Overview
단안 카메라만을 이용한 객체를 인식하기 위한 사전조사와 졸업작품에서 선정한 모델을 왜 사용하는지에 대해 내용을 정리하였습니다.
1. Object Detection
1-1. Oject Detection이란?
컴퓨터 비전과 영상 처리가 기반이 되는 컴퓨터 기술로 input되는 이미지로부터 해당 이미지 내에서 어떠한 객체들이 존재하는지 찾아내는 것을 의미합니다.
Object Detection에서는 객체를 탐지하고, 탐지한 객체를 중심으로 Bounding Box(경계 박스)로 표시합니다.
이러한 과정은 CNN(Convultional Neural Networks) 라는 Neural Network 모델을 사용하여 객체를 판단합니다.
1-2. CNN의 한계
CNN의 프로세스는 4단계로 진행됩니다.
- 이미지 입력
- 객체가 위치한 구역의 bounding box 좌표 탐색
- 해당 bounding box 좌표의 이미지를 crop하여 이미지 classification 모델에 입력
- 각 bounding box 별 이미지 classification 실행
즉, 입력된 이미지로부터 물체가 있을법한 물체의 위치를 찾는 Region Proposal를 실행한뒤, 해당 결과들을 classification 하는 순서로 진행됩니다.
Region Proposal에서는 객체가 위치한 구역을 selection search algorithm으로 찾아내는데, 해당 알고리즘은 주변 픽셀과의 유사도를 파악하여 병합하는 방식으로 객체를 탐지하는 알고리즘입니다.
이러한 알고리즘은 이미지의 픽셀이 많을수록 시간이 오래 걸리는 점과 완벽한 딥러닝 기술이 아니라는 문제점이 존재합니다.
이러한 문제점은 Faster R-CNN에서 selection search algorithm이 아닌 Region Proposal network를 사용하여 처음부터 끝까지 딥러닝 모델로 발전함으로 해결되었습니다.
이러한 발전으로 Multi Object Detection 객체 탐지 성능이 향상되었습니다.
정확도인 mAP(mean Average Precision)과 속도 향상이 되었지만, 여전히 실용성으로는 실시간 분석이 가능할 정도인가라는 의문(?) 갖고 있습니다.
1-3. YOLO
YOLO는 위에서 갖고 의문을 해결한 방향으로 연구된 높은 정확도 대신 어느정도의 정확도와 실시간으로 분석이 가능할 속도를 갖춘 모델입니다.
실제로 아래의 성능표를 보면 Faster R-CNN과 YOLO의 FPS가 훨씬 높은것을 볼 수 있습니다.
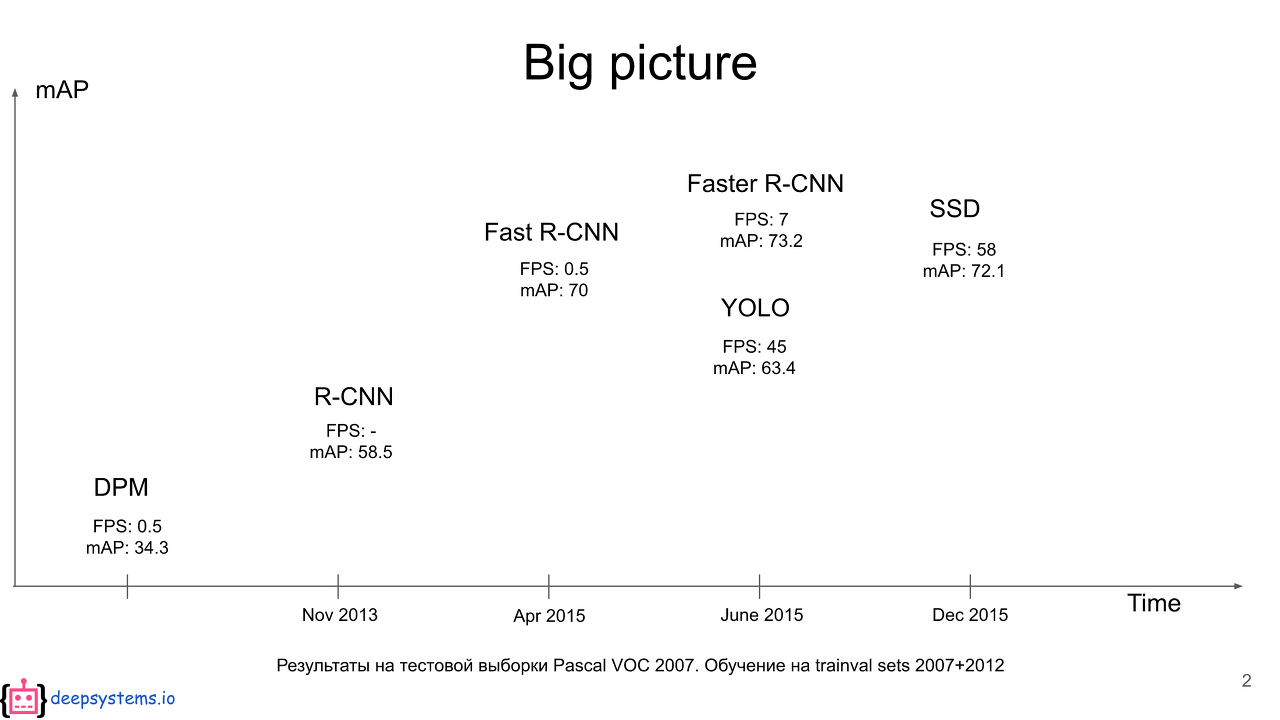
YOLO가 월등한 속도를 갖게 된 이유는.
바로 기존에 Region proposal과 Classification 단계를 각각 나누어 진행하던 CNN의 방식에서 이러한 2가지 방식을 합쳐서 한번에 수행하는 구조를 갖기 때문입니다.
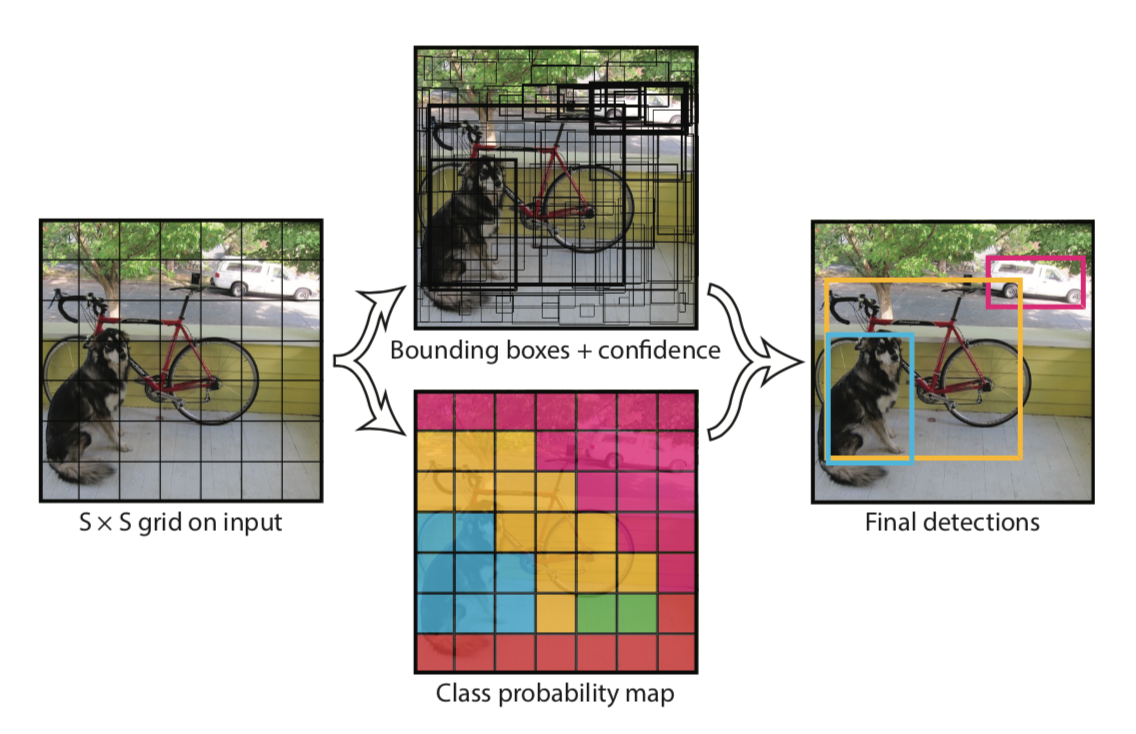
YOLO 논문에서 제공하는 자료를 보면, 처음부터 이미지를 그리드의 영역으로 나눈 뒤 해당 그리드를 기준으로 객체 후보군의 위치를 나는 것을 볼 수 있습니다.
이러한 방식은 Bounding box의 연산량을 줄여주는 역할을 하며 그리드를 더욱더 세세하게 나눈다면 정교한 Bounding Box를 얻을 수 있습니다.
또한 나누어진 그리드별로 바로 classcificaton을 수행하여 판단하여 속도 측면 성능이 향상될 수 있었습니다.
1-4. 모델 선택
졸업작품으로 진행하려는 프로젝트의 경우, 움직이는 교내 에코버스인점을 감안하면 실시간 처리가 가능한 YOLO 모델이 적절하다고 판단하여 One stage Detector인 YOLO로 선택했습니다.
