Network Layer
네트워크 계층의 목적은 transport segment를 수신자에게 보내는 것이다.
- 데이터를 보낼 때 transport layer로부터 segment를 받아서 datagram으로 캡슐화를 한다.
- 모든 host, router에 network layer가 존재한다.
- host: gateway router로 전달
- router: routing algorithm을 계산해서 테이블에 저장해놓고 라우팅 방향을 설정한다.
기능
network layer 에는 크게 두 가지 기능이 있다.
routing
- 목적지까지의 경로를 결정하는 것
forwarding
- 라우팅에서 계산한 경로 정보를 활용해서 들어온 packet을 적절한 output link로 내보내는 것
connection, connection-less service
network layer에는 라우터 간에 통신 방법에는 크게 connection-oriented 인 virtual circuit network 방식과, connection-less인 datagram network 방식으로 나뉜다.
virtual circuits network
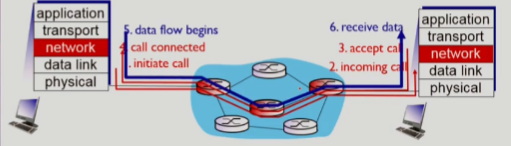
- packet을 주고/받기 전에 받는 쪽에서 call setup request를 던진다.
- 이 메세지에는
VC number라는 다른 라우터와 식별될 수 있는 값을 사용하라는 내용이 담겨 있다.
- 이 메세지에는
VC number는 매 링크마다 변경될 수 있다.
VC number에 따라 output link가 결정된다.- 전체적인 경로에 하나의
VC number를 사용하게 되면 수 많은 경로들이 섞여서 엄청나게 많은VC number가 필요하고,VC number를 결정하기 위해서 모든 router들이 통신을 해야한다는 overhead가 발생하기 때문에 더 작은 단위로 나눈 결과다.
- 주로 ATM이나 전화회사에서 쓰이는데, internet에서는 쓰이지 않는 방식이다.
datagram network
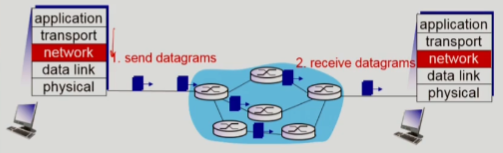
- call setup 단계가 존재하지 않는다.
- packet에 존재하는 목적지 host address 주소를 가지고 routing을 한다.
forwarding table은 address range를 기준으로 output link를 결정한다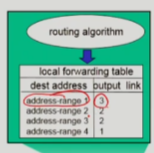
- range로 나누어야 수 많은 entry를 줄일 수 있기 때문이다.
- internet에서 주로 사용된다.
- internet network는 종류가 매우 다양하기 때문에
VC처럼 공통적인 format을 보장할 수 없다. - end system이 매우 smart해서 어느정도의 손실이 발생해도 이를 복구할 수 있기 때문에 packet을 더 간소화시킬 수 있다. (=> 속도가 빠른게 우선)
- internet network는 종류가 매우 다양하기 때문에
IP fragmentation, reassembly
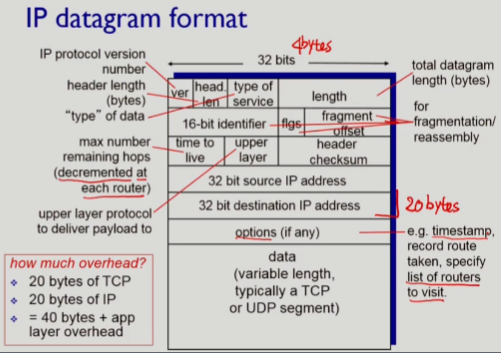
- network link는 각각 다른
MTU와 type을 가지고 있다. - 하나의 IP datagram이 너무 커서 하나의 frame에 담을 수 없는 경우가 발생하면 IP datagrame을 여러개로 쪼개서 frame으로 만든다.
- 작게 쪼개진 IP datagram은 독립적으로 전송되고 이것들은 최종 목적지에 도착해서야 reassembled 한다. (=> 다음 link의
MTU가 크다고 해서 reassembled하지 않는다)- 각각의 fragment 들이 서로 다른 경로로 목적지에 도착할 수 있기 때문이다
- 작게 쪼개면 각각에 header를 달면서 더 많은 byte를 보내야 하는 header overhead가 발생하지만, 이를 감수하는 이유는 중간 router에서의 processing overhead를 줄이기 위함임
- 굳이 reassemlby 하는 이유는 무엇인가 ?
- 목적지에서는 자신이 소통하고 있는 protocol의 메세지를 그대로 받아볼 수 있어야 하기 때문에 payload에 담겨있는 원래의
transport segment를 복구해서 목적지에서 그대로 메세지를 받아볼 수 있도록 한다.
- 목적지에서는 자신이 소통하고 있는 protocol의 메세지를 그대로 받아볼 수 있어야 하기 때문에 payload에 담겨있는 원래의
fragment 예제
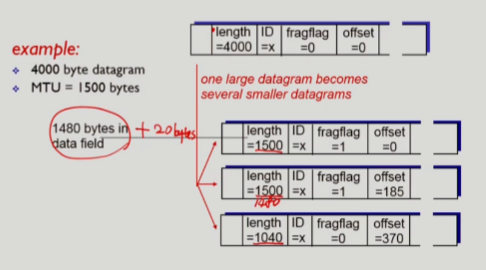
length: 3개의 fragment로 나뉘어 지면서, 앞 두개의 fragment는 (data)1480 bytes+(header)20bytes = 1500bytes가 되고, 마지막 fragment는 1000bytes(남은 data) + 40bytes(추가로 발생한 bytes) = 1040bytes가 된다.ID: 같은 datagram에서 생긴 fragment임을 구분하기 위해 사용한다fragflag: 마지막 fragment를 0으로 표시한다.offset: fragment의 offset를 표시하는데,8bytes당 1로 표현을 한다. 따라서, data의 길이 1480bytes/8 = 185, 2960bytes/8 = 370이 된다
subnet
subnet은 router의 개입없이 서로 연결할 수 있는 IP address를 말한다. 상위 비트를 subnet part, 하위 비트를 host part로 구분한다. 이 때 subnet의 비트 수를 명시하기 위해 subnet mask를 이용한다.
e.g) 223.1.3.1/ 223.1.3.2/ 223.1.3.3 라는 3개의 host가 있다면 subnet은 223.1.3.0/24가 되고, 이들은 router의 개입없이 서로 통신할 수 있다. subnet mask는 /24이다.
IP addressing
예전에는 IP를 할당할 때 subnet bit수를 고정시키고 이들을 class로 나눠서 IP를 할당했었다.
e.g) Class A = 8bit, Class B = 16bit, Class C = 24bit
CIDR(Classless InterDomain Routing)
- class를 없애고 IP를 가변적으로 할당하기 위해서 만들었다.
DHCP(Dynamic Host Configuration Protocol)
- 네트워크 server가 host가 네트워크에 join 했을 때 IP를 동적으로 할당하고 다시 수거했다가 다른 host에게 할당함
- IP 할당 외에도 다른 추가적인 기능을 제공한다
- client에게 외부로 나가는 첫번째 first-hop router의 주소를 알려줌
- loccal DNS server의 IP와 이름을 알려줌
- network mask 를 알려줌
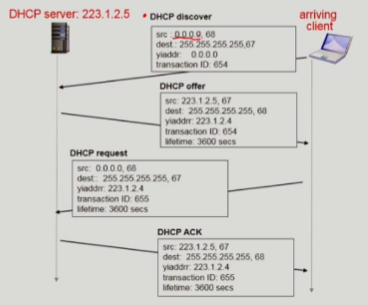
- 동작순서
- host가
DHCP discover메세지를 broadcast함 (optional) - DHCP sever가 이에 대해서
DHCP offer메세지를 응답함 (optional) - host가 IP 주소를 요청하기 위해서
DHCP request메세지를 보냄 - DHCP server가 이에 대한 응답으로 IP 주소를 보냄:
DHCP ACKmsg
ISP가 subnet을 할당하는 방법

- ISP가 사용하는 subnet block에서 network portion의 bit를 확장해서 할당한다.
ISP와 network 통신
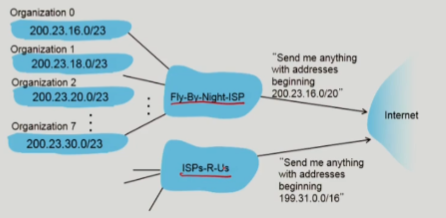
- ISP는 subnet까지의 범위에 해당하는 메세지들을 전달받으며 메세지에 담길 data의 양을 효과적으로 줄인다
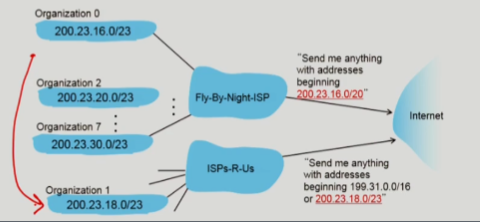
- 만약 다른 ISP로 변경되면 해당 ISP에 맞게 IP를 변경하는 것이 아니라, ISP에서 데이터를 받을 때 새로 들어온 IP로 들어오는 데이터들을 받도록 notify 한다.
- 이렇게 할 수 있는 이유는
logest prefix matching가 적용되기 때문이다.
Logest prefix matching
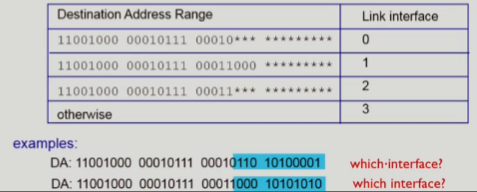
- 상위 비트가 더 많이 매칭되는 interface로 연결된다
NAT
NAT(network address translation)는 local IP를 public IP로, public IP를 local IP로 변환해주는 역할을 하는router이다.- host가 폭발적으로 증가하면서 부족한 IP를 효율적으로 사용하기 위해서 고안됐다.
- local network 내부에서는 외부에 알릴 필요 없이 자유롭게 IP를 변경할 수 있다.
- ISP를 자유롭게 변경할 수 있다.
- local network 내부의 device는 외부 세계에서는 invisible하기 때문에 보안 측면에서 이점이 있다.
NAT translation table에서는 port 번호를 기준으로 내부의 host들을 구분한다- 이 때 port 번호는 아무도 사용하지 않는 번호를 사용함으로써 서로를 식별할 수 있는 값을 사용한다.
흐름
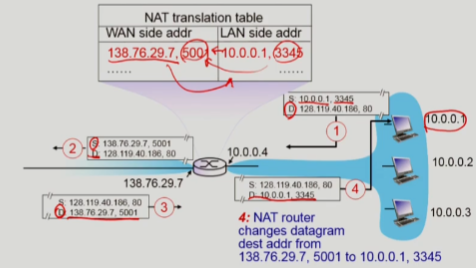
1. datagram이 local network의 host에서 128.119.40.186, 80으로 출발한다.
2. NAT router는 host에서 출발한 datagram의 source address를 NAT router의 주소인 138.76.29.7, 5001로 변경한다. 이 때 port번호 5001은 출발한 host를 구분할 수 있는 번호를 사용한 결과다. (=> 만약 해당 host가 NAT translation table entry에 없으면 추가한다.)
3. destination에서 138.76.29.7, 5001를 destination address로 들어온다.
4. NAT router는 datagram의 destination address를 출발했던 host address인 10.0.0.1, 3345로 변경한다.
문제점
NAT는 IP주소를 절감하는 등의 단점이 있지만, 다음과 같은 단점이 존재한다.
- router는 최대 layer 3 까지 밖에 처리하지 못한다
- travesal problem
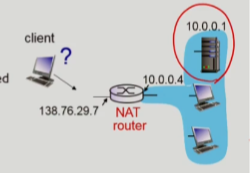
- local net에 server가 있으면 server의 IP는 invisuable하기 때문에 문제가 생긴다.
NAT translation table에 등록이 되려면 local network에서 한번 밖으로 나가야 등록이 되는데, client to server는 client가 먼저 request를 보내기 때문에 문제가 생기는 것이다.- 두 가지 해결방법이 존재한다.
- 관리자가 수동적으로 table에 server의 IP를 등록하는 방식
- upnp 프로토콜을 사용해서 위 작업을 자동적으로 수행하는 방식
ICMP(Internet Control Message Protocol)
ICMP는 host-host, host-router, router-router 간에 통신 시 발생하는 에러를 알려주기 위해서 사용하는 message protocol이다.
- error reporting 역할을 한다.
- 접근이 불가능한 상태로 destination으로 이동하는 중 이동이 불가능하게 되면 source로 error message를 싣고 report한다.
- IP 위에서 동작한다.
- [ [IP]. [ICMP] ]와 같은 형태로 만들어진다.
ICMP를IP로 encapsulate한다. (=> source IP, dest IP를 가지고 있어야 하기 때문)
type,code,error host IP 상위 8비트로 message를 구성하고 있다.type,code는 다음과 같다.
4,0의 congestion control는 사실 사용되지 않는다. => host에서 따로 체크를 하기 때문
traceroute
ICMP로 만들어진 network application 를 살펴보자.

- 각 번호는 순서대로 거치는 router들의 이름과 router를 도달하는데 소요된 시간을 나타낸다.
- 시간들은 1RTT를 기준으로 3번 측정했다.
동작방식
- source host는
UDP 세그먼트를 연속적으로 전송한다- 첫번째 세그먼트는,
TTL을 1로 설정한다.(=> 1번째 router에 도달한 후 버려지고, reporting message가 해당 router에서ICMPmessage를 (TTL expired으로 설정 후) source host로 전송함) - 두번째 세그먼트는,
TTL을 2로 설정한다. - n번째 세그먼트는,
TTL을 n로 설정한다.
- 첫번째 세그먼트는,
- source host는 도착하는
ICMP메세지들을 보고 각 router마다RTT time을 알 수 있다. - 중간중간 이상한 port number를 고의적으로 싣어서 보낸다.
- =>
TTL이 충분히 커져 dest host에 도착할 수 있는 경우 dest host가port unreachable메세지를 보내면 source host는 dest에 도착했음을 인지하고 세그먼트를 그만 보내게 된다)
- =>
IPv6
기존의 IPv4는 32bit를 사용하기 때문에 증가하는 IP를 수용하기 위해 DHCP, CIDR, NAT들을 사용했지만 그래도 한계가 존재함. IPv6는 이를 위해서 128bit를 사용함.
packet을 전송하는데 발생하는 overhead의 큰 문제는 주로 link의 transmission delay였지만, 기술적으로 성장하면서 transmission delay는 줄어들고, router에서의 processing delay가 문제가 됨. 근데 processing delay를 해결할 수 있는 가장 좋은 방법은 H/W적인 방법이고 이를 위해서는 header의 길이가 고정적이어야 함. 이를 위해 IPv6는 다음과 같은 format을 제공함.
- fixed-length 40 byte header
- 기존
IPv4는 가변 길이의optional header가 존재했고 이는trasnmission delay감소를 H/W적으로 처리하기 위해 방해가 됨. 이를 위해IPv6는 고정적인 header를 제공함 IPv6는 가변 길이의optional header를 나타내기 위해Next Header라는 필드를 추가해서optional header가 있는 경우 이를 나타내고, 없으면 해당 필드에서 다음 필드가TCP/UDP segment임을 알려줌
- 기존
- no fragmentation allowed
- 기존
IPv4는 datagram의 길이가 큰 경우 이를 조각으로 나눠서 보냈었음. IPv6는 fragmentation 하면서 지연되는 시간을 줄이기 위해서 datagram의 길이가 크면 그냥 버려버리고,ICMPv6메세지를 통해 이 사실을 source host로 전달해줌
- 기존
- QoS 지원 header field 활용
- 멀티미디어 파일들이 많이 오가는 것을 위해서 QoS를 field를 통해서 지원함
IPv6 datagram format

priority,flow label를 이용해 QoS지원checksumfield가 사라졌음(=> bandwidth가 증가하며 datagram이 손실됐을 가능성이 없다고 판단하고 손실을 check하는 overhead제거)fragment관련,optionsfield 사라짐
transition from IPv4 to IPv6

- 한번에 모든
IPv4를IPv6로 전환할 수 없기 때문에IPv4와IPv6가 서로의 packet을 알아볼 수 있게하기 위해tunneling을 사용
IP tunneling
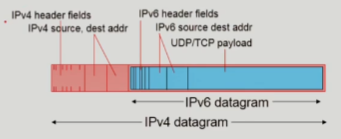
IPv6를IPv4datagram으로 encapsulate 함
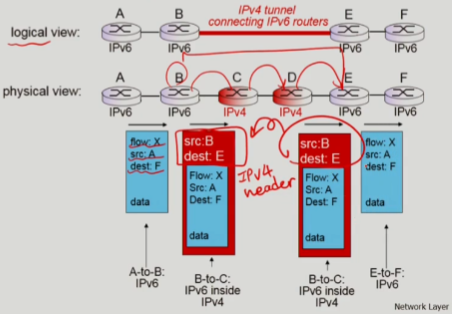
A->B:IPv6datagram을 만들어서router B로 보냄B->E:router B는 다음 router가IPv4임을 인지하고 있어서,router A에게 받은IPv6 datagram을IPv4 datagram으로 encapsulate 하게 됨. 이렇게 만들어진IPv4 datagram은IPv4를 통과할때까지 사용하게 됨E->F:router E는router D에게 받은IPv4 datagram을 decapsulate해서IPv6 datagram으로 만들어서router F에게 전달
Routing Algorithm
routing algorithm은 정보의 양에 따라서 global or decentralized 냐, link cost의 성질에 따라서 static or dynamic이냐로 구분할 수 있음.
global(link state) or decentralized(distance vector)
- global
link state algorithm이라고도 불림(e.g, 다익스트라 알고리즘)- 모든 router들이 전체적인 정보를 가지고 있는 경우. 즉, router에서 각 dest까지의 cost들, 경로를 알고 있는 경우를 말함.
- 임의의 라우터는 자신이 얻은 dest에 따른 cost와 경로를 broadcast해서 다른 라우터들과 공유함 => 전체적으로 모든 라우터들이 다른 라우터의 경로와 cost를 알 수 있게 됨
- 모든 정보를 수집한 후에 알고리즘을 수행해서 경로를 구함
- decentralized
distance vector algorithm이라고도 불림(e.g, 벨만포드 방정식)- router가 제한적인 정보만을 가지고 있는 경우. router들은 물리적으로 연결되어 있는 근처 router에 대한 정보만을 가지고 있는 경우를 말함
- neighbors간의 정보(경로, cost, ...) 교환을 통해 경로를 판단함
- 포워딩 테이블이 만들어지고, 한 곳의 link-state가 더 좋아지면(link cost 감소) 전체 라우터들의 distance vector들이 빠르게 다시 완성된다.
- 하지만 한 곳의 link-state가 나빠지면 전체 라우터들의 distance vector들은 linear하게 증가하면서 느리게 완성됨(=> 자신에게 의존하는 경로를 가진 노드들에게 무한대로 값을 전달하는 방법으로 해결함,
poison reverse)
static or dynamic
- static
- link cost가 변할 일이 없는 경우
- link cost가 자주 변하지 않기 때문에 이 알고리즘은 자주 수행될 필요가 없음
- dynamic
- link cost가 변할 일이 있는 경우
- 최소 속도가 보장되어야 하는 경우, available bandwidth가 큰 link로 보내기 위해서 사용함
- 시간에 따라 에러 발생이나 사용 빈도에 link cost가 따라서 계속 변하기 때문에 이 알고리즘은 자주 실행되어야 함
Hierarchical routing
위의 Routing algorhtims 들은 이상적인 환경(동일한 라우터 사용, network가 동일하다는 전제)에서의 이상적인 공식이고, 실제에서는 조금 다름.
- scale: 600만개 이상의 destination
- 모든 경로 정보를 담고 있으면 포워딩 테이블이 너무 커져서 모든 정보를 담고 있을 수 없음
- administrative autonomy
- network들은 각자 서로 다른 network들을 사용하고 있고 이를 관리하는 기관들은 자신들의 정보를 공개하고 싶지 않아함
위와 같은 이유들로 라우터들을 autonomous systems(AS)로 나눔. 이는 한 지역(기관 sk, kt, ...)에 속해있는 라우터들의 집합을 의미함. 하나의 AS에서 사용되는 라우팅 알고리즘을 Intra-AS routing protocol이라고 하고, 서로 다른 AS들을 연결하는 router를 gateway router라고 함.
Interconnected ASes
Inter-AS routing algorithm은 서로 다른 AS 각각의 Intra-AS routing algorithm 협력으로 만들어진다.
예를 들어 AS1의 host a이 AS2와 연결되어 있는 (x) subnet으로 가려고 한다면, AS2에서의 Intra-AS routing algorithm을 통해서 만들어진 결과를 통해 AS2에서 (x) subnet으로의 경로를 알아내야 하고, AS1에서의 Intra-AS routing algorithm을 통해 b 라우터와 link cost가 가장 적은 AS1의 게이트웨이 라우터(c)와 host a 의 경로를 알아내야 한다.
이후, c와 b가 통신을 거쳐 host a에서 (x) subnet으로 가는 경로를 알아내게 된다.
routing in Internet
Intra-AS Routing
interior gateway protocols(IGP)라고도 불리는데, 서로 다른 AS를 연결하는 gateway router간의 라우팅을 말한다. IGP에는 크게 RIP,OSPF,IGRP가 있다.
-RIP:Routing Information Protocol,가장 오래된 프로토콜
-OSPF:Open Shortest Path First,현재 가장 많이 사용
-IGRP:Interior Gateway Routing Protocol
RIP(Routing Information Protocol)
distance vector algorithm에 속한다고 할 수 있음- 30초 마다 이웃과 distance vector를 공유함(-> advertisemnet)
- 각 hop link마다 cost를 1로 설정하고, 최대 15개의 hop까지만을 기록한다.
- advertisement: 25개의 dest subnet만을 list로 관리한다.
- advertisement는 UDP packet에 담겨서 보내짐
- 180초 동안 advertisement가 없으면 해당 라우터에 대한 링크를 invalidate으로 변경
poisin reverse사용- RIP routing table은 route-d(daemon)라 불리는 app-lavel process에 의해 관리됨
=> 소규모의AS에서만 사용할 수 있음
OSPF(Open Shortest Path First)
link state algorithm을 사용함- 각 노드들에 대한 topology map을 가지고 다익스트라 알고리즘을 수행해서 경로를 계산함
- RIP보다 더 진화된 형태를 지님
- host가 많다면 계층형 OSPF를 활용해서 사용할 수 있음 (=> 계층형 구조로 link의 부하를 줄임)
- link cost를 다양한 기준(delay, bandwidth, ...)으로 포워딩 테이블을 만들 수 있음
- 인증 방식을 통해 보안 기능 향상
- 같은 목적지에 대해 비용이 같은 여러 개의 경로가 있어도 이들을 모두 활용할 수 있음
- multicast protocol을 지원
계층형 OSPF
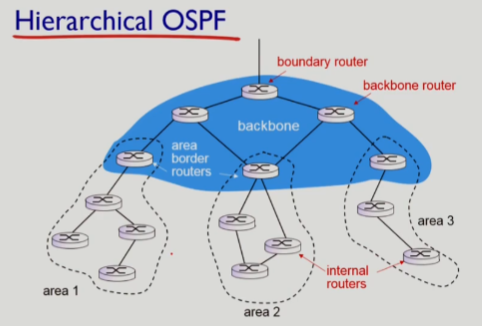
- link와 node가 증가하면 LS broadcasting 할 때 필요한 LS packet의 양이 많아지게 됨 -> LS packet의 양을 줄이기 위해 계층형으로 구조 변경
- 서로 다른 area의 LS link-state advertisement는
area border router를 통해 주고 받고,area border router는 자기가 받은걸 같은 area의 라우터들에게 advertisement하는 방식 boundary routers는 AS 전체를 다른 AS와 연결해주고backbone routers는 서로 다른 area들을 연결해줌
Inter-AS Routing (BGP)
Intra-AS Routing Protocol과는 다르게Inter-AS Routing Protocol은 모두 동일한 프로토콜을 사용해야 한다. 실제로 Internet에서는BGP(Border Gateway Protocol)이라는 동일한 프로토콜을 사용중임- BGP advertisement는 목적지 subnet으로 가기 위한 경로와 다음 hop router의 정보가 들어있음
- dest subnet's prefix + attributes 가 BGP message가 됨
- attributes에는
AS-PATH,NEXT-HOP, ...이라는 경로에 대한 정보가 들어있음 - advertisement를 받는 router는
import policy를 기준으로 경로를 선택하게 됨
- dest subnet's prefix + attributes 가 BGP message가 됨
- peer 간에 semi-permanent TCP를 연결하고 BGP advertisement를 교환함
BGP는 크게 두 가지로 나뉨eBGP: 이웃AS들로부터 접근 가능한 subnet들의 정보를 알아오는 프로토콜iBGP:eBGP를 통해 파악한 정보를AS내에서 전파할 때 사용하는 프로토콜- 서로 다른
AS간의 통신에는 가장 중요한 기준은 bandwidth 같은 것이 아닌정책임 (=> AS의 갯수가 적어도 보안상의 이유, 비용의 이유로 AS의 갯수가 더 많은 경로를 선택)
BGP메세지를 받는 다는 것은 메세지를 보낸AS가 해당 destination까지 forward를 약속한다는 것과 같은 의미

BGP route selection
- policy를 기준으로 결정
AS-PATH를 통해 더 짧은 경로 선택NEXT-HOP를 통해 가장 가까운 hop의 경로 선택 (-> OSPF를 사용해서 구함)- 다른 기준들..
-> best route로 보내는 router port를 고름
BGP message
OPEN: peer간의 TCP 연결을 하기 위한 메세지UPDATE: 새로운 경로가 생기거나 오래된 경로들을 advertiseKEEPALIVE: connection을 유지하기 위한 메세지, 정기적으로 주고받으며 TCP connection을 유지함(OPEN메세지 뒤에 전송)NOTIFICATION: 이전에 보냈던 메세지에 error가 발생했거나, connection을 끊기 위해서 사용
Intra-AS와 Inter-AS routing의 차이점
- policy
- inter-AS: admin은 route의 traffic을 고려해야 하고, 누가 자신의 net을 사용해서 지나가는지를 알아야 함(-> 원치않은 AS가 자신의 net을 지나가면 drop 해야하기 때문)
- intra-AS: 하나의 admin(ISP)에 의해 관리되는 범위이기 때문에 policy에 대한 결정이 필요하지 않고 오직 performance에만 집중하면 됨
- scale
- 계층형 라우팅으로 table size를 줄이고, update시 발생하는 traffic을 줄여야만 함
- performance
- inter-AS: performance보다 policy를 고려
- intra-AS: performance에만 집중
출처: http://www.kocw.net/home/search/kemView.do?kemId=1046412
