AAC BEATs-CONFORMER-BART
intro
모델 구성
- seq2seq 아키텍처
- 오디오 인코더: BEATS 트랜스포머& 2 layer Conformer
- 텍스트 디코더: BART 텍스트 디코더
주요 기능:
- BEATS 모듈: 고해상도 오디오 특징(약 50 Hz) 추출
- Conformer: 오디오 특징 다운샘플링 및 요약
- 훈련:
- 자회귀적 음성 부정 로그 우도(NLL) 손실 계산
- 오디오-텍스트 대조 손실을 적용하여 언어 모달리티 지식 주입
- INSTRUCTOR 트랜스포머 사용
- ChatGPT: 캡션 mixs-ups 생성으로 데이터의 복잡성과 다양성 증가
추론:
- 핵 샘플링과 재순위 알고리즘(nucleus sampling
and a hybrid reranking algorithm) 사용 - hybrid reranking algorithm으로 가능성과 오디오-캡션 표현 유사성을 고려
성과:
Clotho (V2) 평가에서 높은 SPIDEr-FL 점수 기록 (단일 모델 0.326, 앙상블 시스템 0.336)
- 키워드: BEATS, Conformer, INSTRUCTOR, ChatGPT, InfoNCE
2. METHOD
2.1. Network Architecture and Main Loss Function
주요 오디오 인코더:
- BEATs 모듈:
- 입력: 16 kHz 오디오 파형
- 처리 과정:
- 오디오 파형을 멜 스펙트로그램으로 변환
- 멜 스펙트로그램을 2D 패치(작은 조각)로 나눔
- 12개의 셀프 어텐션(트랜스포머) 레이어를 통해 각 패치를 잠재 표현 시퀀스로 변환
- 특징:
트랜스포머 백본 사용
AudioSet에서 사전 학습됨 (마스킹된 오디오 언어 모델링 + 다중 레이블 오디오 분류)
약 50 Hz 해상도의 오디오 특징 출력 (PANN의 약 1 Hz보다 높음)
AudioSet 다중 레이블 분류에서 더 나은 성능 (50.6% vs 43.9% 평균 정확도)- 마스킹된 오디오 언어 모델링(Masked Audio Language Modeling, MALM)
텍스트에서 마스킹된 언어 모델링과 유사한 방식으로, 오디오 데이터에서 특정 부분을 마스킹하고 모델이 이 마스킹된 부분을 예측하도록 학습하는 기법입니다. 이는 모델이 오디오 신호의 특정 부분을 이해하고 복원하는 능력을 키워줍니다.
- 마스킹된 오디오 언어 모델링(Masked Audio Language Modeling, MALM)
추가 구성 요소:
- convolution down sampling layer:
- 2-layer Conformer:
- 역할: 오디오 특징을 더 잘 맥락화하여 텍스트 디코더의 요약 작업 부담 감소(contextualize the audio features, and reduce the text decoder’s workload on summarizing the audio features)
텍스트 디코더:
- 6층 BART 트랜스포머 디코더:
- 작동 방식:
- Conformer의 출력 표현에 cross atention 수행
- 이전에 생성된 캡션 토큰(historical 캡션 토큰)에 셀프 어텐션 수행
- 다음 캡션 토큰을 자기 회귀적으로 생성
- 작동 방식:
- 텍스트 토크나이저: 50K 어휘 크기의 기본 BART 텍스트 토크나이저 사용
- 훈련 방식: BART의 가중치를 처음부터 훈련 (사전 학습된 가중치 없이 처음부터 학습, train the BART’s weights from scratch)
- 자기 회귀적 생성(Autoregressive Generation)
:모델이 시퀀스의 다음 항목을 이전에 생성된 항목들을 기반으로 예측하는 방식 - 텍스트 토크나이저(Text Tokenizer)
: 텍스트 데이터를 처리 가능한 작은 단위, 즉 토큰으로 분할하는 도구입니다. 토큰은 단어, 부분 단어, 또는 심지어 문자일 수 있습니다. 텍스트 토크나이저는 문장을 단어 또는 하위 단위로 분할하고, 각 토큰을 고유한 숫자 ID로 변환합니다. 이는 텍스트 데이터를 신경망 모델에 입력할 수 있는 형식으로 변환하는 중요한 과정입니다.
- 자기 회귀적 생성(Autoregressive Generation)
주요 손실 함수:
- 부정 로그 우도(NLL):
- 적용: BART의 출력 분포에 적용
- 목적: 오디오 캡션의 정확성을 높이기 위함
훈련 및 평가:
- BEATs 모듈 frozen:
- 이유: 계산 및 메모리 부담을 줄이기 위해
- 파일럿 실험 결과: BEATs 모듈을 미세 조정하거나 고정 상태로 두었을 때 유사한 SPIDEr-FL 점수 획득
모델 개요:
- BEATs 모듈 -> 컨볼루션 다운샘플링 레이어 -> 2층 Conformer -> 6층 BART 트랜스포머 디코더
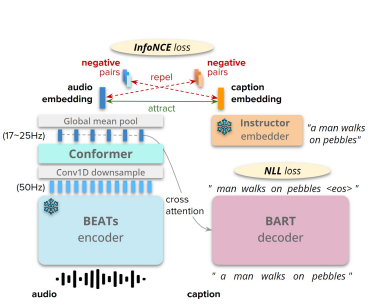
2.2. INSTRUCTOR Embedding Supervision
목표: 오디오 표현에 텍스트 관련 지식을 주입하여 캡셔닝 성능 향상
기법:
- INSTRUCTOR-XL2 트랜스포머:
사전 학습된 T5 텍스트 인코더를 사용해 다양한 NLP 작업에서 finetuning - 프롬프트 사용:
“Represent the audio caption:”을 사용하여 실제 캡션에서 문장 임베딩을 가져옴 - 평균 풀링:
BEATs-Conformer 인코더 스택에서 타임스텝 차원에 따라 오디오 임베딩을 얻음 - InfoNCE 손실:
오디오 임베딩과 텍스트 임베딩 사이의 유사성을 최대화하고, 다른 임베딩과의 유사성을 최소화하여 모델이 고품질 임베딩을 학습하도록 하는 대조 학습(contrastive learning) 기법
배치 내 부정 샘플(negative samples)을 사용해 계산
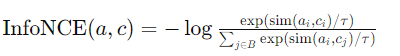
sim(·, ·)은 온도 조정된 코사인 유사성의 지수화된 값 (exponentiated temperature-scaled cosine similarity)
τ는 온도 하이퍼파라미터
B는 샘플링된 미니 배치
i와 j는 미니 배치의 샘플 - 총 멀티 태스크 손실
- 기본적인 캡셔닝 손실(NLL)과 InfoNCE 손실을 결합
- α = 1으로 둠
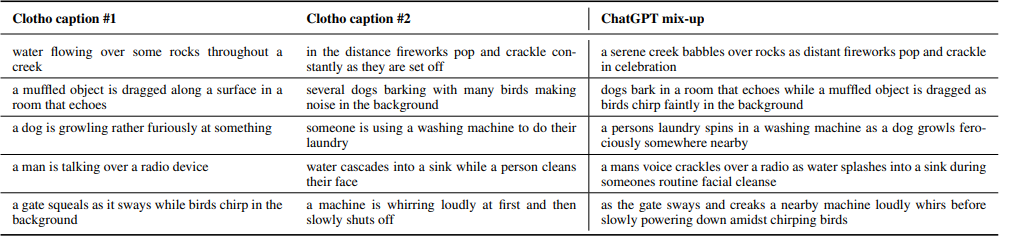
2.3. ChatGPT Mix-up Augmentation
목적: 제한된 크기의 Clotho 데이터셋을 보완하기 위해 더 복잡하고 다양한 훈련 데이터를 생성
기법:
- ChatGPT 활용: 캡션 믹스업 생성.
- 프롬프트
: “Generate a mix of the following two audio captions, and keep the generation under 25 words:” - 입력: Clotho 데이터셋에서 임의로 선택된 두 캡션.
-> 서로 다른 오디오 클립에 해당하는 캡션을 믹스업하는 것 - 출력: 25단어 이하로 생성된 믹스업 캡션.
- 프롬프트
- 해당하는 오디오 파형 믹스업
: 두 오디오 클립을 상대적인 제곱 평균 제곱근 에너지가 ±5 dB 이내에 있도록 스케일링한 후 함께 추가. - 품질 필터링
: FENSE 비유창성 탐지기를 사용하여 품질이 낮은 예제를 제거.
훈련 데이터
: ChatGPT 믹스업과 AudioCaps 데이터셋을 사용하여 캡션 모델 사전 학습.
효과
: 50K ChatGPT 믹스업을 사용하여 더 높은 SPIDEr-FL 점수 획득.

2.4. Sampling and Reranking
1. nucleus sampling
- temperature 0.5 and top-p of 0.95
- 파일럿 실험에서 빔 서치보다 높은 SPIDEr-FL 점수를 얻는 경우가 많음
2. hybrid reranking algorithm
-
학습된 오디오 인코더 스택과 텍스트 디코더의 지식을 다시 활용
-
캡션 로그 우도:
=
->주어진 오디오 입력에 대해 생성된 캡션이 얼마나 잘 맞는지를 나타내는 측정값
->는 모델이 이전 단어들과 오디오 입력을 바탕으로
번째 단어를 생성할 확률 -
오디오-캡션 표현 유사성: 코사인 유사성
-> = 생성된 캡션 을 INSTRUCTOR 모델에 입력하여 얻은텍스트 임베딩
-> = 의 오디오 임베딩
=>로그 우도와 표현 유사성에 대해 각각 {0.3, 0.7}(중요도)이 모든 모델에서 잘 작동
=>빔 서치보다 SPIDEr-FL에서 0.01~0.02 정도 향상
결과
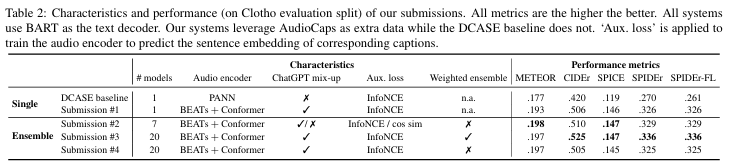
- 3번 모델 여러 경우의 수의 모델을 가중치 앙상블 함
- 4번 모델(평균 앙상블)보다 성능이 좋았음
참고
- INSTRUCTOR-XL2
입력된 텍스트에 대한 고품질 문장 임베딩을 생성하는 모델- INSTRUCTOR-XL2 트랜스포머에서 프롬프트
입력 텍스트 앞에 조건으로 추가됩니다.
예를 들어, "Represent the audio caption:"이라는 프롬프트를 실제 캡션 앞에 추가하면, 모델은 이 프롬프트를 참고하여 해당 텍스트를 오디오 캡션으로 이해하고 임베딩을 생성합니다.
- 평균 풀링(mean pooling)
- 위치:
평균 풀링은 BEATs-Conformer 인코더 스택의 출력에서 시간(time) 차원에 따라 수행됩니다. 이는 인코더의 출력 특징 맵을 시간 차원으로 축소하여 단일 벡터로 만듭니다.
- 이유:
- 단일 오디오 임베딩 생성:
평균 풀링을 통해 각 시간 단계에서 얻어진 특징 벡터들을 평균 내어 하나의 고정된 크기의 벡터로 요약합니다. 이렇게 하면 입력 오디오 파형 전체를 대표하는 단일 임베딩 벡터를 얻을 수 있습니다.- 훈련 및 계산 효율성:
단일 벡터로 요약된 임베딩은 후속 처리 단계에서 계산 부담을 줄이고, 모델의 훈련과 추론 속도를 향상시킵니다.- 텍스트 임베딩과의 일관성:
INSTRUCTOR 모델을 통해 얻은 텍스트 임베딩과 동일한 차원의 벡터를 생성하여 InfoNCE 손실을 적용할 때 일관성을 유지할 수 있습니다.
- 배치 내 부정 샘플(in-batch negative samples)
미니 배치 내에서 오디오에 상응하지 않는 캡션을 가진 쌍들을 말함
- Nucleus Sampling
누클리어스 샘플링은 다음 단어에 대한 확률 분포에서 상위 p%에 해당하는 항목들만 고려하여 새로운 샘플을 생성하는 방법입니다. 이는 생성된 텍스트의 품질을 향상시키고, 더 자연스럽고 다양성이 있는 결과를 얻기 위해 사용됩니다.
- 하이브리드 재순위 결정 알고리즘
하이브리드 재순위 결정 알고리즘은 생성된 샘플들을 다시 평가하여 가장 적합한 샘플을 선택하는 과정
나) 인코더 출력에 대한 mean pooling 시간 정보를 잃음->어텐션 풀링, linear transformation, 어텐션 한 후 풀링
