BART
1. intro
배경
자기 지도 학습(self-supervised learning) 방법은 다양한 자연어 처리(NLP) 작업에서 놀라운 성공을 거두었다. 가장 성공적인 접근법은 마스크된 언어 모델(masked language models)로, 이는 텍스트의 일부분을 마스킹하고 이를 복원하도록 학습되는 디노이징 오토인코더이다.최근 연구에선 task에 맞는 스킴들을(마스크된 토큰을 다루는 방법들) 제시하며 성능향상을 보여줬다. 그러나 이러한 방법들은 특정 유형의 task(예: 스팬 예측, 생성 등)에 중점을 두기 때문에 다른 task에 있어선 적용 가능성이 제한된다.
BART
BART는 Bidirectional Transformer와 Auto-Regressive Transformer를 결합해 사전학습한 디노이징 오토인코더 모델이다. 이 모델은 노이징의 유연성을 통해 다양한 스킴을 내장하고 있어 여러 최종작업에 바로 적용할 수 있다.
-> 스킴을 바꾸거나 그에 따른 모델 설계를 따로 할 필요가 없다.
(fine-tuning만 다르게 해주면 됨)
- 표준 트랜스 포머의 아키텍쳐를 사용
- 인코더: BERT
- 디코더: GPT
- 사전학습
- 임의의 노이징 함수로 텍스트를 손상시킴
- 다시 텍스트를 reconstruction하도록 학습
- noising의 유연성
- 인코더 디코더를 모두 사용하기에 BERT, GPT보다 복잡한 노이즈 변환이 가능
- 인코더의 입력(손상된 텍스트)와 다코더의 출력(복원된 텍스트)가 일치할 필요가 없어 다양한 노이즈 변환이 가능
2. Model
BART
- 디노이징 오토인코더
: 손상된 문서를 원본 문서로 복원하는 디노이징 오토인코더 - seq-2-seq
손상된 텍스트를 Bidirection 인코더로 처리하고, 왼쪽에서 오른쪽으로 Auto-Regressive 디코더로 복원 - 사전 학습
원본 문서의 negative log likelihood를 최적화하여 학습음의 로그 가능성(Negative Log Likelihood, NLL)은 확률 모델의 출력과 실제 데이터 간의 차이를 측정하는 손실 함수
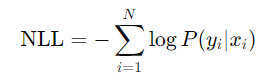
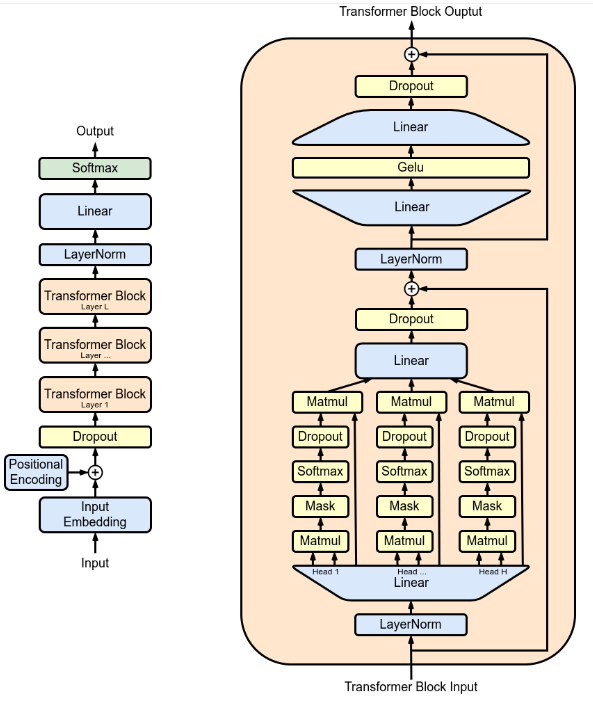
2.1 architecture
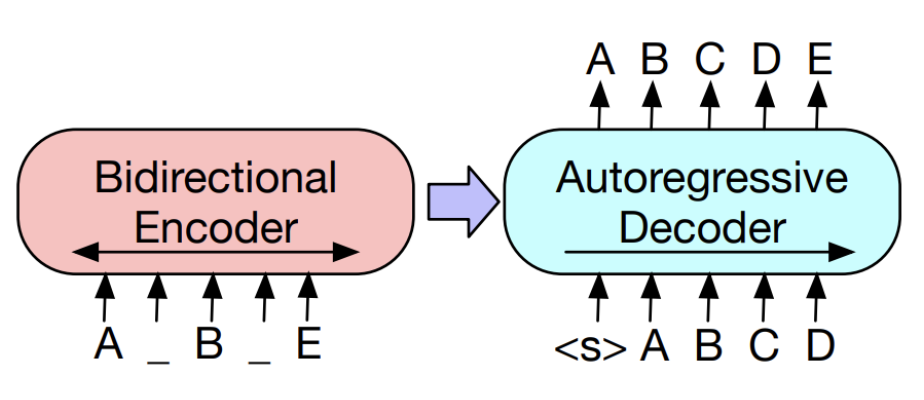
- 표준 트랜스포머 아키텍처 사용
- 인코더: BERT
- 디코더: GPT
- 활성화 함수: ReLu->GeLu
- 파라미터를 정규분포 에서 초기화
- cross atention으로 인코더의 최종 출력과 디코더를 연결
- 레이어 구성:
- 기본 모델: 인코더와 디코더 각각 6개 레이어.
- 대형 모델: 인코더와 디코더 각각 12개 레이어.
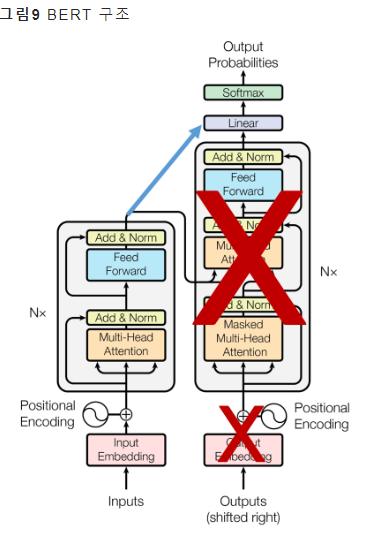
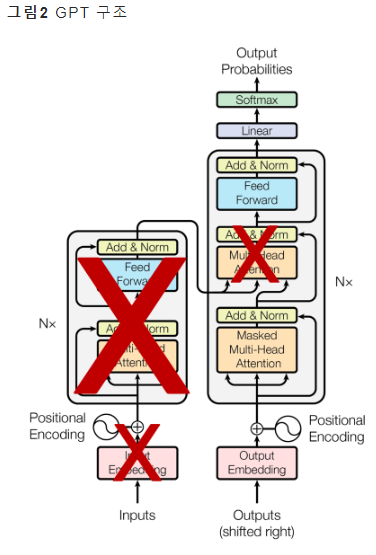
인코더: BERT / 디코더: GPT
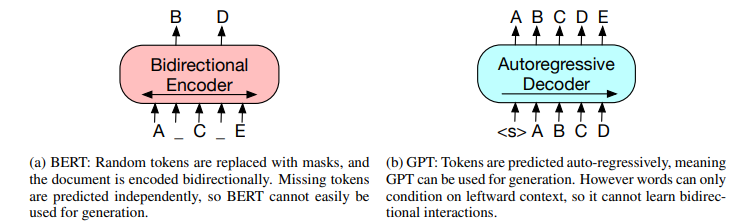
BERT
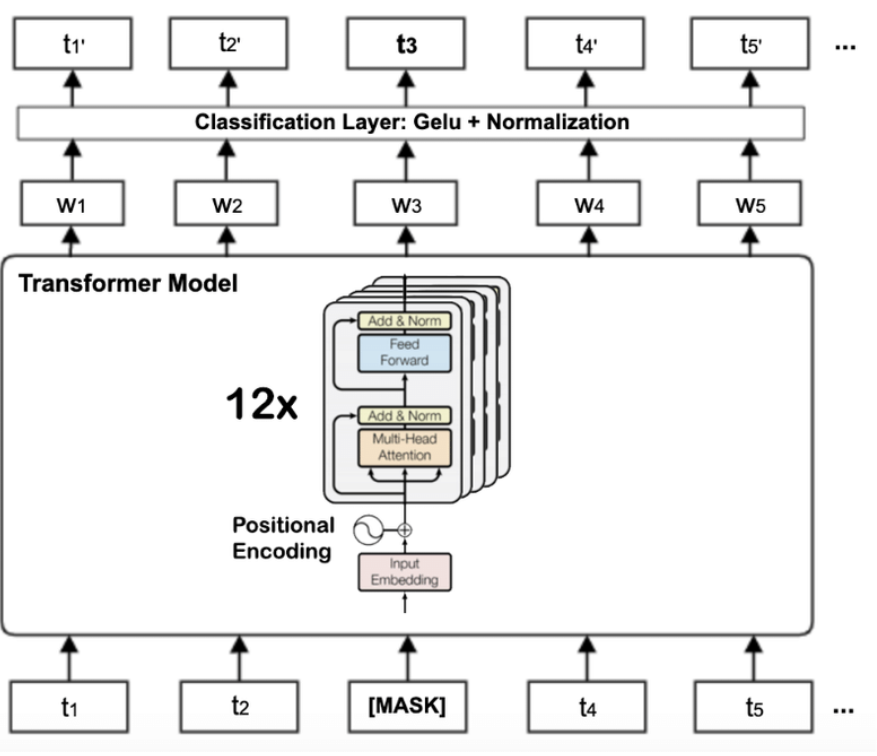
GPT
2.2 Pre-training BART
BART의 사전 학습과정
1. 문서를 의도적으로 손상시킴(다양한 방법으로)
2. 모델에 넣음->모델을 통해 복원
3. 복원한 텍스트와 원본 문서간 교차 엔트로피를 최소화 하는 방향으로 모델을 학습
- 유연한 노이즈 적용:
기존의 디노이징 오토인코더와 달리, BART는 특정 노이즈 스킴에 맞춰 설계되지 않아 다양한 형태의 문서 손상을 적용할 수 있음 - 변환 방법들
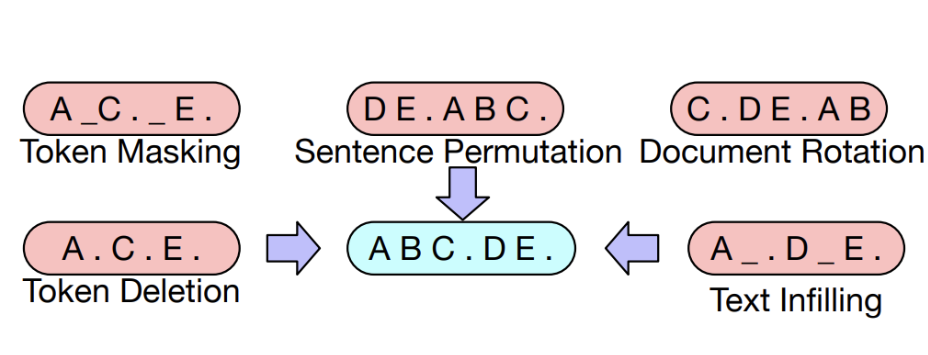
- Token Masking: 랜덤으로 토큰을 [MASK]로 대체.
- Token Deletion: 랜덤으로 토큰을 삭제.->어느 위치에서 토큰이 삭제되었는지 맞춰야됨
- Text Infilling: 포아송 분포에서 추출한 길이의 여러 텍스트 스팬을 [MASK]로 대체.(중요)
- Sentence Permutation: 문서를 문장 단위로 나누어 문장의 순서를 섞음.
- Document Rotation: 임의의 토큰을 선택하여 그 토큰을 시작점으로 두고 배열
3. finetuning
3.1 Sequence Classification Tasks(긍정/부정 등)
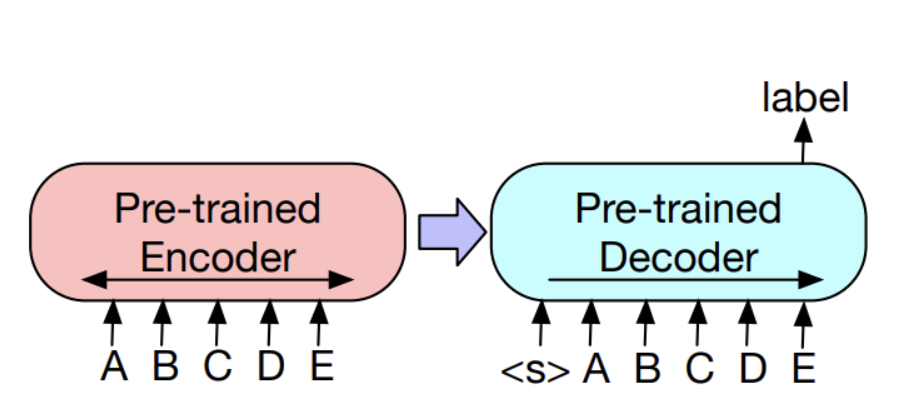
- 동일한 입력을 인코더와 디코더에 넣음
- BERT에서 첫번째 토큰이 문장을 대표해서 사용되는 것처럼 디코더 입력에서 마지막 토큰 (additional token)의 최종 히든 state를 전체문장을 요약하는 표현으로하여 사용됨
3.2 Token Classifications Tasks(명사, 시작위치 등)
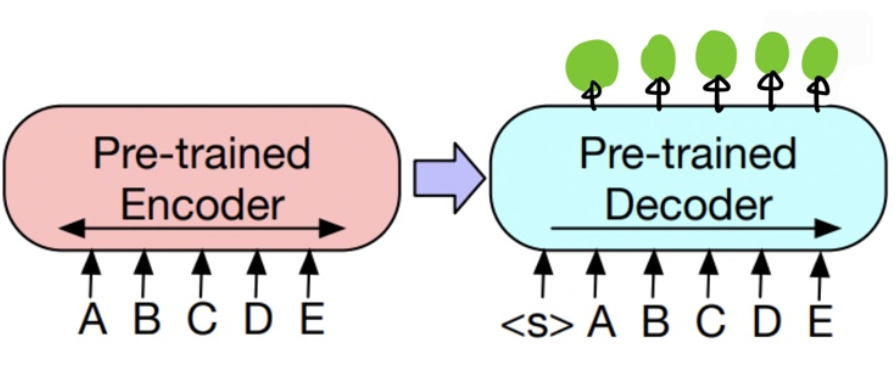
- 동일한 입력을 인코더와 디코더에 넣음
- Decoder의 상단의 hidden state가 token 각각의 representaiton이 된다. 이렇게 나온 representation이 token을 분류할 수 있다.
3.3 Sequence Generation Tasks
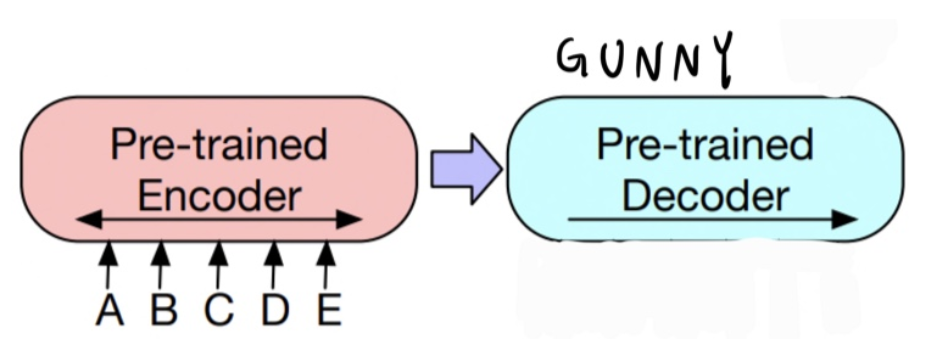
- 인코더에만 입력이 들어감
- BART는 sequential text를 생성할 수 있는 AR 특성의 Decoder가 있기에, 바로 abstractive question answering 혹은 abstractive summarization에 대한 fine-tuning을 할 수 있음
3.4 Machine Tranlsation Tasks
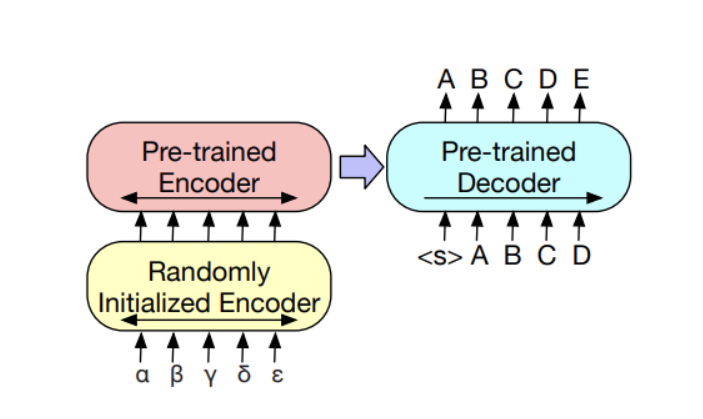
- Tranlsation을 위해 학습된 입력 된 언어의 정보를 학습된 언어로 바꿔줄 인코더가 필요
1) BART의 대부분의 parameters를 freeze하고 randomly initialized한 additional Encoder의 parameters들을 학습합니다.
2) 적은 iteration 만큼의 횟수로 모델의 모든 parameter를 학습합니다.
result
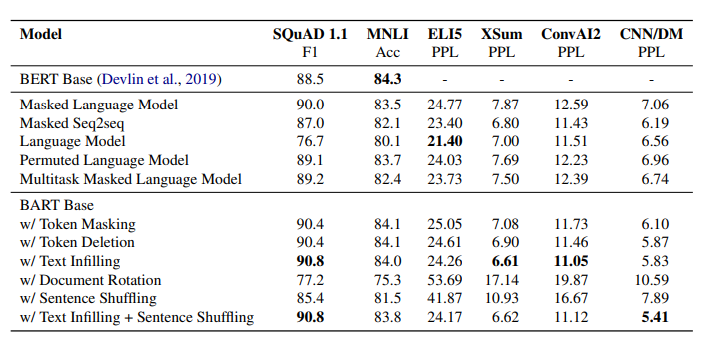
Discriminative Tasks
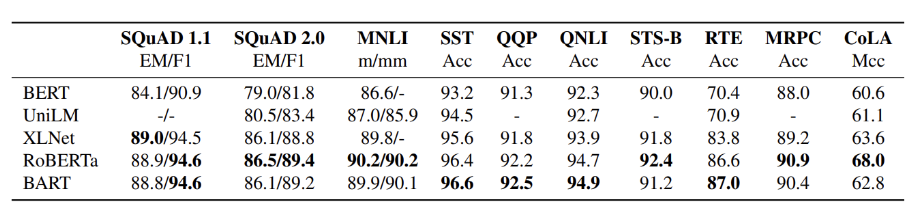
Generation Tasks
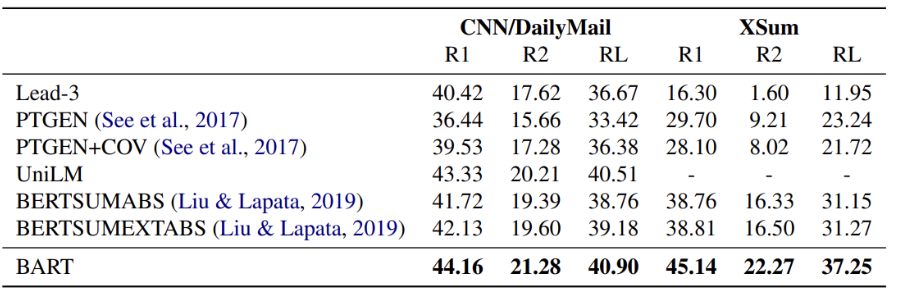
Conclusion
BART는 RoBERTa와 비슷한 수준의 성능을 discriminative tasks에서 보였을 뿐만 아니라, 수 많은 generation tasks에서 State-of-the-art를 달성
