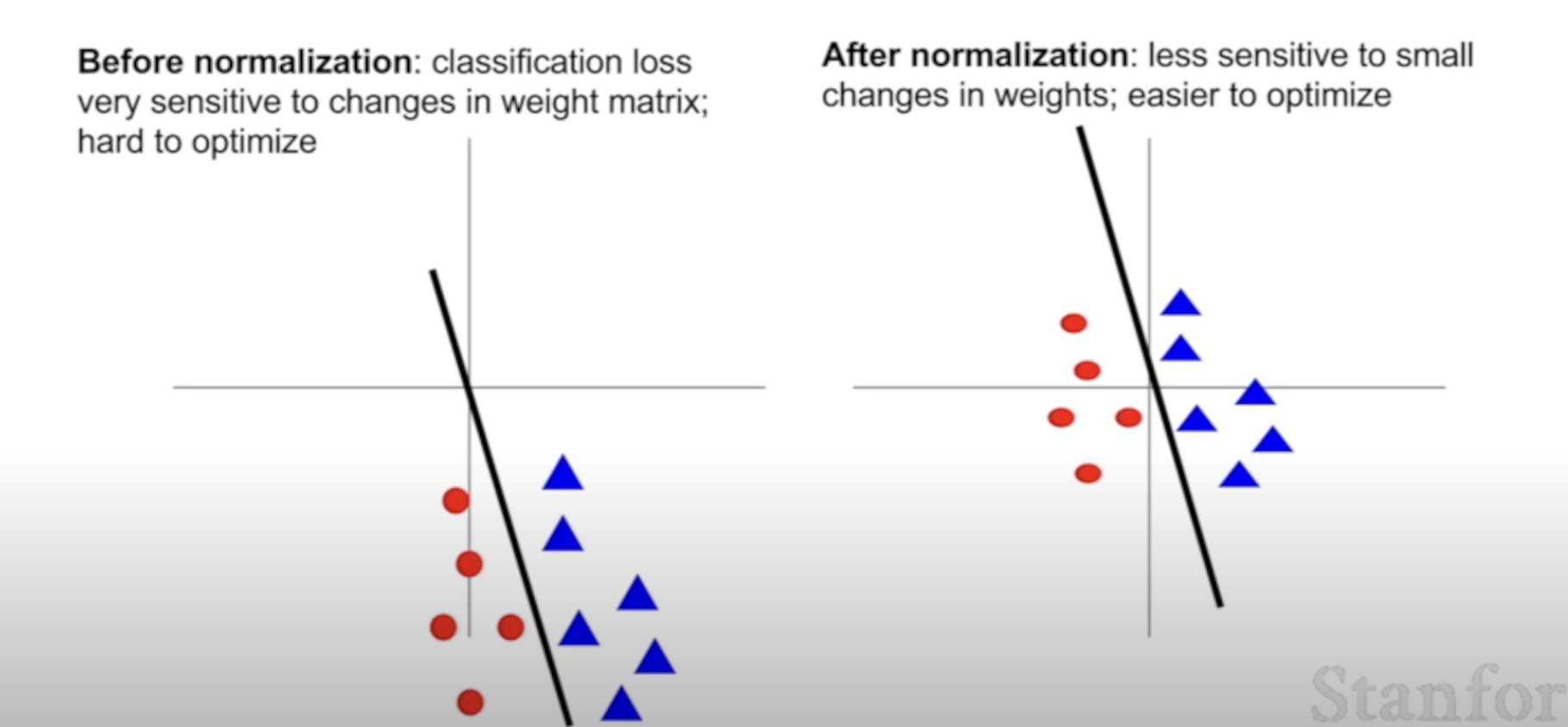
Normalize by each features in the batch.

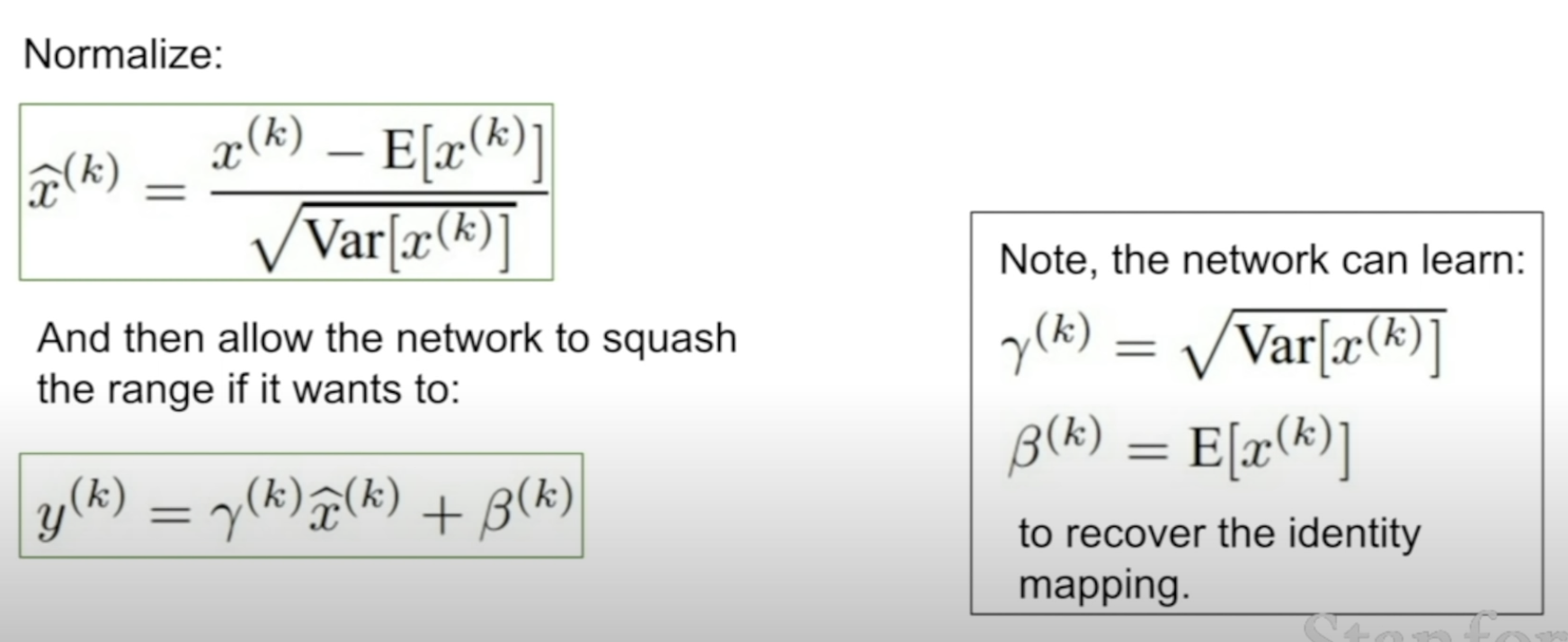
Used to control to squash the range as wanted

〰️ 질문
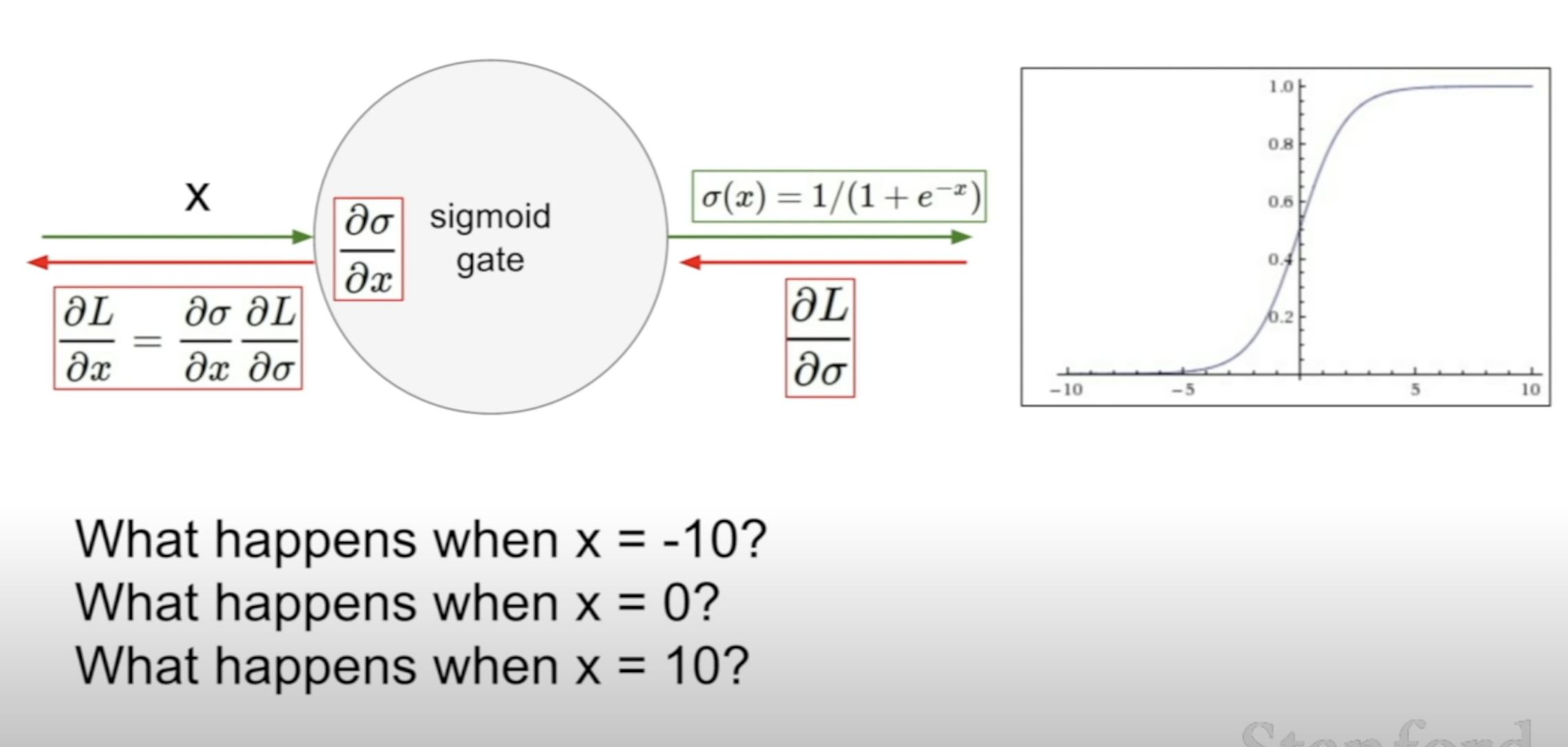
- x = -10 : 기울기가 0에 가까워, 역전파시에 제대로 전달이 안 된다.
- x = 0 : 괜찮음
- x = 10 : 기울기가 0에 가까워, 역전파시에 제대로 전달이 안 된다.

- 기울기가 항상 양수, 음수가 된다
- 즉 파라미터 업데이트(W)를 할 때 항상 increase/decrease를 하게 된다
--> 비효율적이다.
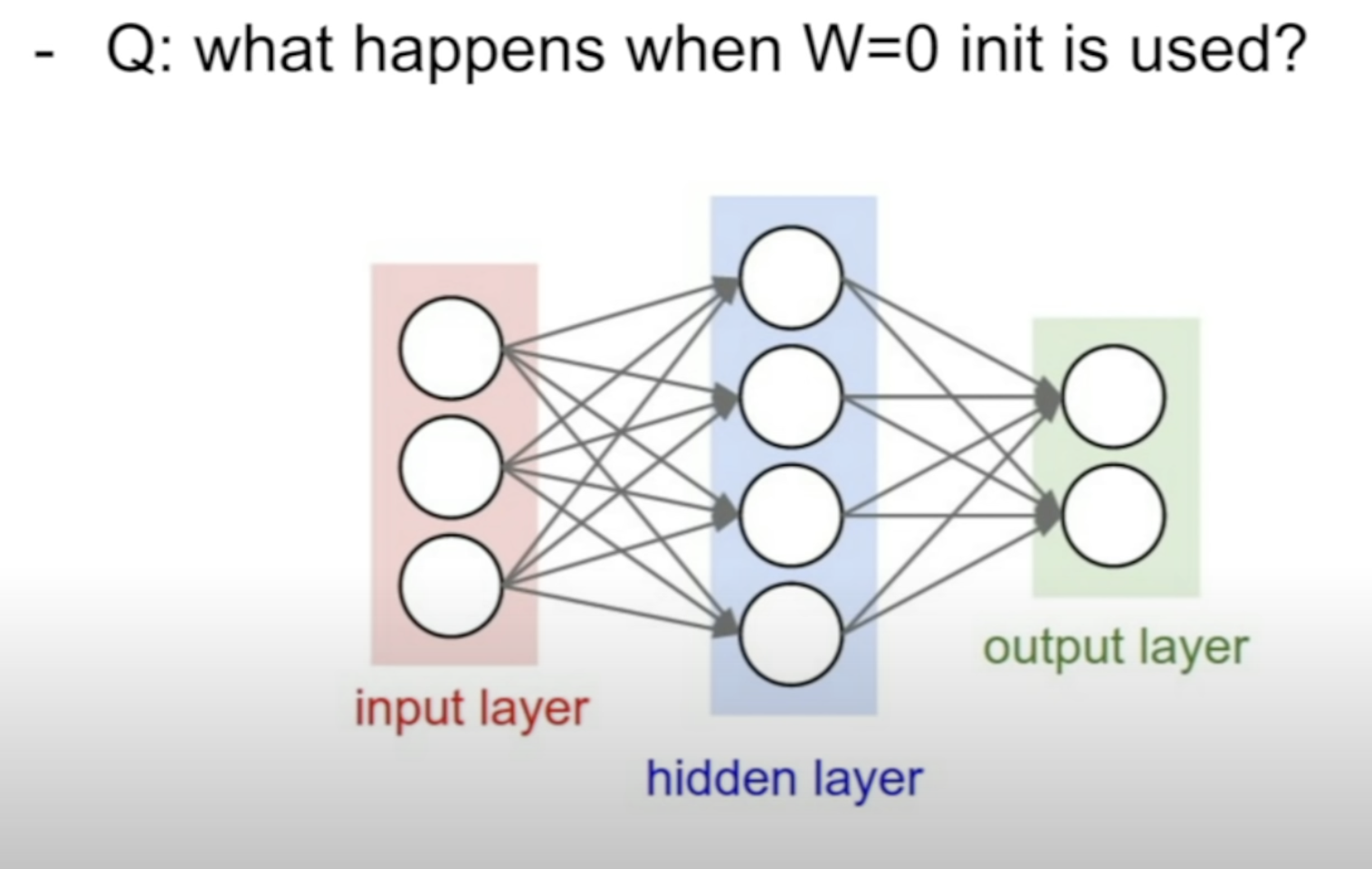
- 같은 output
- 같은 gradient
- update in the same way
〰️ 첨언
Unit Gaussian
Weight Initialization이나 Batch Normalization모두 이것을 해주는건데,
왜 필요할까?
- Vanishing/Exploding 기울기 문제 완화 (분산 유지)
Xavier Initialization

왜 Var(z)를 기준으로 논리가 전개되는가?
Var(z)가 Xavier Initialization에서처럼 일정하게 유지된다면,
- 출력값이 너무 커지거나/작아지지 않는다
- 기울기의 분산이 유지됨
