StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks 논문 정리
DeepLearning
2019년 NVIDIA에서 발표하여 화제가 됐던 A Style-Based Generator Architecture for Generative Adversarial Networks(StyleGAN)를 읽고 정리한 글이다.
1. Introduction
PGGAN
StyleGAN의 Baseline이 되는 모델은 PGGAN이다. 따라서 style GAN을 이해하기에 앞서 PGGAN의 핵심 원리와 구조에 대한 이해가 필요하다. 기존 GAN은 고해상도 이미지를 생성하기 어렵다는 문제점이 있었다. 이는 high resolution일수록 fake image 여부를 구분하기 쉬워지기 때문이다. 게다가 큰 해상도 이미지를 생성할 때 메모리 제한 문제가 있기 때문에 더 작은 mini-batch를 사용하게 되는데, mini-batch의 크기가 작아지면 학습이 불안정해지는 현상이 발생하게 된다. 이런 문제를 해결하고자 제안되었던 모델이 PGGAN이다.
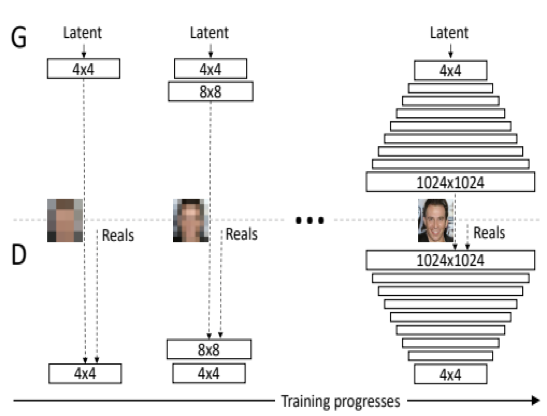
PG GAN의 구조
PGGAN의 핵심은 한 번에 전체 크기의 이미지 feature를 학습 시키기보다는 4x4의 저해상도 이미지에서부터 시작하여 1024 x 1024의 고해상도로 높아지게끔 하는 것이다. 즉, Generator와 Discriminator를 점진적으로 학습시켜, 점차적으로 더 높은 레이어를 추가하는 것이 해상도 성능 측면에서 효과적이라는 것이다.
하지만, PGGAN은 고해상도의 이미지를 생성하지만 생성된 이미지의 구체적인 특징을 컨트롤하는 퍼포먼스는 매우 제한적이다. 다시 말해, feature들이 얽혀있기 때문에(entangled) input을 조금이라도 조정하게 되면 동시에 여러 특징에 영향을 미치게 된다.

PGGAN의 latent space interpolation 결과이다. Interpolation 과정에서 상당히 어색한 이미지들이 나오는 것을 볼 수 있다.
여기서 Interpolation이란, 두 점을 연결하는 방법 의미하며, 궤적을 생성한다는 뜻이다. (압축한 정보를 다시 복원 하기 위함) 실험적으로 구해진 데이터들로부터 주어진 데이터를 만족하는 f(x)를 구하고, 해당 식을 이용해 주어진 변수에 대한 함수값을 구하는 과정이라고 이해하면 된다.
StyleGAN
이 논문에서 소개하고 있는 Style GAN 모델은 PGGAN의 이런 문제점을 해결할 수 있는 효과적인 방법을 제안한다. 이 논문이 제안하고 있는 것들을 요약하면 다음과 같다.
- 기존 GAN과 다른 generator architecture 제안
- Image 합성 과정에서 scale-specific control 가능
- Latent space의 interpolation quality 측정 방법 제안
▶️ Perceptual path length, linear separability - ClebA-HQ보다 고화질이고 다양한 사람의 얼굴을 포함하는 FFHQ 데이터셋 공개
2. Style-based generator
본 논문에서 제시하는 generator의 구조이다.
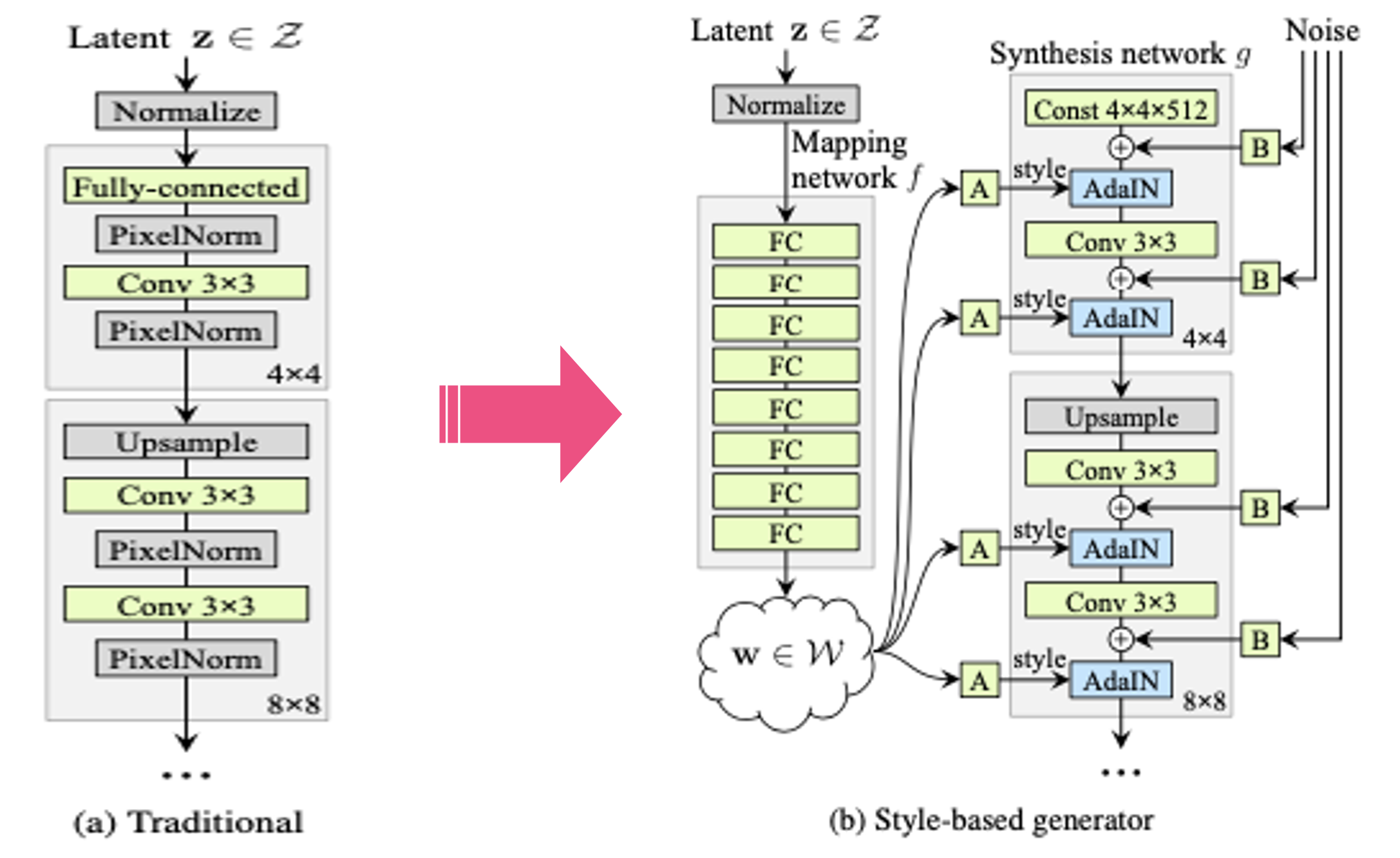
왼쪽 그림에서 (a)가 기존 GAN의 generator 구조이고, input latent vector가 직접 convolution, upsampling을 거쳐 이미지로 변환 되고 있다. 이런식으로 latent vector가 바로 input으로 들어가게 되면, latent vector는 반드시 트레이닝 데이터의 확률 밀도를 따라야만 한다. 트레이닝 데이터 분포에 완전히 관여하고 있어서 헤어스타일이나, 시선만 변경한다던지 이런 부분에 있어 매우 제한적이게 되는 것이다. 이는 generator 모델이 학습을 하는동안 latent space가 entanglement하게 만들어지게끔 한다. 그러나 오른쪽의 style-based generator의 경우, input vector가 직접 convolution으로 들어가지 않고 fully connected layer로 구성된 mapping network를 통과하여 w 벡터로 변환된다. 그리고 변한된 w 벡터는 constant tensor가 이미지로 변환되는 과정에서 스타일을 입히는 역할을 수행함으로써 다양한 스타일의 이미지를 만들어낼 수 있게 된다.
기존의 방법에서처럼 input vector로부터 이미지를 직접 생성할 경우, 고정된 input distribution (예: Gaussion)에 학습 이미지의 distribution을 맞춰야 한다는 한계가 있다. 이로 인해 visual attribute가 input space에 non-linear하게 mapping되고, input vector로 visual attribute를 조절하기가 매우 어려워진다.
예를 들어 검정머리 80%, 노란머리 20%로 이루어진 이미지 데이터를 가지고 generator를 학습한다면 latent space 또한 편중되어 있는 데이터의 분포를 따라가게 되고, input space의 대부분의 영역이 검은 머리를 표현하게 될 것이고, input vector를 조절하여 머리 색을 변경하기가 어려워진다. 하지만 다른 비선형 mapping network f를 이용하면, 모델이 학습 데이터의 분포를 따를 필요가 없는 벡터를 생성할 수 있고, 고정된 distribution을 따를 필요가 없어지기 때문에 학습 데이터를 intermediate latent space에 mapping 할 수 있다.
이러한 특징을 disentanglement라고 하며, 논문에서 이를 측정하기 위한 두가지 방법을 제시하는데, 뒤에서 살펴보도록 하겠다.
Mapping network
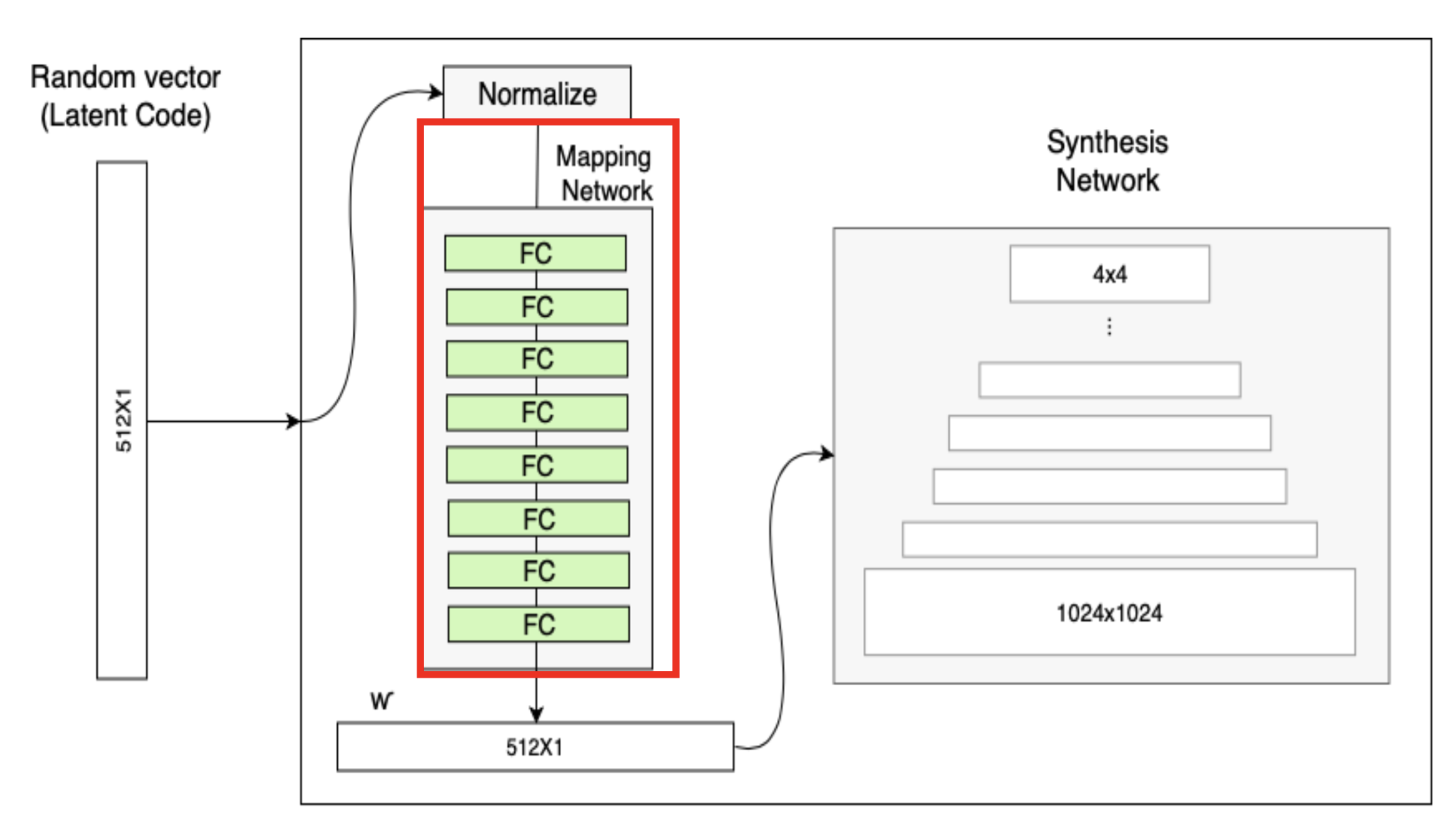
StyleGAN의 가장 큰 특징은 input vector로부터 직접 이미지를 생성하는 것이 아니라, 아래와 같이 mapping network를 거쳐 intermediate vector로 먼저 변환한 후 이미지를 생성한다는 것이다.
기존의 GAN 방식대로라면 Latent space가 학습 데이터의 분포를 직접적으로 따라가게 된다. 이럴 경우 앞서 언급했던 문제점인 interpolation이 부자연스럽게 되는 feature entanglement현상이 발생한다.
이러한 이유로 z를 비선형 함수인 mapping network f를 통과시켜 나온 w를 사용한다. f는 8개의 FC layer로 이루어진 단순한 인공 신경망이다.
{kind=link}
Reference
https://arxiv.org/abs/1812.04948
https://arxiv.org/abs/1710.10196
https://github.com/NVlabs/stylegan
다른 논문을 읽으려고 정리해두는 것을 미루다보니 벌써 화요일,, 목요일 이전에는 꼭 완성해두기.
겨울방학때 GAN 논문 차근차근 정리하기 제발 꼭 하자 하영아..
