이번에 few shot learning과 metric learning에 대해 공부하면서 읽게 된 논문에 대해 정리해보려고 한다!
일단 앞으로 하게될 과제에 필요한 부분만 겟또 ㅎ0ㅎ
FaceNet (Florian Schroff, Dmitry Kalenichenko, James Philbin, 2015)
🔈논문을 읽고 제가 이해한 것을 기반으로 정리한 논문이라 오류가 있을 수 있습니다. 오류가 있다면 댓글 남겨주시면 감사하겠습니당~~!
Background
Metric Learning
metric learning은 Input image를 이용하여 feature extraction을 학습함으로 기하학적 거리가 시맨틱 거리에 근접한 새로운 feature space로 바꾼다. 즉, input image space에서 data들에 가장 적합한 형태의 어떤 metric을 learning하는 알고리즘이다. 여기에서 data는 각 pair 별로 유사도가 정의되어 있는 형태의 데이터이다. metric learning은 유사한 데이터들끼리는 가까운 거리로, 유사하지 않은 데이터들끼리 더 먼 거리로 판단하게 하는 어떤 metric을 학습하는 것이다.
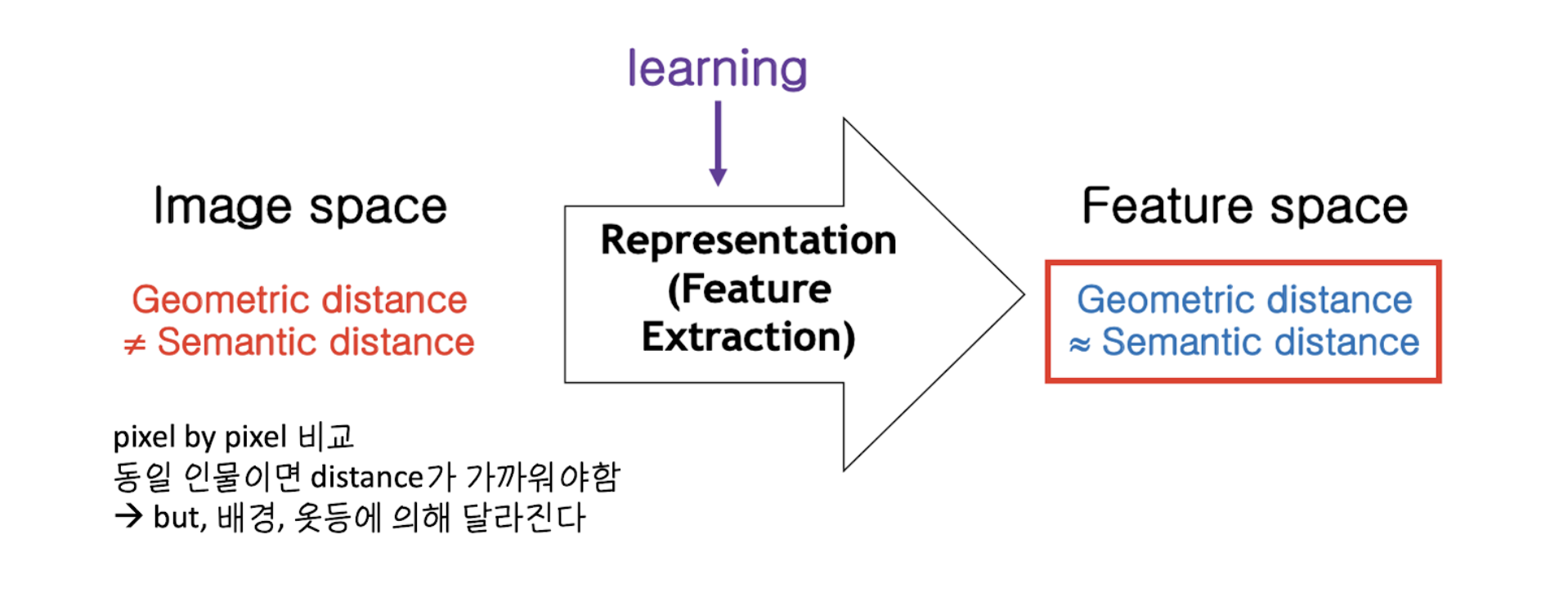
기존의 Image space에서는 pixel by pixel로 비교하기 때문에, 기하학적 거리와 시맨틱 거리가 일치하지 않는다. 예를 들어, 인물 사진 2장을 비교했을 때, 동일 인물이면 거리가 가까워야 하는데, 인물이 입고 있는 옷이나 배경에 따라 그 거리가 달라지기 때문에 두 공간상의 거리가 일치하지 않게된다.
하지만, Fearture extraction을 학습시키면, feature space에서의 기하학적 거리는 시맨틱 거리에 근접하게 되어, 굉장히 좋은 성질을 갖게 된다. 이는 하나의 sample을 골라, 대표 sample과의 거리만 재면 어떤 클래스인지 파악 할 수 있게 되는 것을 의미한다.
Feature Extraction이란, 고차원의 원본 feature 공간을 저차원의 새로운 feature 공간으로 투영시킨다. 새롭게 구성된 feature 공간은 보통은 원본 feature 공간의 선형 또는 비선형 결합이다.
특징 추출기가 추출한 특징 벡터 간 거리가 입력 패턴 간의 의미적 거리와 비례하도록 학습하면, 동일 클래스의 샘플들이 특징 공간 상에서 유사한 위치에 배치되도록 할 수 있다.
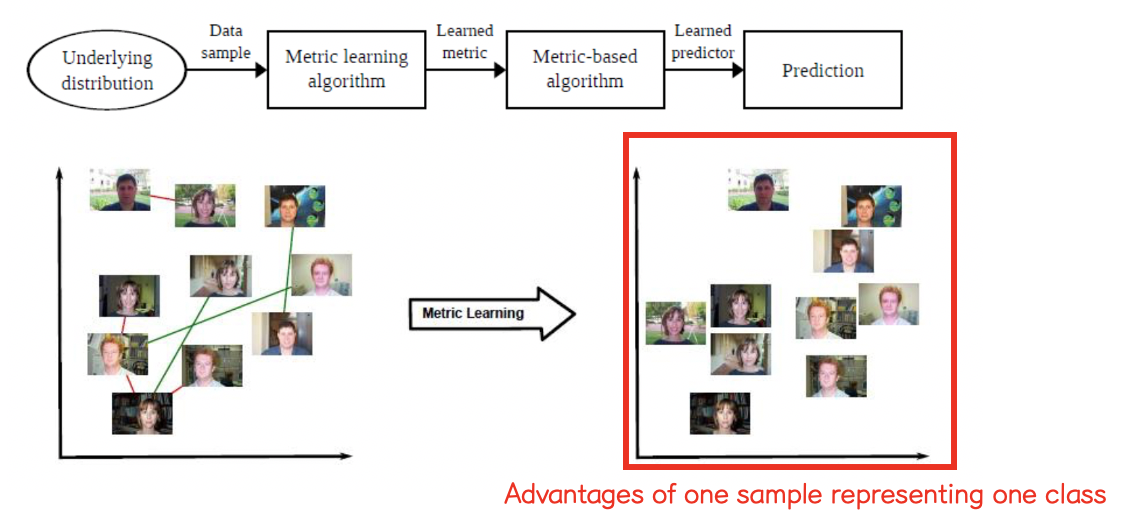
Metric learning이 성공적으로 이루어지면, 거리척도를 이용한 간단한 학습 모델을 이용하여 효율적으로 인식을 수행할 수 있다.
Few shot learning
Few-shot learning은 각 클래스 별 소수의 참조 샘플만으로 클래스의 특성을 학습하여, 인식을 수행하는 학습 알고리즘이다.
- 다음 그림과 같이 각 클래스 별 소수의 참조 샘플에 의해 인식을 수행하며, 기존 인식 클래스에 속하지 않은 클래스도 소수의 참조 샘플을 추가함으로써 인식 대상에 추가할 수 있다.

Abstract & Introduction
-
해당 논문은
Face-Verification, Recognition, Clustering을 위한 통합시스템 제시한다. -
FaceNet이라는 시스템은 얼굴 이미지로부터 얼굴 유사성과 직접적으로 대응하는 유클리드 공간의 관계를 직접적으로 학습한다.
-
이 논문에서는 Deep Convolution Network를 이용하여, 이미지당 유클리드 임베딩을 학습한다.
-
여기서 임베딩 공간의 L2 distance는 얼굴 유사도와 곧바로 일치한다.
(같은 사람의 얼굴은 적은 거리, 다른 사람일 경우 큰 거리) -
기존 접근 방법에서는 CNN의 중간 단계 레이어의 출력값 사용한다. 이는 중간 레이어를 사용하기 때문에 간접적이며, 비효율적이고 차원이 크다는 문제가 발생한다. FaceNet 논문에서는 direct하게 저차원의 임베딩을 적절히 구현하는 방법을 제시하며, 저차원의 벡터를 학습 시키는 방법으로
Triplet loss를 제안한다.
Method
-
Triplet network
Triplet Network는 동일한 네트워크 3개와, 기준이 되는 클래스에 속하는 샘플 x와, 다른 클래스에 속하는 negative sample, 같은 클래스에 속하는 positive smaple로 구성된다.
일반적은 손실함수가 한 개의 input sample을 받는데 비해 삼중항 손실 함수는 위의 3개의 입력을 받으며, loss또한 3개의 입력에 대해 계산한다.
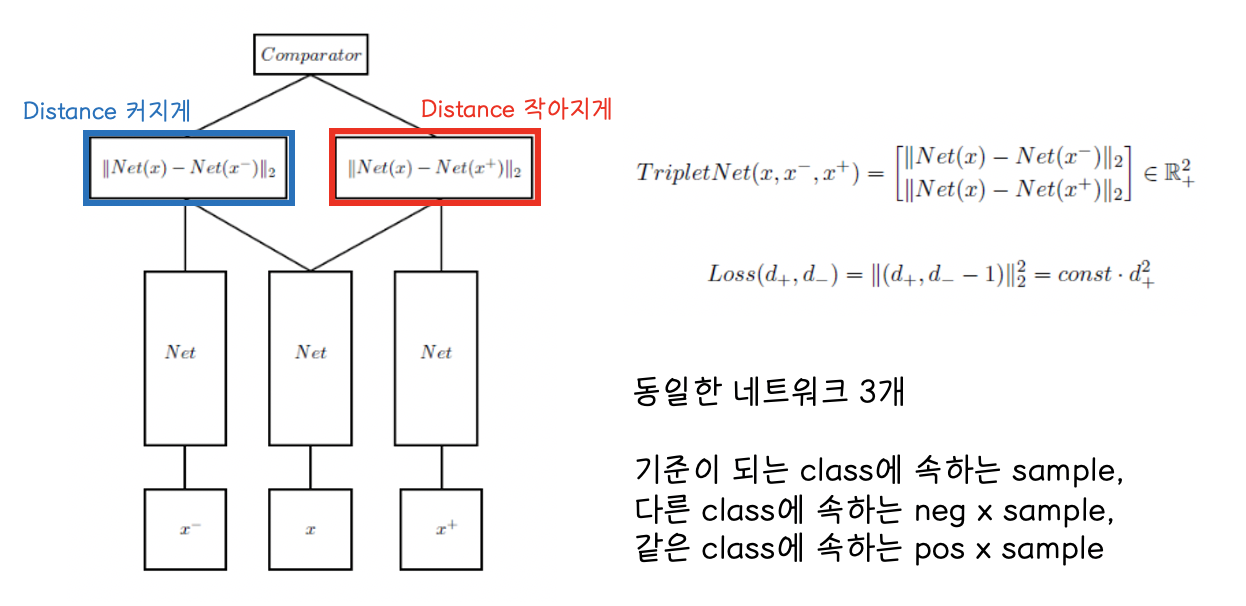
-
Triplet loss
Triplet loss는 anchor sample, positive sample, negative sample, 3개의 샘플에 대해 loss 계산을 수행한다.
앞에서 말했던 저차원의 벡터를 학습 시키는 방법으로 사용한다. 같은 사진은 가까운 거리에, 다른 사진 먼 거리에 있도록 유사도를 벡터 사이의 거리와 같아지게 하려는 목적이다. 이를 loss로 나타낸다.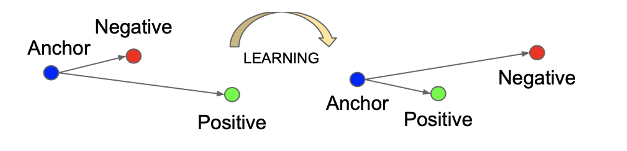
같은 사진을 가깝게, 다른 사진을 멀게 하는 것을 표현한 식이 다음과 같다.
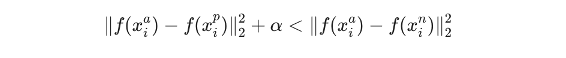
α는 positive와 negative 사이에 주고 싶은 margin을 의미한다고 생각하면 된다.
이를 Loss function으로 나타내면 다음과 같다.
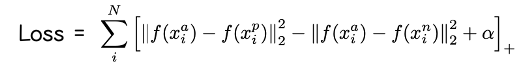
-
Triplet selection
위의 식을 만족하는 triplet을 만들면서 학습을 진행할 때, 완전 다른 사진일 때는 너무 쉽게 만족하는 경우가 많을 것이다. 이런 경우, 학습이 제대로 되지 않는 문제가 발생한다. 따라서 잘 구분하지 못하는 사진을 넣어, 위의 식을 만족하지 않는 triplet을 만들어야 한다.
따라서 최대한 먼 거리에 있는 Positive를 고르고, 최대한 가까운 거리에 있는 negative를 골라야 한다.

이를 각각 hard positive, hard negative로 표현한다. 하지만, 전체 데이터에서 각각 hard point들을 찾아야 한다고 할 때, 계산량이 많아져 시간이 많이 필요하며, 비효율적이고, 오버피팅이 생길 수 있다는 문제가 발생한다. 따라서, 이것을 해결하기 위해 이 논문에서 mini batch 안에서 hard point를 찾도록 하는 방법을 제시한다. 이 때, hard positive를 뽑는 것보다 모든 anchor-positive쌍을 학습에 사용하며, hard negative를 뽑을 때는 다음과 같은 식을 만족하는 x중에 뽑는 것이 좋은 성능을 보였다고 한다.
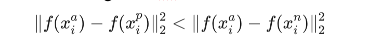
이러한 negative examplars를 semi-hard라고 부른다.
이는 anchor-positive보다 anchor-nagative간 거리가 더 멀긴 가지만 margin이 충분히 크지 않은 nagative를 뽑는 것이다.

(수정 예정 20.03.18)
