SiReN: Sign-Aware Recommendation Using Graph Neural Networks

한줄요약
추천시스템에서 negative feedback을 버리지 말고 사용해보자!
(이 논문은 2021년 version 1이 있고, 2022년 version 2가 있다. 둘의 차이는 loss가 많이 바뀐 점이다. 이 리뷰는 2022년 version 2를 리뷰한다.)
ABSTRACT
최근 추천시스템에서 positive feedback만을 이용하고, negative feedback은 이용하지 않는데, 이 논문에서는 negative feedback도 이용해보겠다. (모델 이름은 SiReN)
SiReN
1) bipartite graph로 구성하고, positive edges랑 negative edges를 각각 따로 분리한다.
2) positive edges는 GNN으로, negative edges는 MLP로 훈련하여 각자 embedding 생성 후에 attention model을 최종적으로 사용해서 최종 embedding을 만든다.
3) BPR loss를 사용하는데, 그냥 BPR loss가 아니고 sign-aware BPR loss를 사용한다.
1. INTRODUCTION
GNN 기반 추천시스템은 많은 발전을 해왔다.
GNN 모델은 기본적으로 대상 노드와 그 이웃이 서로 유사하다는 homophily(또는 assortativity) 가정 하에 전달되는 메시지를 통해 직접 이웃 노드의 정보 전달을 집계하여 훈련된다.
GNN 기반 추천시스템에서 강한 homophily를 나타내기 위해 negative feedback을 제거하고, positive feedback만 활용하는 것이다.
그럼에도 불구하고 negative feedback에는 사용자가 싫어하는 정보가 들어있기 때문에 활용 가치가 있다.
SiReN
1) signed graph construction and partitioning
-> user-item간의 긍정적 관계와 부정적 관계를 모두 학습하지 못하는 기존 GNN의 주요한 문제점 때문에 positive edges와 negative edges를 모두 한 번에 훈련하는게 아니라 나눠서 훈련하는 것이다.
2) model architecture design
-> balance theory에 기반한 기존 GNN 접근 방식을 사용하는 대신, 각 분할된 그래프에 대한 자체 모델 아키텍처를 설계한다. positive edges는 GNN 모델을 사용하고, negative edges는 MLP 모델을 사용한다 (negative edges를 GNN 모델에 사용하면 homophily를 약화시킬 수 있으므로 사용하지 않는다. user1 과 user2가 같은 item을 동일하게 싫어한다고 해서 user1과 user2의 취향이 같다고 말할 수 없다). 그리고 최종 embedding을 얻기 위해 atteion 모델을 사용한다.
3) model optimization
-> 원래의 BPR loss를 기반으로 하여 만든 sign-aware BPR loss를 사용한다. 이것을 사용하면 user와 item 사이의 positive, negative, unobserved 관계를 파악할 수 있다.
2. RELATED WORK
A. Standard CF Approaches
B. NE-Based Recommendation Approaches
- LR-GCCF
- LightGCN (https://velog.io/@chwchong/LightGCN-Simplifying-and-Powering-Graph-Convolution-Network-for-Recommendation)
C. NE Approaches for Signed Networks
-SGCN
3. METHODOLOGY
G = (U,V,E) 로 나타낸다. U는 M명의 user, V는 N개의 item, E는 U와 V의 weighted edge 이다. (u,v,Wuv) ∈ E 로 나타낼 수 있고, Wuv는 rating 값이다 (ex. user u가 item v를 4.5점(Wuv)으로 평가했다).
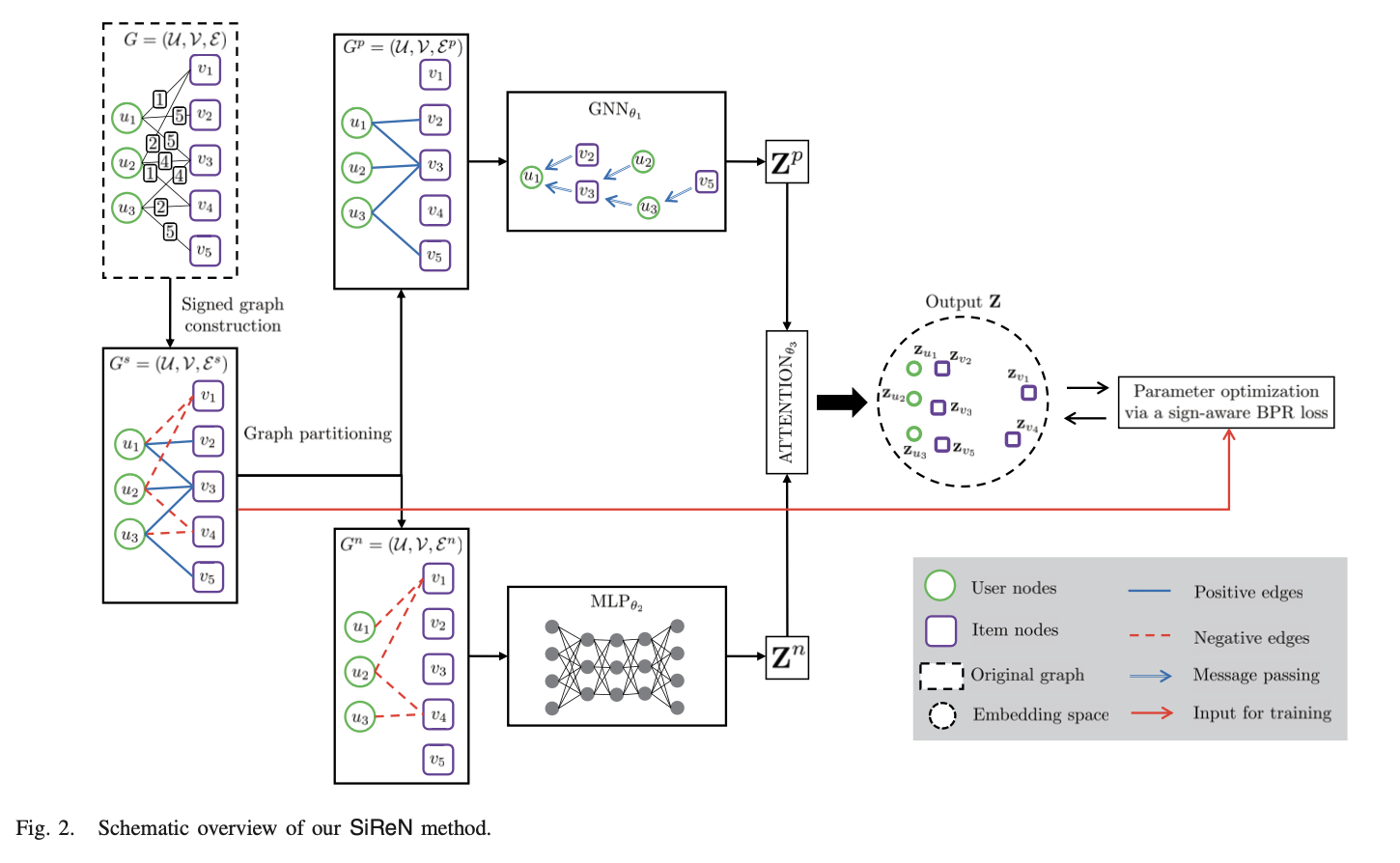
1) Signed bipartite graph construction and partitioning.
-> positive edge와 negative edge 구분 없이 전체 edge를 Gs = (U,V,Es) 로 나타낸다 (여기서 s는 Signed bipartite graph 할 때 s인 것으로 추측된다). 그리고 아래 식을 만족한다.
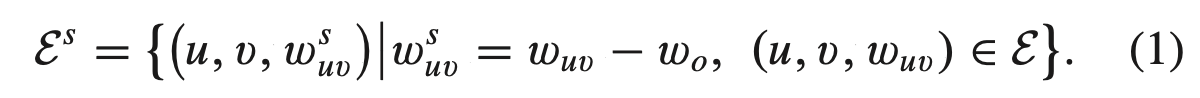
여기서 w0 > 0 이라고 논문에서 설명하는데, 코드를 보니 w0는 3.5로 나와있었다 (w0를 각 user의 평균으로 하는 것도 있지만 보통 3.5를 많이 쓴다). 여기서 3.5라는 것은 3.5를 초과하는 rating은 positive로 그렇지 않은 rating은 negative로 보겠다는 것이다. 그래서 아래와 같은 식으로 나뉠 수 있고, 이렇게 분할된 것이 위의 모델 그림에서 분할된 것과 동일하다.
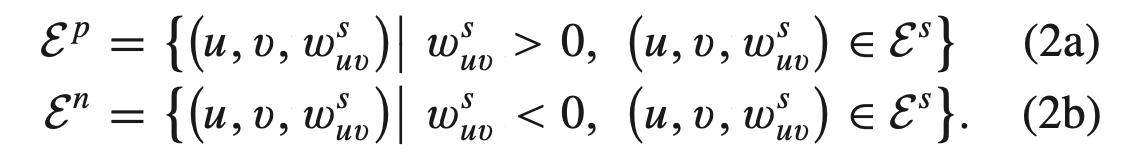
2) Embedding generation for each partitioned graph.
-> GNN, MLP, ATTENTION을 소개한다.
GNN: positive edge는 LR-GCCF와 LightGCN 모델을 채택하여 사용한다. 아래의 Zp는 (M+N) x d 차원이다.
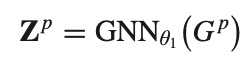
MLP: negative edge는 MLP를 사용한다. 아래의 Zn은 (M+N) x d 차원이다.
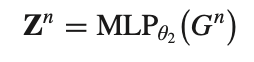
ATTENTION: attention mechanism을 사용하여 Zp와 Zn의 importance를 얻는다. 아래의 αp와 αn은 (M+N) x 1 차원이고, 1attn은 1 x d 차원이다.

이렇게 GNN, MLP, ATTENTION를 거쳐서 아래와 같은 final embedding Z를 구한다. 아래의 Z는 (M+N) x d 차원이다.
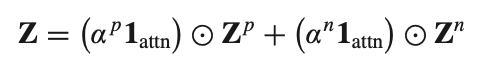
3) Optimization via a sign-aware BPR loss.
-> 기존 BPR loss은 negativelt connected neightbors를 capture하지 못하기 때문에 긍정, 부정 관계를 모두 고려하기 위해서 기존 BPR loss가 아닌 이 논문의 저자가 제안한 sign-aware BPR loss를 사용한다.
Algorithm

4. PROPOSED SiReN METHOD
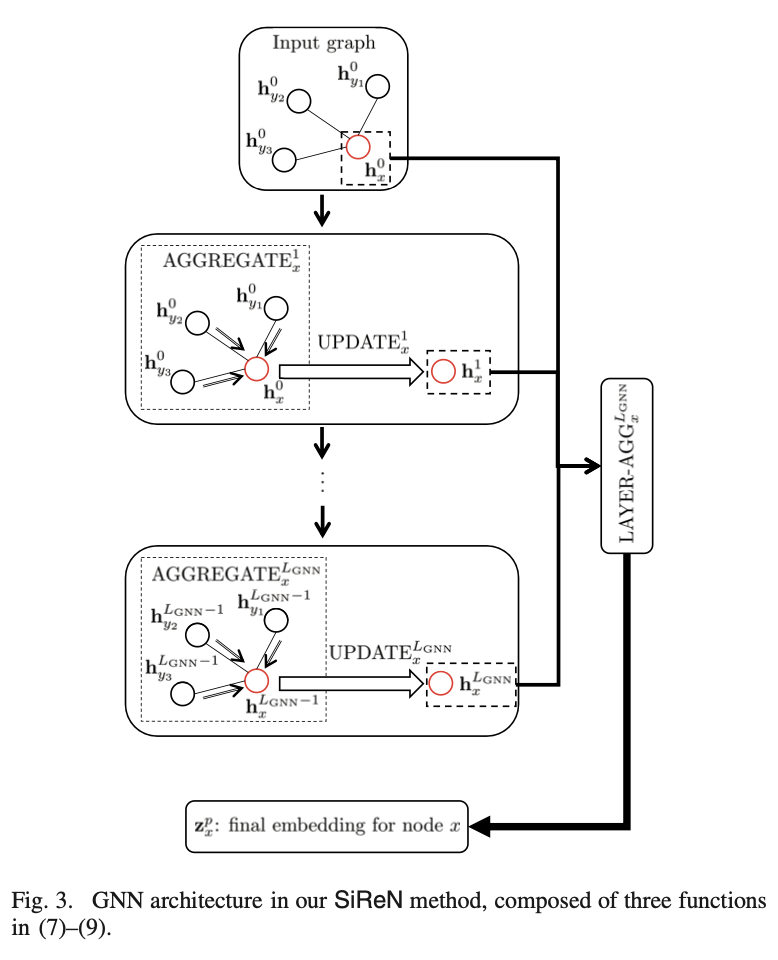
GNN for positive
시작하기 전에 아래의 사진을 먼저 이해하면 좋을 것 같다.
(출처: https://www.youtube.com/watch?v=PrNwfNOge8o&t=609s)

AGGREGATE: x의 주변 노드 y에게 message를 받아서 AGGREGATE 한다.
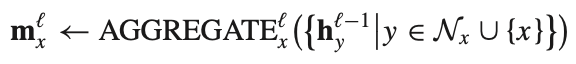
UPDATE: 자기 자신의 정보와 AGGREGATE한 정보를 합친다.

LAYER-AGG: 오버스무딩 방지를 위해 만든 장치이다. 아래 식과 아래 사진을 함께 참고하면 된다.
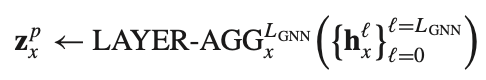
MLP for negative
negative edge는 아래와 같은 식으로 연산된다. 그냥 단순한 MLP 식이다.
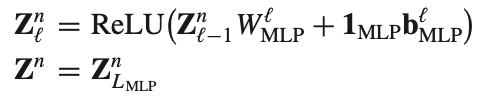
ATTENSION for positive + negative
attention model을 사용하여 Zp와 Zn의 importance αp와 αn을 얻는다. 식은 아래와 같다.
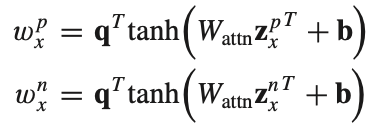
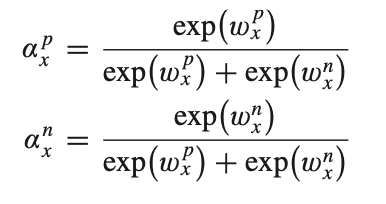
optimization
sign-aware BPR loss를 사용하기 위해 negative sampling을 한다 (여기서 negative sampling은 negative feedback을 sampling 한다는게 아니라 unobserved item을 sampling 한다는 말이다). training set Ds를 triplet (u,i,j)로 구성하는데 u는 user, i는 observed item, j는 negative sampling된 unobserved item이다. 여기서 j를 추출하는 방법은 아래와 같은 degree-based noise distribution을 따른다. 여기서 dj는 item j의 degree이다.
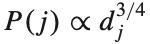
이렇게 구성된 training set Ds는 아래와 같은 식을 따른다. 아래 식에서 negative sample의 개수 n은 40개이다.
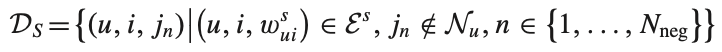
최종 예측값은 아래와 같이 계산되는데, 이것을 바탕으로 optimization을 수행한다.
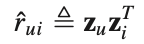
(여기부터는 BPR 논문을 이해하지 못하면 따라올 수 없기 때문에 BPR 논문을 반드시 읽고고 와야한다. https://arxiv.org/pdf/1205.2618.pdf)
이제부터 sign-aware BPR loss를 소개한다. 일단 아래의 식이 전체적인 loss function이고,
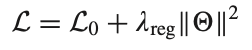
L0가 아래와 같이 나타나는데,
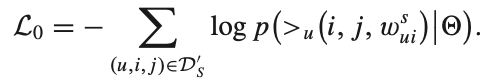
여기서 p는 아래와 같다. 여기서 중요한 것은 w가 0보다 크면 그냥 BPR loss와 동일한데, 그렇지 않으면 c가 붙어서 식이 약간 달라진다. 직관적으로 보면 r^ui > (1/c) x r^uj 이어야 한다는 것이다. 수식을 한글로 풀어쓰면 "user u가 item i를 negative feedback한 것의 예측값 > (1/c) x user가 unobserved한 item i의 예측값"이어야한다고 할 수 있다. 여기서 c는 2이다. positive와 negative에 차이를 두고 unobserved를 통해 optimization을 할 수 있다.
5. EXPERIMENTAL EVALUATION
Precision@k, Recall@k, nDCG@k로 성능을 평가한다.
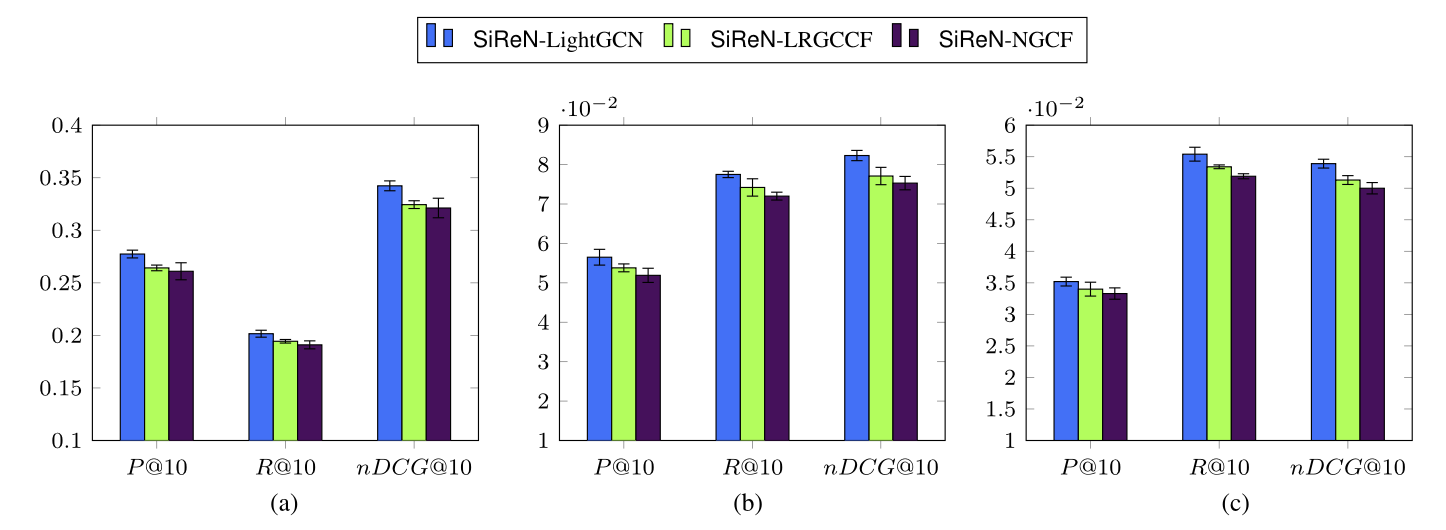
RQ1: How do underlying GNN models affect the perfor- mance of the SiReN method?
-> positive feedback을 train 할 때 LightGCN이 가장 효과적이라는 것이 아래의 실험에서 증명한다.
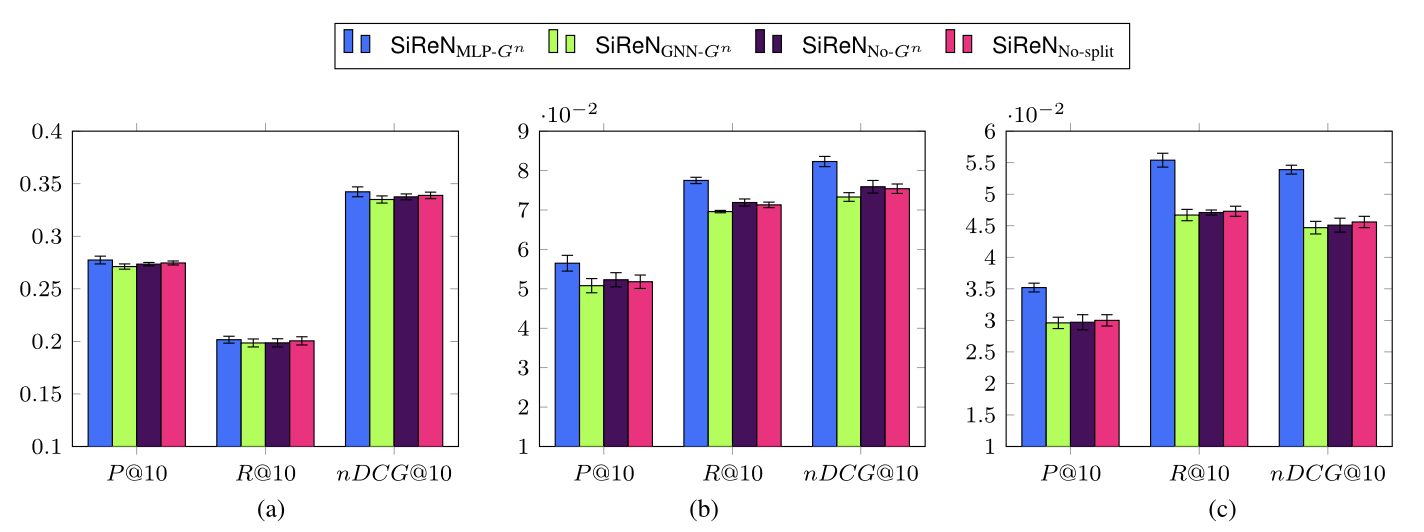
RQ2: Which model architecture is appropriate to the graph Gn with negative edges?
-> negative train 할 때는 MLP를 사용하는 것이 가장 적합하다고 아래의 실험이 설명한다.
RQ3: How much does the SiReN method improve the top-K recommendation over baseline and state-of-the-art methods?
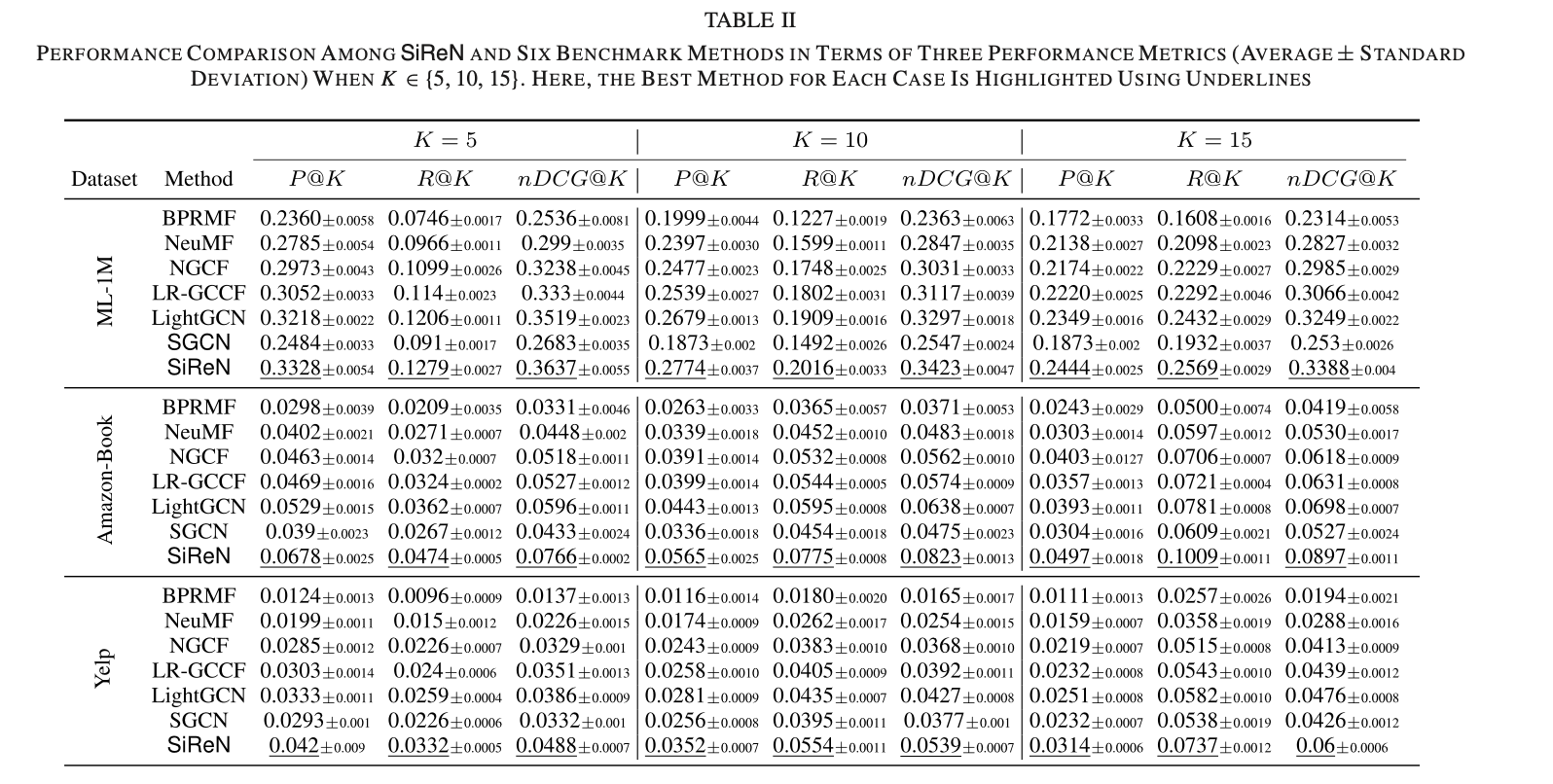
-> 아래의 표가 SiReN이 SOTA인 것은 보여준다 (다만 SiReN을 제외한 모델은 negative를 train에 사용하지 않았다는 점은 알아두어야한다. 이 논문에서도 ground truth 값은 negative feedback을 활용하지 않은 기존 모델들과 동일하게 4점 이상인 것만 정답으로 간주했기 때문에 pair comparison이라고 하는데 냉정하게 보면 train에서 data를 더 사용하였기 때문에 성능이 좋아진 것도 있으니 이를 부정할 수 없다고 생각한다).
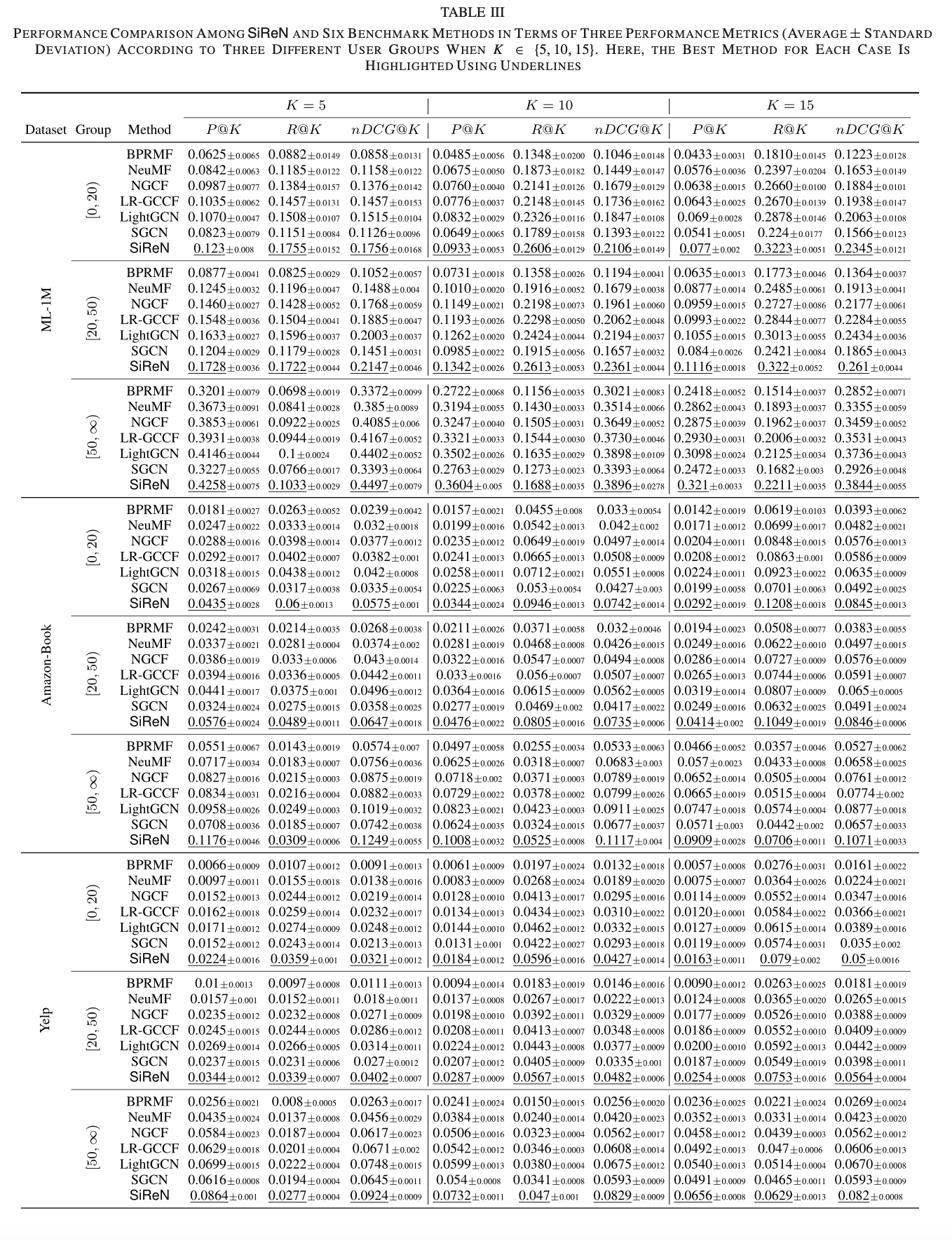
RQ4: How robust is our SiReN method with respect to interaction sparsity levels?
-> negative feedback은 sparse 문제를 완하시킬 수 있고, 아래의 표를 통해 증명한다. SiReN과 second best performer 사이의 gap이 가장 큰 것은 Amazon-Book dataset의 [0, 20) 구간이다. Amazon-Book dataset은 3개의 dataset 중에서 가장 sparse하고 [0, 20) 구간은 그 중에서도 가장 sparse한 것이기 때문에 sparse한 것에 확실한 효과가 있다고 할 수 있다.
6. CONCLUSION
negative feedback을 활용한 SiReN이 negative feedback을 활용하지 않은 LightGCN에 비해 최대 30.93%의 성능 향상을 보일만큼 negative feedback을 활용할 필요가 있다.
