
for gbc...
🤖 인공지능, 머신러닝, 딥러닝
인공지능 (Artificial Intelligence)
- 인간의 학습능력, 추론 능력등을 컴퓨터를 통해 구현하는 포괄적 개념
- Strong AI 와 week AI 로 구분
머신러닝 (Machine Learning)
- Data 를 이용하여 데이터 특성과 패턴을 학습하여, 그 결과를 바탕으로 특정 데이터에 대한 미래 결과(값, 분포)를 예측
- Learn from data
딥러닝 (Deep Learning)
- 머신러닝의 방법론 중 하나로 심층신경망을 통해 고급 정보를 학습하는 알고리즘의 집합
📚 머신러닝 유형
지도 학습 (Supervised learning)
- 정답이 주어진 상태에서 학습하는 알고리즘
- 입력 값(x)와 정답(label)을 포함하는 Training Data 를 이용하여
학습하고, 그 학습된 결과를 바탕으로 Test Data 에 대해 미래 값을 예측하는 방법

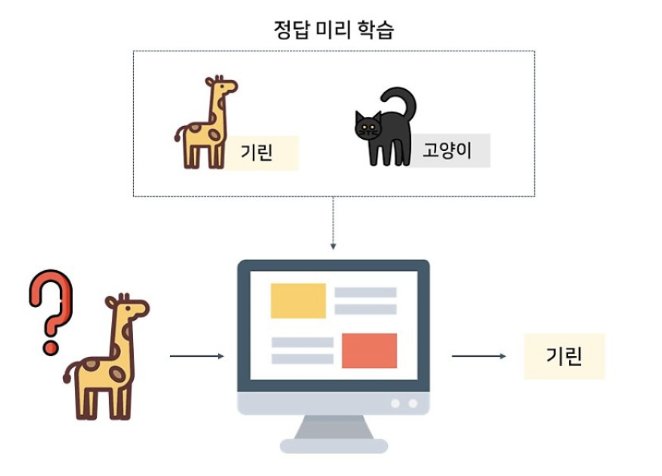
수많은 고양이와 기린의 사진을 주고 각 사진이 고양이인지 기린인지 정답을 알려준 후, 어떤 사진을 주었을 때 고양인지 기린인지 맞힐 수 있도록 하는 것
💁🏻♀️ 대표적인 예
- 분류 문제 (Classfication)

- 개와 고양이 이미지 분류
- 어떤 데이터를 적절한 유한개의 클래스로 분류하는 것을 의미
- binary classification, multiclass classification)
- 회귀 문제 (Regression)

- 주가 예측
- 데이터의 특징을 기반으로 연속적인 값을 예측하는 것
- 일반적으로 연속적인 숫자(벡터)를 예측하는 문제 - 음성 인식 (Speech Recognition) : siri
- 언어 번역 (Language Translation) : 번역기
- 이미지 세그멘테이션 (Image Segmentation)
비지도 학습 (Unsupervised learning)
- 데이터에 대한 label 또는 목적 변수가 주어지지 않은 상태에서 network를 학습시키는
방법이다. 비지도 학습을 통해 데이터를 시각화함으로써 데이터를 이해하는데 유용하다. - 비지도 학습은 데이터의 숨겨진 특징 (Hidden feature)이나 구조를 발견하는데 사용된다.
💁🏻♀️ 대표적인 예
-
클러스터링 (Clustering)
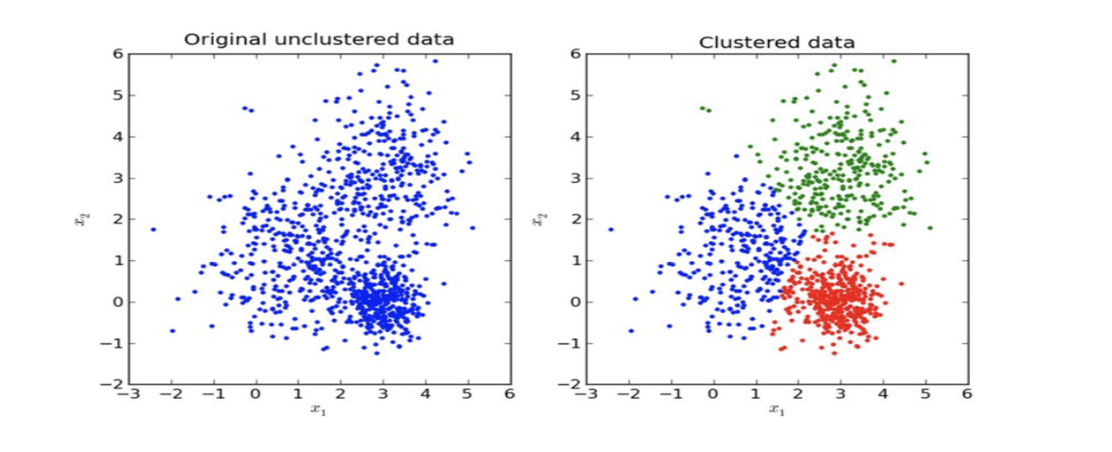
데이터가 무작위로 분포되어 있을 때, 해당 데이터를 비슷한 특성을 가진 부류로 묶는 알고리즘
-
Auto-Encoder
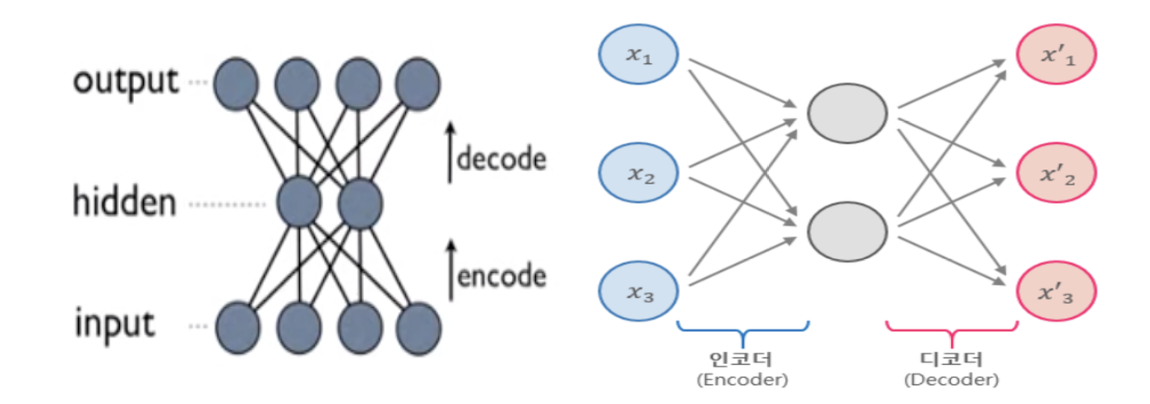
입력을 출력으로 복사하는 신경망.
Hidden layer 의 뉴런 수를 input layer 보다 작게 하여 데이터를 압축 (차원 축소)하거나, 입력 데이터에 noise 를 추가한 후 원본 입력을 복원할 수 있도록 네트워크를 학습시키는등 다양한 오토인코더가 있다.
단순히 입력을 바로 출력으로 복사하지 못하도록 방지하며, 데이터를 효율적으로 표현하는 방법을 학습하도록 제어한다. -
Latent variable models
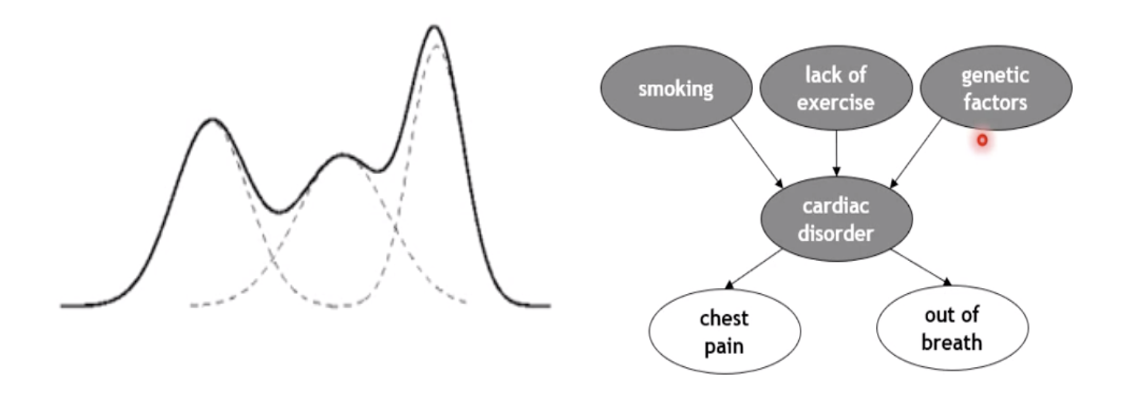
어떤 현상 관찰, 관찰한 현상의 hidden feature 이나 structure 를 발견하는 것이다.
일부가 주어졌을 때, 역으로 추정하는 것을 의미하며, 나타나 있는 현상을 가지고 숨겨진 것을 예측한다.
관찰가능한 변수: visible variable,
관찰 불가능하지만 머신러닝 테크닉으로 추정하는 변수: latent variable
준지도 학습 (Semi-supervised Learning)
- Label 이 없는 sample data 로부터 정확한 정보를 가급적 많이 얻어내 성능을 향상하는 것이 주요한 목적이다.
- 다량의 데이터가 정답이 있기도 없기도 할 때, 소량의 데이터에
대해서만 확실한 정답 값을 부여하고 나머지는 스스로 학습하며 정답 값을 달아 주는 것.
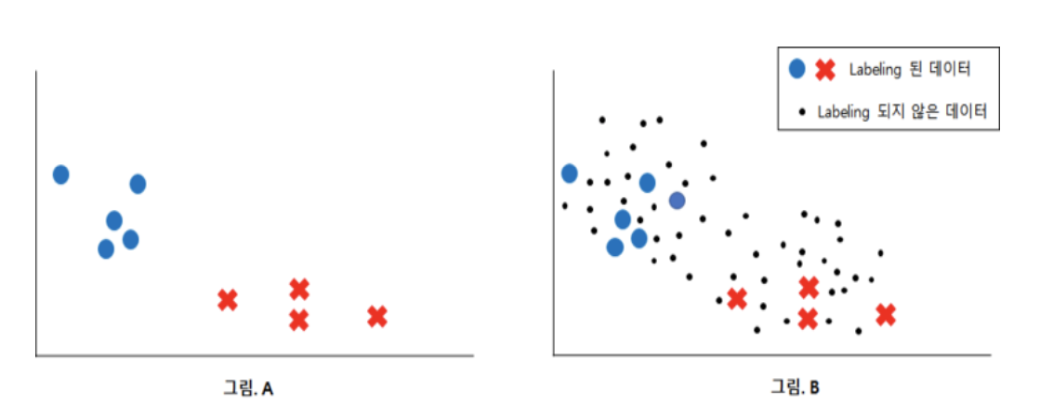
A는 labeling이 된 데이터이므로, 지도학습을 통해 분류 가능하다.
B는 labeling 이 되어있지 않은 데이터들도 함께 가지고 있음
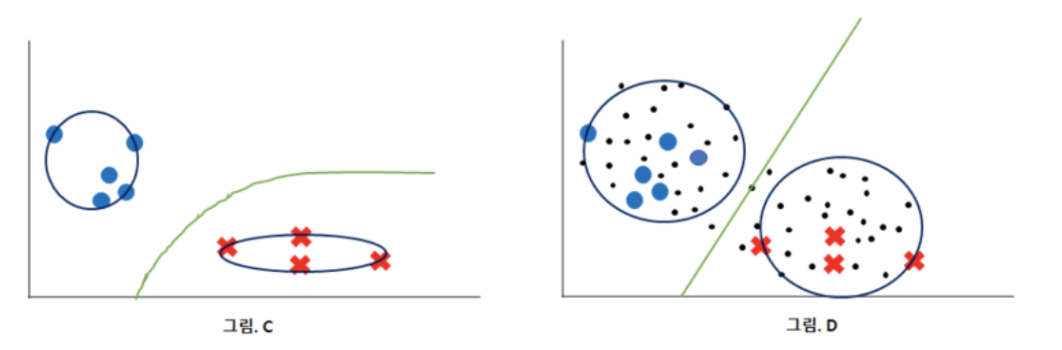
labeling 되어있지 않은 데이터들을 통해 그림 D에서 더 나은 분류를 하였다. (label 이 없는 데이터가 분류에 도움이 된 경우)
어떤 모델을 사용하느냐에 따라 unlabeling 된 데이터가 도움이 될 때도 있고 되지 않을 때도 있다.
강화 학습 (Reinforcement Learning)
- 지도학습과 비지도학습이 data가 주어진 정적인 상태에서 학습을
진행하였다면, 강화 학습은 에이전트가 주어진 state 에 대해 어떠한
action을 취하고 이로부터 특정한 reward를 얻으면서 학습을 진행한다. - 이 때, 에이전트는 reward 를 maximize 하도록 학습이 진행된다. 즉,
강화 학습은 동적인 상태에서 데이터를 수집하는 과정까지 포함된 알고리즘이다.
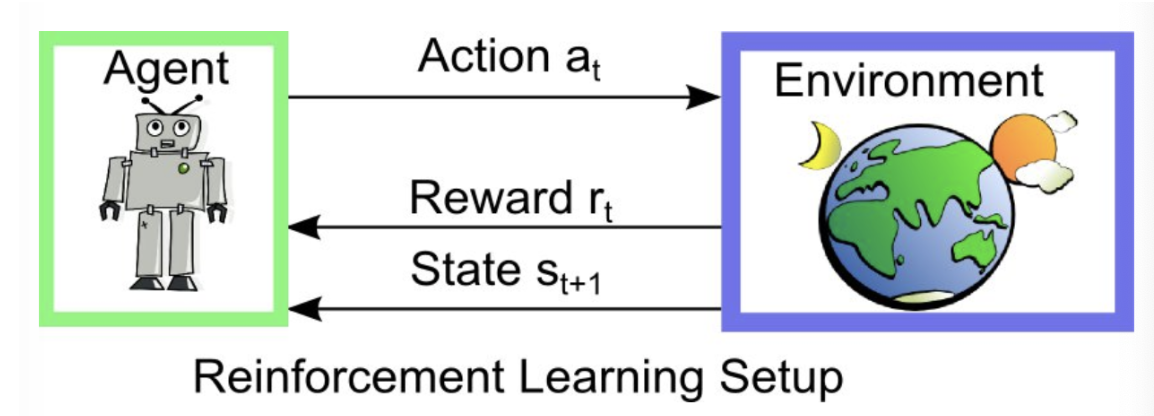
Ex) environment: 바둑판, agent:알파고(각 상태에서 액션을 취할 수 있음, reward 를 maximize 해야함), state: 현재 바둑판의 국면, reward: environment 가 주는 결과물(집을 몇 개 만드냐), action: 어디에 돌을 둘 것인가
learn actions to maximize reward signal
- Policy :
p(a|s), 에이전트가 현재 상태를 기준으로 다음의 행동을 결정하는데 사용하는 전략, 에이전트는 특정한 상태에서 보상을 최대화할 수 있는 행동을 선택함. - Value of state :
v(s), 현재의 상태에서 policy 에 따른 기대되는 보상 - Value of action (Q-function) :
Q(s, a), 현재의 상태에서 취하는 행동 a 를 고려. Quality of action
