Transport services & protocols
- app process 간의 logical communication을 제공
- delay 보장이나, minimum badnwidth 같은건 보장하지 못함
transport vs network layer
network layer: host 간의 logical communicationtransport layer: process 간의 logical communication- network layer를 보완하는 역할(e.g 흐름제어, 오류제어, ...)
TCP
- reliable, in-order delivery
- connection setup
- flow control: receiver 사정에 따라 조절
- congestion control: network 사정에 따라 조절
UDP
- unreliable, unordered delivery
- network 계층에 process 간 delivery 역할만 추가함
multiplexing/demultiplexing
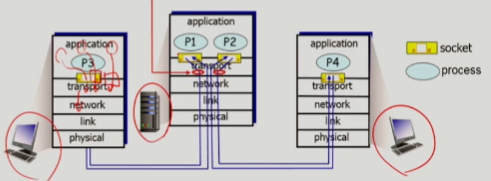
multiplexing: 송신 측의 transport layer에서 app layer에서 내려온 메세지에 transport header 값을 더하는 과정demultiplexing: 수신 측의 transport layer에서 network layer에서 올라온 datagram의 transport heeader를 extract해서 올바른 socket으로 넣어주는 과정- network layer에서 올라오는 datagram 에는 수신/송신자 IP주소가 담겨 있음
- TCP/UDP segment에는 송신/수신자 port 번호가 담겨 있음
- 이러한 정보들을 socket에 연결하는데 사용함
connectionless demultiplexing
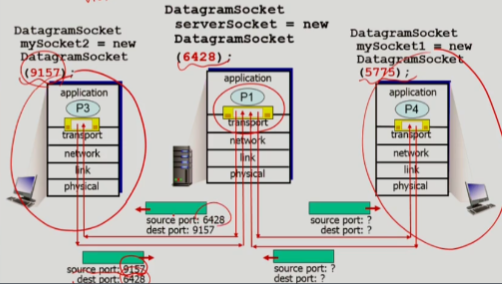
- 하나의 socket을 여러개의 process가 공동으로 이용함 => 목적지에서 dest port 번호로 socket을 구분할 수 있음
- 그렇기 때문에, 서로를 식별하기 위해 UDP와 같은 connectionless 통신에는 보낸 host의 IP주소와 port번호가 반드시 명시되어야 함
connection-oriented demultiplexing
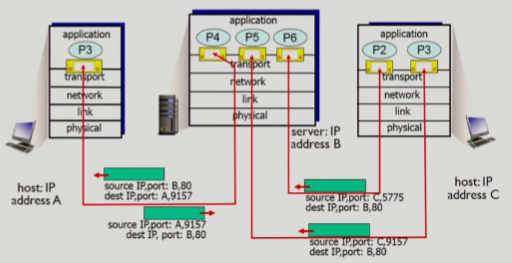
- contact한 app에 대해서 각각 별도의 socket을 생성함
- 목적지에서 socket을 구분하기 위해서 dest port 번호와 dest IP, source IP, source port 번호가 필요함
UDP
- connectionless
- no handshaking
- 각각의 UDP segment가 서로 독립적으로 처리됨 => 송신자가 누구인지를 서로 구분하지 않음
- 손실되거나 순서가 바껴서 도착할 수 있음
- minimum throughput 을 제공함
- 오히려 reliable transfer를 위해서 사용되는 경우도 있음
- app layer에서 reliability를 위한 function과 error가 발생한 경우 app layer에서 recovery할 수 있는 function을 추가하고 반복적인 transportation으로 overhead를 줄임
- e.g) streaming multimedia, DNS, SNMP, ...
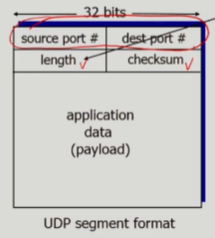
UDP checksum

- sender 측에서 UDP segment를 연속적인 두 개의 16bit로 보고, 이 두 개의 16bit integers를 더한 후 NOT 연산을 통해 checksum을 만들고 checksum field에 이를 넣어줌
- receiver 측에서도 전달받은 UDP segment를 통해 checksum을 만들어보고 checksum field의 값과 다르다면 에러가 발생했다는 것으로 인지
- 다만, 모든 에러를 잡을 수 있는 것은 아님. 예를 들어 두 개의 16bit integers의 4번째 bit가 0->1, 1->0 으로 바꼈다면 에러가 발생했지만, 결과적으로 checksum이 같을 수 있음
TCP
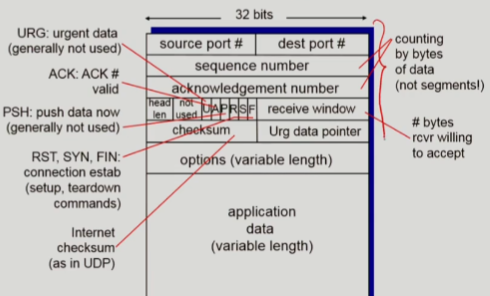
- point to point
- reliable
- in-order byte stream delivery
- 유저의 message를 buffer에 받고 이 message들을 연속적으로 이어진 byte들의 집합으로 보고 message boundary가 아니라 maximum segment size를 기준으로 잘라서 내보냄
- pipelined
- throughput를 향상시키기 위해 전달과 응답을 한번씩 주고 받는게 아니라, window를 설정해서 주고 받음
- full duplex data
- server도 client에게 data를 보낼 수 있음
- connection-oriented
- flow controlled
- congestion controlled
TCP sender events
- reliable transfer를 위해 segment number & checksum을 segment header에 싣는다
- segment number는 byte-stream의 첫 data 번호를 말함
- 만약 timer가 동작하고 있지 않다면 timer를 작동시킴
timeout이 발생했으면 segment를 재전송하고 timer를 재시작- timer는 내보냈지만 ack을 아직 못받은 segment를 기준으로 돌아감, 받지 못한게 없으면 timer stop
재전송 시나리오
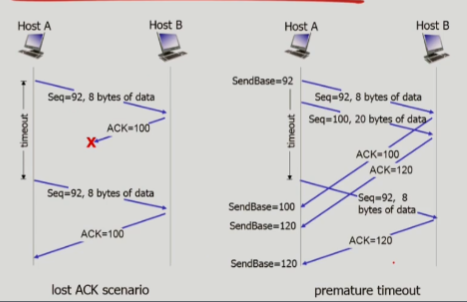
premature timeout: receiver는 accumulative ACK을 사용하므로 ACK이 도착하기전에 timeout이 발생해도 마지막으로 받은 segment를 기준으로 ACK을 전송한다
3-way handshake
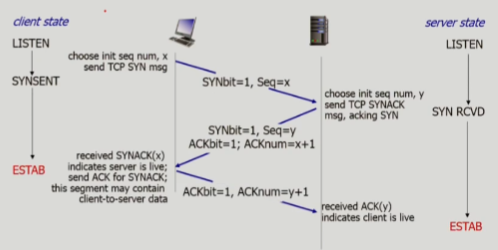
1. client가 syn 메세지를 보냄(client가 사용하고 싶은 initial segment number를 보냄(Seq=x))
2. server는 syn 메세지에 대한 응답으로 ack 메세지(ACKnum=x+1)를 보내고, server 측에서도 syn 메세지를 보냄(server에서 사용할 initial segment number(Seq=y)를 보냄)
3. client는 server가 보낸 syn 메세지에 대한 응답으로 ack 메세지를 보냄. 이 때 이 메세지에는 client가 server로 보내는 첫 번째 데이터가 들어있을 수도 있음
4-way handshake
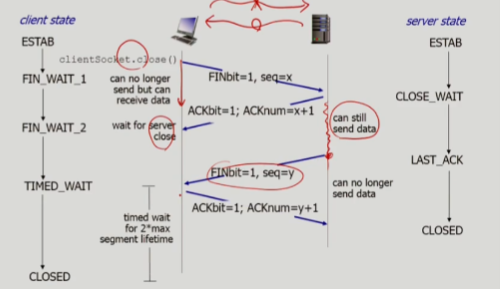
- server와 clinet는 자신의 connection을 종료해야 함
- client가 server에게 FIN bit=1 인 segment를 전송함
- server는 이에 대한 응답으로 ack 메세지를 보냄
- server는 client에게 FIN bit=1 인 segment를 전송함
- client는 이에 대한 응답으로 ack 메세지를 보냄. 이때 아직 네트워크에서 떠돌아다니는 데이터들이 들어올 시간을 두고 기다렸다가 연결을 종료하게 됨
TCP 빠른 재전송
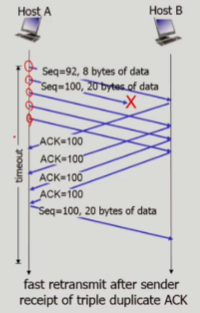
- 일반적으로 time-out period는 길기 때문에 이를 줄이고자 사용하는 방법
- 3개의
dup ACK이 들어오면 재전송을 하는 방식- 불필요한 재전송을 피하기 위해서 3번을 기다리는 것
- 만약 그림대로 마지막 segment에 ACK packet을 보낸다면 segment number는 180이 된다.
TCP 흐름 제어 (송신자 능력에 맞게)
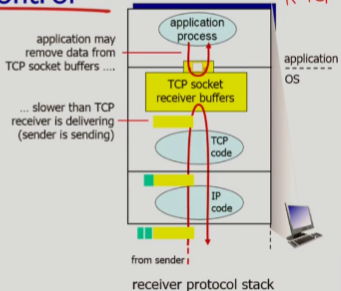
- sender가 보내는 segment는 TCP socket receiver buffer에 저장되는데, buffer가 넘치면 segment가 손실되는 현상이 발생함 => flow control은 이를 예방하기 위한 기법
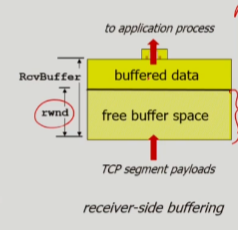
- receiver는 free buffer space 값인
rwnd을 sender에게 보내는 segment TCP header에 적어서 보내고, sender는 이rwnd값을 넘지 않기 위해 보내는 양을 조절함
TCP 혼잡 제어 (네트워크 상태에 따라)
- network가 감당할 수 없을만큼 많은 data를 보내는 경우 delay가 길어지거나 packet이 손실될 수 있음 => 이를 예방하고자 사용하는 기법
- retransmission이 많이 발생하는 만큼 효율성이 줄어듬
AIMD(Additive Increase Multiplicative Decrease)
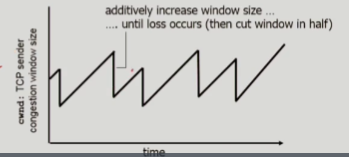
additivie increase: 송신자가 1RTT마다 1MSS(Maximum Segment Size)만큼cwnd를 증가시킴multiplicative decrease: 손실이 발생하면cwnd를 절반으로 줄임
Slow Start
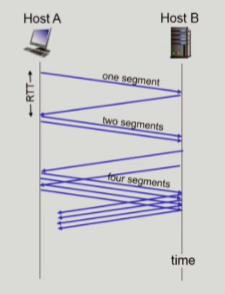
- 초기에는
cwnd가 1임 - connection이 연결되고 손실이 발생하기 전까지 매 RTT마다
cwnd를 2배씩 증가시킴 => ACK이 들어올때마다cwnd를 1씩 증가시킴 - 시작은 적지만 매우 빠르게 증가함 =>
cwnd가 충분히 커지면 조심해야 함
혼잡 회피
Slow Start시cwnd가 충분히 커진다면 그때부터는 네트워크 상황에 따라서 증가값을 줄여야 함 => 그 기준을ssthresh, 즉 임계치라고 함ssthresh는 처음엔 OS가 설정한 값으로 세팅되었다가, 손실이 발생하면 손실이 발생했을 때의cwnd의 절반으로 재설정됨
cwnd가ssthresh를 넘어가면 그때부터 매 RTT마다cwnd를 1씩 증가시킴cwnd<ssthresh: slow start phasecwnd>=ssthresh: congestion avoidance phase
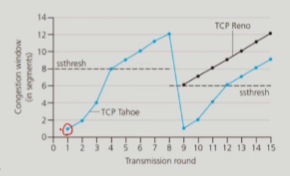
TCP Tahoe
timeout이 발생하거나3 dup ack가 발생하면cwnd를 1로 줄임
TCP RENO
timeout과3 dup ack의 판단 기준을 서로 구분함3 dup ack: 덜 심각한 network 상황이라고 판단하고cwnd를 절반으로 줄임 => 이 때는ssthresh도 절반으로 줄여지기 때문에cwnd랑ssthresh랑 같아지는 결과가 생김 =>cwnd를 RTT마다 1씩 증가시킴timeout:cwnd를 1로 줄임 =>cwnd가 1이기 때문에slow start, 즉 RTT마다 2배씩 증가
출처: http://www.kocw.net/home/search/kemView.do?kemId=1046412

내 머릿속 지우개